Multi-Agent Reinforcement Learning for Dynamic Pricing: Balancing Profitability,Stability and Fairness
Dynamic pricing in competitive retail markets requires strategies that adapt to fluctuating demand and competitor behavior. In this work, we present a systematic empirical evaluation of multi-agent reinforcement learning (MARL) approaches-specificall…
Authors: Krishna Kumar Neelakanta Pillai Santha Kumari Amma
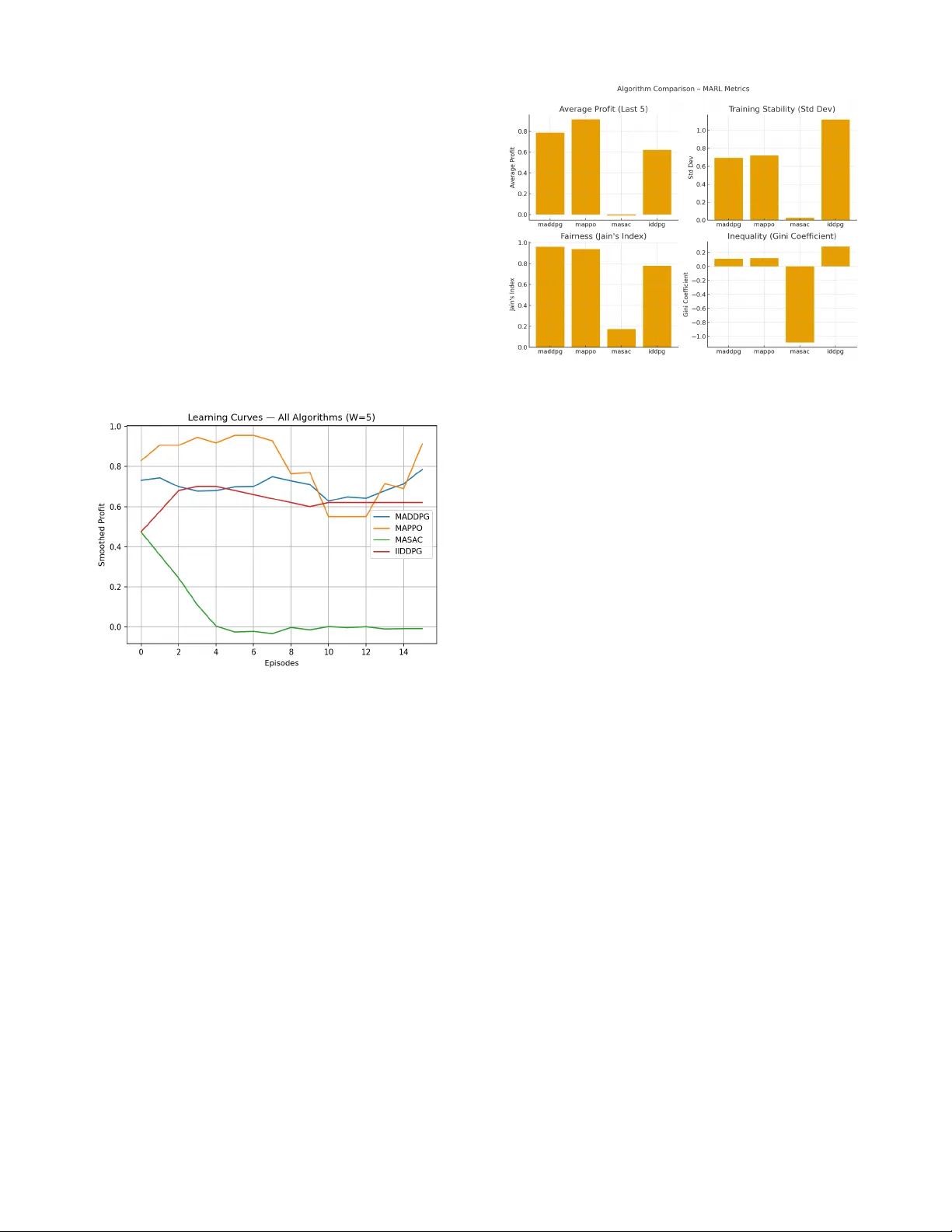
Abstract — Dynamic pricing in competitive retail markets requires strategies that adapt to fluctuating demand and competitor behavior. In this work, we present a syst ematic empirical evaluation of multi - agent reinforcement learning (MARL) approaches — specifically MAPP O and MADDPG — for dynamic price optimization under competition. Using a simulated marketp lace envi ronment de rived fr om re al - world retai l da ta, we benchmark thes e alg orithms against an Independent DDPG (IDDPG) baseline, a widely used independent learner in M ARL literature. We evaluate profit performance, stability across random seeds, fairness, and training efficiency. Our results show that MAPPO consistently achieves the highest average returns with low variance, offering a stable and reproducible approach for competitive price optimization , while MADDPG achieves slightly lower profit but the fairest profit distribution among agents. These findings demonstrate that MARL methods — particularly MAPPO — provide a scalable and stable alternat ive to independent learni ng approaches for dynamic reta il pricing. Index Term s — Centralized Training Decen tralize d Execution (CTDE), Competitive Pricing, Dynamic Pricing, E - Commerce Optimiza tion, IDDPG Baseli ne, MADDPG, MAPPO, MASAC, Multi - Agent Rei nforcement Learn ing ( MARL), Per formance Evaluation, Retail Market Si mulation, Stabili ty Analysis I. INTRODUCTION Dynamic prici ng plays a critical role in modern ret ail and e - commerce platforms, where sellers must continuously adjust prices to respond to fluctuati ng demand, inventory levels, and competitor actio ns. Traditional approaches o ften rely on static business rules, manual price adjustm ents, or heuristics that struggle to adapt effectively to rapidly shift ing market co nditions. This le ads to s uboptimal profit outcomes and misses opportunities for personalized pri cing strategies. Reinforcement Learning (RL) o ffers a pr omising alternative by enabling agents to learn pr icing policies that maximize l ong - term cumulative reward throu gh interaction with the e nvironment. In multi - seller settings, however, the pricing problem becomes a mul ti - agent reinforcement learning (MARL) task, where each agent’s dec ision impacts others, and coordination or competition emerges naturally. MARL methods ha ve shown po tential to produ ce more a daptive and profitable strategies, but challenges remain in achieving stable training, reproducibility acro ss random seeds, and scalab ility to large action/state spaces typ ical of retail markets. In this work, we conduct a systematic empiric al evaluation of several state - of - the - art MARL algorithms for dynamic retail pricing under competition. Specifi cally, we investigate: • MAPPO (Mul ti - Agent Prox imal Policy Optimization) , an on - policy cent ralized training – decentralized execution (CTDE) algorithm, • MASAC (Mult i - Agent Soft Actor - Critic ), an off - policy entropy - regularized algorithm, • MADDPG (Mult i - Agent Deep Determinist ic Policy Gradient), a widely s tudied act or – critic baseline and compare them against an Independent DDPG (IDDPG) baseline, a common reference point in MARL lit erature. Our evaluat ion is per formed in a simulated marketplace environment constructed from real - world re tail tran saction data, allowing us to model reali stic demand elasticity and competitive interactions. We measure each algorithm’s profit performance, training stability across random seeds, and sample efficiency. The key contribut ions of this paper are: 1. Comprehensive ben chmarking of MAPPO, MASAC, and MADDPG against an IDDPG baseline in a retail dynamic pricing environment. 2. Stability and reproducibi lity analysis across multiple seeds, highlighting MAPPO’s low variance and consistent performance. 3. Performance insights show MASAC achieving high peak rewards but suffering from instabi lity, providing guidance for practitioners on t rade - offs between exploration and reliability. 4. Practical implications for deploying MARL in retail markets, demonstrat ing that MAPPO is practical and reliable for real - world retail application s . The results demon strate that MAPPO consistently achieves the highest mean profits with signi ficantly lower variance than MASAC and MADDPG, maki ng it a str ong cand idate for rea l - world dynamic pricing systems. Multi-Agent Reinforcement Learning for Dynamic Pricing: Balancing Profitability, Stability and Fairness Krishna Kumar Neelakanta Pil lai Santha Kumari Amma II. LITERATURE REVIEW A. Dynamic Pricing a nd Rule - Based Methods Dynamic prici ng has lo ng been a key lever in retail revenue management. Early appro aches relied on static business rules, simple demand models, or manual price adjustments driven by domain experts. These rule - based strategies are easy to deploy but are inh erently myopic, failing to adapt optimally to cha nging market conditions, co mpetitor actions, and demand shifts. Recent studie s indicate that reinforcement learnin g (RL) can surpass rule - based approaches by continually adapting through interactions with the environment. Liu et al. (20 19) [1] reported in a large - scale field experiment on A libaba’s Tmall platform t hat deep RL – driven pricing “s ignificantly outperformed the manual pricing by operati on experts,” leading to measurable im provements in GMV (gross merchandis e volume) and conve rsion ra tes. Similarly, Kephart and Greenwald [4] showed that Q - learning Pricebo t consistently achieved higher long - term profits than fixed - strategy Pricebot in competitive markets, valid ating the superiority of learning - based approaches over static heuristics. Further supporting this transition from rule - based systems to RL, K ropp et al. (20 19 ) [5] demonstrated that multi - agent RL for product cluster pr icing improved daily profi ts by 7 – 8% over static price control and by over 25% compared to single - agent RL methods, demonstrating the economic and scalability benefits of MARL in retail pricing . B. Independent vs. Multi - Agent Reinforcement Learning While i ndepen dent learni ng app roache s suc h as Independent DDPG (IDDP G) train each agent in isolation, they often fail to account for th e coupled nature of compe titive markets. This can lead to unstable or osci llatory pricing behaviors and suboptimal equilibria. Greenwald et al. (1999) [4] and subsequent works showed that when multiple independent learners com pete, convergence is not gu aranteed and can result in chaotic price fluctuat ions. To address these issues, mult i - agent reinforcement learning (MARL) has been proposed, where agents are trained jointly under a centralized training – decentrali zed execution (CTDE) paradigm. MARL methods have been shown to produce more coordinated and stable strategies, improving collective reward or individual profitabili ty in competitive settings. Villarrubia - Martín et al. (2025) [6] demonstrated that MARL agents in a transportation pricing dom ain learned adaptive strategies th at responded to user preferences and outperfo rmed simpler heuristics on profit metrics . Recent benchmark s (Yu et al. , 2022) [2] suggest that MAPPO (Mul ti - Agent PPO) provides superior s tability and reproducibility compared to independen t learners and several state - of - the - art MARL baselines (e.g., MADDPG, COMA, QMIX). MADDPG remai ns a popul ar baseli ne due to its simplicity and effectiveness in continuous action spaces, making it a natur al point of compar ison for new MARL algorithms. C. Positi oning of This Work Building on th ese insights, our work fo cuses on benchmarking three representative MARL algorithms — MAPPO (on - policy) , MASAC (off - policy entropy - regularized), and MADDPG (off - policy deterministic) — against an IDDPG baseline in a realistic retail pricing simul ation. While Y u et al. ( 2022) [2] demonstrated that MAPPO achieves strong stability and reproducibili ty across general MARL bench marks, o ur work extend s this analys is to the retail dynamic pricing domain and provid es a head - to - head comparison with M ASAC, MADDPG, and an IDDPG baseline. This allows us to evaluate not only algorithmic stability but also profit performance and competitive pricing behavior in a retail sett ing. This comparison a llows us to qu antify the ben efit of moving from independent le arners to CTDE - based MARL, understand the trade - off between stability (MAPPO) and peak performance potential (MASAC), and evaluate how deterministic policy gradients (MADDPG) perform relative to stochastic policy approaches . III. PROBLEM FORMULATION We cons ider a compe titiv e reta il mark etplace comprising N sellers (agents), each offering a set of products to a shared pool of customers. Time is discret ized into T decision steps per episode, where each step represents a pricing period (e.g., a day). A. State Space At each discrete time step , indexed from 0 to T -1 the environment produces a global state ! !" " #$ % # & # ! that encodes information such as: • Current pric es for all sellers an d SKUs, • Inventory levels or availability indicators, • Observed dema nd signals (e.g., recent sa les veloci ty), • Exogenous market fe atures (seasonal ity, promotio ns, competitor activity). In the CTDE (Centralized Training, D ecentralized Execution) paradigm, this state is us ed centrally for training t he critics but only each agent’s local observation ' ! $ is available to the policy during execution. The observati on ' !" $ " # ( $ # % # & # " # typically includes seller - specific features (its own price, inventory, and recent demand) but not other agents’ private states. B. Action Space Each seller choo ses a pricing action ) ! $ # " # * $ # + # ,- %$& . - %'( ] representing a price adjustment (or absolute price leve l) for its SKU(s). In our implementation, the action space is continuous and normalized to [−1,1], which is later s caled to the real - world price band ,- %$& . - %'( /0 The joint acti on vector at time t is ) ! # + # ,) ! ) . ) ! * . 0 0 0 . ) ! + / , C. Reward Fun ction After all ag ents select their pri ces, the mar ketplace si mulator computes sales, demand allocation, and profits. Each agent i receives a scalar reward 1 ! $ + 2 $ 3- ! $ . 4 ! $ 5 # 6 # 7 $ 34 ! $ 5. where 8 -" . is the price, 4 ! $ # is realized demand, 2 $ # is revenue, and 7 $ # ( 9 ) is the cost function (if applicable). We optimize profi t max imizatio n, so the global obj ective is to maximize t he expect ed disco unted ret urn: :3; 5 + #< => ? ! ,/ ) !01 # @ A # > 1 ! $ + $ 0 ) B . where ?# " [0,1) is the discount fac tor . D. Transition Dynamics The environment fo llows a Markov Deci sion Process ( MDP) with joint transiti on dynamics C#3! !2) #D#! ! #. ) ! 5# where demand response is governed by a demand mode l D ( 9 ) calibrated from historical data to capture price elasticity, cross - elasti city, and stochastic noise. E. Mult i - Agent RL Objecti ve The problem is t hus formulated as a stochasti c game or multi - agent MDP. Under CTDE, a centralized critic E #3! ! 5# '1 #F 3! ! . ) ! 5# is trained to estimate the glo bal value of joint states or state - action pairs, while decentralized actors 2 3 $ #3' ! $ 5# are trained to output actions conditioned only on local observations. The optimization objective for each agent is : G)H 3 # : $ #3; $ 5 # + < 4 $ => ? ! # ,/ ) !01 1 ! $ B #.#### where the e xpectation is over trajectori es generat ed by the joint policy 2 3 #3) ! D#' ! ) IV METHODOLO GY This section d escribes the al gorithms benchmark ed in this study and the training procedure used to evaluate their performance in the retail dynamic pri cing environment. Our approach follows a centralized training – decentralized execution (CTDE) paradigm, where a centralized critic is used during training to stabil ize learning, but each agent executes its policy using only loca l observations. A. Benchmarked Algor ithms Independent DDPG (IDDP G) IDDPG serves as our baseline and represents a cla ss of independent learner algo rithms in multi - agent reinforcement learning. Each agent trains its own Deep Deterministic P olicy Gradient (DDP G) actor – critic pair, treating other agents as part of the environ ment . While c omputation ally si mple, thi s approach often suffers from non - stationarity because each agent’s policy changes during training, which can destabilize learning in competitive m arkets. MADDPG Multi - Agent Deep Determin istic Poli cy Gradient (MADDPG) extends DDPG to the CTDE setting by maintaining a centralized critic F $ #3!. ) ) . ) * . 0 0 0 0 0 . ) + 5# for each agent, conditioned on the joint state and joint actions, while keeping decentralized actors 2 $ #3' $ 5 for execution. This allows each agent to learn a better gradient signal that accounts for other agents’ actions, improving coordination and convergence stability relative to IDDPG. MASAC Multi - Agent Soft Actor – Cri tic (MASAC) is an off - policy, entropy - regularized algorithm that encourages exp loration by maximizing both expe cted ret urn and a policy entropy term. Each agent maintai ns two Q - networks and a target network to reduce overestimatio n bias. MASAC is more sample - efficient than on - policy methods but can be more sensitive to hyperparameter choices, sometimes leading to high variance across training runs. We i nclude d MASAC in our benc hmarks despite its sensitivit y and potential instabili ty, as its entropy - driven exploration provides a useful contrast to more stable algorithms and illustrates the trade - off between expl oration and reliability in dynamic pricing. MAPPO Multi - Agent Proximal Pol icy Optimiza tion (MAPPO) is an on - policy policy - gradient algorithm adapted to the CTDE setting. Each agent maintains a stochastic actor 2 $ " 3) $ D#' $ 5 and a centralized value function V(s) shared acros s agents. The objective is optimized using t he clipped surrogate loss: I 5678 3;5 # + < !" J GKL #31 ! 3;5* M ! . 7NK- 31 ! 3;5.@ 6 O . @ P O 5* M ! Q . where 1 ! 3;5 is the likelihood ratio of ne w and old policies and * M ! is the advantage estima te computed using Genera lized Advantage Es timation (GAE) . MAPPO is known for i ts stability and reproducibility, making it a strong candidate for real - world implementa tion . B. Neural Network Architecture All actor networks co nsist of two fully connected layers wit h 128 hidden units and Tanh activations , followed by a linear output layer producing mean actions (and log standard deviations for stochastic pol icies). For MASAC and MADDPG crit ics, joint state –a ction vectors are concatenat ed before passing through two fully connect ed layers (256 – 256 units) with ReLU activations to estimate Q - values. The centralized value network used by MAPPO consists of a similar two - layer MLP with Tanh activations. C. Training Pro cedure Each training e pisode consists of T time st eps. At each s tep, all agents select pricing actions in parallel, interact with the marketpla ce enviro nment, an d receiv e their individua l rewards. The training procedure differs slightly betwe en the on - policy (MAP PO) and off - policy (MASAC, MADDPG, IDDPG) algorithms. MAPPO (On - Policy) Updates MAPPO uses on - policy trajectory rollouts for policy updates. After each episode, we collect the full trajector y 3! ! . ) ! . 1 ! . ! !2) 5 !01 ,/ ) and compute advantages * M ! using Generalized Advantage Es timation ( GAE) with λ=0 .95 and discount factor γ=0.99. The policy is then updated using the clipped surrogate PPO objective with a clipping range of ϵ=0.2. Each batch of trajectory data is shuffled and optimized over 4 PPO epochs with minibatches of si ze 128 to improve sample effici ency. The centralized value network is trained concurrently to minimize mean - squared error between predicted and empirical returns. MASAC, MADDPG, and I DDPG (Off - Policy) Updates For the off - policy algorithms, experiences are stored in a replay buffer. After each environment step, we sam ple minibatche s of si ze 128 fr om the bu ffer to perform gradient updates. • MASAC updat es two Q - networks using a soft Bellman backup a nd optimizes t he stochasti c policy by maximizing the entropy - regularized objective. • MADDPG trai ns a c entrali zed cr itic F $ 3!. ) ) . 0 0 0 . ) + 5 for each agent and updates actors deterministically using the policy gradient from t he centralized Q - function. • IDDPG follows the same update rule as DDPG but trains each agent indepen dently using only local observations and its own criti c. All off - policy methods s hare the same discount factor γ=0.99 and learning rate 3×10 -4 to ensure a fair compariso n with MAPPO. Evaluation Prot ocol Training contin ues for a fixe d number of epis odes. After ever y K episodes (where K=20 in our ex periments), we perfor m evaluation runs with exploration disabled (deter ministic policies for DDPG/MADDPG and mean action for stochastic policies) over multiple episodes and report the mean and standard deviation of cumulative profit. This periodic evaluation enables tracking of stability and convergence trends across random seeds. V EXPERIMENTAL SETUP A. Dataset and Preprocessing We use a tri mmed version of the UCI Online Retail dataset, originally containing ~540,000 t ransaction rows across ~3,700 SKUs. To build a controlled and data - rich simulation environment, we applied the following steps: • Row and SKU Sele ction: Filtered t o approximately 19,000 rows covering the top 50 SKUs by sal es volume, ensuring sufficient demand observat ions per product for model fitting. • Data Cleaning : Removed canceled invoices, negative quantities, and records with missing customer IDs. • Demand Model Fit ting: For each SKU, we t rained a CatBoost gradi ent boosting r egressor to model the price – demand r elationship at a monthly aggregation frequency . The fitted models achie ved: Validation Performance : R 2 =0.654 7 , RMSE ≈ 723.01, MAPE ≈ 1.24. These results indicate a reas onably good predi ctive ability on unseen data, suitable for driving realistic demand simulation. • Train/Validati on Split: The dat a was split chronologically into 160 training periods and 40 validation periods to avoid i nformation leakage from future sales. • Feature Engineering: Constructed per - SKU features including normalized p rice, recent sales velocity, and remaining inventory, which together form the observation vector for each agent. B. Marketplace Si mulation Environmen t The preprocessed dataset is used to parameteri ze a custom Marketpl aceEn v that simulates a com petitive retail marketpla ce. We model N=3 sellers, each acting as an autonomous agent. Each epis ode cons ists of T=24 steps, corresponding to 24 monthly pricing decis ions (two simulated years) . At eac h step: 1. Observation: Each seller observ es its local featu re vector, including normalized price, hi storical sales velocity, and inventory state. 2. Action: Sel lers sel ect a c ontinuous pricing ac tion representing a relative price adjustment within ±30% of the reference price. 3. Demand Allocat ion: Market demand is shared a mong sellers using a softmax market - share model with competition intensity parameter β=10 ,allowing realistic competitive interactions. 4. Reward: Profits are computed using a cost - ratio model with unit cost set to 70% of the selli ng price. 5. State Transition: The environment updates demand history, inventory, and price signals for the next step To better reflect real - world uncert ainty, stochasti c demand noise is added based on the residuals of the fitted demand models. The noise is Gaussian with cali brated standar d deviation (σ≈730) and is clipped at three standard deviations to avoid unrealistic extremes. The envi ronment supports long - term evaluation of pricing strategies under competition and uncertainty . C. Hyperparamete r settings All algori thms are tr ained for 400 episo des per s eed across 10 different random seeds. Key hyperparameters ar e summarized in table 1 Parameter Value Applies to Discount fa ctor γ 0.99 All algori thms Learning rate 3×10 -4 All algori thms PPO clip range ϵ 0.2 MAPPO only GAE parameter λ 0.95 MAPPO only Minibatc h size 128 All algori thms PPO epochs 4 MAPPO only Replay buffer size 10 -5 transitions MASAC, MADDPG, IDDPG Table1 - Key hyperp arameters Hyperparameter s are kept identica l across algorithms wherever applicable to ens ure a fair c omparison. For MASAC, we addition ally use e ntropy coe fficient tuning . D. Evaluati on Metrics To comprehensive ly evaluate algorithm performance, we report metrics covering effici ency, s tabilit y, fai rness, and compet itive behavior: • Average Profit: Mean cumulat ive pr ofit per epis ode over the last five evaluati on runs. • Training Stability: Standard deviation of last -5- episodemeans across 10 seeds, indicati ng reproducibility. • Sample Efficiency: Episodes required to exc eed 80% of the IDDPG baseline’s asymptotic profit . • Learning Curves: Smoothed profit tra jectories (window = 5) over training episodes. • Fairness: Jain’s Index ( 0 – 1, higher = fairer) and Gini Coefficient (lower = fai rer) of pe r - agent profits. • Competitiveness : Price volatilit y (std per agent), undercutting frequency, mean price correlation, competitive intensity and market - share churn (episode - to - episode variation). Evaluations are performed ever y 2 0 e pisodes using deterministic act ions (or mean actions for stochastic policies) over three evaluation episodes, and results are averaged . E. Hardware and Sof tware All experiments were conduct ed o n a home wor kstation with an Intel Core i7 CPU and 32 GB RAM, using CPU - only training. The sof tware stack consisted of Python 3 .10 a nd PyTor ch 2. 2.1. Random seeds were fixed for envi ronment i nitializat ion, network parameter initialization, and action sampling to ensure reproducibility. VI RESULTS AND OBSERVATIONS This section r eports the out comes of the exp eriments based o n the setup described in Sec tion IV. A. Quantitativ e Results Table I I summarizes the performance of all four algorithms across ten random seeds and 20 evaluation episodes. Algorithm Average Profit Training Stability (std) Jain ’ s Index Gini Coeff MAPPO 0.91 0.72 0.94 0.12 MADDPG 0.79 0.69 0.96 0.11 IDDPG 0.62 1.12 0.78 0.29 MASAC - 0.007 0.02 0.17 - 1.08 Table II - Overall met rics of all four algorithms Key Observat ions: • MAPPO achieved the highest aver age profit , outperforming MADDPG (+16 %) and IDDPG (+47 %) w hile maintaini ng high fairness (Jain’ s I ndex = 0.94). • MADDPG pro duced t he fa irest outcomes with the highest Jain’s I ndex (0.96) and lowest Gini coefficient (0.11), suggesting balanced profit distribution among agents. • MASAC fai led t o conv erge t o a profitab le sol ution, with negati ve average profit an d poor fa irness. • IDDPG exhibited the highest variability, confirming the need for more stable C TDE approaches B. Learning Curve s Fig 1. Smoothed profit trajectories for MAPPO, MADDPG, IDDPG and MASAC Fig 1 shows that MAPP O consis tently outper forms o ther algorithms across training episodes, with a minor dip around episodes 10 – 12 followed by recovery. MADDPG is more stable but converges slightly lower than MAPPO. IDDP G remains mostly flat after early training, while MA SA C’s curve drops sharply into negative ter ritory and stays flat, i ndicating failure to learn profitable strategies. C Fairness and Competitiveness Fig 2. Comparison of MARL algor ithm across key metrics Fairness analysis confirms that MADDPG achieves the most balanced profit distribution across agents, while MAPPO offers slightly lower equity but higher profitabili ty. Where price and market - share data were available, MADDPG and MAPPO exhibited moderate pr ice volatility an d market - share ch urn, indicating healthy com petition without excessive un dercutting. Figures 1 and 2 together capture both learning dynamics and overall performance. Fig. 1 shows that MAPPO consistently converges to the highest profit traject ory, whereas MADDPG maintains more sta ble but slightly lower pr ofits, and MASAC fails to learn a profitable policy. Fig. 2 complem ents this by highlighting MAPPO’s superior profitabil ity and MADDPG’s superior fairness, confirming that the choice of algorithm depends on whether maximizing profit or ensur ing equitable agent outcomes is the primary objecti ve. Together, these figures provide a holistic view of algorithm perform ance, stability, and fairness, supporting MAPPO as the most competitive solution for profit maximization in multi - agent pricing, with MADDPG as a strong candidate where fai rness is pri oritized. MASAC exhi bited n egative averag e profi t and a sharp performance collapse early in traini ng (Fig. 1 ). We hypothesize that this fail ure is due to a combination of overestimation bias in Q - values and sensi tivity to entropy regularization coefficients in multi - agent settings. In our environment, where price - setting actions directly affect rewards, MASAC’s stochastic explora tion likely produced overly aggressive pricing polici es, leading to sustained profi t losses. Despite multiple en tropy tuning attempts, MA SAC remained unstable, suggesting that additional stabiliz ation techniques (e.g., twin critics, targ et smoothing, or adaptive entropy adjustment) may be necessary for competitive performance in this domain. VII CONCLUSION This paper inves tigated the a pplication of multi - agent reinforcement learning (MARL ) for dynamic pricing in competitive retail marketplaces. We implemented and evaluated four representative algorithms — IDDPG (baseline), MADDPG, MAPPO , and MAS AC — on a custom environment derived from the UCI Online Retail datas et. The evaluation considered multiple performance dimensions, including average profit, training stability, sample efficiency, fairness (via Jain’s Index and Gini coefficient), and com petitiveness (price volatility, undercutting frequency, and marke t - share churn). Our result s demonstrat e that MAPPO consistent ly achieve s the highest overall profitabili ty, outperforming MADDPG by 16 % and IDD PG by 47 %, whil e mainta ining c ompetiti ve fairness levels. MADDPG, while sligh tly less profitable, produces the fairest outcomes across agents , making it attractive in scenarios where equitable profi t distribution is prioritized. In contrast, MASAC fails to converge to profitable policies in this environment, likely due to its sensi tivity to entropy regularization and overestimatio n bias, which resulted in early performance collap se and negative long - run profits. These findings confirm that CTDE met hods such as MAPPO and MADDPG significantly outperform independent learners like IDDPG in stability, rep roducibility, and overall marke t performance. This work highli ghts the tra de - off between profit maximizati on and fa irness in multi - agent pricing strategies. MAPPO emerg es as the bes t choi ce when profita bilit y is t he primary objective, whereas MADDPG is the preferred algorithm when fairness is a key re quirement. The combination of quantitative metrics, fairness anal ysis, and competitiveness measures provides a holistic view of algorithm performance in multi - agent economic environments. Future directions incl ude incorporating more real istic retail dynamics (demand shocks, inventory limits) , exploring stabilization techniques to improv e MASAC performanc e, and scaling to larger agent populations. We also plan to validate these findings with real trans actional data and explore onlin e - learning deployment s trategies. VIII REFERENCES [1] Liu, Y. Zhang, X. Wang, Y. Deng, an d X. Wu, “Dynamic Pricing on E - commerce Platform with Deep Reinforcement Learning: A Fiel d Experiment,” ar Xiv preprint arXiv:1912.02572 , 2019. [2] Chao Yu, Akash Velu, Eugene Vin itsky, Jiaxuan Gao, Yu Wang, A lexand re Bay en , and Yi Wu, “The Su rprising Effectiveness of PPO in Cooperati ve Multi - Agent Games,” in NeurIPS 2022 Datas ets and Benchmar ks Track , 2022. [3] Sentao Miao, Xi Chen, Xiuli Chao, Jiaxi L iu, and Yidong Zhang, “Context - based Dynamic Prici ng with Online Clustering,” Production and Operations Management , vol. 31, no. 9, pp. 3559 - 3575, 2022. [4] [Kephart & Greenwald, 1999] A. R . Greenwald and J. O. Kephart, “S hopbots and Pricebots ,” in Proceedings of the 16th International Joint Conference on Artificial Intellige nce (IJCAI ’99) , 1999 [5] J. Korbel, L. A. Kropp, M. M. Theilig, and R. Zarnekow, “Dynamic Pricing of Product Cluste rs: A Multi - Agent Reinforcement Lear ning Approach” , in European Conference on Information Systems, Stockholm, Sweden, 2019. [6] E. A. Villarrubia - Martín, L. Rodrigu ez - Benitez, D. Muñoz - Valero, G. Montana, and L. Jimenez - Linares, “Dynamic Pricing in High - Speed Railways Using Multi - Agent Reinforcement Lear ning” , arXiv preprint arXiv:25 01.08234, 2025. [7] W. Qiao, “Distributed Dynamic Pricing of Multiple Perishable Product s Using Multi - Agent Reinforcement Learning” , Expert Systems with A pplications, 2024. [ 8] A. Apte, J . Roy, an d P. Pandi t, “Dynamic Retail Pri cing via Q - Learning — A Reinforce ment Learnin g Framework for Enhanced Revenue Management ,” arXiv preprint arXiv:2411.18261 , 2024. [9 ] S. Paudel and D. Das, “Multi - Agent Deep Re inforcement Learning for Dynami c Pricing by Fa st - Charging Elec tric Vehicle Hubs in Competit ion,” arXiv preprint arXiv:2401.15108 , 2024. [1 0 ] V. Pandey, M. Assemi, and M. W . Burris, “Deep Reinforcement Learning Algori thm for Dynamic Pricing of Express Lanes wit h Multiple Access Locations,” arXiv preprint arXiv:1909.04760 , 2019.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment