CXReasonAgent: Evidence-Grounded Diagnostic Reasoning Agent for Chest X-rays
Chest X-ray plays a central role in thoracic diagnosis, and its interpretation inherently requires multi-step, evidence-grounded reasoning. However, large vision-language models (LVLMs) often generate plausible responses that are not faithfully groun…
Authors: Hyungyung Lee, Hangyul Yoon, Edward Choi
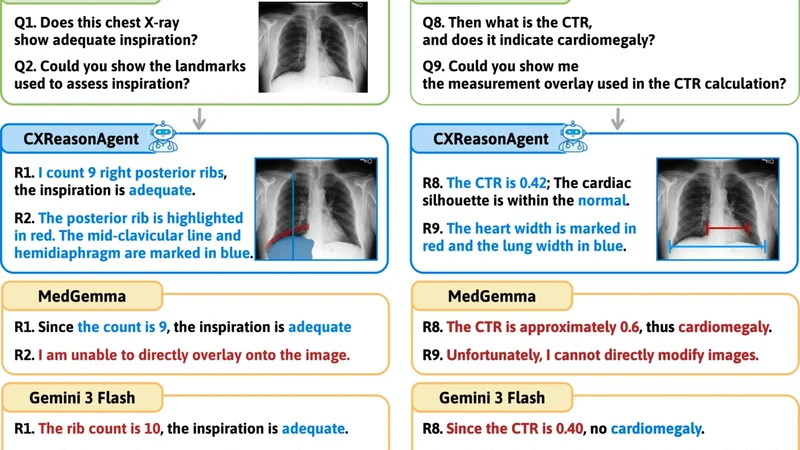
CXReasonAgen t: Evidence-Grounded Diagnostic Reasoning Agen t for Chest X-ra ys Hyungyung Lee, Hangyul Y o on, Edw ard Choi KAIST {ttumyche,edwardchoi}@kaist.ac.kr Abstract. Chest X-ra y plays a cen tral role in thoracic diagnosis, and its in terpretation inheren tly requires m ulti-step, evidence-grounded rea- soning. How ever, large vision-language models (L VLMs) often generate plausible resp onses that are not faithfully grounded in diagnostic evi- dence and provide limited visual evidence for verification, while also re- quiring costly retraining to supp ort new diagnostic tasks, limiting their reliabilit y and adaptability in clinical settings. T o address these limita- tions, we presen t CXReasonAgen t, a diagnostic agent that in tegrates a large language model (LLM) with clinically grounded diagnostic tools to p erform evidence-grounded diagnostic reasoning using image-derived diagnostic and visual evidence. T o ev aluate these capabilities, we intro- duce CXReasonDial, a multi-turn dialogue b enchmark with 1,946 dia- logues across 12 diagnostic tasks, and sho w that CXReasonAgent pro- duces faithfully grounded resp onses, enabling more reliable and verifiable diagnostic reasoning than L VLMs. These findings highlight the impor- tance of integrating clinically grounded diagnostic to ols, particularly in safet y-critical clinical settings. The demo video is av ailable here Keyw ords: Chest X-ra y · Evidence-Grounded Reasoning · Agent 1 In tro duction Chest X-ray (CXR) is a primary imaging mo dalit y for thoracic diagnosis and is widely used in clinical practice [ 3 ]. Inheren tly , CXR in terpretation is a m ulti-step, evidence-grounded reasoning pro cess that inv olv es identifying relev an t anatom- ical regions, deriving quan titativ e measuremen ts or spatial observ ations, and applying diagnostic criteria [ 7 ]. Consequen tly , for diagnostic assistan ts to be trust worth y and clinically useful, their in termediate diagnostic steps should b e grounded in clinically v alid and verifiable image-derived diagnostic evidence, and their reasoning m ust remain coherent and consistent throughout the pro cess. Ho wev er, recen t studies [ 10 , 14 , 15 ] demonstrate that L VLMs often generate plausible resp onses but are not faithfully grounded in the diagnostic evidence presen t in the image, thereby undermining the reliability of their conclusions in clinical practice. Moreov er, L VLMs typically presen t their reasoning through textual explanations alone, which mak es it difficult to verify ho w conclusions are deriv ed from the image. Effective diagnostic supp ort instead requires presenting 2 Hyungyung Lee et al. Fig. 1. Qualitative examples on CXReasonDial . CXReasonAgent produces re- sp onses faithfully grounded in image-derived diagnostic and visual evidence, whereas L VLMs often generate ungrounded resp onses and fail to provide visual evidence. diagnostic evidence directly on the image, enabling direct v erification. How ever, suc h visual evidence is rarely provided in practice, thereby limiting verifiabilit y of diagnostic reasoning [ 2 , 20 ]. F urthermore, building L VLMs that handle diverse diagnostic tasks often in tro duces significant complexit y and inefficiency , motiv at- ing to ol-augmented diagnostic agents [ 4 , 8 , 11 ] that in tegrate task-sp ecific mo dels as to ols [ 6 , 12 , 21 , 23 ], enabling extension to new tasks without costly retraining. Ho wev er, these approaches typically rely on to ols that provide final diagnos- tic conclusions or region-level visualizations, without exp osing the intermediate diagnostic steps used to deriv e these conclusions from image-deriv ed evidence. Consequen tly , they still fall short of supp orting reliable and verifiable evidence- grounded diagnostic reasoning. Notably , recent work in ECG analysis [ 5 ] demon- strates that integrating measuremen t-based to ols [ 13 ] can pro vide quan titative diagnostic evidence, p oin ting tow ard more reliable diagnostic reasoning. Based on these observ ations, we prop ose CXReasonAgent, a diagnostic agent that integrates an LLM with clinically grounded diagnostic tools to p erform evidence-grounded diagnostic reasoning. Unlik e prior approac hes, the to ols re- turn diagnostic evidence, including image-deriv ed quan titative measuremen ts and spatial obs erv ations, and diagnostic conclusions, along with visual evidence that presents this evidence on the image. The agen t then pro duces resp onses grounded in this evidence. T o ev aluate these abilities, w e introduce CXReason- Dial, a multi-turn dialogue b enchmark comprising 1,946 dialogues spanning 12 diagnostic tasks, designed to measure whether resp onses are correctly grounded CXReasonAgen t: Evidence-Grounded Diagnostic Reasoning Agen t for CXR 3 in image-deriv ed evidence, reflecting the iterative nature of diagnostic reason- ing in user-assistan t interactions. Exp erimental results sho w that CXReason- Agen t pro duces correctly grounded resp onses, whereas L VLMs often generate ungrounded resp onses (Fig. 1 ). These findings highlight the imp ortance of inte- grating clinically grounded diagnostic tools for reliable and verifiable evidence- grounded diagnostic reasoning, particularly in safet y-critical clinical settings. 2 CXReasonAgen t As shown in Fig. 2 , CXReasonAgent is a diagnostic agen t that integrates an LLM with clinically grounded diagnostic to ols to p erform evidence-grounded di- agnostic reasoning through m ulti-turn interactions. T o ensure clinical v erifiabil- it y , the agen t op erates within 12 predefined diagnostic tasks whose image-deriv ed evidence can b e reliably extracted by the in tegrated to ols, cov ering cardiac size (cardiomegaly), mediastinal and aortic abnormalities (mediastinal widening, aor- tic knob, ascending, and descending aorta enlargement, descending aorta tortu- osit y), airwa y alignment (trachea deviation, carina angle), and image qualit y assessmen t (inspiration, rotation, pro jection, inclusion) [ 10 ]. Fig. 2. Ov erview of CXReasonAgen t . The pipeline comprises three stages: (1) in terpreting the user query and planning the appropriate diagnostic to ol call, (2) con- structing diagnostic and visual evidence from the chest X-ra y using clinically grounded diagnostic to ols, and (3) generating resp onses solely grounded in this evidence. 4 Hyungyung Lee et al. Query In terpretation and T o ol Planning. Given a user query paired with a chest X-ra y , the agen t interprets the query to iden tify the requested diagnostic task and the type of evidence required to answer it. Queries are categorized into t wo types: 1) Diagnostic Evidenc e R e quest , whic h asks for image-derived diagnostic evidence, such as quantitativ e measurements and spatial observ ations, and their corresp onding diagnostic conclusions and criteria ( e.g. , What is the c ar- diothor acic r atio? ), and 2) Visual Evidenc e R e quest , which asks to presen t the image-derived diagnostic evidence directly on the image ( e.g. , highlighting anatomical regions or showing measurement o verla ys). Based on the identified diagnostic task and evidence type, the agent requests the appropriate diagnostic to ol call to obtain the required evidence. Clinically Grounded Diagnostic T o ol Execution. The selected diagnostic to ol analyzes the chest X-ra y and returns clinically grounded evidence derived from the image. F or a diagnostic evidence request, the to ol outputs diagnostic ev- idence, including quantitativ e measuremen ts, spatial observ ations, and their cor- resp onding diagnostic criteria and conclusions. F or a visual evidence request, it returns annotated images that visualize the image-derived diagnostic evidence di- rectly on the image. The to ols are implemen ted using CheXStruct [ 10 ], a pip eline designed based on clinically grounded criteria defined with b oard-certified radi- ologists to ensure accurate evidence extraction. Because the pip eline relies on rule-based geometric computations derived from these criteria, the extraction pro cess is deterministic, ensuring repro ducible evidence for a given image and supp orting reliable evidence-grounded diagnostic reasoning. Evidence-Grounded Resp onse Generation. Giv en the image-deriv ed evi- dence, the agen t pro duces a resp onse solely grounded on this evidence, without directly accessing the chest X-ray . This enables users to verify the evidence used to generate the resp onse, supp orting reliable and coheren t evidence-grounded diagnostic reasoning across m ulti-turn interactions. 3 CXReasonDial CXReasonDial is a m ulti-turn dialogue b enchmark designed to ev aluate whether resp onses are correctly grounded in image-deriv ed evidence across dialogue turns. The b enc hmark is constructed as follows. Dialogue Scenario Definition. T o co ver div erse dialogue conditions, w e define dialogue scenarios along t wo aspects: 1) T ask Cover age. The b enc hmark is re- stricted to the same 12 predefined diagnostic tasks as CXReasonAgent. W e v ary the num ber of diagnostic tasks addressed within a single dialogue: single-task dialogues fo cus on one diagnostic task, multi-task dialogues co ver t w o diagnostic tasks, and global-to-task dialogues b egin with a global question ( e.g. , ov erall presence of abnormalities) and then explore one to four sp ecific diagnostic tasks in detail. 2) Question Flow Patterns. W e define three question flow patterns to reflect different st yles of diagnostic questioning. In the top-down pattern, the dialogue starts with a diagnostic conclusion question and progressiv ely requests supp orting evidence ( e.g. , quan titative measurements or annotated images). The CXReasonAgen t: Evidence-Grounded Diagnostic Reasoning Agen t for CXR 5 b ottom-up pattern follo ws the reverse order, b eginning with specific evidence and gradually leading to the diagnostic conclusion. In the r andom pattern, questions app ear in a flexible order, reflecting less structured user interactions. A ction Sequence Construction. Giv en a dialogue scenario, we construct an action sequence to specify the turn-by-turn in teraction structure of the dia- logue, as in T o olDial [ 17 ]. Sp ecifically , it defines, for each turn, the type of user request, which in turn dete rmines the exp ected resp onse b ehavior of the mo del. W e consider t w o user request types: diagnostic evidence requests ( e.g. , mea- suremen ts, spatial observ ations, or diagnostic conclusions) and visual evidence requests ( e.g. , highlighting anatomical regions). F or example, a sequence may fol- lo w: Diagnostic evidenc e r e quest → Mo del r esp onse → Visual evidenc e r e quest → Mo del r esp onse → · · · → User bye → Mo del bye . These action sequences serv e as dialogue sk eletons that guide the subsequent dialogue generation pro cess. Dialogue Generation. Using the defined dialogue scenarios and action se- quences, w e generate m ulti-turn dialogues turn by turn using Gemini-3-Flash. F or each turn, w e prompt the mo del with the dialogue scenario, the user request t yp e assigned to that turn, and the request-sp ecific evidence extracted from the c hest X-ray b y the CheXStruct pip eline [ 10 ], along with the previously gener- ated dialogue turns. The user question is generated to b e consisten t with the dialogue scenario and request type and to b e answerable using the provided ev- idence, while the resp onse is grounded in the same evidence. CXReasonDial is constructed from 1,200 c hest X-rays adopted from CXReasonBenc h [ 10 ], whic h w ere manually review ed by a board-certified radiation oncologist to support reli- able extraction of diagnostic evidence using CheXStruct. In total, CXReasonDial comprises 1,946 dialogues with an av erage of 10.87 turns p er dialogue (T able 1 ). Dialogue V alidation. W e v alidate 100 randomly sampled dialogues using b oth an LLM-as-a-Judge [ 24 ] ( i.e. , Gemini-3-Flash) and human ev aluation conducted b y 10 graduate students under the sup ervision of a radiation oncologist. Dialogue qualit y is assessed using three criteria: Question Complianc e (0/1) : whether eac h question follo ws the assigned diagnostic task and request type. Ans wer Corr e ctness (0/1) : whether the resp onse correctly addresses the question and is grounded in the pro vided evidence. Natur alness (1–5) : coherence across turns and adherence to the predefined question flo w patterns. As sho wn in T able 2 , the dialogues adhere to the in tended dialogue design, provide evidence-grounded resp onses, and exhibit natural m ulti-turn interactions. T able 1. Dialogue statistics. Statistic V alue T otal dialogues 1,946 Single-task 1,200 Multi-task 660 Global-to-task 86 A vg. turns / dialogue 10.87 T able 2. Dialogue v alidation results. Criterion Gemini Human Question Compliance 0.981 0.970 Answ er Correctness 0.997 0.982 Naturalness 4.20 4.26 6 Hyungyung Lee et al. 4 Exp erimen ts and Results Ev aluation Mo dels. W e ev aluate CXReasonAgent with multiple LLM bac k- b ones, including the closed-source mo dels, Gemini-3-Flash [ 19 ] and GPT-5 mini [ 18 ], and the open-source mo dels, Llama 3.3-70B [ 9 ] and Qw en3 (4B, 8B, 32B) [ 22 ]. W e compare against three L VLM baselines: Gemini-3-Flash [ 19 ], Pixtral- Large [ 1 ], and MedGemma 27B [ 16 ]. Op en-source mo dels are run with vLLM on NVIDIA A100 GPUs (4 GPUs for Pixtral-Large and Llama-3.3-70B) and R TX A6000 GPUs (2 GPUs for Qw en3 v ariants and MedGemma 27B). Ev aluation Metrics. W e ev aluate mo dels using the following metrics. 1) T urn- level Metrics. Eac h metric is ev aluated as a binary score at the turn level using an LLM-as-a-Judge [ 24 ] ( i.e. , Gemini-3-Flash). (i) Diagnostic T ask Identific ation and (ii) Evidenc e T yp e Identific ation assess whether the agent correctly iden- tifies, from the user query , the requested diagnostic task and evidence t yp e, resp ectiv ely . These tw o metrics are ev aluated only for CXReasonAgen ts, as they assess the to ol planning stage. (iii) Cover age assesses whether the response fully addresses the user query , regardless of factual correctness. (iv) F aithfulness ev al- uates whether the response is consisten t with the request-sp ecific ground-truth evidence used during CXReasonDial construction. (v) Hal lucination is defined as the case where Cover age =1 and F aithfulness =0. When ev aluating L VLMs, turns requesting visual evidence are excluded, as these mo dels do not produce visual evidence. 2) Dialo gue-level Metrics. A turn is considered successful only if all applicable turn-lev el metrics are correct. (i) Aver age Dialo gue Suc c ess is the av erage ratio of successful turns p er dialogue. (ii) Strict Dialo gue Suc c ess is the prop ortion of dialogues in which all turns are successful. Ev aluation Settings. W e ev aluate mo dels under three complementary settings. While CXReasonDial uses pre-generated user queries to ensure con trolled com- parison on iden tical questions, these fixed queries do not adapt to erroneous resp onses. In this default setting, 1) Without GT , the dialogue history is con- structed from the mo del’s o wn outputs, allo wing errors to accumulate across turns and potentially reducing interaction naturalness. 2) With GT provides the ground-truth dialogue history at eac h turn, prev enting error propagation and serving as an upper-b ound setting under fixed user queries [ 17 ]. Ho wev er, b ecause the history is corrected at ev ery turn, this setting can mask ho w mo d- els b ehav e when their o wn errors accumulate in in teractive use. 3) Dynamic User Simulator addresses these limitations by ev aluating p erformance under adaptiv e multi-turn interactions. F ollo wing the same dialogue design ( i.e. , dia- logue scenario and action sequence) as CXReasonDial, Gemini-3-Flash generates user queries conditioned on the mo del-generated dialogue history at each turn, allo wing the queries to adapt to mo del resp onses while main taining a similar structural pattern to the original dialogues. Results: Imp ortance of Clinically Grounded Diagnostic T o ols. T ables 3 and 4 indicate that L VLMs often generate plausible resp onses that app ear rea- sonable but are not correctly grounded in the image-deriv ed diagnostic evidence. In con trast, CXReasonAgent grounds each response in diagnostic and visual evi- dence extracted from the c hest X-ray by clinically grounded diagnostic tools, en- CXReasonAgen t: Evidence-Grounded Diagnostic Reasoning Agen t for CXR 7 suring that the reasoning remains faithfully grounded in v erifiable image-derived evidence. This adv an tage is further reflected in the dialogue-level metrics, where CXReasonAgen t achiev es higher success rates, indicating more stable and coher- en t multi-turn diagnostic reasoning. Overall, these results highligh t the imp or- tance of integr ating clinically grounded diagnostic to ols for enabling reliable and v erifiable evidence-grounded diagnostic reasoning, particularly in safet y-critical clinical settings. T able 3. Results on CXReasonDial under the Without GT (w /o) and With GT (w /) settings. DTI: Diagnostic T ask Iden tification; ETI: Evidence Type Iden tifi- cation; Cov: Cov erage; F aith: F aithfulness; Hall: Hallucination; A vg: A v erage Dialogue Success; Strict: Strict Dialogue Success; Best results are underlined. T urn-level Dialogue-lev el DTI ↑ ETI ↑ Co v ↑ F aith ↑ Hall ↓ A vg ↑ Strict ↑ Mo del w /o w / w /o w / w /o w / w /o w / w /o w / w /o w / w /o w / CXReasonAgen t Gemini-3-Flash 99.8 99.8 97.6 97.6 99.5 99.4 99.7 99.7 0.3 0.3 96.8 96.6 73.4 72.2 GPT-5 mini 99.9 99.9 98.2 98.2 99.5 99.5 99.2 99.2 0.8 0.8 96.9 96.9 74.8 74.2 Llama 3.3-70B 99.3 99.4 96.7 96.9 99.4 99.4 99.3 99.2 0.7 0.8 95.3 95.5 65.8 65.2 Qw en3-32B 98.6 97.0 97.0 97.3 99.6 99.5 97.6 98.6 2.3 1.4 94.2 91.6 61.1 59.0 Qw en3-8B 86.3 89.5 86.6 90.0 99.6 99.7 93.7 95.3 6.3 4.6 76.6 80.6 21.1 23.1 Qw en3-4B 91.6 92.6 92.1 93.7 99.6 99.4 94.7 96.3 5.3 3.7 80.4 82.2 31.6 32.9 L VLM Baselines Gemini-3-Flash - - - - 98.3 98.3 43.1 81.1 55.6 18.0 36.9 69.1 8.6 9.8 Pixtral-Large - - - - 98.8 98.8 57.9 79.8 41.5 20.1 48.6 65.4 5.9 6.0 MedGemma 27B - - - - 98.9 98.5 53.9 76.2 45.4 23.2 46.1 64.1 6.1 6.5 Results: Effect of Backbone Scale and Design Flexibility . T ables 3 and 4 further analyze the effect of backbone scale within CXReasonAgen t. While larger bac kb ones consistently impro ve performance across most turn-level metrics, the gains are generally mo derate, whereas more noticeable improv ements are ob- serv ed in dialogue-level success. This suggests that increased model capacit y primarily enhances query interpretation accuracy and multi-turn reasoning sta- bilit y . Imp ortantly , even small bac kb ones ( e.g. , Qwen3-4B and 8B) already sur- pass all L VLMs across all metrics, indicating that the primary performance gains arise from the agent design, namely clinically grounded diagnostic tool-based ev- idence grounding, rather than from model scale alone. These results highligh t the cost-efficiency and flexibility of the prop osed agen t design: the core diagnostic reasoning capability is largely preserved across bac kb one sizes, allowing practi- tioners to flexibly trade off p erformance and computational cost by sw apping the underlying language mo del without redesigning the system. Results: Robust Evidence Grounding A cross Ev aluation Settings. In T able 3 , CXReasonAgent maintains strong p erformance in b oth Without GT and 8 Hyungyung Lee et al. T able 4. Results with the Dynamic User Simulator based on the CXRea- sonDial dialogue design. Best results are underlined. T urn-level Dialogue-lev el Mo del DTI ↑ ETI ↑ Cov ↑ F aith ↑ Hall ↓ A vg ↑ Strict ↑ CXReasonAgen t Gemini-3-Flash 98.0 98.5 99.9 99.9 0.1 93.3 75.7 GPT-5 mini 99.9 98.8 99.9 99.8 0.2 98.4 85.8 Llama 3.3-70B 98.8 98.3 99.9 99.7 0.3 96.1 79.9 Qw en3-32B 96.5 97.4 99.9 98.7 1.3 92.4 67.8 Qw en3-8B 83.0 84.7 99.9 96.8 3.2 76.4 29.4 Qw en3-4B 88.7 89.6 99.8 97.3 2.7 81.7 38.5 L VLM Baselines Gemini-3-Flash - - 98.5 46.3 52.3 33.8 9.10 Pixtral-Large - - 98.5 48.2 50.3 35.5 7.70 MedGemma 27B - - 98.7 44.9 53.8 34.8 5.10 With GT settings, indicating robust evidence-grounded reasoning even when relying on its own generated dialogue history , where errors can accumulate across turns. In contrast, L VLMs show substan tial gains in faithfulness and reduced hallucination when ground-truth history is provided, suggesting that they may leverage diagnostic evidence already present in the ground-truth his- tory rather than consistently grounding their resp onses in image-derived evi- dence. Under the dynamic user simulator (T able 4 ), CXReasonAgen t contin- ues to outp erform L VLMs by a similar margin, demonstrating that its evidence grounding remains stable under realistic in teractive conditions. Ov erall, these re- sults sho w that CXReasonAgen t maintains reliable evidence-grounded reasoning across both controlled fixed-query ev aluations and resp onse-adaptiv e multi-turn in teractions. 5 Conclusion W e presented CXReasonAgent, a diagnostic agent that in tegrates an LLM with clinically grounded diagnostic to ols to p erform evidence-grounded diagnostic reasoning through multi-turn dialogue. W e also introduce CXReasonDial to sys- tematically ev aluate whether resp onses are correctly grounded in image-derived evidence across dialogue turns. Exp erimen ts demonstrate that CXReasonAgen t consisten tly pro duces faithfully grounded responses and enables more coherent m ulti-turn diagnostic reasoning than L VLMs. These findings highlight the imp or- tance of in tegrating clinically grounded diagnostic tools for reliable and v erifiable diagnostic reasoning, particularly in safety-critical clinical settings. The current scop e is limited to 12 diagnostic tasks on c hest X-rays; future work will extend the agen t to broader diagnostic tasks and mo dalities. CXReasonAgen t: Evidence-Grounded Diagnostic Reasoning Agen t for CXR 9 References 1. Agra wal, P ., Antoniak, S., Hanna, E.B., Bout, B., Chaplot, D., Chudno vsky , J., Costa, D., De Monicault, B., Garg, S., Gervet, T., et al.: Pixtral 12b. arXiv preprint arXiv:2410.07073 (2024) 2. Amann, J., Blasimme, A., V ay ena, E., F rey , D., Madai, V.I., Consortium, P .: Ex- plainabilit y for artificial intelligence in healthcare: a multidisciplinary p ersp ective. BMC medical informatics and decision making 20 (1), 310 (2020) 3. Bansal, T., Beese, R.: Interpreting a chest x-ray . British Journal of Hospital Medicine 80 (5), C75–C79 (2019) 4. Chen, W., Dong, Y., Ding, Z., Shi, Y., Zhou, Y., Zeng, F., Luo, Y., Lin, T., Su, Y., W u, Y., et al.: Radfabric: Agen tic ai system with reasoning capability for radiology . arXiv preprint arXiv:2506.14142 (2025) 5. Ch ung, H., Oh, J., Kyung, D., Kim, J., K won, Y., Kim, M.G., Choi, E.: Ecg- agen t: On-device to ol-calling agent for ecg m ulti-turn dialogue. arXiv preprint arXiv:2601.20323 (2026) 6. Cohen, J.P ., Viviano, J.D., Bertin, P ., Morrison, P ., T orabian, P ., Guarrera, M., Lungren, M.P ., Chaudhari, A., Bro oks, R., Hashir, M., et al.: T orchxra yvision: A library of chest x-ray datasets and mo dels. In: In ternational Conference on Medical Imaging with Deep Learning. pp. 231–249. PMLR (2022) 7. Delrue, L., Gosselin, R., Ilsen, B., V an Landeghem, A., De Mey , J., Duyck, P .: Dif- ficulties in the interpretation of c hest radiography . In: Comparative interpretation of CT and standard radiography of the chest, pp. 27–49. Springer (2010) 8. F allahp our, A., Ma, J., Munim, A., Lyu, H., W ang, B.: Medrax: Medical reasoning agen t for chest x-ra y . arXiv preprin t arXiv:2502.02673 (2025) 9. Grattafiori, A., Dub ey , A., Jauhri, A., Pandey , A., Kadian, A., Al-Dahle, A., Let- man, A., Mathur, A., Schelten, A., V aughan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024) 10. Lee, H., Choi, G., Lee, J.O., Y o on, H., Hong, H.G., Choi, E.: Cxreason b enc h: A benchmark for ev aluating structured diagnostic reasoning in chest x-rays. In: The Thirty-nin th Ann ual Conference on Neural Information Processing Systems Datasets and Benchmarks T rack 11. Li, B., Y an, T., P an, Y., Luo, J., Ji, R., Ding, J., Xu, Z., Liu, S., Dong, H., Lin, Z., et al.: Mmedagen t: Learning to use medical to ols with multi-modal agent. In: Findings of the Asso ciation for Computational Linguistics: EMNLP 2024. pp. 8745–8760 (2024) 12. Li, C., W ong, C., Zhang, S., Usuyama, N., Liu, H., Y ang, J., Naumann, T., P o on, H., Gao, J.: Llav a-med: T raining a large language-and-vision assistant for biomedicine in one da y . Adv ances in Neural Information Processing Systems 36 , 28541–28564 (2023) 13. Mak owski, D., Pham, T., Lau, Z.J., Brammer, J.C., Lespinasse, F., Pham, H., Sc hölzel, C., Chen, S.A.: Neurokit2: A p ython to olb ox for neuroph ysiological signal pro cessing. Beha vior research methods 53 (4), 1689–1696 (2021) 14. Meddeb, A., Rangus, I., P agano, P ., Dkhil, I., Jelassi, S., Bressem, K., Sc heel, M., W attjes, M.P ., Nagi, S., Pierot, L., et al.: Ev aluating the diagnostic accuracy of vision language mo dels for neuroradiological image interpretation. np j Digital Medicine 8 (1), 666 (2025) 15. Nguy en, D., Ho, M.K., T a, H., Nguyen, T.T., Chen , Q., Rav, K., Dang, Q.D., Ram- c handre, S., Phung, S.L., Liao, Z., et al.: Lo calizing b efore answering: A b enchmark for grounded medical visual question answering. In: Thirty-F ourth International 10 Hyungyung Lee et al. Join t Conference on Artificial In telligence (IJCAI-25). International Joint Confer- ences on Artificial Intelligence Organization (2025) 16. Sellergren, A., Kazemzadeh, S., Jaro ensri, T., Kiraly , A., T ra verse, M., K ohlb erger, T., Xu, S., Jamil, F., Hughes, C., Lau, C., et al.: Medgemma technical rep ort. arXiv preprin t arXiv:2507.05201 (2025) 17. Shim, J., Seo, G., Lim, C., Jo, Y.: T ooldial: Multi-turn dialogue generation metho d for to ol-augmen ted language mo dels. arXiv preprint arXiv:2503.00564 (2025) 18. Singh, A., F ry , A., P erelman, A., T art, A., Ganesh, A., El-Kishky , A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: Openai gpt-5 system card. arXiv preprin t arXiv:2601.03267 (2025) 19. T eam, G., Anil, R., Borgeaud, S., Alayrac, J.B., Y u, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable m ultimo dal mo dels. arXiv preprint arXiv:2312.11805 (2023) 20. Tjoa, E., Guan, C.: A surv ey on explainable artificial in telligence (xai): T ow ard medical xai. IEEE transactions on neural netw orks and learning systems 32 (11), 4793–4813 (2020) 21. W ang, S., Zhao, Z., Ouyang, X., W ang, Q., Shen, D.: Chatcad: Interactiv e computer-aided diagnosis on medical image using large language mo dels. arXiv preprin t arXiv:2302.07257 (2023) 22. Y ang, A., Li, A., Y ang, B., Zhang, B., Hui, B., Zheng, B., Y u, B., Gao, C., Huang, C., Lv, C., et al.: Qw en3 technical report. arXiv preprint arXiv:2505.09388 (2025) 23. Zhang, S., Xu, Y., Usuyama, N., Xu, H., Bagga, J., Tinn, R., Preston, S., Rao, R., W ei, M., V alluri, N., et al.: Biomedclip: a multimodal biomedical foundation mo del pretrained from fifteen million scientific image-text pairs. arXiv preprin t arXiv:2303.00915 (2023) 24. Zheng, L., Chiang, W.L., Sheng, Y., Zhuang, S., W u, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E., et al.: Judging llm-as-a-judge with mt-bench and chatbot arena. A dv ances in neural information pro cessing systems 36 , 46595–46623 (2023)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment