Discrete Diffusion with Sample-Efficient Estimators for Conditionals
We study a discrete denoising diffusion framework that integrates a sample-efficient estimator of single-site conditionals with round-robin noising and denoising dynamics for generative modeling over discrete state spaces. Rather than approximating a…
Authors: Karthik Elamvazhuthi, Abhijith Jayakumar, Andrey Y. Lokhov
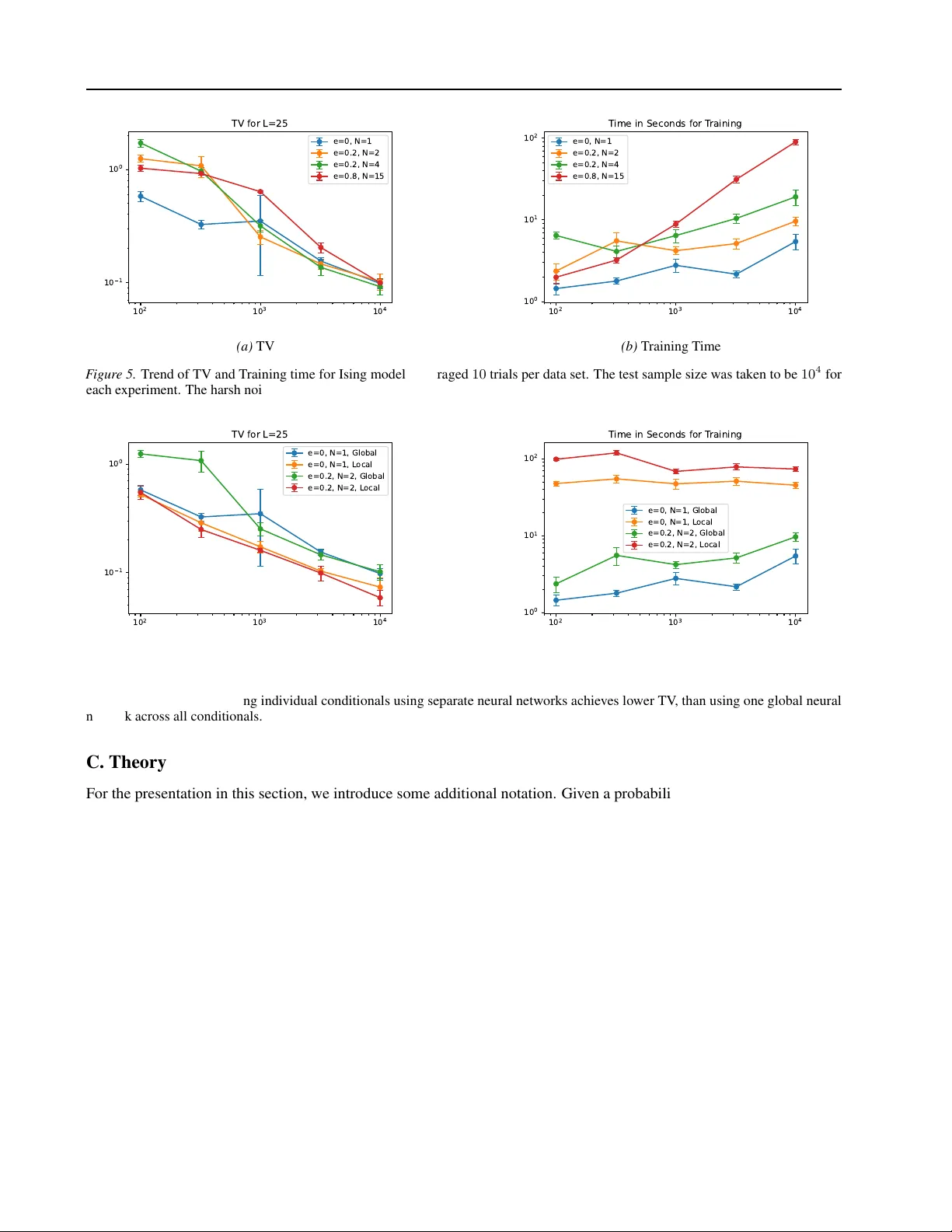
Discr ete Diffusion with Sample-Efficient Estimators f or Conditionals Karthik Elamvazhuthi 1 Abhijith Jayakumar 1 Andrey Y . Lokhov 1 Abstract W e study a discrete denoising diffusion frame- work that integrates a sample-efficient estima- tor of single-site conditionals with round-robin noising and denoising dynamics for generati ve modeling ov er discrete state spaces. Rather than approximating a discrete analog of a score func- tion, our formulation treats single-site conditional probabilities as the fundamental objects that pa- rameterize the re verse dif fusion process. W e em- ploy a sample-efficient method known as Neu- ral Interaction Screening Estimator (NeurISE) to estimate these conditionals in the diffusion dynamics. Controlled experiments on synthetic Ising models, MNIST , and scientific data sets pro- duced by a D-W ave quantum annealer , synthetic Potts model and one-dimensional quantum sys- tems demonstrate the proposed approach. On the binary data sets, these experiments demon- strate that the proposed approach outperforms popular existing methods including ratio-based approaches, achie ving improv ed performance in total variation, cross-correlations, and kernel den- sity estimation metrics. 1. Introduction Generativ e modeling ov er discrete spaces is fundamental to a wide range of applications, including molecular design, language modeling, and policy learning in reinforcement learning ( Ho & Ermon , 2016 ; Bengio et al. , 2003 ; Jin et al. , 2018 ). In these settings, data consist of cate gorical or binary variables with complex statistical dependencies, and accu- rately capturing their joint structure requires models that can scale to high-dimensional combinatorial configuration spaces. While dif fusion models hav e re v olutionized generati v e mod- eling in continuous domains ( Ho et al. , 2020 ), their direct application to discrete data has received increased attention. 1 Theoretical Division T -5, Los Alamos National Labora- tory . Correspondence to: Karthik Elamvazhuthi < karthike- vaz@lanl.go v > . Pr eprint. F ebruary 25, 2026. Continuous-time formulations rely on Gaussian noise and score estimation through gradients of log-densities, quan- tities that are not well defined in discrete spaces. Naiv e relaxations, such as adding continuous noise to one-hot en- codings, break the discrete structure and often yield poor sample quality or unstable training. These limitations moti v ate the need for a principled frame- work for discr ete diffusion pr ocesses that preserves the com- binatorial structure of the data, allo ws tractable inference, and retains the interpretability and scalability that made diffusion models successful in continuous domains. A number of works have considered extending diffusion models to discrete spaces. ( Austin et al. , 2021 ) considers denoising diffusion for discrete data and discrete time (both absorbing and uniform dif fusion), optimizing the v ariational lower bound (VLB) of the log-likelihood. A continuous- time framew ork for discrete dif fusion models is introduced in ( Campbell et al. , 2022 ), which also optimizes the VLB of the log-likelihood. The work ( Sun et al. , 2022 ) performs score matching for continuous-time dif fusion by learning conditionals using cross-entropy . In ( Lou et al. , 2024 ), the authors propose an approach to learn the discrete version of the score using a score-entropy function to ensure non- negati vity of the score along the training iterations. For a broader survey on discrete diffusion models see ( Li et al. , 2025 ). This paper’ s contribution be gins with making e xplicit that for forward transitions the canonical time-reversed kernel can be parameterized entirely through ratios of probabil- ities between configurations that differ at one coordinate, and that these ratios reduce exactly to ratios of single-site conditional distrib utions given the remaining coordinates. So re verse dif fusion can be implemented by learning local conditionals instead of a global density or discrete scor e . The main methodological contribution follo wing this obser- vation is to plug in state-of-the-art estimator for learning discrete conditionals. W e use the Neural Interaction Screen- ing Estimator (NeurISE) ( Jayakumar et al. , 2020 ) due to its approximation- and sample-efficienc y . A key conceptual observ ation is that, under the round-robin noising scheme of ( V arma et al. , 2024 ), autoregressi v e gen- eration emerges as the hard-noise limit of the re verse-time sampler: each reverse step becomes “resample one coordi- 1 Submission and Formatting Instructions f or ICML 2025 nate from its single-site conditional, ” and unrolling these updates in the fixed order yields autoregressi ve sampling (without proposing a ne w AR model). In contrast, ( Ou et al. , 2024 ) also links absorbing diffusion to autoregressi ve generartion. Specifically , the y connect absorbing diffusions any-order autoregressi v e models (A O-ARM) at the objecti v e lev el through a reparameterization of the concrete score and a change of variables to masking probability . They show that in the infinite-noise limit the absorbing-diffusion loss equals the A O-ARM training objecti v e. Thus, our bridge is a more direct, finite-step collapse of the sampler in a specific round-robin construction, whereas ( Ou et al. , 2024 ) derives a broader equi v alence through an algebraic transformation and limit of the training loss. On the theory side, the paper provides total-v ariation error - propagation bounds for data generation with an approximate rev erse kernel, quantifying precisely how local inaccura- cies accumulate across sampling steps, in the same v ein as score-based sampling analyses for the continuous space or continuous time setting ( Chen et al. , 2022 ; Chen & Y ing , 2024 ). Conceptually , the bound isolates the two factors that driv e sampling difficulty in dif fusion models: (i) learning error in the learned reverse-time transitions, and (ii) how well the forward noising process mixes to the target noise distribution. This stands in contrast to Langevin or Glauber dynamics-type MCMC samplers, where con vergence rates typically depend more directly on properties of the data distribution such as multi-modality , rather than on reverse- process estimation accuracy and forward-process mixing to noise. Finally , we ev aluate the proposed estimation approach for ratios of conditionals using NeuRISE on a range of dis- crete generativ e modeling benchmarks, including synthetic Ising on a 25 -variable system, binarized MNIST , and quan- tum annealing (D-W ave) datasets. Across these settings, we compare against representati ve ELBO- and score-based methods: D3PM ( Austin et al. , 2021 ) and the SEDD method proposed in ( Lou et al. , 2024 ), and demonstrate consistent improv ements in distributional accurac y . A key experimen- tal contribution is that the 25 -variable Ising model pro vides a controlled setting to study how dif ferent denoising algo- rithms behav e statistically as the training sample size v aries. 2. Problem Let Σ denote a discrete set of alphabets with cardinality | Σ | = p . W e define the configuration space Σ q for q dis- crete v ariables or coordinates, with elements denoted as σ := ( σ 1 , ...σ q ) . Given training samples from a probability distribution µ : Σ q → R , the goal is to construct a diffusion- based generative model fr om which new samples can be tractably gener ated . W e will specifically focus on a general class of probabilistic models ov er Σ q defined using a Hamiltonian H : Σ q → R as follows: µ ( σ ) = 1 Z exp ( H ( σ )) , σ ∈ Σ q , (1) where the partition function Z = P σ ∈ Σ q exp ( H ( σ )) en- sures normalization. This formulation defines an energy- based probability distrib ution from the e xponential family , where the energy function H ( σ ) typically encodes interac- tions between components of σ , such as pairwise terms or external fields. An important example of such a model is the Ising model , where Σ := {− 1 , 1 } which is a pairwise Markov random field ov er Σ q with interactions defined by an undirected graph G = ( V , E ) , where V = [ q ] and E ⊆ V × V . The Hamiltonian takes the form: H ( σ ) = X ( i,j ) ∈ E J ij σ i σ j + X i ∈ [ q ] h i σ i . (2) Here J ij ∈ R represents the strength of the interaction between nodes i and j , h i ∈ R represents an external bias or field at node i , σ i ∈ Σ for all i ∈ [ q ] . This model defines a probability distribution: µ ( σ ) = 1 Z exp X ( i,j ) ∈ E J ij σ i σ j + X i ∈ [ q ] h i σ i , σ ∈ Σ q . Equation ( 2 ) defines the energy landscape that gov erns the distribution. The graph structure G encodes the conditional dependencies in the model, making the Ising model a special case of an undirected graphical model. 3. Discrete Diffusion thr ough Conditionals W e consider a denoising diffusion frame w ork ov er the con- figuration space Σ q , which consists of a known forward Markov process and a learned reverse process. The goal is to construct a forward Markov process { X n } T n =0 such that X 0 ∼ µ 0 is the data distrib ution that we are interested in learning. The forward process then makes sure that the distribution µ n of X n con v erges to a tractable noise distribu- tion, from which it is easy to sample: lim n →∞ µ n = µ noise . The Markov chain ov er Σ q ev olv es according to a known transition kernel k n : Σ q × Σ q → R ≥ 0 which defines the conditionals k n ( σ, ˜ σ ) := P ( X n +1 = σ | X n = ˜ σ ) . The for- ward e v olution of the distribution µ n of the process X n is then giv en by: µ n +1 ( σ ) = X ˜ σ ∈ Σ q k n ( σ, ˜ σ ) µ n ( ˜ σ ) . (3) 2 Submission and Formatting Instructions f or ICML 2025 Reverse Pr ocess T o sample from the target distribution µ 0 , we define a re- verse process { Y n } T n =0 such that Y n ∼ µ T − n . This reverse process is gov erned by a family of time-inhomogeneous transition kernels k rev n : Σ q × Σ q → R ≥ 0 , which satisfy the backward recurrence: µ n ( σ ) = X ˜ σ ∈ Σ q k rev n ( σ, ˜ σ ) µ n +1 ( ˜ σ ) . (4) W e obtain a natural candidate for the reverse-time transition kernel via Bayes’ rule is the follo wing: k rev n ( σ, ˜ σ ) = k n ( ˜ σ , σ ) · µ n ( σ ) P ˆ σ ∈ Σ q k n ( ˜ σ , ˆ σ ) µ n ( ˆ σ ) , = k n ( ˜ σ , σ ) P ˆ σ ∈ Σ q k n ( ˜ σ , ˆ σ ) · µ n ( ˆ σ ) µ n ( σ ) . (5) This expression sho ws that the re v erse kernel depends only on the forward transition probabilities and on ratios of the form µ n ( ˆ σ ) /µ n ( σ ) . Consequently , if these ratios can be accurately estimated we can construct accurate approxima- tions to the rev erse kernels, k rev n . W e can then sample from the noise distribution µ noise and iterati v ely apply the reverse transitions to generate new samples from an approximation of the data distribution. This captures the core idea of denoising diffusion proba- bilistic models (DDPMs). The forward process gradually driv es the data distribution toward a simple noise distri- bution, while the reverse process reconstructs samples by in v erting this dynamics using learned conditional structure. The following theorem formalizes this intuition. It pro- vides an analogue of the con vergence guarantees established for score-based dif fusion models in the continuous setting ( De Bortoli et al. , 2021 ; Chen et al. , 2022 ; Chen & Y ing , 2024 ). The key insight is that the discrepanc y between the output distribution of the approximate re verse chain and the true data distribution decomposes cleanly into tw o con- tributions: (i) the extent to which the forward process has mixed toward the noise distrib ution, and (ii) the cumula- tiv e error incurred when approximating the re verse k ernels. This decomposition makes precise the tradeof f underlying DDPM-style generati ve modeling. Accurate sampling re- quires both sufficiently fast dif fusion of the forward process to the noise distribution and suf ficiently accurate estimation of the rev erse-time dynamics. Here, the total v ariation (TV) distance ∥ · ∥ TV between two distributions is defined by ∥ ˆ µ − µ ∥ TV = 1 2 P σ ∈ Σ q ˆ µ ( σ ) − µ ( σ ) . Theorem 3.1. Let { X n } T n =0 be the Markov c hain on Σ q with forwar d tr ansition kernels k n : Σ q × Σ q → R ≥ 0 . F ix a noise r efer ence distrib ution µ noise on Σ q and assume that for some δ T ∈ [0 , 1] , ∥ µ T − µ noise ∥ TV ≤ δ T . (6) Let { k rev n } T − 1 n =0 be a well-defined family of r ever se kernels that satisfy ( 4 ) . Consider appr oximate re verse kernels { b k rev n } T − 1 n =0 such that for all n = 0 , . . . , T − 1 , sup σ ∈ Σ q b k rev n ( · , σ ) − k rev n ( · , σ ) TV ≤ η. (7) Initialize the appr oximate re verse c hain with the noise r ef- er ence, i.e. Y T ∼ µ noise , and let b µ 0 denote the law of the output Y 0 obtained by applying b k rev T − 1 , . . . , b k rev 0 . Then the output distribution satisfies ∥ ˆ µ 0 − µ 0 ∥ TV ≤ δ T |{z} Mixing err or + T η . |{z} Reverse kernel estimation err or (8) Theorem 3.1 bounds the error of the approximate rev erse chain when initialized from the true noise distribution µ noise . The proof is provided in the Appendix C . In practice, ho w- ev er , the reverse process is initialized from an empirical approximation 1 N P N i =1 δ X data i of µ noise . The following corollary shows that this additional source of error con- tributes additi vely to the final bound and captures the effect of sampling error from the noise distribution. It partially ex- plains why masked dif fusion models ha ve been observed to perform better ( Austin et al. , 2021 ; Santos et al. , 2023 ; Lou et al. , 2024 ) in practice, than when the noise distrib ution is uniform. Corollary 3.2. (Initialization err or) In the setting of Theo- r em 3.1 , let b µ noise be any distribution on Σ q such that for some γ ∈ [0 , 1] , b µ noise − µ noise TV ≤ γ . (9) Initialize the appr oximate r everse c hain with Y T ∼ b µ noise , and let e µ 0 denote the law of the output Y 0 obtained by applying b k rev T − 1 , . . . , b k rev 0 . Then the output distribution satisfies e µ 0 − µ 0 TV ≤ δ T |{z} Mixing Err or + T η |{z} Reverse kernel estimation err or + γ . |{z} Noise sampling err or (10) One can use this corollary to see the effect of error due to sampling from the noise distribution. For instance, let b µ noise = 1 N P N i =1 δ X noise i be the approximating empirical distribution based on N i.i.d. samples { X noise 1 , ...X noise N } from µ noise . Then from results of ( Berend & K ontorovich , 2012 ) one can quantify the effect of sampling error from the noise distribution, on the distance of the sampled dis- tribution from the data distribution. In the special case, when µ noise = δ σ mask for some σ mask ∈ Σ q , then it is to see that one can in fact, take a stronger bound by setting 3 Submission and Formatting Instructions f or ICML 2025 γ = 0 . While this might explain partially why dif fusion models with absorbing states perform better as observed in literature ( Austin et al. , 2021 ; Santos et al. , 2023 ; Lou et al. , 2024 ), it can be that the estimation error of the rev ersal kernel, as captured by η is high in such situations, as the distribution becomes much more concentrated. On the other hand, in experiments, we observed uniform distribution per - formed better . W e conjecture this is due to this noising process increasing the temperature of the distrib ution and due to fact that higher-temperature distributions being easier to learn via NeurISE ( Jayakumar et al. , 2020 ). Remark: non-uniqueness of re verse process. Another point to note is that the rev erse process kernel that achie ves the marginals µ n is not unique, and there may exist rev erse kernels dif ferent from k rev n defined in ( 5 ) ; see Section C.1 . This is an important observation, since some prior works, such as ( Campbell et al. , 2022 ), e xplicitly deriv e the time- rev ersal of a prescribed forw ard process but, during training, learn a parametric re verse process that only needs to repro- duce the tar get marginals rather than coincide with the e xact time-rev ersed kernel. Consequently , the learned rev erse dy- namics may not correspond to the canonical time-r eversal of the forward process deri ved earlier in this section, e ven when they generate the correct mar ginal distributions. This is dif ferent from the situation considered in this paper and in works such as ( Campbell et al. , 2022 ; Sun et al. , 2022 ; Lou et al. , 2024 ), where the loss function explicitly enforces this canonical choice. For comparison, in the continuous space, where SDEs are used to noise and denoise, the canonical choice is the one considered in time-reversal theorems in the stochastic processes literature ( Anderson , 1982 ; Hauss- mann & Pardoux , 1986 ). On the other hand, the probability flow ODE ( Song et al. , 2020 ) pro vides a non-canonical time rev ersal. Round-Robin Forward Noising W e no w describe a choice of forward dynamics, according to a noising scheme introduced in ( V arma et al. , 2024 ), that will be used in this paper . In this choice of the forward process, we gradually introduce noise into the configuration by modifying one coordinate (e.g., a pixel or spin) at a time. An adv antage of this form of noising is that the number of ratios that are required to be learned for each time step is much smaller , than with other schemes ( Austin et al. , 2021 ; Sun et al. , 2022 ; Lou et al. , 2024 ), where all the v ariables are noised simultaneously . The precise scheme for noising is the following: 1. A randomization parameter ε ∈ [0 , 1] is fixed. 2. At each time step n ∈ { 1 , . . . , T } , a specific coordinate is selected in round-robin order: the n -th coordinate of σ is selected as u = (( n − 1) mo d q ) + 1 . 3. W ith probability ε the coordinate σ u is left unchanged. W ith probability 1 − ε the coordinate v alue σ u is uni- formly randomly sampled from Σ . Since there are p number of elements in Σ , the conditional probabilities if this forward noising process are gi ven by: k n ( σ, ˜ σ ) = 1 − ε p , if σ − u = ˜ σ − u , σ u = ˜ σ u , 1 − ε p + ε, if σ = ˜ σ , 0 , otherwise , where σ − u ∈ Σ q − 1 denotes the configuration excluding the u -th coordinate. For notational con vinience in the forthcom- ing expressions, we define the parameters, a = 1 − ε p , b = 1 − ε p + ε, the probability of noising the chosen coordinate to an alpha- bet different from its current v alue, and the probability of it picking the current alphabet again, respecti vely . Since the only admissible transitions are one coordinate transition aw ay at the noised coordinate u = (( n − 1) mo d q ) + 1 , we can substitute the e xpression for k n ( σ, ˜ σ ) in ( 5 ) to express the re verse kernel as, k rev n ( σ, ˜ σ ) = a µ n ( σ ) a µ n ( σ ) + b µ n ( ˜ σ ) + a P ˆ σ ∈N u ( ˜ σ ) \{ σ, ˜ σ } µ n ( ˆ σ ) with N u ( ˜ σ ) := { ˆ σ ∈ Σ q : ˆ σ − u = ˜ σ − u } . Therefore, this giv es rise to three possibilities, k rev n ( σ, ˜ σ ) = a µ n ( σ ) b µ n ( ˜ σ ) + a P N u ( ˜ σ ) \{ ˜ σ } µ n ( ˆ σ ) , (11) when σ − u = ˜ σ − u , but σ = ˜ σ . Similarly , k rev n ( σ, σ ) = b µ n ( σ ) b µ n ( σ ) + a P N u ( σ ) \{ σ } µ n ( ˆ σ ) , (12) and k n ( σ, ˜ σ ) = 0 otherwise. Of special interest is the case when the discrete set is binary: Σ := {− 1 , 1 } is binary . Then, we get, k n ( σ, ˜ σ ) = 1 − ε 2 , if σ − u = ˜ σ − u , σ u = ˜ σ u , 1+ ε 2 , if σ = ˜ σ , 0 , otherwise , . (13) The corresponding rev erse transition probabilities are: k rev n ( σ, ˜ σ ) = (1 − ε ) · µ n ( σ ) (1 − ε ) µ n ( σ ) + (1 + ε ) µ n ( ˜ σ ) , if σ − u = ˜ σ − u and σ u = ˜ σ u , 4 Submission and Formatting Instructions f or ICML 2025 and k rev n ( σ, σ ) = (1 + ε ) · µ n ( σ ) (1 + ε ) µ n ( σ ) + (1 − ε ) µ n ( ˜ σ ) . The Hard Noise A utoregr essive Limit W e now consider a special case of the forward process in which noise is harsh : ε = 0 . This corresponds to a full randomization of the selected coordinate at each step, and hence all the information is lost in the variable after the corresponding noising step. Our goal in this section is to show that we recover auto-regressi ve generation in this limit. Let T = q , and define a time-inhomogeneous Markov kernel that updates only the n -th coordinate at time step n ∈ { 1 , . . . , T } . The forward transition kernel simplifies to, k n ( σ, ˜ σ ) = 1 p , if σ − n = ˜ σ − n , 0 , otherwise , (14) Over T = p steps, this procedure fully randomizes each coordinate once, resulting in con vergence to the uniform distribution o ver Σ q . By the rev erse kernel construction, we obtain P ( X n = σ | X n +1 = ˜ σ ) = k rev n ( σ, ˜ σ ) = 1 σ − n = ˜ σ − n · µ n ( σ ) P ˆ σ ∈N n ( σ ) µ n ( ˆ σ ) . This corresponds to sampling the n -th coordinate condi- tioned on the others: P ( X n n = σ n | X − n n = ˜ σ − n ) = µ n ( σ ) P ˆ σ ∈N n ( σ ) µ n ( ˆ σ ) , where the sum is taken o ver all configurations ˆ σ ∈ Σ q that agree with σ outside coordinate n . W e now e xpress this re verse process recursiv ely . Let X T = ˜ σ be a configuration sampled from the noise distribution. At each rev erse step n , the process samples a configuration X n = σ such that σ − n = ˜ σ − n , while drawing σ n from the corresponding conditional distribution. Formally , P ( X n = σ | X n +1 = ˜ σ ) = 1 σ − n = ˜ σ − n · P ( X n n = σ n | X − n n = ˜ σ − n ) . Unrolling the rev erse chain from T to 0 yields P ( X 0 = σ | X T = ˜ σ ) (15) = T Y n =1 P ( X T − n = σ T − n | X T − n +1 = ˜ σ T − n +1 ) . (16) Since the two configurations dif fer only at coordinate n , P ( X T − n = σ | X T − n +1 = ˜ σ ) = 1 σ − n = ˜ σ − n P ( σ n | ˜ σ − n ) . Substituting into ( 15 ), we obtain P ( X 0 = σ | X T = ˜ σ ) = T Y n =1 1 σ − n = ˜ σ − n P ( σ n | ˜ σ − n ) . If the re verse update keeps non-updated coordinates fix ed, i.e. X − n n = X − n n +1 , then the conditioning simplifies to P ( X 0 = σ | X T = ˜ σ ) = T Y n =1 P ( σ n | ˜ σ >n ) , (17) which recov ers an autore gressive f actorization ov er the dis- crete alphabet Σ . 4. Learning Conditionals using Neural Interaction Screening Let µ n denote the probability distribution of the random variable X n . In order to implement the rev erse dynamics, we need to estimate the ratio µ n ( ˜ σ ) µ n ( σ ) from samples of the forward process. Suppose σ, ˜ σ ∈ Σ q differ at only one coordinate n , i.e., ˜ σ i = σ i for all i = n, ˜ σ n = σ n . Then, for any distrib ution µ n ov er Σ q , we hav e: µ n ( ˜ σ ) µ n ( σ ) = µ n ( ˜ σ n | σ − n ) µ n ( σ n | σ − n ) , where σ − n ∈ Σ q − 1 denotes the shared values of the config- uration outside the n -th coordinate. This identity follows directly from the definition of con- ditional probability µ n ( σ ) = µ n ( σ n | σ − n ) · µ n ( σ − n ) . T aking the ratio, we obtain: µ n ( ˜ σ ) µ n ( σ ) = µ n ( ˜ σ n | σ − n ) · µ n ( σ − n ) µ n ( σ n | σ − n ) · µ n ( σ − n ) = µ n ( ˜ σ n | σ − n ) µ n ( σ n | σ − n ) . This expression provides a tractable way to compute (or approximate) the required ratio using only local conditionals for the rev ese dynamics. T o compute the required single-site conditional distribu- tions, we use the Neural Interaction Scr eening Estimator (NeurISE) ( Jayakumar et al. , 2020 ), which learns local con- ditionals in discrete graphical models by neural parameteri- zation of partial energy functions. 5 Submission and Formatting Instructions f or ICML 2025 This local conditional modeling is well matched to the re- verse diffusion kernel, which depends only on ratios of single-site conditionals between configurations differing at one coordinate, enabling efficient and scalable imple- mentation of the re verse-time dynamics without e xplicitly modeling the global distribution. Follo wing NeurISE ( Jayakumar et al. , 2020 ), we introduce the centered indicator embedding Φ s ( r ) := 1 − 1 q , r = s, − 1 q , r = s, s, r ∈ Σ . W e then define the vector -valued embedding, Φ( r ) := Φ 1 ( r ) , . . . , Φ q ( r ) ∈ R q , Suppose that µ n ( σ ) ∝ exp( H ( σ )) is a Gibbs distrib ution for some Hamiltonian function H : Σ q → R . F or any coordinate u ∈ [1 , , , q ] , there always e xists a decomposition H ( σ ) = H − u ( σ − u ) + H u ( σ ) , where H − u does not depend on σ u .w Substituting it into the Gibbs distribution µ n ( σ ) ∝ exp( H ( σ )) yields µ n ( σ u | σ − u ) = exp( H − u ( σ − u ) + H u ( σ )) P r ∈ Σ exp( H − u ( σ − u ) + H u ( σ u = r , σ − u )) . Since H − u ( σ − u ) does not depend on σ u , we get µ n ( σ u | σ − u ) = exp( H u ( σ )) P r ∈ Σ exp( H u ( σ u = r , σ − u )) . Therefore, the partial energy H u determines the single-site conditional distribution up to an additiv e function of σ − u , and can be written as H u ( σ ) = log µ n ( σ u | σ − u ) + const( σ − u ) . For each σ − u , H u ( · , σ − u ) can chosen be to satisfy P r ∈ Σ H u ( r , σ − u ) = 0 . The functions Φ r form a basis for functions, f : Σ → R that av erage to 0 or are center ed . Therefore, for each coordinate u ∈ [ q ] , we approximate this partial energy using a neural network NN θ : Σ q − 1 → R q Specifically , we use this parameterization at the Hamiltonian lev el as follows, e H u ( σ ; w ) = Φ( σ u ) , NN θ ( σ − u ) = q X s =1 Φ s ( σ u ) NN θ ( σ − u ) s . This representation is fully general without loss of expres- sivity . Giv en samples { σ ( n ) } N n =1 from the forward process at time n , the NeurISE loss as presented in ( Jayakumar et al. , 2020 ), for site u is L u ( θ ) = 1 N N X n =1 exp − Φ( σ ( n ) u ) , NN θ ( σ ( n ) − u ) . Here θ represents the trainable parameters of the neural net Since we have conditionals that need to be learned be for each time step, we introduce a neural network N N θ : R × R q × R q − 1 → R p that accepts ar guments ( t, u, σ − u ) where the coordinate u is encoded as a one-hot vector . This gives us the composite loss L u ( θ ) = 1 T N T X s =1 N X n =1 exp − Φ(( X n s ) u ) , NN θ ( t, u, ( X n s ) − u . (18) Learned Conditional Distribution. Once trained, the approximate conditional distribution is recov ered by setting b µ n ( σ u | σ − u ) = exp Φ( σ u ) , NN u ( σ − u ) P r ∈ Σ exp Φ( r ) , NN u ( σ − u ) . (19) Therefore, for any pair ( σ, ˜ σ ) differing at coordinate u , the ratio required for the rev erse diffusion kernel is gi ven by µ n ( ˜ σ ) µ n ( σ ) ≈ exp Φ( ˜ σ u ) , NN u ( σ − u ) exp Φ( σ u ) , NN u ( σ − u ) . 5. Numerical Experiments In this section, we compare our denoising method that we refer to as NeurISE diffusion , with two representativ e ELBO- and score-based methods proposed in the literature: D3PM ( Austin et al. , 2021 ), and the score matching ap- proach (SEDD) proposed in ( Lou et al. , 2024 ). The relev ant code used to run the experiments can be found in Github repository . W e implemented our own v ersion of SEDD, and the D3PM implementation was adapted from an unof ficial publicly av ailable implementation ( Ryu , 2024 ). The core parametric model we will use in our method and each of these methods will be multilayer perceptrons with different depth, depending on the test cases, with batch normalization layers. W e make this choice to study the per - formance of these methods on an equal footing, decoupled from representational differences coming from the model. 5.1. T est Case 1: Edwards-Anderson Model W e first compare different methods on small-scale synthetic data. The benchmark is based on the Edwar ds-Anderson (EA) model ( Edwards & Anderson , 1975 ; Bhatt & Y oung , 1988 ), which is a specific instance of the binary Ising model defined by the Hamiltonian in Equation ( 2 ). The EA model Hamiltonian is defined ov er p = L 2 binary variables σ i ∈ {− 1 , +1 } , arranged on a two-dimensional square lattice of size L × L . The graph E ⊆ [ q ] × [ q ] 6 Submission and Formatting Instructions f or ICML 2025 1 0 2 1 0 3 1 0 4 1 0 5 1 0 1 1 0 0 TV for L = 25 NeuRISE Diffusion D3PM SEDD (a) TV 1 0 2 1 0 3 1 0 4 1 0 5 1 0 0 CC differ ence for L = 25 NeurISE Diffusion D3PM SEDD (b) Cross-correlation Error 1 0 2 1 0 3 1 0 4 1 0 5 1 0 0 1 0 1 1 0 2 T ime in Seconds for T raining NeuRISE Diffusion D3PM SEDD (c) T raining Time F igure 1. Trend of TV and Cross-correlation error as a function of training set size for Ising models, av eraged over 5 Ising models and 10 trials per data set. The test sample size was tak en to be 10 5 for each experiment. Error bars represent one standard deviation ov er trials. corresponds to the set of nearest-neighbor pairs on a 2D periodic grid. Each spin σ i interacts with its right and bot- tom neighbors, with periodic boundary conditions applied in both directions. The pairwise couplings J ij are symmet- ric random v ariables sampled independently for each edge ( i, j ) ∈ E as: J ij = J j i ∈ {− 1 . 2 , +1 . 2 } . The local fields h i ∈ {− 0 . 05 , +0 . 05 } are also sampled independently for each node i ∈ [ q ] . In our experiments, we use a lattice size of L = 5 , resulting in a model with q = 25 binary variables. The results of using a two layer MLP can be seen for dif ferent dif fusion methods in Figure 1 . W e test the models for dif ferent values of training data across averaged over 5 different choices of EA models, with 10 runs for differing values of train- ing set size: [100 , 320 , 1000 ... 10 5 ] . The training samples were generated using an e xact sampler . The number of test samples were fixed to be 10 5 across all three experi- ments. W e find that the NeuRISE-based denoising estimator shows the sharpest decay in total variation (TV) distance with increase in sample size, and performs better than the SEDD approach proposed in ( Lou et al. , 2024 ). F or the model presented in ( Lou et al. , 2024 ), the configurations had to be one-hot coded to mak e the algorithm work. The model D3PM ( Austin et al. , 2021 ) performs well for low number of samples b ut its performance deteriorates as the size of the training set is increased. Interestingly , D3PM does not show monotonic decay of TV as the number of training samples decrease. In each case, we also compute the difference between the cross-correlation matrices of the generated samples and the test data, where the correlations are defined as C ij = 1 N P N k =1 σ ( k ) i σ ( k ) j . The decay of cross- correlation errors show a similar trend as that for the TV . Cross-correlation metric has the advantage of tractability for larger models where TV can’ t be efficiently computed. Another important study that was performed is the compari- son of the NeuRISE-based diffusion for dif ferent choice of noise parameter . From our experiments, it doesn’ t seem like the denoising scheme with soft noise significantly outper- form harsh noise setting, which corresponds to autoregres- siv e generation. In fact, for small training sets, the harsh noise case uniformly performs better than the other schemes. See Appendix B . 5.2. T est Case 2: MNIST W e ev aluate the proposed discrete NeurISE dif fusion model on the binarized MNIST dataset, which consists of grayscale images of handwritten digits. Images are discretized into a binarized alphabet by thresholding pixel intensities at a fix ed midpoint v alue, assigning pixels to one of two categories depending on whether their intensity lies abov e or belo w the threshold. This results in binary-valued vectors in Σ q , where q = 784 denotes the number of pixels in each image. F or this benchmark, we allo wed a hyperoptimization schedule to search over MLPs of upto 5 layers. W e used the MMD metric ( Gretton et al. , 2012 ) and a verage cross-correlation of the samples, to compare the performance of the models for conditional sampling task. As can be seen in T able 1 , the NeuRISE based learning of conditionals achiev e the lowest MMD and cross-correlation error . Samples of generated images can be seen in Figure 2 . Compared to the EA model, we see that D3PM achie ves a much better comparable performance in this setting. Note that the metrics used here do not compute a w orst case error between distributions as TV does. This indicates that D3PM is good at reproducing a lower -order projection of the dataset that aligns with such metrics, b ut struggles with true distribution learning, where NeuRISE Dif fusion succeeds. 5.3. T est Case 3: D-W ave Dataset T o demonstrate our method on a scientific application with real data, we use the diffusion model to learn a binary dataset produced by D-W ave’ s Advantage quantum annealer ( Mc- Geoch & Farr ´ e , 2020 ). This dataset is generated by per- forming repeated quantum annealer runs on the D-W a ve machine, with a randomized set of input Hamiltonians. For our experiments we choose q = 2000 qubits, which forms a subsection of the annealer and train a diffusion model on the data produced by this portion of the chip. In this e xample, 7 Submission and Formatting Instructions f or ICML 2025 (a) NeurISE Diffusion (b) D3PM (c) SEDD F igure 2. Class-conditional MNIST samples. Each subfigure sho ws generated samples arranged with one row per digit (0–9). 8 × 10 4 samples were used for training, and 2 × 10 4 samples were reserved for testing. Results in T able 2 again show the advantage of NeurISE Dif fusion in all metrics. Model A vg. MMD A vg. Correlation Neurise Diffusion (ours) 15.17 1 . 3 × 10 − 6 D3PM 19 . 12 2.8 × 10 − 6 SEDD 41 . 2 7 . 1 × 10 − 6 T able 1. MNIST Dataset Comparison. Model MMD A vg. Corr elation Neurise Diffusion (ours) 0 . 016 1 . 18 × 10 − 5 D3PM 0 . 28 1 . 5 × 10 − 5 SEDD 65 . 03 5 . 81 × 10 − 5 T able 2. D-W av e Dataset Comparison. 5.4. T est case 4: Multi-Alphabet Potts Models T o demonstrate that our method on the multi-alphabet case, we also consider the Potts version of the EA model Sub- section 5.1 . Let Σ = { 0 , 1 , . . . , p − 1 } and let σ = ( σ 1 , . . . , σ q ) ∈ Σ q with p = L 2 . W e consider a q -state Potts model on an L × L periodic lattice with Hamilto- nian, H ( σ ) = − P ( i,j ) ∈ E J ij 1 { σ i = σ j } − P p i =1 h i,σ i , , where E denotes the set of nearest-neighbor pairs on the lattice. Here J ij = J j i ∈ {− J , + J } are random couplings, h i,s ∈ {− h, + h } are state-dependent local fields, and 1 {·} is the indicator function. W e test the model for two lattices, L = 2 and L = 3 , which corresponds to q = 4 and q = 9 states, respecti vely . As can be seen in Figure 3 , the TV error decreases as the number of training samples are increased. 5.5. T est case 5: Quantum T omography of GHZ state T o test our methods for the multi-alphabet case for a scien- tifically relev ant applications, we use quantum tomography data obtained from the simulation of a four -outcome mea- surement ( p = 4) on the Greenber ger–Horne–Zeilinger (GHZ) state. This dataset is commonly used in the study of neural net based approaches to the representation of quantum states ( T orlai et al. , 2018 ; Jayakumar et al. , 2024 ). W e study the efficac y of NeuRISE Diffusion on 1 0 2 1 0 3 1 0 4 1 0 5 1 0 0 4 × 1 0 1 6 × 1 0 1 TV for L=25 q = 4, p = 3 q = 9, p = 3 F igure 3. T rend of TV for a non-binary Potts model as a function of training set size, av eraged over 10 trials for each size. The test sample size was taken to be 10 5 for each experiment. Error bars represent one standard deviation o ver trials. 1 0 2 1 0 3 1 0 4 1 0 5 2 × 1 0 1 3 × 1 0 1 4 × 1 0 1 6 × 1 0 1 F igure 4. T rend of cross-correlation error of NeuRISE Diffusion trained to learn the GHZ state as a function of training set size, av eraged over 10 trials for each size. The test sample size was taken to be 10 5 for each experiment. Error bars represent one standard deviation o ver trials. this model with 20 qubits ( q = 20 ) in Figure 4 . The cross-correlation is generalized to the multi-alphabet case as C ij = 1 N P N k =1 P a ∈ Σ δ σ ( k ) i = a δ σ ( k ) j = a . W e see that the cross-correlation error goes down significantly after 10 4 samples, indicating that the model is able to learn a faithful generativ e model for this quantum state. Conclusion W e introduced a discrete diffusion frame work that com- bines round-robin single-site noising with Neural Interaction Screening (NeurISE) to model high-dimensional categorical data. By learning single-site conditional distributions at intermediate diffusion steps, the proposed approach enables an sample efficient rev erse denoising process without requir- ing full joint likelihood estimation. Empirical results on a variety of synthetic and scientific datasets demonstrate that the method effecti vely captures complex dependenc y struc- tures in both image-based and physically motiv ated discrete systems. Our code is provided at Anonymous Github . 8 Submission and Formatting Instructions f or ICML 2025 Impact Statement This paper presents work whose goal is to advance the field of Machine Learning. There are many potential societal consequences of our work, none which we feel must be specifically highlighted here. References Anderson, B. D. Reverse-time dif fusion equation models. Stochastic Pr ocesses and their Applications , 12(3):313– 326, 1982. Austin, J., Johnson, D. D., Ho, J., T arlow , D., and V an Den Berg, R. Structured denoising dif fusion models in discrete state-spaces. Advances in neural information pr ocessing systems , 34:17981–17993, 2021. Bengio, Y ., Ducharme, R., V incent, P ., and Jauvin, C. A neural probabilistic language model. Journal of mac hine learning r esearc h , 3(Feb):1137–1155, 2003. Berend, D. and K ontorovich, A. On the con ver gence of the empirical distribution. arXiv pr eprint arXiv:1205.6711 , 2012. Bhatt, R. and Y oung, A. Numerical studies of ising spin glasses in two, three, and four dimensions. Physical Revie w B , 37(10):5606, 1988. Campbell, A., Benton, J., De Bortoli, V ., Rainforth, T ., Deli- giannidis, G., and Doucet, A. A continuous time frame- work for discrete denoising models. Advances in Neural Information Pr ocessing Systems , 35:28266–28279, 2022. Chen, H. and Y ing, L. Conv ergence analysis of discrete dif- fusion model: Exact implementation through uniformiza- tion. arXiv pr eprint arXiv:2402.08095 , 2024. Chen, S., Chewi, S., Li, J., Li, Y ., Salim, A., and Zhang, A. R. Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions. arXiv pr eprint arXiv:2209.11215 , 2022. De Bortoli, V ., Thornton, J., Heng, J., and Doucet, A. Diffu- sion schr ¨ odinger bridge with applications to score-based generativ e modeling. In Advances in Neur al Information Pr ocessing Systems , volume 34, 2021. Edwards, S. F . and Anderson, P . W . Theory of spin glasses. Journal of Physics F: Metal Physics , 5(5):965, 1975. Gretton, A., Borgwardt, K. M., Rasch, M. J., Sch ¨ olkopf, B., and Smola, A. A kernel two-sample test. The journal of machine learning r esear ch , 13(1):723–773, 2012. Haussmann, U. G. and P ardoux, E. Time re versal of dif fu- sions. The Annals of Pr obability , pp. 1188–1205, 1986. Ho, J. and Ermon, S. Generative adv ersarial imitation learn- ing. Advances in neural information pr ocessing systems , 29, 2016. Ho, J., Jain, A., and Abbeel, P . Denoising diffusion proba- bilistic models. Advances in neural information pr ocess- ing systems , 33:6840–6851, 2020. Jayakumar , A., Lokhov , A., Misra, S., and V uffray , M. Learning of discrete graphical models with neural net- works. Advances in Neural Information Pr ocessing Sys- tems , 33:5610–5620, 2020. Jayakumar , A., V uffray , M., and Lokhov , A. Y . Learn- ing energy-based representations of quantum man y-body states. Physical Revie w Researc h , 6(3):033201, 2024. Jin, W ., Barzilay , R., and Jaakkola, T . Junction tree vari- ational autoencoder for molecular graph generation. In International confer ence on machine learning , pp. 2323– 2332. PMLR, 2018. Li, T ., Chen, M., Guo, B., and Shen, Z. A surv ey on dif fu- sion language models. arXiv pr eprint arXiv:2508.10875 , 2025. Lou, A., Meng, C., and Ermon, S. Discrete diffusion mod- eling by estimating the ratios of the data distrib ution. In International Conference on Machine Learning , pp. 32819–32848. PMLR, 2024. McGeoch, C. and Farr ´ e, P . The D-wav e advan- tage system: An ov erview . T echnical Report 14-1049A-A, D-W ave Systems Inc., Burnaby , BC V5G 4M9, Canada, September 2020. URL https://www.dwavequantum.com/media/ s3qbjp3s/14- 1049a- a_the_d- wave_ advantage_system_an_overview.pdf . Ou, J., Nie, S., Xue, K., Zhu, F ., Sun, J., Li, Z., and Li, C. Y our absorbing discrete diffusion secretly models the conditional distributions of clean data. arXiv pr eprint arXiv:2406.03736 , 2024. Rudolf, D., Smith, A., and Quiroz, M. Perturbations of markov chains. arXiv preprint , 2024. Ryu, S. Minimal implementation of a d3pm (structured denoising diffusion models in discrete state-spaces), in pytorch. https://github.com/cloneofsimo/ d3pm , 2024. Santos, J. E., Fox, Z. R., Lubbers, N., and Lin, Y . T . Black- out dif fusion: generative diffusion models in discrete- state spaces. In International Confer ence on Machine Learning , pp. 9034–9059. PMLR, 2023. 9 Submission and Formatting Instructions f or ICML 2025 Song, Y ., Sohl-Dickstein, J., Kingma, D. P ., Kumar , A., Er- mon, S., and Poole, B. Score-based generative modeling through stochastic dif ferential equations. arXiv pr eprint arXiv:2011.13456 , 2020. Sun, H., Y u, L., Dai, B., Schuurmans, D., and Dai, H. Score- based continuous-time discrete dif fusion models. arXiv pr eprint arXiv:2211.16750 , 2022. T orlai, G., Mazzola, G., Carrasquilla, J., Tro yer, M., Melko, R., and Carleo, G. Neural-network quantum state tomog- raphy . Natur e physics , 14(5):447–450, 2018. V arma, H., Nagaraj, D., and Shanmugam, K. Glauber gen- erativ e model: Discrete diffusion models via binary clas- sification. arXiv pr eprint arXiv:2405.17035 , 2024. 10 Submission and Formatting Instructions f or ICML 2025 A. Algorithm In this section, we present the Neurise based denoising diffusion algorithm introduced in the paper . Algorithm 1 Discrete Diffusion with NeurISE 1: Input: alphabet Σ with | Σ | = p , dimension q , steps T , noise ε ∈ [0 , 1] , data distribution µ 0 (samples , σ 0 ∼ µ 0 ), Number of samples N . Forward diffusion 2: Sample time index t ∼ Unif ( { 1 , 2 , . . . , T } ) 3: Initialize σ ← σ 0 4: f or n = 1 , 2 , . . . , N do 5: u ← (( t − 1) mo d q ) + 1 6: Set σ − u ← σ − u 7: W ith probability 1 − ε change coordinate u according σ u ∼ Unif (Σ) 8: end f or 9: Output forward tuple ( t, σ 0 , σ t ) where σ t ← σ 10: Learn conditionals with NeurISE. 11: Goal: estimate single-site conditionals ˆ µ s ( · | σ s, − u ) for s = 0 , . . . , T − 1 12: f or s = 0 , 1 , . . . , T − 1 do 13: Generate noised samples at time s by running the forward kernel on data to obtain a batch { σ ( n ) s } N n =1 14: for u = 1 , 2 , . . . , q do 15: T rain NeurISE network NN θ by minimizing the NeurISE objectiv e ( 18 ) 16: Obtain conditional estimator ˆ µ s ( · | σ s, − u ) via ( 19 ) 17: end for 18: end f or 19: Rev erse sampling (denoising). 20: Initialize ˜ σ T ∼ Unif (Σ q ) 21: f or r = T − 1 , T − 2 , . . . , 0 do 22: u ← ( r mo d q ) + 1 23: Set ˆ k rev n according to ( 11 )-( 12 ) 24: Sample ˜ σ T − 1 ∼ ˆ k rev n ( σ T , · ) 25: end f or 26: retur n ˜ σ 0 B. Supplementary Numerics B.1. Soft Noise vs Harsh Noise In this section, we show our comparison of the harsh noise setting with soft noise ones, to facilitate comparison of autoregressi ve vs diffusion model. From our observation, the harsh noise setting performs better at lo w number of training samples and for large number of training samples, the models sho w very similar performance. See Figure 5 . Here, N denotes the total number of time-steps used in the noising and denosing phase, and e denotes the noise parameter ε . B.2. Local vs Global Neural Network In this section, we compare the performance of dif fusion models trained using two architectures: (i) a collection of local neural networks, with one network per time step, and (ii) a single global neural network shared across the entire time horizon. As shown in Fig. 6 , the local architecture consistently outperforms the global one, despite both approaches having approximately the same total number of trainable parameters. Specifically , in the local setting, each time step is modeled by a single-hidden-layer MLP with 5 hidden units, whereas the global model uses a fixed network of width 125. W e tested NeuRISE Diffusion for tw o different lattices: 2 × 2 and 3 × 3 , each with alphabet size 3 . As can be seen Figure 3 , the TV decreases in a statistically expected way as the number of training samples is increased from 10 2 to 10 5 . 11 Submission and Formatting Instructions f or ICML 2025 1 0 2 1 0 3 1 0 4 1 0 1 1 0 0 TV for L=25 e=0, N=1 e=0.2, N=2 e=0.2, N=4 e=0.8, N=15 (a) TV 1 0 2 1 0 3 1 0 4 1 0 0 1 0 1 1 0 2 T ime in Seconds for T raining e=0, N=1 e=0.2, N=2 e=0.2, N=4 e=0.8, N=15 (b) T raining Time F igure 5. T rend of TV and Training time for Ising models, av eraged 10 trials per data set. The test sample size was taken to be 10 4 for each experiment. The harsh noise version of the problem performs competitiv ely with situations where noise is soft. 1 0 2 1 0 3 1 0 4 1 0 1 1 0 0 TV for L=25 e=0, N=1, Global e=0, N=1, L ocal e=0.2, N=2, Global e=0.2, N=2, L ocal (a) TV 1 0 2 1 0 3 1 0 4 1 0 0 1 0 1 1 0 2 T ime in Seconds for T raining e=0, N=1, Global e=0, N=1, L ocal e=0.2, N=2, Global e=0.2, N=2, L ocal (b) T raining Time F igure 6. Trend of TV and Training time for Ising models, averaged 10 trials per data set. The test sample size was taken to be 10 4 for each experiment. Learning individual conditionals using separate neural networks achie ves lower TV , than using one global neural network across all conditionals. C. Theory For the presentation in this section, we introduce some additional notation. Giv en a probability distribution µ on Σ q , the action of the rev erse kernel k rev n on µ is defined by ( µk rev n )( ˜ σ ) = X σ ∈ Σ q µ ( σ ) k rev n ( σ, ˜ σ ) , ˜ σ ∈ Σ q . For two k ernels k rev n and k rev n − 1 , their composition is the kernel ( k rev n k rev n − 1 )( σ, σ ′ ) = X ˜ σ ∈ Σ q k rev n ( σ, ˜ σ ) k rev n − 1 ( ˜ σ , σ ′ ) , which corresponds to applying k rev n first and k rev n − 1 second. More generally , the composed rev erse kernel K rev 0: T − 1 = k rev T − 1 · · · k rev 0 satisfies ( K rev 0: T − 1 )( σ T , σ 0 ) = X σ 1 ,...,σ T − 1 ∈ Σ q T − 1 Y t =0 k rev t ( σ t +1 , σ t ) , 12 Submission and Formatting Instructions f or ICML 2025 where σ T denotes the state at time T and σ 0 the state at time 0 . Finally , the distribution obtained by initializing the re verse chain from µ noise is ν 0 ( σ 0 ) = ( µ noise K rev 0: T − 1 )( σ 0 ) = X σ T ∈ Σ q µ noise ( σ T )( K rev 0: T − 1 )( σ T , σ 0 ) . Theorem 3.1. Let { X n } T n =0 be the Markov chain on Σ q with forwar d transition kernels k n : Σ q × Σ q → R ≥ 0 . F ix a noise r eference distrib ution µ noise on Σ q and assume that for some δ T ∈ [0 , 1] , ∥ µ T − µ noise ∥ TV ≤ δ T . (6) Let { k rev n } T − 1 n =0 be a well-defined family of re verse kernels that satisfy ( 4 ) . Consider appr oximate r everse k ernels { b k rev n } T − 1 n =0 such that for all n = 0 , . . . , T − 1 , sup σ ∈ Σ q b k rev n ( · , σ ) − k rev n ( · , σ ) TV ≤ η. (7) Initialize the appr oximate r everse c hain with the noise r eference , i.e. Y T ∼ µ noise , and let b µ 0 denote the law of the output Y 0 obtained by applying b k rev T − 1 , . . . , b k rev 0 . Then the output distribution satisfies ∥ ˆ µ 0 − µ 0 ∥ TV ≤ δ T |{z} Mixing err or + T η . |{z} Reverse kernel estimation err or (8) Pr oof. Let K rev 0: T − 1 denote the composition of the exact reverse kernels k rev T − 1 , . . . , k rev 0 (applied in this order), and let b K rev 0: T − 1 denote the composition of the approximate rev erse kernels b k rev T − 1 , . . . , b k rev 0 . Let ν 0 be the law of the output obtained by running the e xact re verse chain initialized at time T from µ noise , i.e. ν 0 := µ noise K rev 0: T − 1 . Since the kernels { k rev n } satisfy ( 4 ), initializing the exact re verse chain from µ T yields µ 0 . Hence, µ 0 = µ T K rev 0: T − 1 . By the data processing inequality ∥ ν 0 − µ 0 ∥ TV ≤ ∥ µ noise − µ T ∥ TV ≤ δ T . (IE) Let b µ 0 be the law of the output of the appr oximate reverse chain initialized from µ noise , i.e. b µ 0 := µ noise b K rev 0: T − 1 . W e bound ∥ b µ 0 − ν 0 ∥ TV by a telescoping argument as is used in pertubation theory of Markov chains ( Rudolf et al. , 2024 ). Define intermediate distributions for m = 0 , 1 , . . . , T : ρ ( m ) := µ noise b k rev T − 1 · · · b k rev T − m k rev T − m − 1 · · · k rev 0 , with the con vention that ρ (0) = ν 0 and ρ ( T ) = b µ 0 . Then by the triangle inequality , ∥ b µ 0 − ν 0 ∥ TV = ∥ ρ ( T ) − ρ (0) ∥ TV ≤ T X m =1 ∥ ρ ( m ) − ρ ( m − 1) ∥ TV . Fix m ∈ { 1 , . . . , T } and set α ( m ) := µ noise b k rev T − 1 · · · b k rev T − m +1 , 13 Submission and Formatting Instructions f or ICML 2025 so that ρ ( m ) = α ( m ) b k rev T − m k rev T − m − 1 · · · k rev 0 and ρ ( m − 1) = α ( m ) k rev T − m k rev T − m − 1 · · · k rev 0 . Using contraction of TV under a common kernel, ∥ ρ ( m ) − ρ ( m − 1) ∥ TV ≤ α ( m ) b k rev T − m − α ( m ) k rev T − m TV . For an y distribution α and kernels P, Q on Σ q , ∥ αP − αQ ∥ TV ≤ sup σ ∈ Σ q ∥ P ( · , σ ) − Q ( · , σ ) ∥ TV . Applying this with α = α ( m ) , P = b k rev T − m , Q = k rev T − m and the estimation error , we get, ∥ ρ ( m ) − ρ ( m − 1) ∥ TV ≤ η. (KE) Combining giv es ∥ b µ 0 − ν 0 ∥ TV ≤ T η . Finally , by the triangle inequality , ∥ b µ 0 − µ 0 ∥ TV ≤ ∥ b µ 0 − ν 0 ∥ TV + ∥ ν 0 − µ 0 ∥ TV ≤ T η + δ T , which concludes the proof. Corollary C.1. (Initialization err or) In the setting of Theor em 3.1 , let b µ noise be any distribution on Σ q such that for some γ ∈ [0 , 1] , b µ noise − µ noise TV ≤ γ . (9) Initialize the appr oximate r ever se chain with Y T ∼ b µ noise , and let e µ 0 denote the law of the output Y 0 obtained by applying b k rev T − 1 , . . . , b k rev 0 . Then the output distribution satisfies e µ 0 − µ 0 TV ≤ δ T |{z} Mixing Err or + T η |{z} Reverse kernel estimation err or + γ . |{z} Noise sampling err or (10) Pr oof. Let b K rev 0: T − 1 denote the composition of the approximate rev erse kernels. Define b µ 0 := µ noise b K rev 0: T − 1 , e µ 0 := b µ noise b K rev 0: T − 1 . The TV norm under the action of a Markov kernel Q remains preserved (this follo ws trivially from P σ ∈ Σ q Q ( σ, ˜ sig ma ) = 1) and hence, e µ 0 − b µ 0 TV = ( b µ noise − µ noise ) b K rev 0: T − 1 TV ≤ b µ noise − µ noise TV ≤ γ . The claim follows by the triangle inequality together with Theorem 3.1 , which gi ves ∥ b µ 0 − µ 0 ∥ TV ≤ δ T + T η . C.1. Non-uniqueness of Reverse Pr ocesses In this section, we highlight that, in general, the reverse process associated with a forward Mark ov chain is not unique. Even when the marginal distrib utions µ t at each time t ∈ { 0 , . . . , T } are fixed, there may e xist multiple valid re verse dynamics that recov er the same marginals. 14 Submission and Formatting Instructions f or ICML 2025 Let { X t } T t =0 be a forward Marko v process over Σ q , with X t ∼ µ t for each t . The canonical construction of the re verse process introduced in the main text uses Bayes’ rule: P ( X t = σ | X t +1 = ˜ σ ) = P ( X t = σ, X t +1 = ˜ σ ) P ( X t +1 = ˜ σ ) = P ( X t +1 = ˜ σ | X t = σ ) · P ( X t = σ ) P ( X t +1 = ˜ σ ) . This defines a valid re verse kernel based on the forward transition probabilities and the marginal distributions µ t . This is the expression used in 5 . Howe ver , other rev erse processes may exist that yield the same marginals. Let { Y t } T t =0 be another sequence of random variables o ver Σ q such that: P ( Y t = σ ) = P ( X t = σ ) = µ t ( σ ) for all t ∈ { 0 , . . . , T } . (20) Then Y t is a valid alternati ve re verse process if it satisfies the marginal constraints abo ve. As an illustrativ e e xample, consider the extreme case where the rev erse kernel is marginally independent of the conditioning variable: P ( Y t = σ | Y t +1 = ˜ σ ) = µ t ( σ ) . (21) In other words, the re verse step simply resamples from the marginal µ t , ignoring the previous state Y t +1 . Now fix Y T = X T ∼ µ T , and define Y t recursiv ely using (2). Then we show by induction that: P ( Y t = σ ) = X ˆ σ ∈ Σ q P ( Y t = σ | Y t +1 = ˆ σ ) · P ( Y t +1 = ˆ σ ) = X ˆ σ ∈ Σ q µ t ( σ ) · µ t +1 ( ˆ σ ) = µ t ( σ ) · X ˆ σ ∈ Σ q µ t +1 ( ˆ σ ) = µ t ( σ ) , since µ t +1 is a probability distribution and thus sums to 1. In this degenerate case, the re verse kernel k rev t : Σ q × Σ q → R ≥ 0 is defined by: k rev t ( σ, ˜ σ ) := P ( Y t = σ | Y t +1 = ˜ σ ) = µ t ( σ ) ∀ ˜ σ ∈ Σ q . (22) That is, k rev t ( · , ˜ σ ) is simply the marginal distribution µ t , regardless of the value of ˜ σ . This rev erse kernel completely ignores the conditioning state and independently resamples σ ∼ µ t at each step. While this kernel does not capture the time-re versal of the actual forward dynamics, it still guarantees the correct mar ginal distributions at e very time step: µ t ( σ ) = X ˜ σ ∈ Σ q k rev t ( σ, ˜ σ ) · µ t +1 ( ˜ σ ) = µ t ( σ ) · X ˜ σ ∈ Σ q µ t +1 ( ˜ σ ) = µ t ( σ ) . This construction sho ws that the re verse process is not uniquely determined by the mar ginal sequence { µ t } T t =0 , and highlights a family of re verse dynamics that can be arbitrarily different from the canonical re verse Marko v process. In fact, the set of all admissible rev erse kernels that satisfy the mar ginal condition is con ve x; an y con vex combination of two valid re verse kernels k rev t, 1 and k rev t, 2 also yields a valid re verse kernel, k rev t = λk rev t, 1 + (1 − λ ) k rev t, 2 , for any λ ∈ [0 , 1] . 15 Submission and Formatting Instructions f or ICML 2025 This further underscores the flexibility and ambiguity inherent in defining re verse-time dynamics. It is important to emphasize that the transitions defined by general re verse kernels are not local . Unlike the canonical rev erse process where transitions are typically constrained to move between configurations that dif fer by a single spin (i.e., Hamming distance one) this degenerate re verse kernel allo ws transitions between any two configurations in Σ q , regardless of their Hamming distance: k rev t ( σ, ˜ σ ) = µ t ( σ ) for all σ, ˜ σ ∈ Σ q . In other words, starting from an y configuration ˜ σ , the re verse process can jump to an y other configuration σ ∈ Σ q in a single step, with probability determined solely by the mar ginal µ t ( σ ) . There is no notion of continuity or neighborhood preserv ed by the dynamics. This contrasts sharply with reverse processes, where transitions are typically limited to configurations that differ by only one coordinate. Thus, while the degenerate rev erse process is mathematically valid and correctly reproduces the marginal distrib utions µ t , it does not preserve the locality structure of the forward process. Its ability to transition freely between any two configurations in Σ q , without regard for neighborhood structure, leads to a re verse kernel that is inherently non-local. In high-dimensional spaces, such non-local kernels operate o ver the entire Σ q × Σ q transition space, making them exponentially more complex to represent, learn, or approximate. On the other hand, kernels for local update rules scale linearly and generalize more easily . D. Numerical Implementation Details D.1. Model Ar chitecture W e use the follo wing architecture for each of the cases : • Input block: Linear( d in → h ) → Lay erNorm( h ) → SiLU , where d in is dependent on the denoising algorithm. • Hidden blocks (up to D − 1 blocks, depending on depth D ∈ { 1 , . . . , 5 } ): Linear( h → h ) → Lay erNorm( h ) → SiLU . • Output layer: Linear( h → 2) . D.2. Shar ed hyperparameter sweep For e very dataset–denoising algorithm combination, we run a small hyperparameter optimization loop o ver the following parameter using the hyper opt packag e in Python: • Depth: D ∈ { 1 , .., 5 } • Width: h ∈ { 64 , 128 , 256 , 512 } • Noise parameter (Only for NeurISE Dif fusion): ε ∈ (0 , 1) • Noising time horizon (Only f or NeurISE Diffusion): T ∈ [0 , 2 , ... 10] • Learning rate: lr ∈ (10 − 4 , 5 × 10 − 2 ) with log uniform distribution. • W eight decay: w ∈ (10 − 8 , 10 − 3 with log uniform distribution. • Batch Size: [64 , 128 , 256 , 512] D.3. SEDD Implementation details In the implementation of SEDD ( Lou et al. , 2024 ), we introduced a final layer that enforced positivity in the output of the layer for the score approximation. While it is claimed that the loss function introduced in ( Lou et al. , 2024 ) naturally forces the output of the network to wards non-negati vity , we did not observe this in our implementation, and in fact found that the training algorithm returned NaNs if the final layer was not appropriately augmented. Additionally , the inputs were required to be one-hot coded entirely in order for algorithm to sho w any significant learning. In contrast, for the Neurise Diffusion and D3PM only conditioning parameters were required to be one-hot coded. 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment