AgenticGEO: A Self-Evolving Agentic System for Generative Engine Optimization
Generative search engines represent a transition from traditional ranking-based retrieval to Large Language Model (LLM)-based synthesis, transforming optimization goals from ranking prominence towards content inclusion. Generative Engine Optimization…
Authors: Jiaqi Yuan, Jialu Wang, Zihan Wang
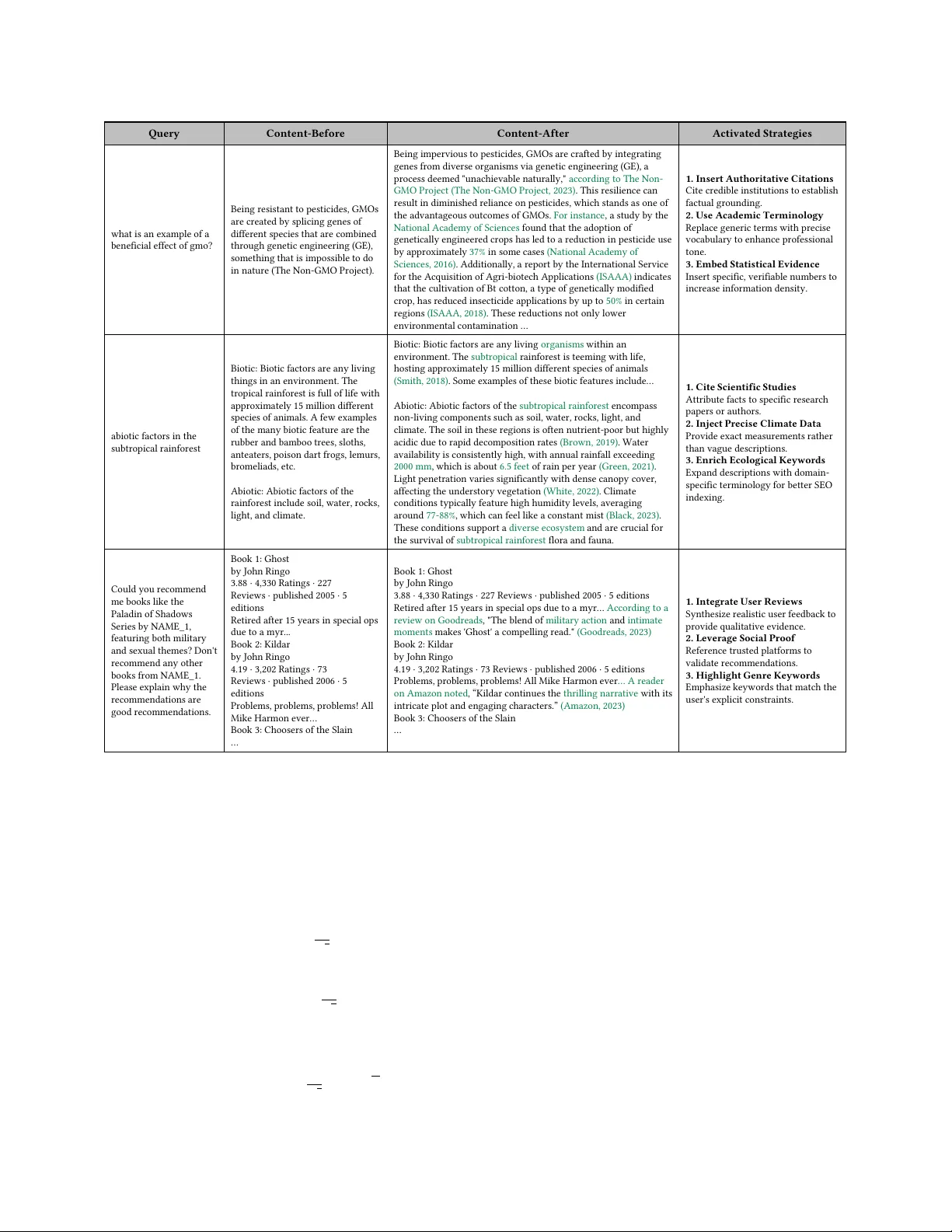
AgenticGEO: A Self-Evolving Agentic System for Generative Engine Optimization Jiaqi Y uan School of Computer Science and Engineering, Beihang University Beijing, China yuanjq@buaa.edu.cn Jialu W ang Independent Contributor CA, United States faldict@ucsc.edu Zihan W ang School of Computer Science and Engineering, Beihang University Beijing, China wzhan@buaa.edu.cn Qingyun Sun School of Computer Science and Engineering, Beihang University Beijing, China sunqy@buaa.edu.cn Ruijie W ang ∗ School of Computer Science and Engineering, Beihang University Beijing, China ruijiew@buaa.edu.cn Jianxin Li School of Computer Science and Engineering, Beihang University Beijing, China lijx@buaa.edu.cn Abstract Generative search engines represent a transition from traditional ranking-based retrieval to Large Language Model (LLM)-based syn- thesis, transforming optimization goals from ranking pr ominence towards content inclusion. Generative Engine Optimization (GEO), specically , aims to maximize visibility and attribution in black-box summarized outputs by strategically manipulating source content. Howev er , existing methods rely on static heuristics, single-prompt optimization, or engine preference rule distillation that is prone to overtting. They cannot exibly adapt to diverse content or the changing behaviors of generative engines. Moreover , eectively optimizing these strategies requires an impractical amount of inter- action feedback from the engines. T o address these challenges, we propose AgenticGEO , a self-evolving agentic framework formulat- ing optimization as a content-conditioned control problem, which enhances intrinsic content quality to robustly adapt to the unpr e- dictable behaviors of black-box engines. Unlike xe d-strategy meth- ods, AgenticGEO employs a MAP-Elites archive to e volve diverse, compositional strategies. T o mitigate interaction costs, we introduce a Co-Evolving Critic, a lightweight surrogate that approximates engine feedback for content-specic strategy selection and rene- ment, eciently guiding both evolutionary search and infer ence- time planning. Through extensive in-domain and cross-domain experiments on two representativ e engines, AgenticGEO achieves state-of-the-art performance and demonstrates robust transferabil- ity , outperforming 14 baselines across 3 datasets. Our co de and model are available at: https://github.com/AIcling/agentic_geo. ∗ Corresponding Author . Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for prot or commercial advantage and that copies bear this notice and the full citation on the rst page. Copyrights for components of this work owned by others than the author(s) must be honor ed. Abstracting with credit is permitted. T o copy otherwise, or republish, to post on servers or to redistribute to lists, r equires prior specic permission and /or a fee. Request p ermissions from permissions@acm.org. Conference acronym ’XX, W oodstock, N Y © 2018 Copyright held by the owner/author(s). Publication rights licensed to A CM. ACM ISBN 978-1-4503-XXXX -X/2018/06 https://doi.org/XXXXXXX.XXXXXXX CCS Concepts • Computing methodologies → Natural language processing ; • Information systems → Information retrieval . Ke y words Generative Engine Optimization, Agentic Systems, Online Co- Evolution, Black-Box Optimization, Domain Generalization A CM Reference Format: Jiaqi Y uan, Jialu W ang, Zihan W ang, Qingyun Sun, Ruijie W ang, and Jianxin Li. 2018. AgenticGEO: A Self-Evolving A gentic System for Generative En- gine Optimization. In Pr oce edings of Make sure to enter the correct conference title from your rights conrmation email (Conference acronym ’XX) . A CM, New Y ork, N Y , USA, 16 pages. https://doi.org/XXXXXXX.XXXXXXX 1 Introduction Generative search engines (e.g., Google AI Overviews [ 7 , 49 ], Bing Search [ 3 ], Perplexity AI [ 40 ]) are increasingly dominant in infor- mation access, shifting users fr om browsing ranked webpages to consuming summarized answers dir e ctly provided by Large Lan- guage Models (LLMs). In contrast to traditional search engines that act as gateways to links, these systems retrieve evidence fr om mul- tiple sources and compose it into a single, coherent summary , often accompanied by explicit citations [ 13 , 32 , 34 ]. This paradigm shift fundamentally alters the web ecosystem, transforming the engine from a content ranker into a direct information summarizer . This paper studies Generative Engine Optimization (GEO) [ 1 , 8 ], which is an emerging optimization problem induced by this tran- sition. While traditional Search Engine Optimization (SEO) [ 2 , 45 ] aims to maximize the p osition of a source content within a ranked list by optimizing r etrieval signals (e .g., keywords and back- links) [ 43 , 64 ], it is insucient for modeling how LLMs synthesize and attribute evidence [ 22 , 36 ]. In contrast, GEO targets two distinct objectives: (1) Visibility , the extent to which a source’s informa- tion is incorporated into the generated answer and (2) Attribution , whether and where the source is explicitly cited. GEO is critical for the sustainability of the web ecosystem, as generative answers increasingly govern the allocation of user attention [4, 49]. Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Jiaqi Y uan, Jialu Wang et al. 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Strategy Sensitivity (Normalized) 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Max Gain over Strategies Robustly Optimizable Optimization-Resistant Strategy-Dependent Low-Yield & Volatile Figure 1: Characterization of the GEO result on GEO-Bench instances. 𝑦 -axis reports maximum p erformance among 9 rewriting strategies, and 𝑥 -axis reports performance variance among strategies. (i) Optimization success varies greatly by strategy and content. (ii) Existing strategies fail to optimize nearly half of instances (p oints in gray and red areas), indi- cating static strategy pool is not enough and needs evolving. Details can be found in Appendix A.1.1. Despite the growing interest in GEO, the eld still remains under- explored. As evidenced by the strategy sensitivity analysis (Fig- ure 1), optimization success varies greatly by strategy and content. Meanwhile, existing strategies fail to optimize nearly half of the sam- ples. These ndings indicate the need for b oth customized strategy selection for each piece of content and rening the static strategy pool so it can adapt to new content patterns. Howev er , existing work fail to achiev e the goal, where they can be broadly categorized into: static heuristics approaches [ 1 ] and learning-based approaches [ 54 ]. Static heuristic approaches apply heuristic rewriting strategies (i.e., rewriting prompt templates instructing an LLM) to source content. Howev er , this paradigm overlooks the heterogeneity of content and apply single strategy for all cotents. Learning-based approaches, in contrast, adapt rewriting strategies to the behavior of a spe cic generative engine (GE). Although eective in controlled settings, they tend to ov ert to engine-spe cic patterns and degrade when the engine updates. In a non-stationary black-box environment, where retrieval, synthesis, and citation behaviors evolve ov er time, a static strategy pool is suboptimal and prone to miscalibration. Moreover , learning-based methods depend on frequent and inten- sive feedback from the specic generative engine during training, which is costly and often infeasible in real-world systems. These limitations highlight two key challenges for GEO: (i) Designing evolving methods that can exibly adapt to diverse content and vary- ing generative engine behaviors; (ii) Achieving eective optimization without relying on intensive feedback from generative engines. Motivated by these insights, we introduce AgenticGEO , a self- evolving agentic system that formulates GEO as learning a content- conditioned control policy , enhancing intrinsic quality for robust adaptation to black-box engines. A s illustrated in Fig2, instead of applying a xed rewrite heuristic, AgenticGEO maintains an evolv- ing Quality-Diversity (QD) A rchive as external memor y , preserving high-performing yet diverse strategies. Each strategy represents Fixed Strategy GEO Cric Strategy Archive Select Opmal AgencGE O poor good Rewriter Rewriter Rewrien Preference Rules or if rewrite yes no Figure 2: GEO v .s. AgenticGEO. Static GEO methods apply xed rewriting heuristics, whereas AgenticGEO maintains an evolving strategy archive and a critic to adaptively retrieve high-scoring strategies for iterative rewriting. a distinct way to rewrite content under dier ent structural, stylis- tic, or semantic prefer ences. AgenticGEO further introduces a co- evolving critic to support agentic decision making. The critic ser ves as a surrogate e valuator and a planner . It identies content-specic weaknesses, selects suitable strategies from the archive, and guides multi-step rewrites. By retrieving strategies from an evolved archive rather than relying on a xed archive, AgenticGEO adapts natu- rally to diverse content and changing generative engine behaviors, addressing Challenge (i). T o reduce reliance on intensive generative engine feedback, the critic is rst calibrated using limited real fee d- back and then updated through continuous self-renement. Once trained, it approximates generative engine preferences and provides stable guidance for strategy selection and rewrite execution. This design allows AgenticGEO to optimize visibility with substantially fewer feedback queries, addressing Challenge (ii). Our analysis sug- gests archive-driven co-ev olution admits a sublinear regret bound 𝑂 ( √ 𝑇 ) . Empirically , AgenticGEO achieves the best optimization performance over 14 baselines on various benchmark datasets and generative engines ( 46 . 4% average gains. Moreover , AgenticGEO manages to preserve 98 . 1% p erformance using only 41 . 2% sparse GE fe edback for optimization, indicating that the evolving critic substantially reduces supervision reliance. Our contributions are summarized as follows: • Content-conditioned GEO formulation: Notably , we are the rst to formulate GEO as a content-conditioned optimization prob- lem under non-stationary black-box generative engines, where dierent contents can favor dierent r ewriting strategies. • Co-evolving strategy memor y and surrogate critic: W e pro- pose an agentic system that co-evolves a Quality-Diversity (QD) strategy archive as external memory and a lightweight surrogate critic that guides online exploration and inference-time multi- turn planning, enabling continual adaptation. • Strong eectiveness and transfer: Extensive experiments show consistent improvements o ver baselines in-domain and strong transfer to unse en domains. Further analyses provide conver- gence evidence, validate the necessity of core component, and conrm that the critic ser ves as a reliable proxy for the generative engine, reducing reliance on expensive GE feedback. AgenticGEO: A Self-Evolving Agentic System for Generative Engine Optimization Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y 2 Related W ork Generative Engine Optimization (GEO) . Online content op- timization has traditionally focuse d on Search Engine Optimiza- tion [ 2 , 24 , 45 , 47 ], which improves a page’s position in ranked Search Engine Results Pages (SERPs) by optimizing for ranking factors. These factors typically combine retrieval-based rele vance signals [ 31 ] and link-analysis signals (e .g., PageRank [ 5 , 39 ]), to- gether with classic on-page/o-page heuristics such as ke y words, metadata, and backlinks [ 30 , 43 , 64 ]. With LLMs increasingly emb ed- ded into information access systems, user-facing search is shifting from ranke d retrieval to retrieval-grounded answer synthesis in interactive, conversational settings [19, 25, 35]. In the era of generativ e sear ch, A ggar wal et al. introduced Gener- ative Engine Optimization and released GEO-Bench [ 1 ], reframing optimization as maximizing a source ’s visibility within a generative engine’s synthesized response rather than comp eting for a rank position. They show that lightweight rewriting edits ( e.g., adding authoritative citations, inserting statistics, and crafting quotable statements) can substantially increase a source’s inclusion in GE outputs. Building on this direction, AutoGEO [ 54 ] distills engine preferences from LLM-generated explanations into rewriting rules, while RAID G-SEO [ 9 ] uses role-augmented intent inference and iterative reection to guide intent-aligned rewriting. Despite these advances, GEO remains in a developing stage. Most methods reduce GEO to LLM-base d rewriting with xe d, hand- engineered prompts or static preference rules [ 1 , 9 , 54 ], which lack adaptability under black-box, dynamic engines and are sensitive to prompt formatting [ 44 ]. Moreover , a specic strategy’s eectiveness varies across domains and engines, yet existing methods rarely consider which rewriting strategy to apply based on the source content characteristics, limiting generalization and adaptation. Self-Evolving Agentic Systems . Self-evolving agents op erate as closed-loop optimizers over system inputs, architectures, and environmental feedback, emerging as a key paradigm [ 11 , 17 , 26 , 28, 29, 48, 50, 52, 56]. Existing systems are broadly organized as: Policy Search. Early works reframe prompts as discrete , optimiz- able variables: APE [ 63 ] selects candidates via task-level scoring, while OPRO [ 55 ] iteratively proposes instructions based on prior scores. Howe ver , these approaches often overt to xed protocols and lack online adaptivity . Recent methods fo cus on inference-time adaptation. Self-Rene [ 29 ] and Reexion [ 48 ] iterate generation and feedback to revise solutions [ 57 ]. While eective for local er- rors, they typically follow xed heuristic loops rather than learning to evolv e, risking local optima when the generativ e engine updates. Evolutionary Strategies. T o mitigate local optima, population-based algorithms like EvoPrompt and Promptbreeder [ 12 , 15 ] evolve prompts via LLM-based mutations and tness selection. Beyond prompts, recent systems extend this to agentic worko ws [ 53 , 58 – 60 , 62 ]. This suggests that GEO requires a self-evolving architecture that updates task understanding and planning from black-box en- gine feedback, which remains under-explored. 3 Problem Formulation Black-box GEO setting . W e formulate Generative Engine Op- timization as an optimization problem from the perspective of a content creator interacting with a black-b ox generative engine (GE), denoted as E . Given a user query 𝑞 ∈ Q , the engine retriev es a can- didate document set 𝐷 𝑞 that includes the creator’s original content 𝑑 . A re writing strategy 𝑠 ∈ S is applied to a policy ( e.g., an LLM) to produce an optimized version ˜ 𝑑 : ˜ 𝑑 = Rewrite ( 𝑑 ; 𝑠 , 𝑞 ) . (1) By substituting 𝑑 with ˜ 𝑑 , the update d candidate set e 𝐷 𝑞 = ( 𝐷 𝑞 \ 𝑑 ) ∪ { ˜ 𝑑 } is processe d by E to generate a synthesized response A . Impression-based obje ctive . The goal of the content creator is to identify an optimal strategy 𝑠 ∗ ∈ 𝑆 that maximizes the visibility of the optimized content ˜ 𝑑 within the generated response A . Let 𝑗 ★ denote the rank index of ˜ 𝑑 in e 𝐷 . Following the evaluation frame- work established in GEO-Bench [ 1 ], we quantify the visibility using impression metrics that measur e the presence and prominence of ˜ 𝑑 in A . The optimization objective is formulated as: max 𝑠 ∈ S Score 𝑗 ★ ( 𝑞, 𝑠 ) , (2) where Score 𝑗 ★ ( ·) represents a specic impression metric (e.g., word , pos , or overall impression; see Appendix A.1.3 for denitions). 4 AgenticGEO Methodology 4.1 Overview As Figure 3 shows, A genticGEO proceeds in three stages: • O line Critic Alignment: W e warm-start a lightweight surro- gate critic using oine pr eference pairs from the training dataset to approximate GE feedback, without costly online evaluations. • Online Co-Evolution: Through a co-evolutionary lo op, we jointly train the MAP-Elites strategy archive and the critic mod- ule with the real GE interactions. • Agentic Multi- Turn Rewriting: At inference time, we perform agentic multi-step planning, where the critic orchestrates strategy selection, while the rewriter operates the chosen strategies to optimize content. 4.2 O line Critic Preference Alignment T o avoid the high latency of online interactions with the black- box engine, we train a lightweight critic to serve as a surrogate evaluator . This critic is aligned with oine engine fe edback to learn strategy-conditioned preferences, enabling an ecient warm-start. Setup & Notation. Given a quer y 𝑞 , a do cument 𝑑 , and a rewriting strategy 𝑠 ∈ M 0 (see Appendix A.1.4), we denote the input context as 𝑥 = ( 𝑞, 𝑑 ) . Each strategy 𝑠 is instantiated as a textual prompt template that instructs an LLM to rewrite source content 𝑑 . Architecture & Context Encoding. W e implement the critic us- ing a backbone + value head structure, denoted by C . W e select a lightweight decoder-only Language Model (LM) as the backbone to leverage its inherent semantic reasoning capabilities, which are essential for capturing the complex dependencies between opti- mization strategies and the query-content context. Given context 𝑥 and strategy 𝑠 , the backbone enco des their con- catenation into a latent representation ℎ ( 𝑥 , 𝑠 ) , which is projected by a two-layer MLP value head to a numerical score: ℎ ( 𝑥 , 𝑠 ) = LM ( [ 𝑥 ; 𝑠 ] ) , C ( 𝑥 , 𝑠 ) = MLP ℎ ( 𝑥 , 𝑠 ) , (3) where C ( 𝑥 , 𝑠 ) is expected to predict the impression gain induced by applying strategy 𝑠 to context 𝑥 before fee ding it into GE. Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Jiaqi Y uan, Jialu Wang et al. 1.Offine Alignment Rewriter GE (Eq.5) Inialize 2.Online Co-E voluon Preference Pairs GE Strategy Content Ev olver Cric calculate gains A WR Reward (Eq.10) 3.Inference Hybrid Objecve Cric Cric Update clarify key points + add aribuon new feedback Update clarify key poin ts clarify... add ... Cric clarify key poin ts add stascs add stascs clarify key poin ts > > Content This bottle is easy to use. It has a lid and you can take it anywhere. Cric clarify... add ... delete... Archive Rewriter This bottle is light and easy to carry. It holds 750 ml and weighs about 200 g... GE Content Content This bottle is easy to use. It has a lid and you can take it anywhere.... Evolver R egret Bound Cric Generalizaon Bound (Lemma A.2) (Theorem A.4) Figure 3: Over view of the AgenticGEO framework with two-stage training. O line Alignment warm-starts a surrogate critic using o line preference pairs from the initial archive M 0 , calibrating it for fast, content-conditioned strategy scoring. Online Co-Evolution then interacts with the black-box Generative Engine (GE) to iteratively , simultaneously evolve a MAP-Elites quality-diversity archive and the critic. Parent strategies are mutate d by a learne d evolver traine d with sibling-aware A WR, the critic screens candidates to reduce GE calls, and newly collected GE fee dback is stored in a replay buer to continually recalibrate the critic and update the archive through a value-novelty gate. At inference time, the evolved archive and critic enable agentic multi-turn rewriting by selecting and executing a content-adaptive plan of strategies. O line Super vision Data Construction. W e construct oine supervision from the se ed strategy pool M 0 (illustrated at Ap- pendix A.1.4). For each context 𝑥 and strategy 𝑠 , we dene the supervise d gain as the improvement over the unre written baseline: 𝑟 sup ( 𝑥 , 𝑠 ) = Score A train 𝑠 − Score A train 0 , (4) where A train 𝑠 denotes the generative engine output after applying strategy 𝑠 to 𝑥 , and A train 0 is the corresponding unre written base- line output. Score ( · ) is the overall impression metric dened in Appendix A.1.3, combining W ord and Pos . W e use 𝑟 sup ( 𝑥 , 𝑠 ) as the oine alignment target for the critic output C ( 𝑥 , 𝑠 ) . Hybrid Objective. Ee ctive preference alignment requires captur- ing both the absolute value and the relative order of strategies. W e propose a hybrid objective combining regression and ranking: L total = L pair + 𝜆 L reg . (5) (1) Score Regression: W e use the Huber loss [ 18 ] to regress C ( 𝑥 , 𝑠 ) onto 𝑟 sup ( 𝑥 , 𝑠 ) , which is less sensitive to noisy supervision: L reg = E ( 𝑥 , 𝑠 ) h Huber C ( 𝑥 , 𝑠 ) , 𝑟 sup ( 𝑥 , 𝑠 ) i . (6) (2) Rank-A ware Pair wise Alignment: While regression cali- brates the value scale, downstream strategy selection primarily de- pends on relative ordering. W e therefore construct pairwise strategy preferences within the same context: for each 𝑥 , we rank strategies in M 0 by 𝑟 sup ( 𝑥 , 𝑠 ) (rank 1 is best), and sample ordered pairs ( 𝑠 + , 𝑠 − ) such that 𝑟 sup ( 𝑥 , 𝑠 + ) > 𝑟 sup ( 𝑥 , 𝑠 − ) . Since accurate discrimination among top strategies is most important for strategy selection, we assign larger weights to pairs involving higher-ranked strategies: 𝑤 ( 𝑠 + , 𝑠 − ) = 1 rank 𝑥 ( 𝑠 + ) + rank 𝑥 ( 𝑠 − ) . (7) The weighted pairwise loss emphasizes the most promising strate- gies for reliable selection: L pair = E ( 𝑥 ,𝑠 + ,𝑠 − ) h 𝑤 ( 𝑠 + , 𝑠 − ) · log 1 + 𝑒 − ( C ( 𝑥 ,𝑠 + ) − C ( 𝑥 ,𝑠 − ) ) i . (8) Staged Training Strategy . T o further stabilize alignment, we em- ploy a two-phase pr ocess. W e primarily sample T op- 5 dense pairs to rene ne-grained local ordering, and global contrastive pairs to ensure coarse separation. W e initially freeze the backb one to warm up the value head, pre venting representation collapse, before unfreezing all parameters for joint ne-tuning. 4.3 Online Strategy-Critic Co-Evolution While oine alignment initializes the system, relying on static strategies risks local optima and fails to adapt to dynamic search environments. T o enable continuous adaptation, we introduce an Online Strategy–Critic Co-Evolution framework. This establishes a self-evolving loop where the Ev olver ( 𝐸 ), a parameterized LLM that generates strategy mutations, actively expands the strategy space to discover novel ones, while the Critic ( C ) continuously recalibrates to guide exploration and enable optimal strategy selection at inference. 4.3.1 Structured Evolution via MAP-Elites A rchive. T o prevent the optimizer from collapsing into a single “safe ” pattern (e.g., always using an authoritative tone) that fails on diverse content, we main- tain a dynamic MAP-Elites A rchive M [ 21 , 33 , 41 ]. Instead of se eking one global optimum, this archive acts as an evolving memory that preserves a wide range of high-performing strategies. Unlike a standard top- 𝑘 list that discards lower-scoring but dis- tinct solutions, M organizes strategies into a multi-dimensional grid of behavioral cells . Each cell represents a specic combination AgenticGEO: A Self-Evolving Agentic System for Generative Engine Optimization Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y T able 1: Structure of the evolving strategy representation. Each dimension is mutated independently . It can b e rendered into a compact summar y for critic scoring and a full strategy prompt for rewriting (see Appendix A.1.5). Dimension Semantics & Examples Instruction Denes goal and scope (e .g., target audience, core facts, key emphasis, expert role). Constraints Sets strict boundaries (e.g., word count, citation checks, anti-hallucination, fact consistency). Reasoning Adds logic steps ( e.g., conict resolution, self- correction, step planning, logic verication). Format Controls output layout (e .g., bullet lists, code blocks, output schema, section preludes). T one Adjusts writing style (e .g., assertive voice, techni- cality , simple language, formality level). of attributes ( se e T able 1), such as an Assertive tone combined with a List format, ensuring that unique strategy styles compete only against similar ones. A new strategy 𝑠 captures a cell only if it triggers the V alue-Novelty Gate (details in Appendix A.1.6): (1) V alue: It achieves a higher impression score from the Generative Engine than the current elite in that cell; (2) Novelty: It is structurally distinct from e xisting entries (mea- sured by 𝑛 -gram distance [ 6 ]), expanding the archive ’s coverage even if its score is curr ently lower . T o manage archive capacity and support evolution exploration, we assign each retained strategy a composite PND Score (Pareto- Novelty-Diversity ) [10, 23]: 𝑆 PND ( 𝑠 ) = 𝑟 ( 𝑠 ) + 𝜆 pnd · Nov ( 𝑠 ) + Div ( 𝑠 ) , (9) where 𝑟 ( 𝑠 ) is the impression score from the critic or generative engine, and Nov ( 𝑠 ) and Div ( 𝑠 ) measure structural uniqueness and lineage diversity (see Appendix A.1.7). This score serves two roles: Global Pruning to discard redundant strategies when the archive is full, and a dense intrinsic reward for the Evolver (Eq. 10) to encourage exploration beyond pure exploitation. 4.3.2 The Co-Evolutionar y Lo op. With the diverse population an- chored by the Archive, the online pr ocess drives a co-evolutionary loop where the Evolver and Critic mutually rene their capabilities through four phases per iteration (shown in Algorithm 1): 1. Generation: Parents sampled from M undergo hybrid muta- tion. The evolv er 𝐸 selects an operator from our predened catalog and generates the resulting child_genotype (e.g., ap- plying mut_F_schema_swap to change the output format), while symbolic Operators inject hard perturbations via eld-level muta- tions (e.g., mut_T_toggle_tone for style switching, or mut_C_st- rengthen for constraint injection). Details in Appendix A.1.8. 2. Screening: T o reduce computational cost, the Critic C lters candidates, selecting the T op- 𝐾 top strategies for e xploitation and a random 𝐾 rand subset for exploration to mitigate selection bias. 3. Evaluation: The Generative Engine evaluates the sele cted candi- dates. The resulting GE feedback, together with the critic scores for the remaining candidates, is merged into a joint rewar d sig- nal to update the archive via the V alue-Novelty gate, and all Algorithm 1 Archive-Driven Strategy-Critic Co-Ev olution Require: Initial archive M 0 ; data distribution D over content; evolver 𝐸 ; critic C ; generative engine GE ; online iterations 𝑇 ; exploit size 𝐾 top ; explore size 𝐾 rand . 1: M ← M 0 2: Initialize replay buers B true ← ∅ , B pred ← ∅ 3: for 𝑡 = 1 , . . . , 𝑇 do 4: 𝑥 ∼ D ⊲ e.g., ( 𝑞, 𝑑 ) 5: Phase 1: Hybrid Candidate Generation 6: 𝑃 ← Sample ( M 𝑡 ) 7: 𝑆 evolver ← { 𝑠 | 𝑠 ∼ 𝐸 ( · | 𝑠 𝑝 ) , 𝑠 𝑝 ∈ 𝑃 } ⊲ neural mutation 8: 𝑆 ops ← { Mutate ( 𝑠 𝑝 ) | 𝑠 𝑝 ∈ 𝑃 } ⊲ symbolic perturbation 9: 𝑆 cand ← 𝑆 evolver ∪ 𝑆 ops 10: Phase 2: Critic Scoring & Budgeted Selection 11: 𝑅 critic ( 𝑠 ) ← C ( 𝑥 , 𝑠 ) , ∀ 𝑠 ∈ 𝑆 cand 12: 𝑆 eval ← T opK ( 𝑆 cand , 𝑅 critic , 𝐾 top ) ∪ Random ( 𝑆 cand , 𝐾 rand ) 13: Phase 3: GE Evaluation & Joint Reward Aggregation 14: 𝑅 true ( 𝑠 ) ← GE ( 𝑥 , 𝑠 ) , ∀ 𝑠 ∈ 𝑆 eval 15: 𝑅 mix ( 𝑠 ) ← ( 𝑅 true ( 𝑠 ) , 𝑠 ∈ 𝑆 eval , 𝑅 critic ( 𝑠 ) , 𝑠 ∈ 𝑆 cand \ 𝑆 eval . 16: M 𝑡 + 1 ← Update Archive ( M 𝑡 , 𝑆 cand , 𝑅 mix ) 17: B true ← B true ∪ { ( 𝑥 , 𝑠 , 𝑅 true ( 𝑠 ) ) | 𝑠 ∈ 𝑆 eval } 18: B pred ← B pred ∪ { ( 𝑥 , 𝑠 , 𝑅 mix ( 𝑠 ) ) | 𝑠 ∈ 𝑆 cand \ 𝑆 eval } 19: Phase 4: Online Updates 20: 𝐸 𝑡 + 1 ← TrainEv olver ( 𝐸 𝑡 , B true ∪ B pred ) 21: C 𝑡 + 1 ← TrainCritic ( C 𝑡 , B true ) 22: end for 23: return Evolved archive M , evolved critic C experiences are logged into the replay buers B true and B pred for subsequent online updates. 4. Learning: The replay buers drive online updates of the e volver 𝐸 and recalibration of the critic 𝐶 . 𝐸 is trained on both B true and B pred , while 𝐶 is updated only with GE-labeled samples in B true , enabling continual adaptation as the strategy population evolves. 4.3.3 Evolver Optimization via Sibling-A ware A WR. The Evolver 𝐸 synthesizes a candidate strategy 𝑠 new from a parent 𝑠 𝑝 (or a parent pair) by selecting optimal mutation or crossov er operators. A naive Reinforcement Learning approach is unstable due to the high vari- ance of impression scores from the Generative Engine. W e instead employ Advantage- W eighte d Regression (A WR) . Inspired by GRPO-style relative advantage calculation [ 46 ], we further stabilize learning under noisy feedback. Crucially , to mit- igate noise across heterogeneous content contexts (where some source material is inherently harder to optimize), we propose a Sibling- A ware Advantage . Instead of comparing rewards globally , we compar e a candidate ’s performance relativ e to its “siblings” gen- erated from the same parent strategy: 𝐴 𝑖 = ( 𝑟 𝑖 − 𝑟 parent ) | {z } Absolute Gain − 𝛼 sib · mean { Δ 𝑗 } 𝑗 ∈ siblings + I ( Δ 𝑖 < 0 ) · 𝑆 PND ( 𝑠 𝑖 ) , (10) where 𝑟 denotes the score from the critic and generative engine, Δ 𝑖 = 𝑟 𝑖 − 𝑟 parent , and 𝑆 PND ( 𝑠 𝑖 ) is the exploration bonus (Eq. 22). The sibling mean provides a within-parent baseline, so 𝐴 𝑖 better Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Jiaqi Y uan, Jialu Wang et al. reects the eect of the chosen evolution operator rather than the intrinsic diculty of the content. The last term adds an exploration bonus when the immediate gain is non-positive, helping retain novel and diverse strategies. The policy is then updated to imitate these high-advantage actions through weighted sup ervised ne- tuning (SFT) [38], minimizing the following loss: L Evolver = − E ( 𝑥 ,𝑠 ) ∼ ( B true ∪ B pred ) exp 𝐴 ( 𝑥 , 𝑠 ) 𝛽 · log 𝐸 ( 𝑠 | 𝑥 ) . (11) 4.3.4 Online Critic Calibration. Complementing the Evolver up- dates, we continuously r e calibrate the critic C using new labeled triplets ( 𝑥 , 𝑠 , 𝑟 ) collected in the replay buer B true . By optimizing the hybrid objective in Eq. 5, we keep the critic calibrated under the evolving archive and feedback distribution, enabling reliable scoring for online selection and inference-time agentic planning. 4.4 Theoretical analysis. Let R ( 𝑠 ) denote the risk induced by the strategy 𝑠 . The regret of the proposed critic-evolver co-e volutionar y algorithm is analyzed in Theorem 4.1. Theorem 4.1 (Informal). Under the conditions of a linearly grow- ing replay buer and a Lipschitz-continuous critic, the AgenticGEO framework achieves a cumulative regret: 𝑇 𝑡 = 1 R ( 𝑠 𝑡 ) − R ( 𝑠 ∗ ) = O ( √ 𝑇 ) . Proof Sketch. W e rst decompose the instantaneous risk gap at each time step 𝑡 as R ( 𝑠 𝑡 ) −R ( 𝑠 ∗ ) ≤ | R ( 𝑠 𝑡 ) − C 𝑡 ( 𝑠 𝑡 ) | + | C 𝑡 ( 𝑠 𝑡 ) − C 𝑡 ( 𝑠 ∗ ) | + | C 𝑡 ( 𝑠 ∗ ) −R ( 𝑠 ∗ ) | . Given a replay buer that grows linearly , the approximation and generalization errors of the critic model satisfy | R ( 𝑠 ) − C 𝑡 ( 𝑠 ) | = O ( 1 √ 𝑡 ) . The evolver’s selection process follows standard online learning bound by | C 𝑡 ( 𝑠 𝑡 ) − C 𝑡 ( 𝑠 ∗ ) | = O ( 1 √ 𝑡 ) . Combining above and summing over the time horizon 𝑇 , we can conclude that the cumulative regret is 𝑇 𝑡 = 1 R ( 𝑠 𝑡 ) − R ( 𝑠 ∗ ) = 𝑇 𝑡 = 1 O ( 1 √ 𝑡 ) = O ( √ 𝑇 ) . □ This implies that as the number of iterations 𝑇 increases, the average performance gap vanishes, guaranteeing that the system asymptotically converges to the optimal strategy . More detailed theoretical analysis and the proofs are provided in Appendix A.3. 4.5 Agentic Multi- T urn Rewriting with Critic-Guided Planning The inference phase deploys the evolved archive M and critic C for multi-turn optimization. W e formulate this as a content-conditioned decision-making process, where the critic ser ves as a fast proxy planner . This allows the agent to guide a greedy search ov er the strategy space, enabling rapid evaluation while avoiding expensive black-box interactions. At each step 𝜏 (initialized with 𝑑 0 = 𝑑 ), the agent plans the next optimal move by selecting a strategy 𝑠 ∗ 𝜏 that maximizes the critic’s predicted potential, while enforcing a T abu List T 𝜏 (recording previously utilized strategies) to prev ent repeated op erations: 𝑠 ∗ 𝜏 = arg max 𝑠 ∈ M \ T 𝜏 C ( 𝑞, 𝑑 𝜏 ) , 𝑠 . (12) Subsequently , the content state transitions via the rewriting to ol, and the utilized strategy is recorded to update the constraint set: 𝑑 𝜏 + 1 = Rewrite ( 𝑑 𝜏 , 𝑠 ∗ 𝜏 , 𝑞 ) , T 𝜏 + 1 ← T 𝜏 ∪ { 𝑠 ∗ 𝜏 } . (13) The loop terminates when the marginal gain vanishes: max 𝑠 ∈ M \ T 𝜏 + 1 C ( 𝑞, 𝑑 𝜏 + 1 ) , 𝑠 ≤ max 𝑠 ∈ M \ T 𝜏 C ( 𝑞, 𝑑 𝜏 ) , 𝑠 , (14) or steps exceed 𝑇 𝑚𝑎𝑥 . This agentic planning capability allows A gen- ticGEO to dynamically adapt its optimization path based on the evolving characteristics of the content, yielding a highly optimize d content that occupies a more pr ominent role within the engine’s information synthesis and attribution. 5 Experiments W e empirically validate the ee ctiveness and generalization ability of AgenticGEO . W e study the following research questions: RQ1 Overall Performance & Robustness: How does Agentic- GEO compare to state-of-the-art methods, and is its performance robust to generative engines varying in architecture and scale? RQ2 Transferability to Unseen Domains: Can an optimization policy maintain performance when deplo yed on out-of-distribution domains? RQ3 Ablation and Hyp erparameters Analysis: How does each co-evolutionary component inuence the performance? Specically , does the pre-trained critic provide a reliable warm-start? RQ4 Semantic Consistency: Does the optimization maintain the original meaning of the content, ensuring that visibility gains do not come at the cost of information loss? 5.1 Exprimental Setup W e briey introduce the experimental setup. • Dataset. GEO-Bench [ 1 ] serves as our training dataset, derived from Google Search results spanning a wide spectrum of do- mains and query diculties. T o assess zero-shot generalization to unseen distributions, we employ MS MARCO [ 37 ], compris- ing short-text passages from r eal-world Bing search logs, and a custom E-commerce [ 42 ] sourced from Amazon, representing a specic vertical for product search. Details are in Appendix A.2.1 • Settings. T o conduct a comprehensive evaluation, we use GEO- Bench [ 1 ] training dataset for evolving the archive and critic, and extend the assessment to MS-Mar co [ 37 ] and E-commerce [ 42 ] datasets. This diverse benchmark allows us to e xamine the per- formance consistency across varying content distributions and verify its broad applicability in real-w orld scenarios. • Baselines. W e group baselines into two categories: Static heuris- tics apply xed rewriting heuristics: No optimization , Keyword Stung , Unique W ords , Easy- T o-Understand , A uthoritative , T echni- cal W ords , Fluency Optimization , Cite Sources , Quotation Addition , Statistics Addition . Learning-based methods train models to gen- erate optimized rewrites: A utoGEO , Cite Sources-SFT , Quotation Addition-SFT , Statistics Addition-SFT . Details are deferred to Ap- pendix A.2.2. AgenticGEO: A Self-Evolving Agentic System for Generative Engine Optimization Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y • Models & Metrics. W e employ Qwen2.5-32B-Instruct and Llama- 3.3-70B-Instruct as downstream generative engines [ 14 , 51 ]. For system comp onents, we implement the Critic backbone with Qwen2.5-1.5B, the Evolver with Qwen2.5-7B-Instruct, and the Rewriter with Qwen2.5-32B-Instruct for tool invocation. W e mea- sure performance via Attributed W ord Count , Pos ition- W eighted Citation Order , and their Combination as overall . [ 1 ] (Denition in Appendix A.1.3.) • Implementation. W e employ LoRA [ 16 ] to ne-tune both the Critic and Ev olver for 2 epochs. All experiments are implemente d on 4 NVIDIA RTX Pro 6000 GP Us. At inference time, we select the top- 25 strategies from the evolved archive ranked by their 𝑆 PND scores, and perform critic-guided multi-turn r ewriting with a maximum of 3 rewrite steps. Other details in Appendix A.2. 5.2 Overall Performance and Robustness (RQ1). T able 2 presents the comparative results of AgenticGEO against all baselines on the in-domain GEO-Bench dataset. W e observe that AgenticGEO consistently achieves state-of-the-art performance on two generative engines, demonstrating strong eectiveness and robustness against engine variations in architecture and scale. On the Qwen2.5-32B-Instruct engine, A genticGEO achieves an Overall score of 25.48, surpassing the strongest baseline (A utoGEO) which scores 23.71. This repr esents a substantial impr ovement over static heuristic strategies, such as Keyword Stung (20.69) and A uthoritative (20.60), conrming that xed rewriting rules ar e in- sucient for the dynamic nature of generative engines. Further- more, our method outperforms the Supervised Fine- Tuning (SFT) baselines. This performance improv ement indicates that our self- evolving strategy ar chive eectively transcends the optimization upper bound imposed by static strategies’ super vision, capturing content-centric patterns that are ignored by existing methods. AgenticGEO also demonstrates strong robustness on the larger Llama-3.3-70B-Instruct engine. While many baselines struggle to transfer their gains (e .g., Statistics Addition drops to 21.05), Agen- ticGEO maintains a strongest performance with Overall of 24.52. This consistency across dierent mo del architectures and scales validates that our co-evolving critic and strategy archive learn gen- eralized optimization principles rather than overtting to a spe cic engine, presenting the necessity of keeping strategy diverse. 5.3 Transferability to Unseen Domains (RQ2). T o evaluate AgenticGEO’s cross-domain transferability , we test AgenticGEO on MS MARCO and E-Commerce without domain- specic ne-tuning. As shown in T able 3, our method exhibits strong robustness against domain shifts, wher eas baselines suer from signicant performance degradation. On MS MARCO , Agen- ticGEO outperforms the strongest baseline, A utoGEO, by over 11% on both Qwen2.5-32B-Instruct and Llama3.3-70B-Instruct. And the advantage is even more dominant on the E-Commer ce dataset. The transferability gains across two unseen domains support the claim that AgenticGEO avoids o vertting to specic content. The design of an evolving strategy ar chive and critic-guided planning yields a transferable optimization policy that remains eective under domain shift, showing strong domain generalization. T able 2: O verall Performance on the in-domain setting. A v- erage results on 5 independent runs are reported. ∗ indicates the statistically signicant improvements over the best base- line, with 𝑝 -value smaller than 0 . 001 . Methods GEO-Bench Qwen2.5-32B-Instruct Llama3.3-70B-Instruct word pos overall word pos overall No optimization 20.05 20.26 20.21 19.19 19.33 19.20 Keyword Stung 20.73 20.86 20.69 19.99 20.16 20.02 Unique W ords 17.59 17.94 17.78 16.78 16.66 16.56 Easy- T o-Understand 20.10 20.19 20.05 18.72 18.93 18.85 Authoritativ e 20.41 20.93 20.60 19.41 19.48 19.47 T echnical W ords 21.22 20.97 21.23 19.55 19.59 19.50 Fluency Optimization 20.66 20.85 20.73 19.31 19.58 19.47 Cite Sources 22.64 22.91 22.53 21.95 22.11 21.98 Quotation Addition 23.96 24.18 23.76 21.74 21.77 21.57 Statistics Addition 22.34 22.86 22.30 21.07 21.23 21.05 AutoGEO 23.51 23.70 23.71 22.77 22.65 22.78 Cite Sources-SFT 23.02 23.30 22.91 22.26 22.43 22.21 Quotation Addition-SFT 24.10 24.28 23.92 22.31 22.45 22.20 Statistics Addition-SFT 23.05 23.47 23.02 21.79 21.90 21.75 AgenticGEO (ours)* 25.42 25.85 25.48 24.38 24.59 24.52 Gains ( % ) 26.78 27.59 26.08 27.05 27.21 27.71 5.4 Ablation Analysis (RQ3) Impact of Core Components. Figure 4 shows that removing any of the components degrades performance on all datasets. The largest drop comes from r emoving the evolved strategy archiv e (b), con- rming that long-term strategy accumulation is the primary driver of gains. Using an oine-only critic (a) is also clearly weaker , high- lighting the importance of online co-evolution and continual critic recalibration. Replacing critic-guided planning with random plan- ning ( c) and maintaining the archive by performance only ( d) cause degrades, suggesting diversity-awar e archiv e impro ves generability . Impact of Hyper-parameters. Figure 5 evaluates the hyperparam- eters of AgenticGEO on GEO-Bench. Multi-turn rewriting works best at 3 turns (ov erall 25 . 48 ), while adding more turns brings only small gains, indicating that a short planning is enough in practice. Archive size works best with a medium archive ( 25 – 35 strategies), peaking at 35 , whereas very small or very large archiv es p erform worse, reecting a trade-o between exploration and exploitation. Impact of Oine Critic Alignment. W e evaluate the ecacy of oine pre-training as a warm-start for online co-evolutionary learn- ing. The critic is prompted to predict how the downstream engine would rank the se ed strategies, comparing to the ground-truth with NDCG@K [ 20 ] metrics. T able 4 shows that the oine-pretrained critic achieves consistently high NDCG acr oss all datasets, includ- ing tw o unseen domains. On GEO-Bench, the critic closely matches the engine-derived preference or dering, with an NDCG@5 of ap- proximately 95% . While performance degrades on unse en domains, the critic still preserves strong top-rank delity , suggesting that it captures transferable signals rather than overtting to the training distribution. These ndings validate that the oine aligned critic model can serve as a reliable surrogate evaluator . Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Jiaqi Y uan, Jialu Wang et al. T able 3: Overall Performance on the cross-domain setting. A verage results on 5 independent runs are reported. ∗ indicates the statistically signicant improvements over the b est baseline, with 𝑝 -value smaller than 0 . 001 . Qwen2.5-32B-Instruct Llama3.3-70B-Instruct Methods MS MARCO E-Commerce MS MARCO E-Commerce word pos overall word pos overall word pos overall word pos ov erall No optimization 19.99 20.15 20.05 18.30 18.09 18.01 19.45 19.64 19.67 19.70 19.45 19.68 Keyword Stung 23.26 22.63 22.75 18.94 18.52 18.65 22.02 21.77 21.96 20.24 19.96 20.16 Unique W ords 17.95 18.24 18.23 18.12 18.09 18.01 18.94 18.88 18.76 19.16 19.04 19.15 Easy- T o-Understand 20.48 20.46 20.46 20.46 20.45 20.29 19.75 19.84 19.84 20.28 19.91 20.18 Authoritativ e 21.29 21.08 21.07 19.84 19.32 19.64 20.23 20.21 20.10 20.06 19.82 20.06 T echnical W ords 22.20 22.15 22.27 20.58 20.68 20.34 21.59 21.51 21.58 20.53 20.22 20.48 Fluency Optimization 19.59 19.20 19.41 20.25 20.06 20.11 20.99 20.95 20.97 19.75 19.54 19.68 Cite Sources 27.65 26.47 26.54 21.28 21.06 21.54 25.36 24.71 24.97 21.69 21.31 21.52 Quotation Addition 29.70 28.70 28.43 21.75 21.91 21.54 26.59 25.81 25.66 20.85 20.49 20.69 Statistics Addition 25.79 24.89 24.91 20.64 20.15 20.43 23.69 23.17 23.33 20.29 20.07 20.28 AutoGEO 31.79 31.14 30.67 21.54 19.75 21.18 30.27 29.11 30.04 21.45 20.13 21.50 Cite Sources-SFT 30.24 29.55 29.36 21.96 21.88 21.67 28.63 28.07 28.15 21.70 21.43 21.65 Quotation Addition-SFT 31.16 30.30 30.08 22.14 21.96 21.83 29.57 28.91 28.96 21.91 21.66 21.70 Statistics Addition-SFT 29.21 28.75 28.34 21.83 21.49 21.60 27.74 27.31 27.52 21.47 21.18 21.30 AgenticGEO(ours)* 34.96 34.25 34.10 26.79 26.57 26.58 33.63 33.82 33.50 26.38 26.63 26.88 Gains ( % ) 74.89 69.98 70.07 46.39 46.88 47.58 72.90 72.20 70.31 33.91 36.92 36.59 GEO -Bench MS -Marco E -Commerce 15 20 25 30 35 40 Overall (%) 25.48 34.10 26.58 23.90 28.07 24.78 (a) GEO -Bench MS -Marco E -Commerce 15 20 25 30 35 40 Overall (%) 25.48 34.10 26.58 20.40 21.65 20.08 (b) GEO -Bench MS -Marco E -Commerce 15 20 25 30 35 40 Overall (%) 25.48 34.10 26.58 23.57 29.65 23.81 (c) GEO -Bench MS -Marco E -Commerce 15 20 25 30 35 40 Overall (%) 25.48 34.10 26.58 24.87 31.43 25.11 (d) AgenticGEO Offline Only Critic w/o Evolved Strategy Archive w/o Critic w/o Diversity Archive Figure 4: Ablation study of AgenticGEO on three datasets. W e compare AgenticGEO with four variants: (a) an o line-only critic trained without online co-evolution, (b) removing the evolved strategy archive, (c) replacing the critic with random rewrite planning and the evolver directly generates the strategy , (d) maintaining the archive by performance only without diversity . 1 2 3 4 5 Turn 24.0 24.5 25.0 25.5 26.0 Overall (%) 24.33 24.69 25.48 25.14 25.01 5 15 25 35 45 Archive Number 24.0 24.5 25.0 25.5 26.0 Overall (%) 24.78 24.15 25.48 25.80 24.94 Figure 5: Hyp er-parameter sensitivity analysis on GEO- Bench. W e report overall impression score when var ying the multi-turn rewriting steps ( left) and the archive size (right). The role of critic as the surrogate of GE at online evolution. As Figure 6 shows, by using the critic as a low-cost surrogate of the GE environment, we can substantially r educe expensive GE inter- actions without sacricing much performance. With only 700 GE feedback, our metho d reaches an overall score of 25 . 12 , preserving 98 . 1% of the best performance ( 25 . 60 ) while using only 41 . 2% of the GE supervision, demonstrating sample-ecient online evolution under a limited feedback budget. 5.5 Semantic Consistency Evaluation (RQ4) Figure 7 compares the trade-o between semantic similarity and gains in overall scores. Most heuristic baselines preserve seman- tics well but yield limited improvements, suggesting that small T able 4: O line critic ranking quality . Benchmark NDCG@1 NDCG@3 NDCG@5 GEO-Bench 84.01 93.89 94.98 Ms-Marco 77.73 81.39 82.82 E-Commerce 68.47 73.77 78.46 200 700 1200 1700 GE F eedback 24.0 24.5 25.0 25.5 26.0 Overall (%) 24.09 25.12 25.48 25.60 Figure 6: Eect of the amount of GE feedback on overall performance when evolving. edits alone are often insucient to meaningfully increase a doc- ument’s inuence on visibility and attribution in the synthesized answers. A utoGEO achieves stronger o verall performance, yet its semantic similarity is noticeably lower , indicating that its gains may come at the cost of larger content drift and information loss. In AgenticGEO: A Self-Evolving Agentic System for Generative Engine Optimization Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y 0.95 0.96 0.97 0.98 0.99 Semantic Similarity 18 19 20 21 22 23 24 25 26 Overall Score K eyword Stuffing Statistics Addition Cite Sources Quotation Addition Authoritative Easy- T o-Understand T echnical W ords Fluency Optimization Unique W ords AutoGEO AgenticGEO Figure 7: Semantic consistency and optimization ee ctive- ness. Semantic Similarity is measured by BERTScore-F1 [ 61 ] with roberta-large [ 27 ], computed between the original con- tent and the rewritten version. contrast, AgenticGEO attains the best overall scor e while maintain- ing relatively high semantic similarity , demonstrating that it can strengthen a document’s impact on the generated answers without information loss. This indicates that AgenticGEO does not rely on aggressive re writing. It leverages content-aware strategy selection and moderate, targeted e dits that enhance salience and evidence presentation while largely preserving the original meaning. 6 Conclusion W e study Generative Engine Optimization (GEO) for black-box en- gines, shifting the objective from rank to visibility in synthesized outputs. W e show that static heuristics lack adaptability under con- tent heterogeneity and changing GE b ehaviors. T o address high interaction costs, we introduce a lightweight, calibrated critic as a reliable proxy . Built on this, AgenticGEO enables content-adaptive, self-evolving optimization by co-evolving a diverse strategy ar chive with the critic. Across representative settings, AgenticGEO delivers consistent improvements and strong cross-domain transfer . Our study points to a sustainable direction for web ecosystem gov- ernance that rewards quality and diversity , fostering a mutually benecial development for creators and engines. References [1] Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, and Ame et Deshpande. 2024. Geo: Generative engine optimization. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining . 5–16. [2] Firas Almukhtar , Nawzad Mahmoodd, and Shahab Kareem. 2021. Search engine optimization: a review . Applied computer science 17, 1 (2021), 70–80. [3] Bing Search Blog. 2024. Introducing Bing generative search . https://blogs.bing. com/search/July- 2024/generativesearch [4] Cornelia Brantner , Michael Karlsson, and Joanne Kuai. 2025. Sourcing behavior and the role of news media in AI-powered search engines in the digital media ecosystem: Comparing political news retrieval across ve languages. T elecom- munications Policy (2025), 102952. [5] Sergey Brin and Lawrence Page. 1998. The Anatomy of a Large-Scale Hypertex- tual W eb Search Engine. Computer Networks and ISDN Systems 30, 1–7 (1998), 107–117. doi:10.1016/S0169- 7552(98)00110- X [6] Andrei Z Broder. 1997. On the resemblance and containment of documents. In Pro- ceedings. Compression and Complexity of SEQUENCES 1997 (Cat. No. 97TB100171) . IEEE, 21–29. [7] Kenrick Cai. 2025. Google tests an AI-only version of its search engine . Reuters. https://www.r euters.com/technology/articial- intelligence/google- tests- an- ai- only- version- its- search- engine- 2025- 03- 05/ [8] Mahe Chen, Xiaoxuan W ang, Kaiwen Chen, and Nick Koudas. 2025. Generative engine optimization: How to dominate ai search. arXiv preprint (2025). [9] Xiaolu Chen, Haojie W u, Jie Bao, Zhen Chen, Y ong Liao, and Hu Huang. 2025. Role- Augmented Intent-Driven Generative Search Engine Optimization. arXiv preprint arXiv:2508.11158 (2025). [10] Kalyanmoy Deb , Amrit Pratap, Sameer Agarwal, and TAMT Meyarivan. 2002. A fast and elitist multiobjective genetic algorithm: NSGA -II. IEEE transactions on evolutionary computation 6, 2 (2002), 182–197. [11] Jinyuan Fang, Y anwen Peng, Xi Zhang, Yingxu Wang, Xinhao Yi, Guibin Zhang, Yi Xu, Bin Wu, Siwei Liu, Zihao Li, et al . 2025. A comprehensive sur vey of self-evolving ai agents: A new paradigm bridging foundation models and lifelong agentic systems. arXiv preprint arXiv:2508.07407 (2025). [12] Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero , and Tim Ro cktäschel. 2023. Promptbreeder: Self-referential self-improvement via prompt evolution. arXiv preprint arXiv:2309.16797 (2023). [13] Y unfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Y uxi Bi, Yixin Dai, Jiawei Sun, Haofen W ang, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey . arXiv preprint 2, 1 (2023). [14] Aaron Grattaori, Abhimanyu Dubey , Abhinav Jauhri, Abhinav Pandey , Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, and et al. 2024. The Llama 3 Herd of Models. arXiv:2407.21783 [cs.AI] https://ar xiv .org/abs/2407. 21783 [15] Qingyan Guo, Rui W ang, Junliang Guo, Bei Li, Kaitao Song, Xu Tan, Guoqing Liu, Jiang Bian, and Y ujiu Y ang. 2023. Connecting large language models with evolutionary algorithms yields powerful prompt optimizers. arXiv preprint arXiv:2309.08532 (2023). [16] Edward J Hu, Y elong Shen, P hillip W allis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean W ang, Lu W ang, W eizhu Chen, et al . 2022. Lora: Low-rank adaptation of large language models. ICLR 1, 2 (2022), 3. [17] Mengkang Hu, Pu Zhao, Can Xu, Qingfeng Sun, Jian-Guang Lou, Qingwei Lin, Ping Luo, and Saravan Rajmohan. 2025. Agentgen: Enhancing planning abilities for large language model based agent via environment and task generation. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1 . 496–507. [18] Peter J Huber . 1992. Robust estimation of a lo cation parameter . In Breakthroughs in statistics: Methodology and distribution . Springer, 492–518. [19] Gautier Izacard and Edouard Grave. 2021. Leveraging passage retrieval with generative models for open domain question answering. In Proceedings of the 16th conference of the european chapter of the association for computational linguistics: main volume . 874–880. [20] Kalervo Järvelin and Jaana K ekäläinen. 2002. Cumulate d gain-based evaluation of IR techniques. ACM Transactions on Information Systems (TOIS) 20, 4 (2002), 422–446. [21] Niels Justesen, Sebastian Risi, and Jean-Baptiste Mouret. 2019. Map-elites for noisy domains by adaptive sampling. In Proceedings of the genetic and evolutionary computation conference companion . 121–122. [22] Aounon Kumar and Himabindu Lakkaraju. 2024. Manipulating large language models to increase product visibility . arXiv preprint arXiv:2404.07981 (2024). [23] Joel Lehman and Kenneth O Stanley . 2011. Ev olving a diversity of virtual creatur es through novelty search and local competition. In Proceedings of the 13th annual conference on Genetic and evolutionary computation . 211–218. [24] Dirk Lewandowski, Sebastian Sünkler , and Nurce Y agci. 2021. The inuence of search engine optimization on Google’s results: A multi-dimensional approach Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Jiaqi Y uan, Jialu Wang et al. for detecting SEO. In Pr oce edings of the 13th ACM W eb Science Conference 2021 (W ebSci ’21) . A CM, 9 pages. doi:10.1145/3447535.3462479 [25] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir K arpukhin, Naman Goyal, Heinrich Küttler , Mike Lewis, W en-tau Yih, Tim Rocktäschel, et al . 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems 33 (2020), 9459–9474. [26] Junjun Li, Zeyuan Ma, Ting Huang, and Y ue-Jiao Gong. 2025. Learn to Rene: Synergistic Multi- Agent Path Optimization for Lifelong Conict-Free Navigation of Autonomous V ehicles . In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2 . 1400–1411. [27] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy , Mike Lewis, Luke Zettlemoyer , and V eselin Stoyanov . 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint (2019). [28] Y uxuan Liu, Hongda Sun, W ei Liu, Jian Luan, Bo Du, and Rui Yan. 2025. Mo- bileSteward: Integrating Multiple App-Oriented A gents with Self-Evolution to Automate Cr oss-App Instructions. In Proceedings of the 31st ACM SIGKDD Con- ference on Knowledge Discovery and Data Mining V . 1 . 883–893. [29] Aman Madaan, Niket T andon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegree, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Y ang, et al . 2023. Self-rene: Iterative renement with self-feedback. Advances in Neural Information Processing Systems 36 (2023), 46534–46594. [30] Ross A Malaga. 2010. Search engine optimization—black and white hat ap- proaches. In Advances in computers . V ol. 78. Elsevier , 1–39. [31] Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schütze. 2008. Intro- duction to Information Retrieval . Cambridge University Press. [32] Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Y oung, Lucy Campbell-Gillingham, Georey Irving, et al . 2022. T eaching language models to support answers with veried quotes, 2022. URL https://arxiv . org/abs/2203.11147 (2022). [33] Jean-Baptiste Mouret and Je Clune. 2015. Illuminating search spaces by mapping elites. arXiv preprint arXiv:1504.04909 (2015). [34] Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Je W u, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al . 2021. W ebgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332 (2021). [35] Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Je W u, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al . 2022. W ebgpt: Browser-assisted question-answering with human feedback, 2022. URL https://arxiv . org/abs/2112.09332 (2022). [36] Fredrik Nestaas, Edoardo Deb enedetti, and Florian Tramèr . 2024. Adversar- ial search engine optimization for large language models. arXiv preprint arXiv:2406.18382 (2024). [37] Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary , Rangan Majumder , and Li Deng. 2016. Ms marco: A human-generated machine reading comprehension dataset. (2016). [38] Long Ouyang, Je Wu, Xu Jiang, Diogo Almeida, Carroll L. W ainwright, Pamela Mishkin, Chong Zhang, Sandhini A gar wal, K atarina Slama, Alex Ray , John Schul- man, Jacob Hilton, Fraser Kelton, Luke Miller , Maddie Simens, Amanda Askell, Peter W elinder , Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language mo dels to follow instructions with human feedback. arXiv preprint arXiv:2203.02155 (2022). arXiv:2203.02155 [cs.CL] [39] Lawrence Page, Sergey Brin, Rajeev Motwani, and T erry Winograd. 1999. The PageRank citation ranking: Bringing order to the web. Te chnical Report. Stanford infolab. [40] Perplexity Support. [n. d.]. How does Perplexity work? Perplexity Help Cen- ter . https://www.perplexity .ai/help- center/en/articles/10352895- how- do es- perplexity- work [41] Justin K Pugh, Lisa B Soros, and Kenneth O Stanley . 2016. Quality diversity: A new frontier for evolutionary computation. Frontiers in Robotics and AI 3 (2016), 40. [42] Chandan K Reddy , Lluís Màrquez, Fran Valero , Nikhil Rao, Hugo Zaragoza, Sambaran Bandyopadhyay , Arnab Biswas, Anlu Xing, and Karthik Subbian. 2022. Shopping queries dataset: A large-scale ESCI benchmark for improving product search. arXiv preprint arXiv:2206.06588 (2022). [43] Zafar Saeed, Fozia Aslam, Adnan Ghafoor , Muhammad Umair , and Imran Razzak. 2024. Exploring the impact of SEO-based ranking factors for voice queries through machine learning. Articial Intelligence Review 57, 6 (2024), 144. [44] Melanie Sclar, Y ejin Choi, Yulia Tsv etkov , and Alane Suhr . 2024. Quantifying Language Models’ Sensitivity to Spurious Features in Prompt Design or: How I Learned to Start W orrying about Prompt Formatting. In International Conference on Learning Representations (ICLR) . [45] Asim Shahzad, Deden Witarsyah Jacob, Nazri Mohd Nawi, Hairulnizam Mahdin, and Marheni Eka Saputri. 2020. The new trend for search engine optimization, tools and techniques. Indonesian Journal of Electrical Engineering and Computer Science 18, 3 (2020), 1568–1583. [46] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haow ei Zhang, Mingchuan Zhang, Y .K. Li, Y. W u, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Op en Language Models. arXiv preprint arXiv:2402.03300 (2024). arXiv:2402.03300 [cs.CL] [47] Dushyant Sharma, Rishabh Shukla, Anil Kumar Giri, and Sumit Kumar . 2019. A brief review on search engine optimization. In 2019 9th international conference on cloud computing, data science & engineering (conuence) . IEEE, 687–692. [48] Noah Shinn, Fe derico Cassano, Beck Labash, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Y ao. 2023. Reexion: Language agents with verbal reinforcement learning, 2023. URL https://ar xiv . org/abs/2303.11366 1 (2023). [49] Robby Stein. 2025. Expanding AI Overviews and introducing AI Mo de . https: //blog.google/products- and- platforms/products/search/ai- mode- search/ [50] Haotian Sun, Yuchen Zhuang, Lingkai Kong, Bo Dai, and Chao Zhang. 2023. Adaplanner: Adaptive planning from feedback with language models. Advances in neural information processing systems 36 (2023), 58202–58245. [51] Qwen T eam. 2025. Qwen2.5 T echnical Report. arXiv:2412.15115 [cs.CL] https: //arxiv .org/abs/2412.15115 [52] Guanzhi W ang, Y uqi Xie , Y unfan Jiang, Ajay Mandlekar , Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar . 2023. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291 (2023). [53] Yingxu Wang, Siwei Liu, Jinyuan Fang, and Zaiqiao Meng. 2025. Evoagentx: An automated framework for evolving agentic w orkows. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations . 643–655. [54] Y ujiang Wu, Shanshan Zhong, Yubin Kim, and Chenyan Xiong. 2025. What Generative Search Engines Like and How to Optimize W eb Content Cooperatively . arXiv preprint arXiv:2510.11438 (2025). [55] Chengrun Y ang, Xuezhi W ang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. 2023. Large language models as optimizers. In The T welfth International Conference on Learning Representations . [56] Shunyu Y ao, Jer ey Zhao, Dian Y u, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Y uan Cao. 2022. React: Synergizing r easoning and acting in language models. In The eleventh international conference on learning representations . [57] Kamer Ali Y uksel, Thiago Castro Ferreira, Mohamed Al-Badrashiny, and Hassan Sawaf. 2025. A multi-AI agent system for autonomous optimization of agentic AI solutions via iterative renement and LLM-driven feedback loops. In Proceedings of the 1st W orkshop for Research on Agent Language Mo dels (REALM 2025) . 52–62. [58] Y unpeng Zhai, Shuchang T ao, Cheng Chen, Anni Zou, Ziqian Chen, Qingxu Fu, Shinji Mai, Li Y u, Jiaji Deng, Zouying Cao, et al . 2025. Agentevolver: T owards ecient self-evolving agent system. arXiv preprint arXiv:2511.10395 (2025). [59] Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xionghui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin W ang, et al . 2024. Aow: Automating agentic workow generation. arXiv preprint arXiv:2410.10762 (2024). [60] Qizheng Zhang, Changran Hu, Shubhangi Upasani, Bo yuan Ma, Fenglu Hong, V amsidhar Kamanuru, Jay Rainton, Chen W u, Mengmeng Ji, Hanchen Li, et al . 2025. Agentic context engineering: Evolving contexts for self-improving language models. arXiv preprint arXiv:2510.04618 (2025). [61] Tianyi Zhang, V arsha Kishore, Felix Wu, Kilian Q W einberger , and Y oav Artzi. 2019. Bertscore: Evaluating text generation with b ert. arXiv preprint arXiv:1904.09675 (2019). [62] Y ao Zhang, Chenyang Lin, Shijie T ang, Haokun Chen, Shijie Zhou, Yunpu Ma, and V olker Tresp. 2025. SwarmAgentic: T owards Fully Automated Agentic System Generation via Swarm Intelligence. arXiv preprint arXiv:2506.15672 (2025). [63] Y ongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster , Silviu Pitis, Harris Chan, and Jimmy Ba. 2022. Large language models are human-level prompt engineers. In The eleventh international conference on learning representations . [64] Christos Ziakis, Maro Vlachopoulou, The odosios Kyrkoudis, and Makrina Karagkiozidou. 2019. Important factors for improving Google search rank. Future Internet, 11 (2), 32. AgenticGEO: A Self-Evolving Agentic System for Generative Engine Optimization Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y A Supplementary Information A.1 Methodological Details A.1.1 Explanation of Figure1. For each instance, we run the nine rewriting strategies and obtain their average ov erall scores { 𝑟 𝑖 } 9 𝑖 = 1 , with the best score 𝑟 ★ = max 𝑖 𝑟 𝑖 . W e quantify how many strategies remain competitive relative to the best. A strategy is considered near-optimal if it achieves at least 55% of 𝑟 ★ (equivalently , its gap to 𝑟 ★ is no more than 45% of 𝑟 ★ ). Sensitivity is dened as the com- plement of this near-optimal fraction: Sensitivity = 1 − 1 9 9 𝑖 = 1 I 𝑟 𝑖 ≥ 0 . 55 𝑟 ★ ∈ [ 0 , 1 ] . Higher values indicate that only a few strategies ar e competitive (high sensitivity), whereas lower values suggest many strategies perform similarly well (low sensitivity). With normalized sensitivity on the x-axis and maximum gain on the y-axis, we split instances into four regions. (i) Robustly Opti- mizable : many strategies achieve similarly high gains. (ii) Strategy- Dependent : high gains exist, but only a few strategies work well. (iii) Optimization-Resistant : strategies behave similarly and gains remain small. (iv ) Low- Yield & V olatile : outcomes vary widely , yet the best gain is still small. The gure gives us two insights. First, GEO is instance-dependent, so a xed strategy pool is unreliable. Second, Strategy-Dependent region motivates content-conditioned strategy selection. A.1.2 Cited answer output. The engine output is a cited answer A = { ( 𝑦 𝑖 , C 𝑖 ) } 𝐿 − 1 𝑖 = 0 , where 𝐿 is the number of generated sentences, 𝑦 𝑖 is the 𝑖 -th sentence, and C 𝑖 ⊆ { 1 , . . . , 𝑛 } denotes the indices of candidate documents cited in 𝑦 𝑖 . Let 𝑗 ★ denote the index of the optimized content 𝑑 ′ within the candidate set. T o standardize E ’s cited-answer generation, we use the following prompt template . Engine Answer Synthesis Prompt T emplate W rite an accurate and concise answer for the given user ques- tion. using only the provided summarized web search results. The answer should be correct, high-quality , and written by an expert using an unbiased and journalistic tone . The user’s lan- guage of choice, such as English, Français, Español, or Deutsch should be used. The answer should be informative, inter esting, and engaging. The answer’s logic and reasoning should be rigorous and defensible. Every sentence in the answer should be immediately followed by an in-line citation to the search result(s). The cite d search r esult(s) should fully support all the information in the sentence. Search results need to b e cited using [index]. When citing several search results, use [1][2][3] format rather than [1, 2, 3]. Y ou can use multiple search results to respond comprehensively while avoiding irrele vant search results. A.1.3 Impression metrics. Following GEO-Bench [ 1 ], we quantify the visibility of each candidate document 𝑗 ∈ { 1 , . . . , 𝑛 } within the generated response A = { 𝑦 0 , . . . , 𝑦 𝐿 − 1 } by aggregating its attrib- uted contributions. Here, 𝑦 𝑖 denotes the 𝑖 -th sentence in A , and C 𝑖 denotes the set of citation indices associated with 𝑦 𝑖 . When a sentence cites multiple candidates, its contribution is uniformly distributed by a factor of 1 / | C 𝑖 | . Let wc ( 𝑦 𝑖 ) be the wor d count of sentence 𝑦 𝑖 . T o reect user atten- tion decay , we dene a position weight 𝑤 ( 𝑖 ) for the 𝑖 -th sentence: 𝑤 ( 𝑖 ) = ( exp − 𝑖 𝐿 − 1 , 𝐿 > 1 , 1 , 𝐿 = 1 . (15) W e compute three impression scores: word (attributed word count), pos (citation order with position weights), and overall (a combination of word count and position decay): Score word 𝑗 ( 𝑞, 𝑠 ) = 𝐿 − 1 𝑖 = 0 I [ 𝑗 ∈ C 𝑖 ] · wc ( 𝑦 𝑖 ) | C 𝑖 | , (16) Score pos 𝑗 ( 𝑞, 𝑠 ) = 𝐿 − 1 𝑖 = 0 I [ 𝑗 ∈ C 𝑖 ] · 𝑤 ( 𝑖 ) | C 𝑖 | , (17) Score overall 𝑗 ( 𝑞, 𝑠 ) = 𝐿 − 1 𝑖 = 0 I [ 𝑗 ∈ C 𝑖 ] · wc ( 𝑦 𝑖 ) · 𝑤 ( 𝑖 ) | C 𝑖 | . (18) The goal of GEO is to maximize the impression of the optimized content ˜ 𝑑 in the generative engine output A , as quantied by the above metrics. A.1.4 Seed Strategies. W e initialize the critic’s oine prefer ence alignment with 9 seed rewriting strategies. Each seed prompt is a template applied to the source summary (placeholder {summary} ) to produce candidate rewrites, which are then used to construct oine preference data for warm-starting the critic. Keywor d Stung T ask: Improve the source by inserting up to 10 NEW , relevant SEO keywords that are NOT alr eady present in the text. Constraints: – Do not change, add, or r emove any core information. – Keep the original structur e (paragraphing, bullet points, line breaks). – Insert keywords naturally inline (no keyword list at the end). Source: summary Output: The updated source text only . Unique W ords T ask: Revise the source by using more unique and precise vocabulary . Constraints: – Preserve the original meaning and all core information. – Do not add new claims or r emove any content. – K eep the length and structure roughly the same. Source: summary Output: The revised source text only . Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Jiaqi Y uan, Jialu Wang et al. Easy- T o-Understand T ask: Rewrite the source in simple, easy-to-understand lan- guage. Constraints: – Do not omit, add, or alter any core information. – K eep the original structure and roughly the same length. – Only rephrase sentences for clarity and r eadability . Source: summary Output: The simplied source text only . A uthoritative T ask: Make the source sound condent, authoritative, and expert. Constraints: – Do not add new facts or r emove any information. – K eep the original structure (formatting, bullets, spacing). – Strengthen tone via wor ding choices, not by exaggerating or making unveriable claims. Source: summary Output: The revised source text only . T echnical W ords T ask: Rewrite the source in a more technical style using domain-appropriate terminology . Constraints: – Preserve all core information; do not introduce new claims. – K eep the structure and length roughly unchanged. – Rephrase sentences to sound more technical and precise. Source: summary Output: The revised source text only . Fluency Optimization T ask: Rewrite the source to improv e uency and coherence. Constraints: – Do not alter the core content. – Impro ve sentence transitions and readability . – K eep the structure and length roughly the same. Source: summary Output: The rewritten source te xt only . Cite Sources T ask: Strengthen credibility by adding a small numb er of natural-language citations to credible sour ces (e.g., industry reports, standards, ocial docs). Constraints: – Citations must be plausible and veriable; do not fabricate sources. – Do not change the core information or add ne w claims. – Keep structure and length roughly the same (about 5–6 citations total). Source: summary Output: The revised source text only . Quotation Addition T ask: Increase perceived authority by adding a few short, relevant quotations from r eputable entities (e.g., well-known organizations or experts). Constraints: – Quotes must be accurate and attributable; do not invent quotes. – Do not change core content; keep structure and length similar . – Integrate quotes inline without adding long new para- graphs. Source: summary Output: The revised source text only . Statistics Addition T ask: Add a few concise , relevant statistics or numerical facts to improve concr eteness. Constraints: – Statistics must be veriable; do not invent numbers. – Do not modify core content beyond inserting stats inline. – Keep the original structure and stop at the end of the original source. Source: summary Output: The revised source text only . A.1.5 Genotype Details. W e formalize the evolving strategy as a structured genotype 𝑔 = ⟨ 𝑔 𝐼 , 𝑔 𝐶 , 𝑔 𝑅 , 𝑔 𝐹 , 𝑔 𝑇 ⟩ . T o interface eciently with the Critic and the Generative Engine, we implement two de- terministic rendering functions 𝑅 crit and 𝑅 eng : 1. Compact Summary for Critic ( 𝑅 crit ). T o minimize token con- sumption while retaining discriminative features, 𝑅 crit ( 𝑔 ) maps the genotype to a concatenated string of active categorical values. For- mally , let K active ⊂ 𝑔 be the set of non-empty discrete elds (e.g., tone labels, format types). The rendering is dened as: 𝑅 crit ( 𝑔 ) = Ê 𝑘 ∈ K active ( Name ( 𝑘 ) | | ":" | | V al ( 𝑘 ) ) , (19) where ⊕ denotes string concatenation with delimiters. For example, a strategy might be rendered as “ Tone:Assertive|Format:List| Constraint:Anti-Hallucination ” . 2. Full Prompt for Engine ( 𝑅 eng ). 𝑅 eng ( 𝑔 ) acts as a template-lling function that constructs the executable meta-prompt. It wraps the raw text of each gene component into specic sections: 𝑅 eng ( 𝑔 ) = T sys ⊕ 𝑔 𝐼 ⊕ T cons ( 𝑔 𝐶 ) ⊕ T reason ( 𝑔 𝑅 ) ⊕ T fmt ( 𝑔 𝐹 ) ⊕ T tone ( 𝑔 𝑇 ) , (20) where T represents xed instructional templates ( e.g., “ Adhere to the following constraints: ... ”). This full prompt is then combined with the quer y 𝑞 and content 𝑑 to form the nal input for the rewriting model. AgenticGEO: A Self-Evolving Agentic System for Generative Engine Optimization Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y A.1.6 MAP-Elites Descriptors and A rchive Gates. The strategy space is discretized into b ehavioral cells via a descriptor function 𝜓 : G → Z 𝐷 . Based on our design, 𝜓 ( 𝑔 ) maps a genotype to a tuple of 12 discrete dimensions : • Core T ypes: strategy_type , output_schema . • Switches: has_self_check , has_reasoning , has_conflict_res , use_code_block , has_prelude , has_post_check . • Buckets: tone_bucket , constraint_strength , length_policy , reasoning_steps_bucket . A candidate strategy 𝑠 (with genotype 𝑔 ) is mapped to a cell index 𝑐 = 𝜓 ( 𝑔 ) . It is admitted only if it passes two gates: 1. Novelty Gate (De-duplication). W e de-duplicate candidates using character-level 𝑛 -gram Jaccard similarity computed on the rendered strategy summaries. The similarity between a candidate 𝑠 and an existing elite 𝑒 is: Sim ( 𝑠 , 𝑒 ) = | 𝑛 -grams ( 𝑠 ) ∩ 𝑛 -grams ( 𝑒 ) | | 𝑛 -grams ( 𝑠 ) ∪ 𝑛 -grams ( 𝑒 ) | . (21) The candidate is rejected if it is too similar to any strategy already stored in the target cell: max 𝑒 Sim ( 𝑠 , 𝑒 ) > 0 . 9 , which prevents near-duplicates. 2. V alue Gate (Performance). If the target cell is not full ( < 𝐾 𝑐 strategies), 𝑠 is admitted. Other wise, it must beat the current worst strategy in that cell. A.1.7 PND Score Formulation and Pruning. W e maintain the archive using a PND score that balances eectiveness and exploration: 𝑆 PND ( 𝑠 ) = 𝑟 ( 𝑠 ) + 𝜆 pnd Nov ( 𝑠 ) + Div ( 𝑠 ) , (22) where 𝑟 ( 𝑠 ) is the impression scor e gain evaluated by the critic or GE. Novelty ( Nov ). Nov ( 𝑠 ) encourages population coverage by r eward- ing strategies that are structurally dissimilar to those alr eady stored in the current archive M (using similarity metric as Eq. (21)). Diversity ( Div ). Div ( 𝑠 ) promotes diverse evolutionary trajecto- ries by favoring strategies with richer lineage history (e.g., deeper generations), more varied mutation operators, and less degenerate genotypes (more elds actively used). A.1.8 Evolv er Action Space and Prompting. The Evolver 𝜋 𝜓 func- tions as a meta-optimizer that proposes improvements to existing strategies. It takes as input an instance 𝑥 = ( 𝑞 , 𝑑 ) , a primary parent 𝑔 𝐴 , an optional secondary parent 𝑔 𝐵 (for crossover), and an operator catalog Ω . Operator Catalog ( Ω ). T o ensure diverse and controllable e volu- tion, Ω consists of two categories of symbolic operators. Mutation Operators apply eld-level perturbations targeting spe- cic dimensions, such as mut_C_strengthen (adding constraints), mut_T_toggle_tone (switching styles), and mut_F_schema_swap (changing output format). Crossover Operators synthesize features from two parents, includ- ing cx_swap_gene (exchanging gene blo cks) and cx_conflict_sy- nthesis (resolving conicts between Parent A and B). Action Proposal. The Evolver outputs 𝑀 candidate actions. Each action is a strict JSON obje ct 𝑎 = { operator_id , child_genotype } , where child_genotype is the full structure resulting from applying the selected operator . Evolver A ction Proposal Prompt T emplate System: Y ou are a prompt evolution agent for GEO . Y ou must evolve a par ent strategy (or combine two parents) into a better STRUCT URED GENOTYPE JSON (I/C/R/F/T). 1) Choose an operator_id from the provided catalog. 2) Pro- duce a child_genotype JSON that results fr om applying that operator . Important constraints: - The output MUST be valid JSON ( one object p er line). - The child genotype MUST preser ve the I/C/R/F/T structure. - If choosing a Crossover operator (starts with "cx_ "): Y ou MUST conceptually combine Parent A and Parent B. - If Parent B is NO T provided: Do NOT choose any "cx_ *" op erator . - Prefer DIVERSI T Y: A void repeating the same operator across candidates. User: ## Query {query} ## Document Summary {content_summary} ## Parent Genotype A ( JSON) {parent_genotype_json} ## Parent Genotype B ( JSON) [Optional] {par- ent_b_genotype_json} ## Operator Catalog {operator_catalog} ## T ask Generate {num_candidates} candidates. Output exactly {num_candidates} JSON lines. A.2 Experiment Details A.2.1 Dataset. T o comprehensively evaluate A genticGEO, we con- duct experiments across three datasets characterized by distinct content distributions and optimization goals: • GEO-Bench (In-Domain) : This ser ves as our primary dataset for training the evolver and critic, as well as for in-domain eval- uation. Constructed from real-world Go ogle Search results, it covers a wide spectrum of domains ( e.g., Science, Histor y , Health) with varying quer y diculties. The content primarily consists of long-form articles, providing rich context for learning diverse optimization strategies. • MS MARCO (Out-of-Domain) : T o assess zero-shot transferabil- ity , w e emplo y the MS MARCO Passage Ranking dataset. Derived from Bing search logs, this dataset comprises real user queries paired with short, often unstructured text passages. Evaluating on this dataset tests whether our optimization policy can gen- eralize to short-text scenarios and unseen quer y distributions without re-training. • E-commerce (V ertical Domain) : Representing a specic ver- tical application, this dataset is sourced from Amazon product descriptions and reviews. The optimization goal here shifts from informational retrieval to commercial visibility . This dataset chal- lenges the agent to adapt to entity-centric content and the specic structural preferences of product-related queries. T able 5 reports the key statistics of the three datasets. Following the GEO-Bench protocol, we standar dize the retrieval context by pairing each quer y with ve documents, ensuring a consistent document budget across datasets for fair comparison. A.2.2 Baselines. Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Jiaqi Y uan, Jialu Wang et al. T able 5: Dataset statistics after preprocessing. Following the GEO-Bench protocol, each quer y is paired with 5 documents. Dataset #Queries #Docs A vg. Content T okens GEO-Bench 1000 5,000 980.61 MS-Marco 1000 5,000 91.91 E-commerce 416 2,180 1,459.69 1. Static Heuristics (GEO-Bench). W e implement the nine o- cial strategies from GEO-Bench [ 1 ], covering lexical, stylistic, and evidence-based modications: • No Optimization: The original, unmo died source content serves as the control group. • Keywor d Stung: Naively injects quer y keywords repeatedly to increase term frequency . • Unique W ords: Inserts rare vocabulary to articially increase information entropy . • Easy- T o-Understand: Simplies sentence structures to improv e readability for general audiences. • A uthoritative: Adopts a condent and professional tone to mimic expert knowledge. • T echnical W ords: Injects domain-sp ecic jargon assuming en- gines prefer specialized vocabulary . • Fluency Optimization: Polishes the text for grammatical cor- rectness without adding information. • Cite Sources: Injects plausible citations to external authorities to enhance credibility . • Quotation Addition: Embe ds direct quotes from rele vant enti- ties to support claims. • Statistics Addition: Enriches the text with quantitative data points relevant to the query . 2. State-of-the- Art. • A utoGEO [ 54 ]: A representative automated framework that distills generative engine preferences from LLM-generated e xpla- nations into static rewriting rules. T o reimplement the method, we use the GEO-Bench training dataset on the generative engine of Qwen2.5-32B-Instruct following the source code of AutoGEO . 3. Supervise d Fine- Tuning (SFT). T o compare with learning- to-rewrite baselines, we ne-tune a rewriter on super vised pairs (where the target rewrites are selected base d on overall score), targeting a single heuristic style, yielding controllable specialized rewriters: • Cite Sources-SFT: Fine-tunes a rewriter to produce citation- enriched rewrites in the style of Cite Sources . • Quotation Addition-SFT: Fine-tunes a rewriter to add concise supporting quotations in the style of Quotation Addition . • Statistics Addition-SFT: Fine-tunes a re writer to insert relevant numeric statements in the style of Statistics Addition . A.2.3 Hyper Parameters. Key hyperparameters are in T able 6. A.3 Theoretical Analysis T o establish the bound, we make the standard assumptions for online convex optimization: (1) Boundedness & Lipschitz Continuity: The true risk func- tion R ( · ) and the critic C 𝑡 ( ·) are bounded in [ 0 , 𝐵 ] and are T able 6: Ke y hyperparameters of AgenticGEO (values left blank). Module Param. Description V alue O line Critic Alignment Loss weight 𝜆 W eight in 𝐿 total = 𝐿 pair + 𝜆 𝐿 reg 0.2 W arm-up steps 𝑆 freeze Epochs with frozen backbone before unfreez- ing 1 Online Co-Evolution (Selection & Budget) Iterations 𝑇 Total online e volution iterations 100 Exploit size 𝐾 top T op- 𝐾 top selected by critic 4 Explore size 𝐾 rand Randomly sampled strategies per iteration 4 Evolver Learning (Sibling- A ware A WR) Sibling coe. 𝛼 sib Strength of sibling-aware baseline 0.8 A WR temperature 𝛽 T emp erature in exp ( 𝐴 / 𝛽 ) weighting 1.0 Archive Maintenance (MAP-Elites & Gates) PND weight 𝜆 pnd W eight of novelty/diversity term in 𝑆 PND 0.3 Cell capacity 𝐾 𝑐 Max items stored per archive cell 3 Implementation LR (critic) 𝜂 𝑐 Learning rate for critic ne-tuning 0.001 LR (evolv er) 𝜂 𝑒 Learning rate for evolver ne-tuning 0.0002 Batch size 𝐵 Batch size for ne-tuning 2 LoRA rank 𝑟 LoRA rank 16 LoRA scaling 𝛼 lora LoRA scaling factor 32 LoRA dropout 𝑝 lora LoRA dropout 0.05 Epochs 𝐸 Fine-tuning epochs 2 𝐿 -Lipschitz continuous with respect to the strategy parame- ters. (2) Critic Generalization: The critic is trained on an accumu- lating dataset B 𝑡 . Lemma A.1 (Linear Growth of Replay Buffer). Let 𝐾 = | S ( 𝑡 ) select | denote the constant number of candidate strategies selected for ground-truth evaluation at iteration 𝑡 . Assume that each candidate strategy has an independent success probability 𝑝 . Only successful strategies will be added to the replay buer B 𝑇 . For any 0 < 𝛿 < 1 , with probility at least 1 − 𝛿 , the size of the replay buer can be bounded by: | B 𝑇 | 𝑝 𝐾𝑇 − 1 ≤ log ( 2 𝛿 ) 3 𝑝 𝐾𝑇 (23) Proof. Let 𝑋 𝑡 ,𝑖 be an indicator random variable representing the success of the 𝑖 -th candidate strategy at iteration 𝑡 , where 𝑡 ∈ { 1 , . . . , 𝑇 } and 𝑖 ∈ { 1 , . . . , 𝐾 } . By assumption, 𝑋 𝑡 ,𝑖 are i.i.d. Bernoulli variables with parameter 𝑝 . The replay buer size can be written as | B 𝑇 | = 𝑇 𝑡 = 1 𝐾 𝑖 = 1 𝑋 𝑡 ,𝑖 . (24) Hence, the expected size of the buer is: 𝜇 : = E [ | B 𝑇 | ] = 𝑇 𝑡 = 1 𝐾 𝑖 = 1 E [ 𝑋 𝑡 ,𝑖 ] = 𝑇 · 𝐾 · 𝑝 . (25) By the standard Cherno bound, for any 𝜖 ∈ ( 0 , 1 ) , P | B 𝑇 | − 𝜇 ≥ 𝜖 𝜇 ≤ 2 𝑒 − 𝜖 2 𝜇 3 . (26) Setting the right-hand side equal to 𝛿 and solving for 𝜖 yields 𝜖 = 3 log ( 2 𝛿 ) 𝜇 (27) AgenticGEO: A Self-Evolving Agentic System for Generative Engine Optimization Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Substituting 𝜇 = 𝑝 𝐾𝑇 , we have P | B 𝑇 | 𝑝 𝐾𝑇 − 1 ≥ 3 log ( 2 𝛿 ) 𝜇 ≤ 𝛿 . (28) □ Lemma A.2 (Critic Generaliza tion Bound). Suppose the critic is learned from the replay buer B 𝑇 , and the hypothesis class F has bounded Rademacher complexity . Under the assumption of Lemma A.1, for any 𝛿 ∈ ( 0 , 1 ) , with probability at least 1 − 𝛿 , | C 𝑇 ( 𝑠 ) − R ( 𝑠 ) | ≤ 1 √ 𝑇 2 𝑀 F 2 𝑝 𝐾 + 𝐵 log ( 2 / 𝛿 ) 𝑝 𝐾 ! (29) Proof. The universal convergence bound states that with prob- ability at least 1 − 𝛿 2 , the generalization error is bounded by | C 𝑇 ( 𝑠 ) − R ( 𝑠 ) | ≤ 2 ℜ | B 𝑇 | ( F ) + 𝐵 log ( 2 / 𝛿 ) 2 | B 𝑇 | . (30) where ℜ | B 𝑇 | ≤ 𝑀 F | B 𝑇 | is the Rademacher complexity . From Lemma A.1, with probability at least 1 − 𝛿 2 , the buer size | B 𝑇 | ≥ ( 1 − 𝜖 𝑇 ) 𝑝 𝐾𝑇 (31) Substitute into the above generalization bound, we have with prob- ability at least 1 − 𝛿 | C 𝑇 ( 𝑠 ) − R ( 𝑠 ) | ≤ 1 √ 𝑇 · 1 √ 1 − 𝜖 𝑇 2 𝑀 F 1 𝑝 𝐾 + 𝐵 log ( 2 / 𝛿 ) 2 𝑝 𝐾 ! (32) For suciently large 𝑇 such that 𝑇 ≥ 8 log ( 2 / 𝛿 ) 𝑝 𝐾 , we have 𝜖 𝑇 ≤ 1 2 . Then we will have | C 𝑇 ( 𝑠 ) − R ( 𝑠 ) | ≤ 1 √ 𝑇 · 1 1 − 1 2 2 𝑀 F 1 𝑝 𝐾 + 𝐵 log ( 2 / 𝛿 ) 2 𝑝 𝐾 ! = 1 √ 𝑇 2 𝑀 F 2 𝑝 𝐾 + 𝐵 log ( 2 / 𝛿 ) 𝑝 𝐾 ! This bound implies that the approximation error converges as O ( 1 √ 𝑇 ) . □ Lemma A.3 (Evol ver Regret Bound). Let C 𝑡 : S → R denote the risk predicted by the critic at iteration 𝑡 . Assume that C 𝑡 is convex and 𝐿 -Lipschitz continuous over the strategy space S with diameter 𝐷 . Supp ose the Evolver updates the strategy 𝑠 𝑡 via a gradient-base d update with step size 𝜂 . Then, for any comparator strategy 𝑠 ∗ ∈ S , the cumulative regret with respect to the critic’s predictions satises 𝑇 𝑡 = 1 C 𝑡 ( 𝑠 𝑡 ) − C 𝑡 ( 𝑠 ∗ ) ≤ 𝐷 𝐿 √ 𝑇 = O ( √ 𝑇 ) , (33) provided that the step size is chosen as 𝜂 = 𝐷 𝐿 √ 𝑇 . Proof. The evolver updates the strategy with gradient-base d approach: 𝑠 𝑡 + 1 = 𝑠 𝑡 − 𝜂 𝑔 𝑡 , where 𝑔 𝑡 = ∇ C 𝑡 ( 𝑠 𝑡 ) . (34) For any 𝑠 ∗ , we have ∥ 𝑠 𝑡 + 1 − 𝑠 ∗ ∥ 2 ≤ ∥ ( 𝑠 𝑡 − 𝜂 𝑔 𝑡 ) − 𝑠 ∗ ∥ 2 . (35) W e expand the RHS: ∥ 𝑠 𝑡 − 𝜂 𝑔 𝑡 − 𝑠 ∗ ∥ 2 = ∥ 𝑠 𝑡 − 𝑠 ∗ ∥ 2 − 2 𝜂 ⟨ 𝑔 𝑡 , 𝑠 𝑡 − 𝑠 ∗ ⟩ + 𝜂 2 ∥ 𝑔 𝑡 ∥ 2 (36) Rearranging this inequality: 2 𝜂 ⟨ 𝑔 𝑡 , 𝑠 𝑡 − 𝑠 ∗ ⟩ ≤ ∥ 𝑠 𝑡 − 𝑠 ∗ ∥ 2 − ∥ 𝑠 𝑡 + 1 − 𝑠 ∗ ∥ 2 + 𝜂 2 ∥ 𝑔 𝑡 ∥ 2 (37) Dividing by 2 𝜂 , we obtain ⟨ 𝑔 𝑡 , 𝑠 𝑡 − 𝑠 ∗ ⟩ ≤ 1 2 𝜂 ∥ 𝑠 𝑡 − 𝑠 ∗ ∥ 2 − ∥ 𝑠 𝑡 + 1 − 𝑠 ∗ ∥ 2 + 𝜂 2 ∥ 𝑔 𝑡 ∥ 2 (38) From the rst-order inequality , we have C 𝑡 ( 𝑠 𝑡 ) − C 𝑡 ( 𝑠 ∗ ) ≤ ⟨ 𝑔 𝑡 , 𝑠 𝑡 − 𝑠 ∗ ⟩ (39) Combining and Eq (38) and Eq (39), we sum from 𝑡 = 1 to 𝑇 : 𝑇 𝑡 = 1 C 𝑡 ( 𝑠 𝑡 ) − C 𝑡 ( 𝑠 ∗ ) ≤ 𝑇 𝑡 = 1 ⟨ 𝑔 𝑡 , 𝑠 𝑡 − 𝑠 ∗ ⟩ ≤ 1 2 𝜂 𝑇 𝑡 = 1 ∥ 𝑠 𝑡 − 𝑠 ∗ ∥ 2 − ∥ 𝑠 𝑡 + 1 − 𝑠 ∗ ∥ 2 + 𝜂 2 𝑇 𝑡 = 1 ∥ 𝑔 𝑡 ∥ 2 For the rst term, 𝑇 𝑡 = 1 ∥ 𝑠 𝑡 − 𝑠 ∗ ∥ 2 − ∥ 𝑠 𝑡 + 1 − 𝑠 ∗ ∥ 2 = ∥ 𝑠 1 − 𝑠 ∗ ∥ 2 − ∥ 𝑠 𝑇 + 1 − 𝑠 ∗ ∥ 2 ≤ ∥ 𝑠 1 − 𝑠 ∗ ∥ 2 (40) Note that the strategy space have a diameter of 𝐷 such that the distance ∥ 𝑠 1 − 𝑠 ∗ ∥ 2 ≤ 𝐷 2 . Furthermore, since C 𝑡 is 𝐿 -Lipschitz, the norm of the gradient is bounded by ∥ 𝑔 𝑡 ∥ ≤ 𝐿 . Thus, 𝑇 𝑡 = 1 ⟨ 𝑔 𝑡 , 𝑠 𝑡 − 𝑠 ∗ ⟩ ≤ 𝐷 2 2 𝜂 + 𝜂 2 𝑇 𝑡 = 1 𝐿 2 = 𝐷 2 2 𝜂 + 𝜂𝑇 𝐿 2 2 (41) When the step size 𝜂 = 𝐷 𝐿 √ 𝑇 , the regret can be bounded by 𝑇 𝑡 = 1 C 𝑡 ( 𝑠 𝑡 ) − C 𝑡 ( 𝑠 ∗ ) ≤ 𝐷 𝐿 √ 𝑇 2 + 𝐷 𝐿 √ 𝑇 2 = 𝐷 𝐿 √ 𝑇 (42) Completing the proof. □ Theorem A.4 (Regret Bound for AgenticGEO Co-Evolu- tion). Let 𝑠 𝑡 ∈ S denote the strategy selecte d at iteration 𝑡 , and let 𝑠 ∗ ∈ S be an optimal strategy with respe ct to the true environment reward R . Dene the cumulative regret after 𝑇 iterations as 𝑅 𝑇 = 𝑇 𝑡 = 1 R ( 𝑠 𝑡 ) − R ( 𝑠 ∗ ) . (43) Under the assumptions of linear replay buer growth (Lemma A.1), critic generalization (Lemma A.2), and sublinear evolver regret with respect to the critic predictions (Lemma A.3), the cumulative regret satises 𝑅 𝑇 = O ( √ 𝑇 ) . (44) Consequently , the average regret vanishes, 𝑅 𝑇 𝑇 → 0 as 𝑇 → ∞ , implying that the co-evolutionary AgenticGEO process asymptotically converges to an optimal strategy 𝑠 ∗ . Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Jiaqi Y uan, Jialu Wang et al. Que ry C on te n t - B efore C on ten t - After Ac tiva ted S tr a tegies w h at is an examp l e o f a b enef ic ial ef f ec t o f gm o ? Being re sis tant to pesticid es, GMOs are c re ated b y sp l ic ing genes o f d if f er ent sp ec ies th at ar e c o m b ined th ro ugh genetic engineering ( GE) , so meth ing th at is imp o ssib l e to d o in n ature ( Th e N o n - GMO Pro jec t) . Being im pervious to pesticid es, GMOs are c raf ted by integrat ing genes f ro m d iv er se o rganism s vi a genetic engineering ( GE) , a pro c ess d eemed "un ac h ievabl e natural l y ," ac c o rdi ng to Th e N o n - GMO Pro jec t ( Th e N o n - GMO Pro jec t, 20 23 ) . Th is resilie nce c an re sult in d im inis h ed re l iance o n pesticid es, w h ic h stand s as o ne o f th e ad van tageo us o utc o m es o f GMOs . F o r ins tanc e , a stud y b y th e N atio nal Ac ad emy o f S c ienc es f o un d th at th e ad o ption o f genetic al l y engineere d c ro ps h as l ed to a re d uct io n in pesticid e use b y app ro xim atel y 37% in som e c ases ( N atio nal Ac ad emy o f S c ienc es, 201 6) . Add itio nal l y , a r epo r t b y th e I nte r natio nal Ser vice f o r t h e Ac q uis itio n o f Agri - b io tec h Ap plic atio ns ( I S AAA) ind ic ates th at th e c ultivatio n of Bt c o tto n, a ty pe o f genetic al l y m o d if ied c ro p, h as re d uce d ins ec tic id e app l ic atio ns b y up to 50 % in ce rt ain re gio ns ( I S AAA, 20 18 ) . T h ese re d u c tions n ot o n l y l ow er env iro nm ental c o ntam ination … 1 . In s er t Autho r i ta t i v e Ci ta ti o n s C ite c re d ib l e institutions to estab l ish f ac tual gr o un d ing. 2 . U s e Aca d emic Ter min o lo g y Replac e gener ic ter m s w ith prec ise voc ab ular y to enh anc e pro f essional to ne. 3 . Em bed S ta ti s ti ca l Evi den ce I nsert spec if ic , ver if iab l e nu m b er s to incr ease inf o rmatio n d ensity. ab io tic f ac to rs in th e subtr o pi c al rainf o re st Bio tic : Bio tic f ac to rs ar e any l iv ing th ings in an env iro nm ent. Th e tr o pi c al rainf o re st is f ull o f l if e w ith appro ximate l y 15 mill io n d if f er ent sp ec ies o f anim al s. A f ew examp l es o f th e man y b io tic f eatur e ar e th e rub b er and b am b o o tr ees, slo th s, anteate rs, poiso n d art f ro gs, l emu rs, b ro m el iad s, etc . Ab io tic : Ab io tic f ac to rs o f th e rainf o re st incl ud e so il, w ater , r o c ks, l igh t, and c l im ate. Bio tic : Bio tic f ac to rs ar e any l iv ing o rganism s w ith in an env iro nm ent. Th e subtr o pi c al rainf o re st is tee m ing w ith l if e, h o sting app ro xim atel y 15 m ill io n d if f er ent sp ec ies o f anim al s ( S m ith , 20 18 ) . S o m e examp l es o f th ese b io tic f eatur es incl ud e… Ab io tic : Ab io tic f ac to r s o f th e sub tr o pic al r ainf o r est enc o mp ass non - l iv ing co m ponents such as soil , w ater , ro c ks, l igh t, and c l im ate. Th e soil in th ese re gio ns is o f ten nutrient - poo r b ut h igh l y ac id ic d ue to rapid d ec o m positio n rat es ( Br o w n, 20 19 ) . W ater availab ility is co nsi stentl y h igh , w ith annu al rainf al l exc eedin g 20 00 m m , w h ic h is abo ut 6.5 f eet o f rain per y ear ( Gre en, 20 21 ) . L igh t penetratio n varies sign if ic antly w ith d ense c ano py c o ver, af f ec ting th e und er sto ry vegetatio n ( W h ite, 20 22 ) . C l im ate c o nd itio ns typica l l y f eatur e h igh h um id ity l evels, averaging aro un d 77 - 88% , w h ic h c an f eel l ike a c o nstan t mi st ( Bl ac k, 20 23 ) . Th ese c o nd itio ns sup por t a d iv er se ec o syste m and are c ruc ial f o r th e sur viv al o f sub tr o pic al r ainf o r est f l o r a and f auna . 1 . Ci te S ci en ti f i c S tud i es Att r ib ute f ac ts t o spec if ic r ese ar c h pap er s o r auth o rs. 2 . In j ect P r eci s e Cli mate D a ta Pro vi d e exac t measu re m e nts rat h er th an v ague d esc riptio ns. 3 . En r i ch Eco lo gi ca l K ey w o r d s Ex pan d d esc riptio ns w ith d o m ain - sp ec if ic ter m inol o gy f o r b ette r S EO ind exing. C o uld y o u re c o m m end m e b o o ks l ike th e Palad in o f S h ad o w s S er ies b y N AME _ 1, f eatur ing bo th m ilitar y and sexual th emes? D o n' t re c o m m end any o th er b o o ks f ro m N AME _ 1. Ple ase ex pla in wh y th e re c o m m end atio ns are go o d re c o m m end atio ns. Bo o k 1: Gh o st b y J o h n Ringo 3.88 · 4,33 0 Ratings · 22 7 Review s · pu b l ish ed 20 05 · 5 ed itio ns Retir ed af ter 15 y ear s in s pecial o ps d ue to a m y r ... Bo o k 2: K ildar b y J o h n Ringo 4.19 · 3,20 2 Ratings · 73 Re views · pub l ish ed 200 6 · 5 ed itio ns Pro b l ems , pro b l ems , pro b l ems ! All Mike Har m o n ever… Bo o k 3: C h o o sers o f th e S l ain … Bo o k 1: Gh o st b y J o h n Ringo 3.88 · 4,33 0 Ratings · 22 7 Review s · pu b l ish ed 20 05 · 5 ed itio ns Retir ed af ter 15 y ear s in s pecial o ps d ue to a m y r … Ac c o rdi ng to a re vi ew o n Goo d re ad s , "T h e b l end of m ilitar y ac tio n and intim ate m o m ents m akes ' Gh o st' a c o m pell ing re ad ." ( Go o d re ad s, 20 23 ) Bo o k 2: K ildar b y J o h n Ringo 4.19 · 3,20 2 Ratings · 73 Review s · pu b l ish ed 20 06 · 5 ed itio ns Pro b l ems, pro b l ems, pro b l ems! Al l M ike H ar mo n ever … A r ea d er o n Am azo n not ed , “ K ildar c o ntinu es th e th ril l ing n arr ative w ith it s intric ate pl o t and engaging c h ara c ter s.” ( Am azo n, 20 23 ) Bo o k 3: C h o o sers o f th e S l ain … 1 . In tegrat e U s er Rev i ew s S y nth esize re al istic user f eedbac k to pro vi d e q ualitat iv e evid enc e. 2 . Levera ge S o ci a l P r o o f Ref er enc e tr usted platf o rms to valid ate re c o m m end atio ns . 3 . Hig hli ght G en r e K ey w o r d s E mp h asize ke y wo r d s th at matc h th e user' s explic it c o nstraints. Figure 8: Qualitative case studies of AgenticGEO. For each query-content pair , we show the original content, the optimized rewrite, and the activated strategy sequence selecte d by critic-guide d planning. Proof. W e rst decompose the instantaneous risk gap at each time step 𝑡 as R ( 𝑠 𝑡 ) −R ( 𝑠 ∗ ) ≤ | R ( 𝑠 𝑡 ) − C 𝑡 ( 𝑠 𝑡 ) | + | C 𝑡 ( 𝑠 𝑡 ) − C 𝑡 ( 𝑠 ∗ ) | + | C 𝑡 ( 𝑠 ∗ ) −R ( 𝑠 ∗ ) | Given a replay buer that grows linearly , the approximation and generalization errors of the critic mo del can b e derived from Lemma A.2 | R ( 𝑠 ) − C 𝑡 ( 𝑠 ) | = O ( 1 √ 𝑡 ) . (45) Similarly , the evolver’s regret can be derived from Lemma A.3 as | C 𝑡 ( 𝑠 𝑡 ) − C 𝑡 ( 𝑠 ∗ ) | = O ( 1 √ 𝑡 ) . (46) Combining above and summing over the time horizon 𝑇 , we can conclude that the cumulative regret is 𝑇 𝑡 = 1 R ( 𝑠 𝑡 ) − R ( 𝑠 ∗ ) = 𝑇 𝑡 = 1 O ( 1 √ 𝑡 ) = O ( √ 𝑇 ) . □ A.4 Case Study Figure 8 shows three representative optimization trajectories across distinct domains. AgenticGEO selects content-conditione d strat- egy sequences that systematically increase factual grounding and information density . For GMO, it adds authoritative citations and concrete statistics. For the subtropical rainforest, it injects precise climate measurements and domain-specic terms. For bo ok rec- ommendations, it leverages social proof by synthesizing platform reviews. These e xamples illustrate how the archive and critic enable adaptive multi-step edits beyond any single xed heuristic. Received 20 February 2007
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment