Deepfake Word Detection by Next-token Prediction using Fine-tuned Whisper
Deepfake speech utterances can be forged by replacing one or more words in a bona fide utterance with semantically different words synthesized by speech generative models. While a dedicated synthetic word detector could be developed, we investigate a…
Authors: Hoan My Tran, Xin Wang, Wanying Ge
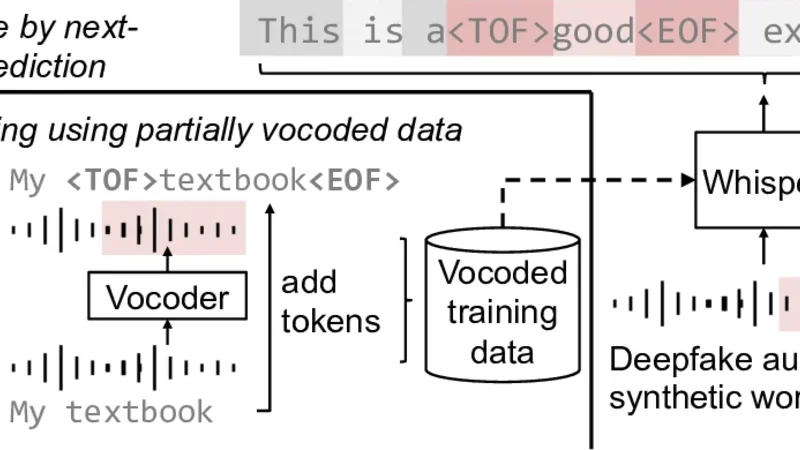
Deepfake W ord Detection by Next-token Pr ediction using Fine-tuned Whisper Hoan My T ran 1 , ∗ , Xin W ang 2 , ∗ , W anying Ge 2 , Xuechen Liu 2 , J unichi Y amagishi 2 1 Uni versit ´ e de Rennes, France. 2 National Institute of Informatics, Japan hoan.tran@irisa.fr, wangxin@nii.ac.jp Abstract Deepfake speech utterances can be forged by replacing one or more words in a bona fide utterance with semantically differ- ent words synthesized by speech generative models. While a dedicated synthetic word detector could be developed, we in- vestigate a cost-ef fective method that fine-tunes a pre-trained Whisper model to detect synthetic w ords while transcribing the input utterance via next-token prediction. W e further inv esti- gate using partially vocoded utterances as the fine-tuning data, thereby reducing the cost of data collection. Our experiments demonstrate that, on in-domain test data, the fine-tuned Whisper yields low synthetic-word detection error rates and transcription error rates. On out-of-domain test data with synthetic words produced by unseen speech generative models, the fine-tuned Whisper remains on par with a dedicated ResNet-based detec- tion model; howe ver , the overall performance degradation calls for strategies to impro ve its generalization capability . Index T erms : speech anti-spoofing, deepfake detection, speech recognition, deep learning 1. Introduction Detecting deepfake speech utterances, which are not uttered by a real speaker but synthesized by a speech generativ e model, is now a well-established topic with numerous publications on detector architectures [1], [2], feature engineering [3], [4], datasets, and competitions [5], [6], [7]. Beyond simply detect- ing whether an input utterance is synthetic (i.e., deepf ake or forged by any synthesis model alike), an emerging task is to de- tect which part of the input utterance is synthetic . Solutions are needed to counter advanced manipulations that alter part of a bona fide (i.e., human-uttered real) utterance, for example, by swapping bona fide words with synthetic ones. 1 Such manipula- tion can be conducted using traditional audio forgery methods (e.g., slicing) or more adv anced deep-neural-network (DNN)- based generati ve models [9]. The latter case is known to pro- duce synthetic contents with less discernible artifacts [10]. Detecting the synthetic part of an utterance is more com- plicated than deciding whether the utterance is (partially) syn- thetic. For the latter , the detector has to produce a sequence of decisions (or scores that indicate the likelihood of being bona fide), rather than a single binary decision of synthetic or not. Accordingly , a sequential classification model can be implemented by sophisticating a binary deepfake speech de- tector , e.g., extracting sequential latent features from a DNN- based detector and transforming them via additional recurrent * These authors contributed equally . 1 As an of ficial example of the V oiceCraft system by Meta, the origi- nal speech ‘gov ernments don’ t control things ’ was manipulated to ‘go v- ernments don’t control mone y dir ectly ’ [8]. Whisper Fine -tuning using partially vocoded d ata Inference by next- token prediction My textbook V ocoder My < TOF > textbook < EOF> This is agood example! add tokens V ocoded training data Deepfake audio with a synthetic word wav: tokens: Figure 1: Illustration of a fine-tuned Whisper for speech-to-text transcription and synthetic word detection. and denote the tokens surr ounding a synthetic word. layers [11], boundary-matching map [12], or attention mecha- nism [13]. Despite the studies aforementioned, we seek more cost- efficient solutions to locate the synthetic contents in the input utterance. This is motiv ated by the fact that DNN-based mod- els require a full-fledged development flow , including data cu- ration, model designing, model training, and hyper -parameter tuning. Adding a trained model to a speech data processing sys- tem also requires additional computation and storage resources. T o av oid the cost, we explore solutions that add synthetic word detection as an additional function to existing models, particu- larly the automatic speech recognition (ASR) models. In this paper, we inv estigate whether we can fine-tune a pr e- trained ASR model, i.e ., Whisper [14], so that it can detect syn- thetic wor ds while transcribing the input utter ance. 2 T o address this research question, we present a fine-tuning method that re- quires only a minimum change—adding specific tokens to the training data, which is illustrated in Figure 1. This a voids the costs of implementing a new training algorithm or deploying a separate fake detector . T o save the cost of training data curation, we also in vestigate the usage of the training data that contains ‘simulated’ synthetic words created by v ocoders. As f ar as the authors are aware, this is the first study to aug- ment Whisper with the function of synthetic word detection. Our experiments demonstrate promising results. On test sets with data from the same domain as the training data, the fine- tuned Whisper performed on par with a dedicated ResNet model in terms of synthetic word detection, while its text transcrip- tion accuracy was not degraded. On test sets with words syn- thesized by adv anced DNN-based generative models, the fine- tuned Whisper degraded to varying degrees in terms of synthetic word detection and transcription. Further analysis in vestigates how the fine-tuned Whisper is af fected by the domain mismatch between fine-tuning and test data. Improving the out-of-domain detection performance is to be addressed in future work. 2 The term ‘synthetic word’ refers to a wav eform se gment that corre- sponds to a word but whose w aveform signal is synthesized by a model. 2. Methods 2.1. Deepfake word detection via next-tok en prediction Let a speech waveform be x 1: N with N denoting the total num- ber of samples, where x n ∈ R is the amplitude value at the n -th sampling point, n ∈ [1 , N ] . As an ASR model, Whis- per uses an encoder-decoder Transformer structure and con verts x 1: N into a sequence of M tokens y 1: M , wherein each token y m ( m ∈ { 1 , . . . , M } ) usually corresponds to a subword text unit and belongs to a finite set Y pre-defined by a tokenizer . Conceptually , synthetic word detection is to con vert x 1: N into another sequence of tags c 1: M , where each c m ∈ { REAL , FAKE } . A na ¨ ıve implementation is to add another clas- sification head so that the Whisper maps x 1: N → y 1: M × c 1: M , but it requires a change of the model architecture and hyper- parameter tuning (e.g., weights for ASR and detection losses). Our proposed method, which is illustrated in Figure 1, blends synthetic word detection and te xt transcription into a sin- gle next-token prediction task . Fine-tuning the Whisper only requires a minimal change to the tok ens of the fine-tuning data. Suppose that we have pairs of speech utterances and their text transcriptions { x 1: N , y 1: M } , wherein each speech utter- ance contains one or more synthetic words. Assuming that the i -th token belongs to a synthetic word, we insert two to- kens and around y i to obtain a new token se- quence ˆ y 1: M = { y 1 , · · · , , y i , , · · · , y M } . W e now fine-tune the Whisper using pairs of { x 1: N , ˆ y 1: M } , with- out any change to the model architecture or fine-tuning algo- rithm. Inference is performed in the same way as the original Whisper . Given an output sequence of tokens, any token be- tween a pair of and is flagged as synthetic. Note that, for { , } , if we add two new tokens to Y , we need to add additional embedding v ectors to the Whis- per . Hence, we do not introduce new tokens but simply reuse two existing tokens from Y that are unlikely to be used for the ASR task. While other choices are possible, we used the tokens ‘ !!!!!! ’ and ‘ ∼∼∼ ’ as the and , respecti vely . 2.2. Using vocoded data f or fine-tuning Whisper A common approach to prepare the training data { x 1: N , ˆ y 1: M } is to use di verse speech generative models to synthesize the se- lected words, which requires extra text or source audio input. T o simplify the data curation pipeline, we are inspired by [15] and use v ocoders to create simulated synthetic words. Giv en a pair of { x 1: N , y 1: M } , we use WhisperX to obtain word-le vel align- ment [16]. W e then randomly select one to five words, conduct copy-synthesis [15] on their corresponding w aveform segments via a vocoder , and replace the segments in the original wa ve- form with the vocoded versions. This process only needs to extract the acoustic features (e.g., mel spectrogram) and resyn- thesize the wav eform. The vocoded waveforms are assumed to preserve the voice identity as well as the artifacts that are similar to those caused by speech generativ e models [15]. Note that, when replacing the wav eform segments with their corresponding v ocoded counterparts, we use an overlap- add algorithm to ensure a smooth transition between the bona fide and the vocoded parts [11]. The source data and vocoders used in this study are explained in the ne xt section. 3. Experiments T o answer the research question raised in § 1, we testify the models’ performance on synthetic w ord detection as well as te xt transcription, using training and test data sets listed in T able 1. 3.1. Data and protocols Fine-tuning data : we compared fine-tuning data sets using ut- terances altered by vocoders, speech synthesis systems, or both: • Ft.Voc : a vocoded fine-tuning data set constructed on the basis of MLS dataset [17]. W e randomly selected 2,100 utter- ances per each of the 5 languages: English (en), Italian (it), German (de), French (fr), and Spanish (es). In each utterance, one to fi ve words were randomly selected and vocoded using the method in § 2.2 and using each of the six vocoders (or wa veform reconstruction methods): HiFi-GAN[18], W av eG- low [19], Hn-NSF [20], a hybrid v ocoder with Hn-NSF as the generator and the HiFi-GAN’ s discriminators, WORLD [21], and Griffin-Lim (GL) [22]. The first four vocoders are based on DNNs, and the last two use signal processing techniques. If an utterance failed to be vocoded (e.g., due to F0 e xtraction error), it was removed. This produced Ft.Voc with around 60k utterances ( ≈ 2100 × 5 × 6 ). • Ft.TTS : a subset of the LlamaPartialSpoof corpus [23] with the same number of randomly selected utterances as Ft.Voc . The synthetic words were generated by one of the six text-to-speech (TTS) systems: JETS [24], Y ourTTS [25], XTTS [26], SoVITS [27], CosyV oice [28], and Elev enLab 3 . • Ft.V+T : a dataset with 50% of the data randomly sampled from Ft.Voc and the rest sampled from Ft.TTS . A v alidation set for Ft.Voc was also created but using another 300 utterances per language. A validation set with the same size as that of Ft.Voc was sampled from LlamaPartialSpoof for Ft.TTS . Then, the validation set for Ft.V+T was merged from the two v alidation sets via random sampling. T est data : the E.Voc measures the performance on vocoded words, while the others measure the performance on data generated by DNN-based speech synthesis or editing sys- tems. In terms of the data domain, E.Voc and E.TTS are sourced from audio books, the same domain as the that of the training sets. In contrast, E.AV1M and E.PE are out-of-domain data since they are sourced from Y outube or a studio. • E.Voc : a vocoded data set constructed in the procedure as Ft.Voc but using two unseen v ocoders and 600 utterances for each of the five languages. The utterances are disjoint from the training and validation sets. • E.TTS : a subset of LlamaPartialSpoof with 3,000 utterances (disjoint from Ft.TTS or Ft.V+T ). • E.AV1M : a subset of the A V -Deepf ake 1M validation set [29]. The synthetic words in the utterances were created using the TTS systems called VITS [30] and Y ourTTS [25]. • E.PE : a subset of PartialEdit [9], wherein synthetic words are created using the publicly av ailable attacks. One is the V oiceCraft [8], a LLM-based speech editing system that ma- nipulates words via modifying the token. The other is also a LLM-based speech editing system called SSR-speech [31]. 3.2. Models and training configurations W e use the pre-trained Large (v3) Whisper checkpoint [14]. The fine-tuning was done on the entire model with a learning rate of 1e-5 and a batch size of 8 (to fit the size of a single Nvidia H100 GPU card). 4 T raining was conducted for fiv e epochs, and the 3 https://elev enlabs.io/ 4 W e tried LoRA [32] but had no impro vement. T able 1: Statistics of fine-tuning ( Ft. ) and test ( E. ) data sets. Generators using TTS systems ar e in an italic typeface. Name #. utterance Language(s) Domain Generator of synthetic words T rain data Ft.Voc 60,596 en, es, fr , it, de Audiobook HiFi-GAN, NSF , NSF+GAN, W av eGlow , WORLD, GL Ft.TTS 60,596 en Audiobook JETS, Y ourTTS, XTTS, SoVITS, CosyV oice, ElevenLab Ft.V+T 60,596 en, es, fr , it, de Audiobook All above T est data E.Voc 3,000 en, es, fr , it, de Audiobook HiFi-GAN, NSF , NSF+GAN, W av eGlow , WORLD, GL E.TTS 3,000 en Audiobook JETS, Y ourTTS, XTTS, SoVITS, CosyV oice, ElevenLab E.AV1M 3,000 en Y outube Y ourTTS, VITS E.PE 3,000 en Studio rec. V oiceCraft, SSR-speech best checkpoint on the validation set w as used for ev aluation. W e also trained a ResNet152 [33] for synthetic word de- tection, which was the sub-component of the top system in the localization track of the 1M-deepfakes detection challenge [33]. The input wav eform was transformed into mel spectrogram in the same setting as Whisper’ s front end. The model produces approximately one detection score per 16 ms. A training label ( REAL or FAKE ) w as prepared per 16 ms given the ground-truth time alignment. Training was done using binary cross entropy for a maximum of 30 epochs, and the best checkpoint on the validation set w as used for ev aluation. 3.3. Evaluation metrics The text transcription performance is measured using the word error rate (WER) implemented by the JIWER toolkit [34]. The WER is computed after removing { , } in the model’ s output and ground truth transcription. Giv en the word alignment from the JIWER, the synthetic word detection is measured using the follo wing metrics: • false acceptance rate (F AR): among the synthetic words, the ratio of those being mis-classified as real; • false rejection rate (FRR): among the real words, the ratio of those being mis-classified as synthetic; Note that, even if a word is mis-recognized, it is not counted as detection error when REAL or FAKE is correctly labeled. Because Whisper makes hard decision when detecting the syn- thetic words, for a fair comparison, we let ResNet make hard decision as well. F or ev ery word in a test utterance, the output probabilities from the ResNet’ s softmax layer aligned with the word were av eraged as the probabilities of being REAL ( P real ) and FAKE ( P fake ). A word is classified as real if P real > P fake . 3.4. Results on in-domain data In § 3.4.1, we analyze the setups wherein the fine-tuning and test data are matched in terms of data domain and synthe- sis methods, i.e., training on Ft.Voc and testing on E.Voc ( Ft.Voc → E.Voc ), and training on Ft.TTS and testing on E.TTS ( Ft.TTS → E.TTS ). In § 3.4.2, we discuss the crossed cases, i.e., Ft.Voc → E.TTS and Ft.TTS → E.Voc . Evalua- tion across the domains is presented in § 3.5. 3.4.1. Matched data domain and synthetic methods On E.Voc , the Whisper fine-tuned on Ft.Voc obtained a lower WER (0.87%) than the pre-trained Whisper (23.89%). This is not surprising because both the fine-tuning and test data are in the domain of audiobooks. In terms of synthetic word detection, the Whisper fine-tuned on Ft.Voc obtained F AR 7.22% and FRR 0.52%. The results are on a par with the ResNet (F AR 7.15% and FRR 3.81%). W e observe similar results on T able 2: Results on E.Voc and E.TTS . Bold text indicates the best r esult in each column and each test set. Data set WER(%) Whisper F AR (%) FRR (%) T est Fine-tune Whisper ResNet Whisper ResNet E.Voc Pre-trained 23.89 Ft.Voc 0.87 7.22 7.15 0.52 3.81 Ft.V+T 2.18 8.45 9.80 1.01 5.32 Ft.TTS 35.11 18.86 76.42 78.59 9.08 E.TTS Pre-trained 8.13 Ft.Voc 12.58 76.16 83.04 9.01 10.14 Ft.V+T 3.86 2.08 0.34 3.82 32.90 Ft.TTS 2.20 1.38 0.15 1.79 3.13 E.TTS . The Whisper fine-tuned on Ft.TTS obtained a lo wer WER (2.20%) than the pre-trained one (8.13%). Meanwhile, the fine-tuned Whisper performed similarly (F AR 1.38% and FRR 1.79%) to the ResNet in synthetic word detection (F AR 0.15% and FRR 3.13%). Note again that the training and test utterances do not over- lap in terms of speech contents. The results suggest that, in the case wherein the data domain and synthetic methods match , the fine-tuned Whisper can well detect synthetic words while transcribing the input utterance via next-token prediction . The fine-tuned Whisper performed on par with a well-known ResNet-based detection model, e ven though the de- tection is just an add-on to the Whisper’ s transcription function. Example outputs of the fine-tuned Whisper are listed below , where wrong detection is marked with a red color . Note that the word Cay-Man is correctly marked as FAKE , ev en though it is not correctly transcribed. More examples are in the Appendix. Ground truth: I present to you the human genome. Ft.Voc → E.Voc : I present to you the human genome. Ground truth: But I could not bear the thought of wearing decayed boots. Ft.TTS → E.TTS : But it could not bear the thought of wearing Cay-Man boots . 3.4.2. Matched data domain b ut differ ent synthetic methods When evaluating across the test sets in the same audiobook domain, the performance of fine-tuned Whisper and the ResNet degraded to different degr ees . On E.Voc , the fine-tuned Whisper and the ResNet trained from scratch using Ft.TTS obtained higher F AR and FRR than 0.04 0.12 0.20 0.28 0.35 0.43 0.51 0.59 0.67 0.75 Duration (s) 0 20 40 60 80 100 Error rates (%) F AR Ft.V oc FRR Ft.V oc F AR Ft.TTS FRR Ft.TTS 10 3 10 4 Count (a) Err or rates on E.Voc 0.04 0.11 0.18 0.25 0.32 0.40 0.47 0.54 0.61 0.68 Duration (ms) 0 20 40 60 80 100 Error rates (%) F AR Ft.V oc FRR Ft.V oc F AR Ft.TTS FRR Ft.TTS 10 3 10 4 Count (b) Err or rates on E.TTS Figure 2: Analysis of synthetic word detection err or rates based on word duration. Black and r ed pr ofiles corr espond to the fine- tuned Whisper using Ft.Voc and Ft.TTS , respectively . their counterparts using Ft.Voc . F or analysis, we calculated the F AR and FRR values e valuated after grouping the words based on their durations. Figure 2 (a) plots the results of the Whisper fine-tuned on Ft.Voc (black profiles) or Ft.TTS (red profiles). While the F ARs of the two fine-tuned Whispers are close, the FRR when using Ft.TTS (red dashed line) is around or higher than 80%. In contrast, the FRR in the case of using Ft.Voc (black dashed line) is close to 0%. T o further in vestigate the above result, we analyzed the er- rors across the languages using E.Voc . The results presented in T able 3 show that using Ft.TTS led to F AR and FRR abo ve 40% on the English data. On other languages, it obtained F ARs similar to those in the case of using Ft.Voc but FRRs close to 90%. This suggests that the increased FRR when training on Ft.TTS but testing on E.Voc is due to the unseen languages. On E.TTS , the results in T able 2 show that the Whisper fine-tuned on Ft.Voc obtained higher F AR and FRR than its counterparts using Ft.TTS . Particularly , its F AR was as high as 76%. As analysis, we plot the F ARs and FRRs against the word duration in Figure 2 (b) and observ e that the Whisper fine- tuned on Ft.Voc obtained high F AR (black solid line) regard- less of the word duration. The high F AR values suggest that the Whisper fine-tuned on the vocoded training data strug- gles to spot words created by the TTS systems . Using more div erse vocoders may improve the performance, but the explo- ration is left to future work. Note that the FRR of the Whisper fine-tuned on Ft.Voc increases when the word is longer (black dashed line in Figure 2 (b)). The same trend is observed on the Whisper fine-tuned using Ft.TTS (red dashed line). One hypothesis is that the fine-tuned Whisper seems to flag REAL only if it does not find any artifact within a word. The longer a word is, the more likely it contains patterns similar to artifacts. 3.5. Results on out-of-domain test data Giv en the results above, it is not surprising that the performance of the fine-tuned Whisper and the ResNet also degraded on the out-of-domain test data. As T able 4 shows, on both E.AV1M T able 3: Decomposed r esults over languages, using the pr e- trained Whisper (left) or fine-tuned on Ft.Voc (right). F AR (%) FRR (%) Ft.Voc Ft.TTS Ft.Voc Ft.TTS en 8.38 46.28 0.50 40.97 fr 10.41 11.54 0.78 91.19 es 5.59 10.76 0.36 89.36 de 5.47 8.97 0.40 91.80 it 6.30 13.03 0.53 88.12 T able 4: Results on test sets manipulated by DNN-based speec h synthesis and editing systems. W ithin eac h column, a value with a darker color indicates a worse performance . Data set WER(%) Whisper F AR (%) FRR (%) T est Fine-tune Whisper ResNet Whisper ResNet E.AV1M Pre-trained 14.72 Ft.Voc 23.17 39.98 33.70 7.70 17.69 Ft.V+T 21.23 15.98 27.63 39.42 27.04 Ft.TTS 20.47 16.04 11.14 59.97 36.44 E.PE Pre-trained 3.64 Ft.Voc 5.01 78.60 88.75 9.61 11.97 Ft.V+T 4.81 28.39 36.56 49.90 40.44 Ft.TTS 5.77 8.74 30.92 87.89 52.49 and E.PE , we observe higher WER when the Whisper is fine- tuned using either vocoded or TTS-synthesized data. In terms of synthetic word detection, the detection performance is ov erall unstable. For example, in the case of training using Ft.Voc and testing on E.PE , both models obtained lo w FRRs ( 10%) but very high F ARs ( 80%). In short, current out-of-domain synthetic word detection is not yet sufficiently r eliable. Note that, in the case of using Ft.TTS , comparison be- tween the results on E.TTS and E.AV1M sho ws that both the fine-tuned Whisper and ResNet performed worse on E.AV1M , ev en though the synthesizers ( Y ourTTS and VITS ) are cov ered by the training data. Hence, to improve the out-of-domain per- formance, understanding the differences across datasets may be more important than complicating the model architecture. 4. Conclusion W e proposed a method for fine-tuning Whisper to detect syn- thetic words while preserving its speech-to-text transcription capability . The proposed method requires only augmenting the text token sequences with tokens that mark synthetic words, with no change to the algorithm or model architecture. This integrates the detection task into the ne xt-token prediction task. In the experiment wherein the training and test data matched, the fine-tuned Whisper , while doing transcription, detected the synthetic words with a performance comparable to a dedicated ResNet-based detection model. Howe ver , results on multiple test sets also demonstrate that the detection performance de- graded when there is a data domain mismatch between the train- ing and test sets. A better understanding of the cross-domain differences is needed for future work. Using vocoded training data did not alle viate the degradation when the synthetic words are from a different domain or unseen synthesizers. Future work will in vestigate using vocoded data from diverse synthesizers and domains. 5. Acknowledgment This work is partially supported by JST , PRESTO Grant (JP- MJPR23P9), and K Program Grant (JPMJKP24C2), Japan. It is partially done on TSUB AME4.0, Institute of Science T okyo. 6. Generative AI Use Disclosur e Generativ e AI was used to check grammatical errors. 7. References [1] J.-w . Jung et al., “ AASIST : Audio anti-spoofing using in- tegrated spectro-temporal graph attention networks, ” in Pr oc. ICASSP , 2022, pp. 6367–6371. [2] Q. Zhang, S. W en, and T . Hu, “ Audio Deepfake Detec- tion with Self-Supervised XLS-R and SLS Classifier , ” in Pr oc. A CM MM , Oct. 2024, pp. 6765–6773. [3] M. R. Kamble et al., “Advances in anti-spoofing: From the perspectiv e of ASVspoof challenges, ” APSIP A T rans. SIP , vol. 9, e2, 2020. [4] H. T ak et al., “ Automatic speaker verification spoofing and deepfake detection using w av2vec 2.0 and data aug- mentation, ” in Pr oc. Odyssey , 2022, pp. 112–119. [5] M. T odisco et al., “ASVspoof 2019: Future horizons in spoofed and fake audio detection, ” in Pr oc. Interspeec h , 2019, pp. 1008–1012. [6] J. Y i et al., “ADD 2023: The Second Audio Deepfake Detection Challenge, ” in Pr oc. IJCAI W orkshop onDeep- fake A udio Detection and Analysis , 2023. [7] T . Kirill et al., “SAFE: Synthetic Audio F orensics Evalu- ation Challenge, ” in A CM W orkshop IH&MMSEC , 2025, pp. 174–180. [8] P . Peng et al., “V oiceCraft: Zero-shot speech editing and text-to-speech in the wild, ” in Proc. A CL , 2024, pp. 12 442–12 462. [9] Y . Zhang et al., “PartialEdit: Identifying Partial Deep- fakes in the Era of Neural Speech Editing, ” in Proc. In- terspeech , 2025, pp. 5353–5358. [10] S.-F . Huang et al., “Detecting the Undetectable: Assess- ing the Efficacy of Current Spoof Detection Methods Against Seamless Speech Edits, ” in Pr oc. SLT , Macao, Dec. 2024, pp. 652–659. [11] L. Zhang et al., “The PartialSpoof Database and Coun- termeasures for the Detection of Short Fak e Speech Seg- ments Embedded in an Utterance, ” IEEE/A CM T rans. ASLP , pp. 1–13, 2022. [12] X. Chen et al., Localizing Audio-V isual Deepfakes via Hierar chical Boundary Modeling , Aug. 2025. [13] M. Li, X.-P . Zhang, and L. Zhao, “Frame-lev el tempo- ral dif ference learning for partial deepfake speech detec- tion, ” IEEE SPL , vol. 32, pp. 3052–3056, 2025. [14] A. Radford et al., Rob ust Speech Recognition via Lar ge- Scale W eak Supervision , Dec. 2022. [15] X. W ang and J. Y amagishi, “Spoofed training data for speech spoofing countermeasure can be efficiently cre- ated using neural vocoders, ” in Pr oc. ICASSP , 2023. [16] M. Bain et al., “WhisperX: Time-accurate speech tran- scription of long-form audio, ” in Pr oc. Interspeech , 2023, pp. 4489–4493. [17] V . Pratap et al., “MLS: A large-scale multilingual dataset for speech research, ” in Pr oc. Interspeech , 2020. [18] J. Kong, J. Kim, and J. Bae, “HiFi-GAN: Generativ e ad- versarial networks for efficient and high fidelity speech synthesis, ” Advances in neural information pr ocessing systems , vol. 33, pp. 17 022–17 033, 2020. [19] R. Prenger, R. V alle, and B. Catanzaro, “W aveGlo w: A flow-based generative network for speech synthesis, ” in Pr oc. ICASSP , 2019, pp. 3617–3621. [20] X. W ang, S. T akaki, and J. Y amagishi, “Neural source- filter wav eform models for statistical parametric speech synthesis, ” IEEE/ACM T rans. ASLP , vol. 28, pp. 402– 415, 2019. [21] M. Morise, F . Y okomori, and K. Ozawa, “WORLD: A vocoder-based high-quality speech synthesis system for real-time applications, ” IEICE T rans. on Information and Systems , vol. 99, no. 7, pp. 1877–1884, 2016. [22] D. Griffin and Jae Lim, “Signal estimation from mod- ified short-time Fourier transform, ” IEEE T rans. ASSP , vol. 32, no. 2, pp. 236–243, Apr . 1984. [23] H.-T . Luong et al., “LlamaPartialSpoof: An LLM-Driven Fake Speech Dataset Simulating Disinformation Gener- ation, ” in Pr oc. ICASSP , 2025. [24] D. Lim, S. Jung, and E. Kim, “JETS: Jointly Train- ing FastSpeech2 and HiFi-GAN for End to End T ext to Speech, ” in Pr oc. Interspeech , Sep. 2022, pp. 21–25. [25] E. Casanov a et al., “Y ourTTS: T owards zero-shot multi- speaker TTS and zero-shot voice con version for every- one, ” in Pr oc. ICML , 2022, pp. 2709–2720. [26] E. Casanov a et al., “XTTS: A massi vely multilingual zero-shot te xt-to-speech model, ” in Pr oc. Interspeec h , 2024, pp. 4978–4982. [27] R VC-Boss and contributors, Gpt-sovits: F ew- shot voice con version and text-to-speec h webui , https://github .com/R VC-Boss/GPT -SoVITS, Feb . 2024. [28] Z. Du et al., “CosyV oice: A Scalable Multilingual Zero- shot T ext-to-speech Synthesizer based on Supervised Se- mantic T okens, ” no. arXiv:2407.05407, Jul. 2024. [29] Z. Cai et al., “A V -Deepfake1M: A Large-Scale LLM- Driv en Audio-V isual Deepfake Dataset, ” in Proc. ACM MM , 2024, pp. 7414–7423. [30] J. Kim, J. Kong, and J. Son, “Conditional v ariational au- toencoder with adversarial learning for end-to-end text- to-speech, ” in Pr oc. ICML , 2021, pp. 5530–5540. [31] H. W ang et al., “SSR-Speech: T ow ards Stable, Safe and Robust Zero-shot T ext-based Speech Editing and Syn- thesis, ” in Pr oc. ICASSP , Apr . 2025, pp. 1–5. [32] E. J. Hu et al., “LoRA: Low-Rank Adaptation of Large Language Models, ” in Pr oc. ICLR , vol. abs/2106.09685, 2022. [33] N. Klein et al., “Pindrop it! Audio and visual deepfake countermeasures for robust detection and fine-grained localization, ” in Pr oc. A CM MM , 2025, pp. 13 700– 13 706. [34] N. V aessen, JiWER: A simple and fast python pack- age to e valuate an automatic speech r ecognition system , https://github .com/jitsi/jiwer. A. Example of synthetic word detection A.1. Example on vocoded test set E.Voc These are detection outputs using Whisper fine-tuned on Ft.Voc . REF and HYP refers to the ground-truth and Whisper output. The start and end of a faked w ord are marked by ‘ !!!!!! ‘ and ‘ ∼∼∼ ‘, respectiv ely . Example 1: correctly identified all synthetic words REF: !!!!!!Now˜˜˜ this !!!!!!isn’t˜˜˜ absolutely definitive. It’s !!!!!!not˜˜˜ to say that the idea isn’t important. HYP: !!!!!!Now˜˜˜ this !!!!!!isn’t˜˜˜ absolutely definitive. It’s !!!!!!not˜˜˜ to say that the idea isn’t important. Example 2: faked ‘weiter’ is not detected (false acceptance), while real ‘leben’ is incorrectly marked as f ake (false rejection). REF: selber verdienen und leben !!!!!!weiter.˜˜˜ HYP: selber verdienen und !!!!!!leben˜˜˜ weiter. Example 2: faked ‘wie’ and ‘und’ are not detected (false acceptance), while real ‘dann’ is incorrectly detected (false rejection). REF: solche Sachen !!!!!!wie˜˜˜ !!!!!!dieses˜˜˜ Licht !!!!!!und˜˜˜ dann diese Baume, die HYP: solche Sachen wie !!!!!!dieses˜˜˜ Licht und !!!!!!dann˜˜˜ diese Baume, die A.2. Example on A VDeepfake-1M test set E.AV1M These are detection outputs using Whisper fine-tuned on Ft.Voc . Example 1: the synthetic word is corrected identified REF: To give kids that !!!!!!different˜˜˜ experience and hopefully them make those kind of friendships ... HYP: To give kids that !!!!!!different˜˜˜ experience and hopefully them make those kind of friendships ... Example 2: synthetic ‘want’ and ‘it’ are mis-classified as real (false acceptance) REF: He !!!!!!doesn’t˜˜˜ !!!!!!want˜˜˜ to talk about !!!!!!it˜˜˜ all the time, and whenever I start talking about it HYP: He !!!!!!doesn’t˜˜˜ want to talk about it all the time, and whenever I start talking about it Example 3: ‘enjoy’ is mis-recognized and mis-identified as a synthetic word (false rejection) REF: delivery so I really !!!!!!didn’t˜˜˜ enjoy putting together my own album and finding my own sound. HYP: delivery, so I really !!!!!!didn’t˜˜˜ !!!!!!kind˜˜˜ of putting together my own album and finding my own sound and A.3. Example on PartialEdit test set E.PE These are detection outputs using Whisper fine-tuned on Ft.Voc . Example 1: transcription error happened on ‘harmful’, but the synthetic word is corrected marked. REF: Mixing drugs and alcohol can be extremely !!!!!!harmful.˜˜˜ HYP: Mixing drugs and alcohol can be extremely !!!!!!humble.˜˜˜ Example 2: the real ‘go’ is incorrectly marked as fake (false rejection). REF: but you can go !!!!!!beneath˜˜˜ that condition. HYP: But you can !!!!!!go˜˜˜ !!!!!!beneath˜˜˜ that condition. Example 3: the synthetic ‘fitting’ is incorrectly marked as real (false acceptance). It seemed a moving and !!!!!!fitting˜˜˜ !!!!!!destruction.˜˜˜ It seemed a moving and fitting !!!!!!distraction.˜˜˜
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment