DTT-BSR: GAN-based DTTNet with RoPE Transformer Enhancement for Music Source Restoration
Music source restoration (MSR) aims to recover unprocessed stems from mixed and mastered recordings. The challenge lies in both separating overlapping sources and reconstructing signals degraded by production effects such as compression and reverbera…
Authors: Shihong Tan, Haoyu Wang, Youran Ni
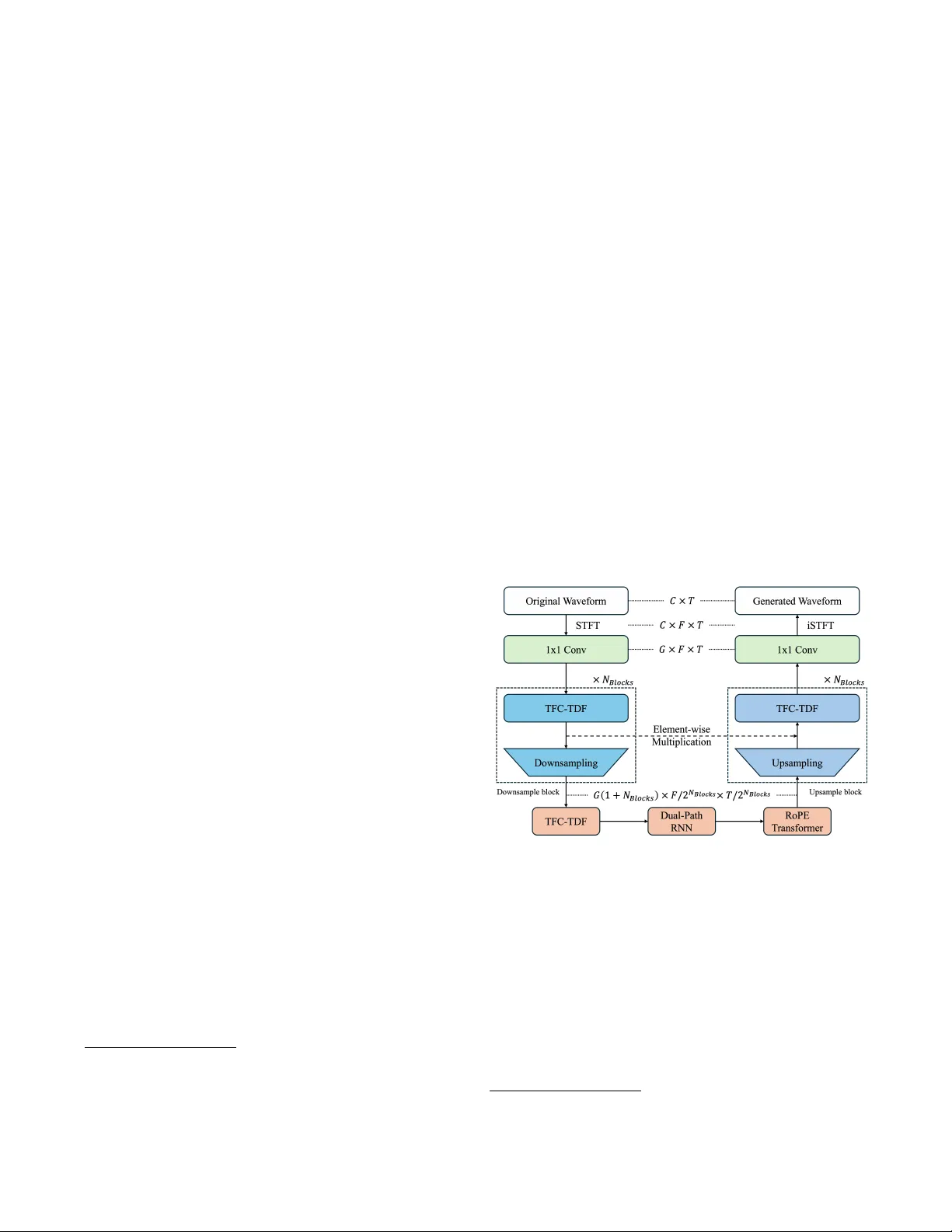
DTT -BSR: G AN-B ASED DTTNET WITH R OPE TRANSFORMER ENHAN CEMENT FOR MUSIC SOUR CE RES TORA TION Shihong T an 1 ,★ , Haoyu W ang 2 , 4 ,★ , Y our an Ni 1 , Yingzhao Hou 1 , Jiayue Luo 1 , Zipei Hu 1 , Han Dou 1 , Zerui Han 4 , Ningning P an 2 , Y uzhu W ang 3 , Gongping Huang 1 , † 1 School of Electronic Inf or mation, W uhan U niv ersity , China 2 Southw ester n U niv ersity of Finance and Economics, China 3 T ampere U niversity , Finland 4 MiLM Plus, Xiaomi Inc., China ABSTRA CT Music source restoration (MSR) aims to recov er unprocessed stems from mixed and mastered recordings. The challenge lies in both separating ov erlapping sources and reconstruct- ing signals deg raded b y production effects suc h as compres- sion and rev erberation. W e theref ore propose DTT -BSR, a h ybrid g enerative adv ersar ial network (G AN) combining ro- tary positional embeddings (R oPE) transf or mer f or long-ter m temporal modeling with dual-path band-split recurrent neural netw ork (RNN) f or multi-resolution spectral processing. Our model ac hiev ed 3rd place on the objectiv e leaderboard and 4th place on the subjectiv e leaderboard on the ICASSP 2026 MSR Challenge, demons trating ex ceptional g eneration fidelity and semantic alignment with a compact size of 7 . 1M parameters. Index T erms — Music source restoration, GAN , Music source separation 1. INTR ODUCTION Music source restoration (MSR) [1] e xtends music source sep- aration (MSS) by requiring both source isolation and restora- tion of signals degraded during music production. Inspired b y Dual-P ath TFC- TDF UNet (DTTNet) [2] and Band-Split R oPE T ransf ormer (BSR oFormer) [3], W e propose a gen- erativ e adv ersar ial netw ork (GAN) based adaptation of the DTTNet with band-sequence modeling and rotary positional embeddings (R oPE) [4] transf or mer bottleneck (DTT -BSR). Specifically , DTTNet is adopted as backbone f or its efficient U-Net s tructure, with R oPE transf ormer blocks equipped to capture long-ter m dependencies and dual-path recur rent neu- ral netw ork (RNN) modules for fine-grained spectral f eatures. This approach br idg es discriminative separation and genera- tiv e restoration within a single, end-to-end framew ork. ★ These authors contributed equally to this w ork. † Corresponding author. This w ork was supported b y the N ational Natural Science Foundation of China under Grant 62471340 and 62401479 and Sichuan Science and T echnology Program under Grant 2026NFSFC1430. Our approach achie ves competitiv e perf ormance in the ICASSP 2026 MSR Challeng e, ranking 3rd on objectiv e met- rics and 4th on subjective ev aluation. Code 1 and pretrained w eights 2 are publicly a vailable. 2. METHODOLOG Y 2.1. Model Ar chitectur e Fig. 1 . Our Proposed Model Architecture Figure 1 sho ws the framew ork of the proposed method, DTT -BSR, where DTTNet is adopted as the backbone, with R oPE transf or mer blocks incor porated to capture long-term dependence, and dual-path RNN block f or fine-g rained time- frequency f eature e xtraction. The 𝐶 -channel time-domain wa v ef or m W 𝐶 × 𝑇 is first processed through short-time F our ier transf or mation (STFT), which yields S 𝐶 × 𝑇 × 𝐹 . Then, a 1 × 1 con v olution lay er is applied, which yields a 𝐺 -dimensional f eature, which is then processed through 𝑁 𝑏𝑙 𝑜 𝑐 𝑘 𝑠 of downsam- ple blocks, each containing a TimeFrequency Conv olutions 1 https://github.com/OrigamiShido/DTT -BSR 2 https://huggingface.co/OrigamiShido/MSR Challenge- A CDC T able 1 . Overall R esults on the Official T est Set Method MMSNR Zimtohrli F AD-CLAP MOS Sep MOS Rankrestoration MOS o v erall DTT -BSR 1.4520 0.0182 0.2907 3.5425 2.4768 2.5412 T able 2 . Results per S tem on the Official T est Set Method Metrics V ocals Gtr . Ke y . Synth Bass Drums Perc. Orch. DTT -BSR MMSNR 1.0494 1.1410 1.8237 0.9508 2.8572 2.7304 0.0171 1.0464 Zimtohrli 0.0195 0.0165 0.0167 0.0183 0.0142 0.0185 0.0230 0.0189 F AD-CLAP 0.4186 0.3386 0.4257 0.6060 0.6026 0.4039 0.9606 0.3275 Time-Dis tr ibuted Full y-connected(TFC- TDF) bloc k [5] and a con v olution lay er that halv es the f eature map and increase the f eature dimensions by 𝐺 . The high-dimensional f eatures are subsequentl y processed by another TFC- TDF block, a dual- path RNN block[2], and a R oPE transformer block. The bottle-neck latent f eatures then go through 𝑁 𝐵𝑙 𝑜𝑐 𝑘 𝑠 of up- sample blocks, which contains a con v olutional la y er and a TFC- TDF block. W e apply skip connection mechanism to impro ve the connectivity , where element-wise multiplication is per f ormed after eac h upsampling block. F inally , a 1 × 1 con v olution lay er is added to project the feature dimension 𝐺 bac k to 𝐶 . An inv erse STFT operation is conducted to transf or m the spectrum to the generated w av eform. The proposed model is trained using a composite objec- tiv e that combines regression losses with adv ersar ial feed- back from the multi-frequency discriminator of EnCodec [6]. Specifically , the joint loss function L compr ises: The Multi- Mel STFT loss, L MMS , computes L1 distance between mag- nitude spectrograms at multiple windo w sizes; the adv ersar ial loss L adv uses a hing e loss f ormulation to impro v e perceptual quality b y encouraging the generator to produce realistic sam- ples that f ool the discriminator; the feature matching loss L f eat measures L1 distance betw een discr iminator feature maps of real and generated samples. Hence, L can be calculated by L = 𝜆 MMS L MMS + 𝜆 adv L adv + 𝜆 f eat L f eat (1) where 𝜆 MMS , 𝜆 adv , and 𝜆 f eat are weights that balance the con- tribution of each loss term. In our experiments, these h yper- parameters w ere set to 45 . 0, 2 . 0, and 4 . 0, respectiv el y . 3. EXPERIMENTS 3.1. Model T raining and Ev aluation W e only use Ra wStems[1] as the training set, whic h in- cludes 578 songs containing all 8 targ et stems with a total 354 . 13 hours of length. Dynamic Range Compression (using compressor and limiter), Harmonic Distortion, Re verb, and Random Audio Resample are applied as data augmentation method. Hanning window is used for conducting STFT , with the window length of 2048, hop length of 512. W e set 𝑁 𝐵𝑙 𝑜𝑐 𝑘 𝑠 at 2, and the conv olution kernel size of TFC- TDF module at ( 3 , 3 ) . The number of la y ers of the dual-path module is set to be 4 and number of heads set to be 2. The RoPE parameters T able 3 . Overall Objectiv e Results on MSRBenc h Method MMSNR ( ↑ ) Zimtohr li ( ↓ ) F AD-CLAP ( ↓ ) DTT -BSR 0.5011 0.0216 0.5660 Baseline 0.4020 0.0216 0.7545 are set to repeat 2 times with 8 heads, 2 time and frequency transf or mer modules each, with 0 . 1 of dropout rate. Final generator parameter amount is 7 . 1M. W e use AdamW f or optimizer and set the initial lear ning rate of 0 . 002. A single NVIDIA RTX 5090 is used to train each stem with a batch size of 2, for a total of 1 million steps each stem, and the training takes about 26 hours. W e use the officiall y released MSRBench [7] f or model ev aluation. For checkpoint selection, we ev aluate all sav ed chec kpoints on the validation set using Multi-Mel SNR (MM- SNR), F AD-CLAP[8], and Zimtohrli[9]. The best-performing chec kpoint is then evaluated on the official tes t set. 3.2. Results and Analy sis The model is tested with the official released test set. T able 1 sho ws the o verall objectiv e and subjective results and T able 2 details the per -stem results[10]. Throughout the 8 target stems, our model per f orms better at Guitar , Ke yboard and Orches tra stem, and outper f orms by Zimtohrli, F AD-CLAP , and subjectiv e evaluation, indicating that the proposed model impro ves perceptual q uality and semantic alignment ability . A ccording to our tested result on the validation set as in T a- ble 3, our model has a 24.62% increase on MMSNR and 24.93% decrease on F AD-CLAP , showing a significant im- pro vement. DTT -BSR per f or ms better at Medium-frequency stringed ins truments while lacking notable per f ormance on the other stems. Hence, our model pro vides a promising solution on non-v ocal instr ument separations. 4. CON CLUSION W e propose DTT -BSR, a DTTNet-based G AN generator which show s improv ement in Music Source Res toration. With a high-efficiency DTTNet backbone integrated with R oPE transf or mer bloc k, our proposed model achie ves 3rd in Object metr ics and 4th in Subject metrics in the ICASSP Music Source Restoration Challenge, highlighting the percep- tual and semantic alignment ability , and non-vocal ins trument performance. 5. REFERENCES [1] Y . Zang, Z. Dai, M. D. Plumbley , and Q. Kong, “Music source restoration, ” 2025. [2] J. Chen, S. V ekk ot, and P . Shukla, “Music source sepa- ration based on a lightweight deep lear ning framew ork (dttnet: Dual-path tfc-tdf unet), ” in IC ASSP 2024 - 2024 IEEE Int ernational Conf er ence on Acoustics, Speec h and Signal Pr ocessing (ICASSP) , pp. 656–660, 2024. [3] W .- T . Lu, J.-C. W ang, Q. K ong, and Y .-N . Hung, “Mu- sic source separation with band-split rope transf or mer , ” in ICASSP 2024 - 2024 IEEE International Confer ence on Acoustics, Speec h and Signal Processing (ICASSP) , pp. 481–485, 2024. [4] J. Su, M. Ahmed, Y . Lu, S. Pan, W . Bo, and Y . Liu, “R o- f or mer: Enhanced transformer with rotar y position em- bedding, ” Neur ocomputing , vol. 568, p. 127063, 2024. [5] M. Kim, J. H. Lee, and S. Jung, “Sound demixing chal- lenge 2023 music demixing track technical repor t: Tfc- tdf-unet v3, ” arXiv pr eprint arXiv :2306.09382 , 2023. [6] A. D ´ ef ossez, J. Copet, G. Synnaev e, and Y . A di, “High fidelity neural audio compression, ” T ransactions on Ma- c hine Learning R esear c h , 2023. [7] Y . Zang, J. Hai, W . Ge, Q. K ong, Z. Dai, H. W ang, Y . Mit- sufuji, and M. D. Plumble y , “Msrbench: A benchmark - ing dataset f or music source restoration, ” arXiv pr eprint arXiv :2510.10995 , 2025. [8] Y . W u, K. Chen, T . Zhang, Y . Hui, M. Nezhurina, T . Berg-Kirkpatrick, and S. Dubno v , “Larg e-scale con- trastiv e languag e-audio pretraining with f eature fusion and ke yword-to-caption augmentation, ” 2024. [9] J. Alakui jala, M. Br use, S. Boukortt, J. M. Coldenhoff, and M. Cernak, “Zimtohr li: An efficient psy choacoustic audio similarity metr ic, ” 2025. [10] Y . Zang, J. Hai, W . Ge, Q. Kong, Z. Dai, H. W ang, Y . Mitsufuji, and M. D. Plumble y , “Summar y of the inaugural music source restoration c hallenge, ” 2026.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment