Carbon-Aware Quality Adaptation for Energy-Intensive Services
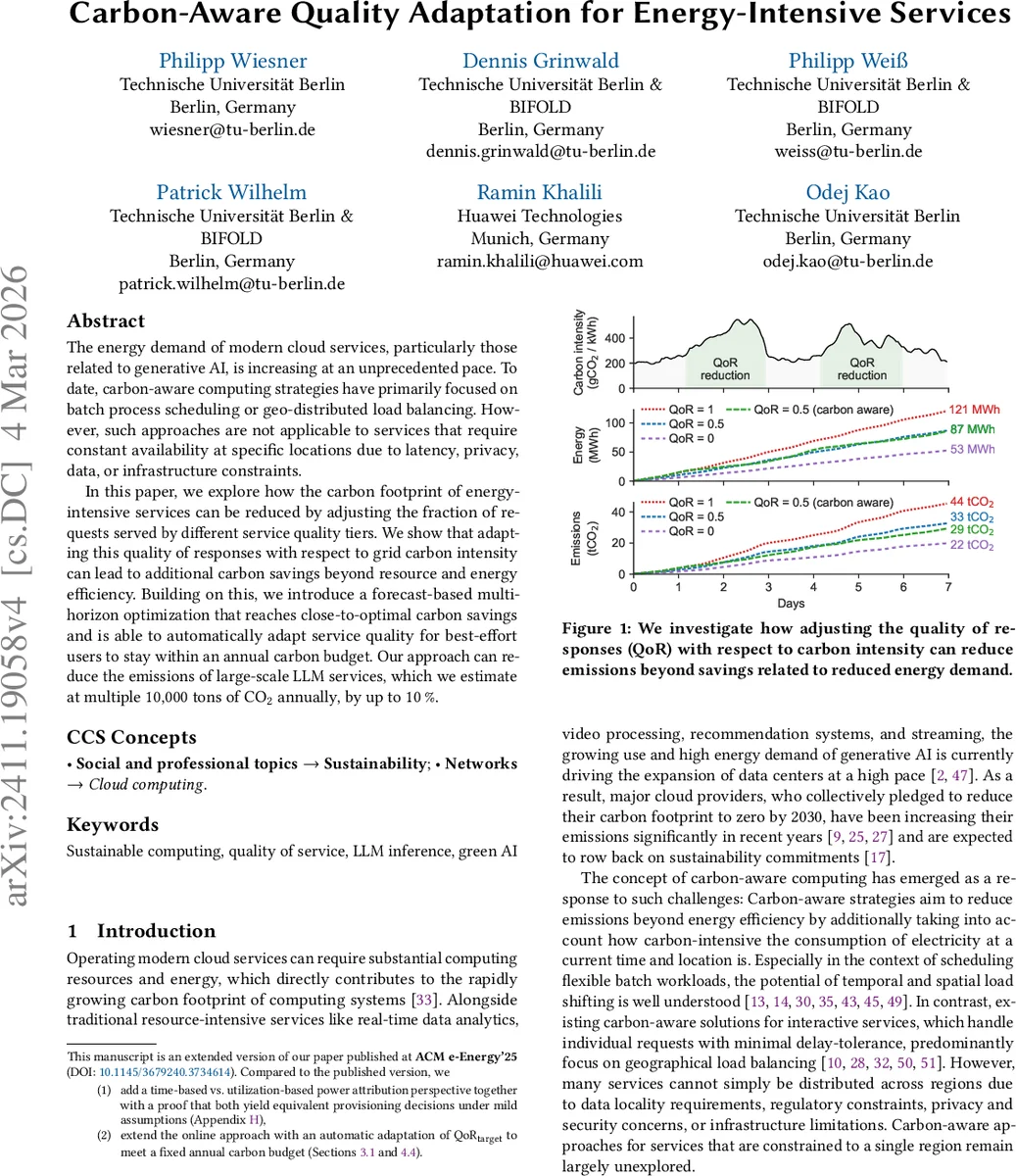
The energy demand of modern cloud services, particularly those related to generative AI, is increasing at an unprecedented pace. To date, carbon-aware computing strategies have primarily focused on batch process scheduling or geo-distributed load balancing. However, such approaches are not applicable to services that require constant availability at specific locations due to latency, privacy, data, or infrastructure constraints. In this paper, we explore how the carbon footprint of energy-intensive services can be reduced by adjusting the fraction of requests served by different service quality tiers. We show that adapting this quality of responses with respect to grid carbon intensity can lead to additional carbon savings beyond resource and energy efficiency. Building on this, we introduce a forecast-based multi-horizon optimization that reaches close-to-optimal carbon savings and is able to automatically adapt service quality for best-effort users to stay within an annual carbon budget. Our approach can reduce the emissions of large-scale LLM services, which we estimate at multiple 10,000 tons of CO2 annually, by up to 10%.
💡 Research Summary
The paper tackles the growing carbon footprint of energy‑intensive cloud services, especially generative‑AI workloads, by introducing a novel carbon‑aware quality‑of‑response (QoR) adaptation mechanism. Traditional carbon‑aware strategies focus on batch job scheduling or geo‑distributed load balancing, which are unsuitable for latency‑sensitive, privacy‑constrained, or region‑locked services that must remain continuously available in a single location.
The authors propose to split service delivery into two quality tiers: a high‑quality, high‑power tier (e.g., a large LLM model) and a low‑quality, low‑power tier (e.g., a smaller LLM or a quantized version). QoR is defined as a real number between 0 and 1 representing the proportion of requests served by the high‑quality tier; QoR = 1 means all requests use the high‑quality tier, QoR = 0 means all use the low‑quality tier. By varying QoR over time, the system can align higher‑quality processing with periods of low grid carbon intensity (ACI) and shift to lower‑quality processing when the grid is carbon‑intensive.
A formal model is built: the planning horizon (typically one year) is divided into intervals of length Δ (e.g., one hour). QoR is evaluated over rolling windows of length γ (multiple of Δ) to enforce a minimum average quality over each window. Carbon emissions for interval i are expressed as
E_i = Σ_{m∈M} Σ_{q∈Q} d_{i,m,q}·Δ·p_{i,m,q}·C_i + C_emb,m
where d_{i,m,q} is the number of active machines of type m serving tier q, p_{i,m,q} is the power draw (either utilization‑based or time‑based), C_i is the regional carbon intensity (gCO₂/kWh), and C_emb,m accounts for embodied emissions. The paper shows that under mild concavity assumptions, utilization‑based and time‑based power attribution lead to identical provisioning decisions, simplifying implementation.
The core optimization problem minimizes total emissions ΣE_i subject to: (1) every request is assigned to a tier, (2) provisioned capacity meets the assigned load, and (3) QoR over each validity window stays above a target QoR_target. This mixed‑integer linear program (MILP) is NP‑hard and requires forecasts of future carbon intensity and request volume, which are inherently uncertain.
To make the approach practical, a two‑level multi‑horizon online algorithm is introduced. A long‑term optimization runs every τ intervals (e.g., every 24 h) solving the MILP for the remaining horizon while keeping past decisions fixed, ensuring global feasibility of QoR constraints. A short‑term optimization runs each interval, solving a much smaller MILP over the next γ intervals using the latest short‑term forecasts; this step refines the deployment quickly (typically within 1–2 seconds). If the short‑term solver fails, the system falls back to serving all requests with the high‑quality tier (QoR = 1) and provisioning the minimal number of machines needed for capacity.
The authors also address scenarios where operators have an annual carbon budget B. In this case QoR_target becomes a decision variable, and the objective switches to maximizing QoR_target while keeping ΣE_i ≤ B. The remaining budget B_rem(α) is updated after each interval, and the long‑term optimization is re‑solved with the updated constraint, allowing the system to automatically tighten or relax QoR_target throughout the year.
Experiments simulate a large‑scale LLM inference service for the year 2023. Two LLMs are used: LLaMA 3.1 8B (low‑quality tier) and LLaMA 3.1 70B (high‑quality tier). The hardware platform is an AWS EC2 p4d.24xlarge instance (3781 W power, 135 gCO₂ embodied emissions). Throughput measurements from vLLM give 11.57 req/s for the 8B model and 5.05 req/s for the 70B model. Eight request traces are employed: synthetic constant and random traces, real Wikipedia page‑view logs (English and German), New York City taxi trips, and three synthetic traces derived from Google’s Borg cluster models (Cell B, D, F). Four years of hourly request data are generated; three years train forecasting models, the fourth year serves as the evaluation period. Real grid carbon intensity data for ten regions are used.
Key findings:
- Aligning high‑quality processing with low‑carbon‑intensity periods and low‑quality processing with high‑carbon‑intensity periods reduces annual emissions by 6 %–10 % across all regions and workloads.
- When an annual carbon budget is imposed, the system can start with a modest QoR_target (≈ 0.7) and still keep total emissions below the budget while maintaining an average QoR above 0.85, demonstrating that service quality need not be sacrificed dramatically.
- The long‑term optimization run every 24 h, combined with the short‑term refinement, keeps total solver time for a full‑year simulation under three hours, and the per‑interval short‑term solve averages 1.2 seconds, confirming feasibility for real‑time operation.
- The equivalence of time‑based and utilization‑based power attribution is validated experimentally, meaning the method can be applied regardless of the accounting framework (Scope 2 vs. Scope 3).
The paper contributes a practical, forecast‑driven framework for carbon‑aware quality adaptation that works for services constrained to a single region. It demonstrates that dynamic QoR control can achieve meaningful carbon savings without violating service‑level expectations. Limitations include the binary tier model (only two quality levels) and reliance on accurate carbon‑intensity forecasts; future work is suggested on extending to multiple tiers, incorporating per‑user SLA differentiation, and deploying the approach in production environments with cloud providers. The authors release all code and datasets, facilitating reproducibility and encouraging further research in sustainable AI service design.
Comments & Academic Discussion
Loading comments...
Leave a Comment