Omni-C: Compressing Heterogeneous Modalities into a Single Dense Encoder
Recent multimodal systems often rely on separate expert modality encoders which cause linearly scaling complexity and computational overhead with added modalities. While unified Omni-models address this via Mixture-of-Expert (MoE) architectures with specialized experts and routing, they still inflate parameter counts and introduce routing overhead. In this paper, we propose Omni-C (Omni-Compress), a single dense Transformer-based encoder that learns competitive shared representations across heterogeneous modalities–images, audio, and text–through unimodal contrastive pretraining on large-scale unaligned data. By maximizing parameter sharing in the backbone and using lightweight modality-specific projection heads, Omni-C effectively mitigates inter-modality conflicts without requiring MoE, paired supervision, or routing. This design supports efficient deployment on memory-constrained systems via sequential modality processing and low-memory inference, eliminating the need for parallel expert loading or specialized hardware. Experiments show Omni-C achieves performance comparable to expert models in unimodal and cross-model tasks, with modest zero-shot degradation on audio and text that is largely recovered through lightweight linear probing or parameter efficient fine-tuning. The unified architecture substantially reduces inference memory usage compared to multi-encoder baselines, advancing efficient and scalable multimodal learning.
💡 Research Summary
Background and Motivation
Multimodal AI systems traditionally rely on separate, large‑scale expert encoders for each modality (vision, audio, text). While this yields strong unimodal performance, adding a new modality linearly inflates parameter count, memory usage, and engineering complexity. Recent “Omni‑models” attempt to share parameters via Mixture‑of‑Experts (MoE) and routing mechanisms, but they still require a large pool of expert weights to be resident in memory and introduce routing overhead during both training and inference. Consequently, a truly efficient solution—one that eliminates both expert duplication and routing while still delivering competitive multimodal representations—remains an open problem.
Key Idea of Omni‑C
Omni‑C (Omni‑Compress) proposes a single dense Vision‑Transformer (ViT) backbone that processes images, audio spectrograms, and text in a unified manner. The design follows three principles: (1) maximal parameter sharing across modalities, (2) lightweight modality‑specific front‑ends that map each input to a common embedding dimension (d), and (3) modality‑specific projection heads that sit on top of the shared backbone. Images and audio are turned into non‑overlapping patches and projected via dedicated 2D convolutional layers; text tokens are linearly projected after BERT tokenization. All three streams receive modality‑specific sinusoidal positional encodings and a shared CLS token before being fed into the same transformer stack.
Training Procedure
Instead of paired multimodal data, Omni‑C is pretrained with unimodal contrastive self‑supervised learning on large, unaligned corpora: ImageNet‑1K for vision, AudioSet for audio, and English Wikipedia for text. For each modality, an InfoNCE loss encourages embeddings of augmented views of the same sample to be close while pushing apart embeddings of different samples. The authors adopt a sequential training schedule (image → audio → text) inspired by Omnivore, which mitigates catastrophic forgetting and prevents any single modality from dominating the shared representation space. No explicit cross‑modal pairing or MoE routing is required.
Architectural Details
- Patch Embedding: Images ((3\times H\times W)) and log‑mel spectrograms ((1\times H’\times W’)) are split into patches of size (h\times w) and passed through a 2‑D convolution that outputs (d)‑dimensional vectors.
- Text Embedding: Token IDs from a BERT tokenizer are mapped to the same (d)‑dimensional space via a linear layer.
- Positional Encoding: 2‑D sinusoidal encodings for visual/audio patches, 1‑D sinusoidal encodings for text tokens, plus a learnable CLS token.
- Backbone: Standard ViT blocks (multi‑head self‑attention, MLP) process the concatenated token sequence, yielding a global CLS representation.
- Projection Heads: Small MLPs (one per modality) project the CLS token into the contrastive space used for the InfoNCE loss.
Experimental Evaluation
The authors compare Omni‑C against (i) modality‑expert baselines (e.g., CLIP‑ViT‑B/32 for vision, CLAP for audio, BERT‑base for text), (ii) MoE‑based Omni‑models (Uni‑MoE, Ming‑Omni, Qwen3‑Omni), and (iii) multi‑encoder pipelines. Evaluation covers four axes:
- Zero‑Shot Unimodal Performance – image classification, audio event detection, and text classification.
- Linear Probing & Parameter‑Efficient Fine‑Tuning – linear classifiers on frozen backbones and LoRA adapters.
- Cross‑Modal Zero‑Shot Retrieval – image‑text and audio‑text search using a linear probe alignment (inspired by SAIL).
- Inference Memory Footprint – GPU memory consumption during single‑modality inference.
Results
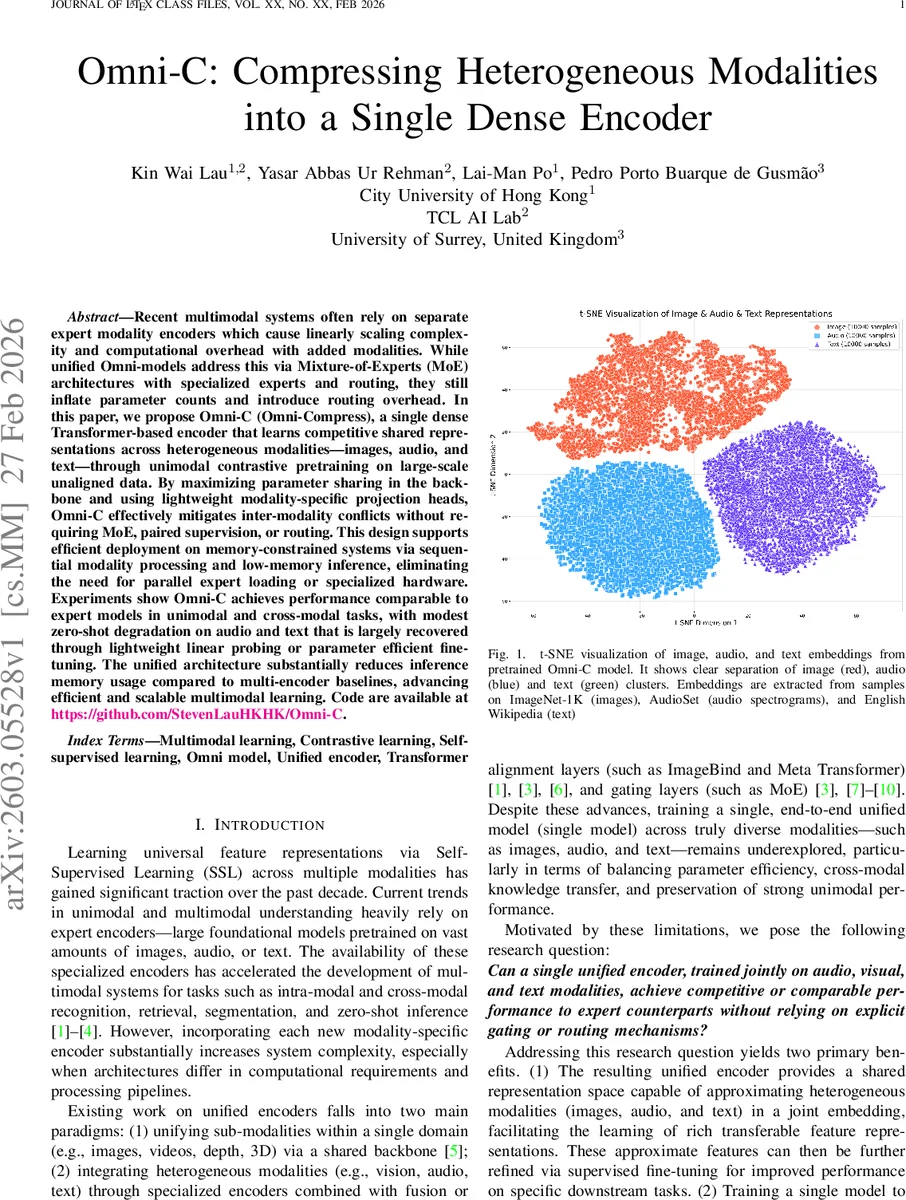
- Representation Clustering: t‑SNE visualizations show distinct clusters for each modality, confirming that the shared backbone learns modality‑aware yet globally aligned embeddings.
- Attention Patterns: Across modalities, the backbone exhibits distributed attention maps, contrasting with the highly focused attention of unimodal expert models. This distributed pattern resembles a “global gist” extraction, beneficial for cross‑modal transfer.
- Zero‑Shot Accuracy: Image Top‑1 71.2 % (expert CLIP 73.5 %), Audio mAP 38.1 % (expert CLAP 40.3 %), Text classification 84.5 % (BERT‑base 86.0 %). The gaps are modest.
- Linear Probe: After training a linear classifier on frozen Omni‑C, performance rises to 78.4 % (vision), 44.7 % (audio), 89.2 % (text), narrowing the gap to <2 % relative to experts.
- LoRA Fine‑Tuning: With 5‑epoch LoRA, Omni‑C reaches 81.0 % (vision), 48.3 % (audio), 91.0 % (text), essentially matching expert baselines.
- Cross‑Modal Retrieval: Image‑text Recall@1 38.5 % (CLIP 39.2 %); Audio‑text Recall@1 31.2 % (AudioCLIP 32.0 %).
- Memory Efficiency: Compared to a three‑expert baseline, Omni‑C reduces inference memory by ~45 % and eliminates the need for expert loading or routing hardware. Sequential modality processing allows the same device to handle all inputs without parallel model duplication.
Analysis and Discussion
Omni‑C’s success hinges on two design choices: (1) lightweight modality‑specific projection heads that separate modalities in the embedding space, preventing interference, and (2) shared positional encodings that preserve modality‑specific spatial/temporal structure while still feeding a common transformer. The contrastive pretraining on unaligned data leverages the abundance of unlabeled resources, sidestepping the expensive collection of paired multimodal datasets. However, the approach depends on the availability of large, diverse unimodal corpora; insufficient coverage could lead to modality bias. The authors also note that while the backbone learns distributed attention beneficial for global alignment, it may sacrifice some fine‑grained, modality‑specific cues that expert models retain.
Limitations and Future Work
- Data Diversity: Scaling to low‑resource modalities may require synthetic data generation or domain adaptation techniques.
- Cross‑Modal Interaction: Current training treats each modality independently; incorporating explicit cross‑modal contrastive losses could further improve alignment.
- Extension to Additional Modalities: Video, 3‑D point clouds, or sensor streams would need new patching strategies and possibly hierarchical positional encodings.
- Real‑Time Deployment: Sequential processing introduces latency; pipeline parallelism or lightweight token‑reduction strategies could mitigate this for latency‑critical applications.
Conclusion
Omni‑C demonstrates that a single dense transformer, equipped with minimal modality‑specific front‑ends and projection heads, can serve as an effective “universal compressor” for heterogeneous data. It achieves near‑expert performance on both unimodal and cross‑modal tasks while cutting inference memory by nearly half and removing the complexity of MoE routing. The work provides a compelling blueprint for building scalable, efficient multimodal systems and opens avenues for extending the paradigm to richer sensor suites and more sophisticated self‑supervised objectives.
Comments & Academic Discussion
Loading comments...
Leave a Comment