MetaOthello: A Controlled Study of Multiple World Models in Transformers
Foundation models must handle multiple generative processes, yet mechanistic interpretability largely studies capabilities in isolation; it remains unclear how a single transformer organizes multiple, potentially conflicting "world models". Previous …
Authors: Aviral Chawla, Galen Hall, Juniper Lovato
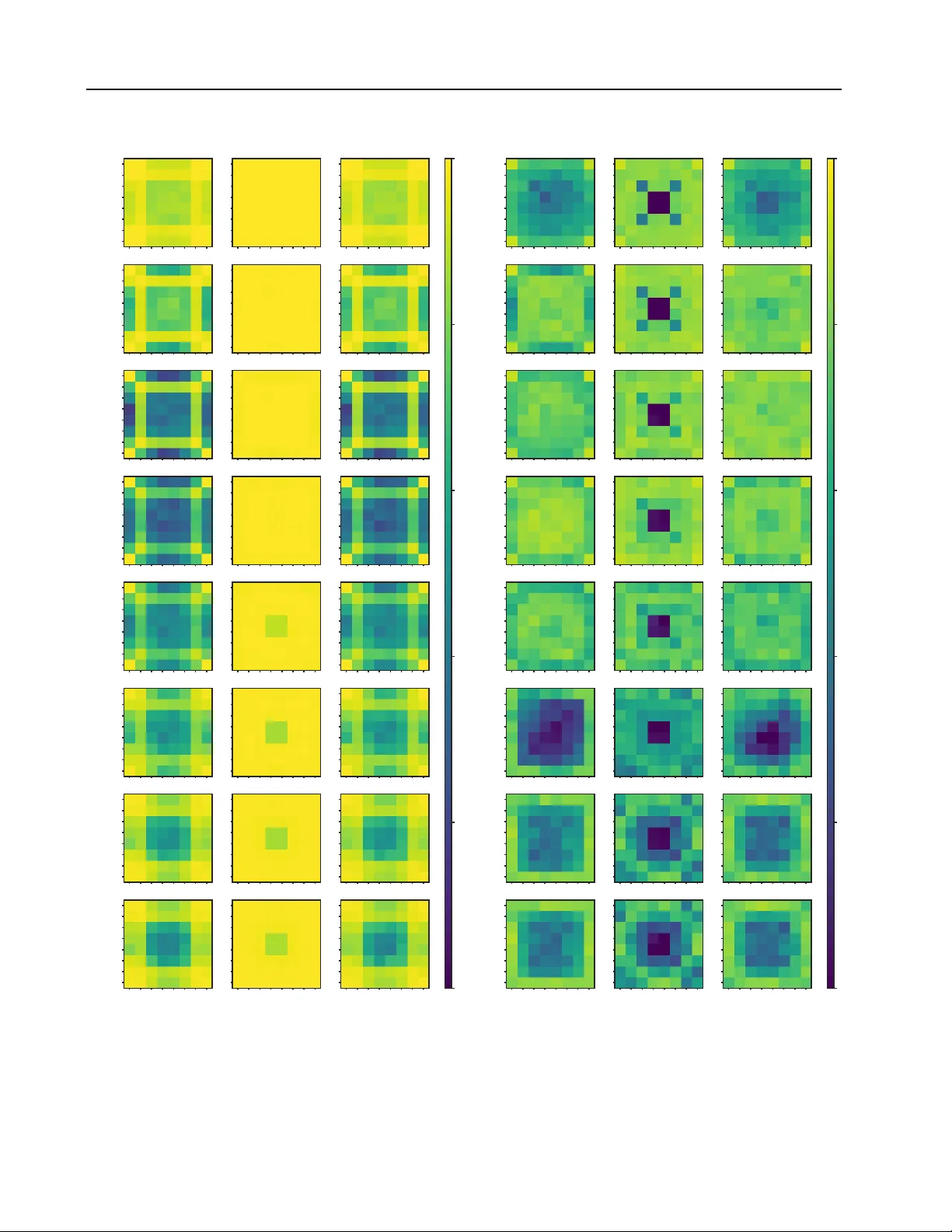
MetaOthello: A Contr olled Study of Multiple W orld Models in T ransf ormers A viral Chawla * 1 Galen Hall * 2 Juniper Lov ato 1 3 Abstract Foundation models must handle multiple gen- erativ e processes, yet mechanistic interpretabil- ity largely studies capabilities in isolation; it re- mains unclear how a single transformer organizes multiple, potentially conflicting “world models”. Previous experiments on Othello playing neural- networks test world-model learning but focus on a single game with a single set of rules. W e intro- duce MetaOthello , a controlled suite of Othello variants with shared syntax b ut dif ferent rules or tokenizations, and train small GPTs on mixed- variant data to study ho w multiple world models are organized in a shared representation space. W e find that transformers trained on mix ed-game data do not partition their capacity into isolated sub- models; instead, they conv er ge on a mostly shared board-state representation that transfers causally across variants. Linear probes trained on one variant can intervene on another’ s internal state with effecti veness approaching that of matched probes. For isomorphic games with token remap- ping, representations are equiv alent up to a single orthogonal rotation that generalizes across lay- ers. When rules partially overlap, early layers maintain game-agnostic representations while a middle layer identifies game identity , and later layers specialize. MetaOthello offers a path to- ward understanding not just whether transformers learn world models, b ut ho w they or ganize man y at once. 1. Introduction Large transformer models trained on di verse data must han- dle multiple generative processes. One model must translate languages, debug code, solve arithmetic, and it must de- termine which sort of text to simulate based on context * Equal contribution 1 V ermont Complex Systems Institute, Uni- versity of V ermont, Burlington, VT 2 Univ ersity of Michig an, Ann Arbor , MI 3 Department of Computer Science, Uni versity of V er- mont, Burlington, VT. Correspondence to: A viral Chawla < avi- ral.chawla@uvm.edu > . Pr eprint. F ebruary 27, 2026. ( Merullo et al. , 2024 ; T odd et al. , 2024 ). Mechanistic inter- pretability has made strides in understanding how models represent individual concepts ( P ark et al. , 2024 ), and imple- ment specific tasks ( W ang et al. , 2022 ), including e vidence of emergent internal state-tracking (“w orld models”) 1 Y et these analyses study one task at a time. Real models face het- erogeneous data where multiple rule systems coexist—and may conflict. This raises a question: how does a single transformer org anize multiple world models within a shared representation space in Othello-GPT and related systems ( Li et al. , 2024 ; Nanda et al. , 2023 ). Addressing this question in large-scale models is challeng- ing due to the difficulty of isolating specific rule systems in naturalistic data. W e address this gap with MetaOthello , a toy-model frame work for generating v ariants of Othello that share a common syntax (an 8 × 8 board) but dif fer in their underlying physics (update rules and validity logic). W e train small transformers on “pure” datasets generated by a single game, and “mixed” datasets generated by sampling from a pair of variants. Our main findings are: Cross-v ariant alignment. Transformers trained on het- erogeneous game data do not partition their capacity into isolated sub-models. Instead, board-state representations learned for one game transfer causally to others. Linear probes trained on one variant can interv ene on another’ s in- ternal state with effecti veness approaching matched probes. Syntax in variance. For isomorphic games with scram- bled tokenization, representations are equiv alent up to a single orthogonal rotation that generalizes across layers— demonstrating the model learns abstract structure indepen- dent of surface tokens. Layerwise routing and economization. When rules par- tially ov erlap, early layers track game-agnostic board state while a middle layer identifies game identity; later layers apply game-specific rules. The model economizes by keep- ing representations shared where games o verlap, di verging only where rules explicitly conflict. 1 Follo wing Li et al. ( 2025 ), we use ’world model’ to mean a causally complete representation—one sufficient to reconstruct the latent state of the data-generating process, without implying the model ’understands’ that state. 1 MetaOthello: A Controlled Study of Multiple W orld Models in T ransformers Flanking Flanking Neighbor Classic NoMidFlip DelFlank Initialization V alidation Rule Update Rule Game Sampled seq. ambiguous Classic Diver ges NoMidFlip Diver ges ... Input Sequence s 0 . 98 across the board. Performance dips by about half a percentage point in mixed models as compared to their single-game alternates, particularly in the second half of the game (see Appendix Figure 7 ). Second, generalizing the result from Nanda et al. 2023 , we sho w that linear probes can accurately infer values of “mine, ” “yours, ” and “empty” at each board position for each game type (Appendix Figure 8 ). Probes trained on earlier layers and on mixed models show worse performance than those trained on later layers and single-game models. 3 MetaOthello: A Controlled Study of Multiple W orld Models in T ransformers 1 2 3 4 5 6 7 8 Layer 0.0 0.2 0.4 0.6 0.8 1.0 Mean Cosine Similarity Classic vs. DelFlank 1 2 3 4 5 6 7 8 Layer Classic vs. Iago 1 2 3 4 5 6 7 8 Layer Classic vs. NoMidFlip Raw Procrustes-aligned Random baseline (raw) Random baseline (Procrustes) F igure 2. Cosine similarity between board state probe weights in mixed models, with random baseline controls. Blue bars show raw cosine similarity; orange bars show similarity after per-layer Procrustes alignment. Black circles and squares indicate expected similarity for random probes (shuffled to preserve distrib ution) before and after alignment, respectively . For Classic vs. Iago (center), raw similarity matches the random raw baseline (0.03). Howev er , after alignment, similarity reaches 0.98—substantially exceeding the random Procrustes baseline of 0.68. Error bars denote 95% CIs across 192 probe dimensions. T able 1. Model Performance: W e measure model performance us- ing the α metric to ensure comparability across games. All models perform well, with α = 1 indicating perfect ov erlap between the model’ s predicted probabilities and the ground truth. Model Name Game A vg. α Score ± CI Classic Classic 0 . 995 ± 0 . 002 Nomidflip Nomidflip 0 . 988 ± 0 . 003 Delflank Delflank 0 . 997 ± 0 . 001 Iago Iago 0 . 994 ± 0 . 002 Classic-Nomidflip Classic 0 . 991 ± 0 . 003 Classic-Nomidflip Nomidflip 0 . 983 ± 0 . 004 Classic-Delflank Classic 0 . 992 ± 0 . 002 Classic-Delflank Delflank 0 . 995 ± 0 . 002 Classic-Iago Classic 0 . 992 ± 0 . 003 Classic-Iago Iago 0 . 991 ± 0 . 003 Nomid-Delflank Nomidflip 0 . 984 ± 0 . 004 Nomid-Delflank Delflank 0 . 996 ± 0 . 002 5.2. Cross-v ariant alignment of board-state features Giv en that mixed-game models linearly encode board states for all variants, we in vestigate their internal organization: does the model partition its residual stream into distinct subspaces for each game, or does it utilize a shared rep- resentational format? W e first examine this question for rule-modified variants (NoMidFlip, DelFlank), then sepa- rately for the tokenization-scrambled v ariant (Iago), which requires distinct methodology . 5 . 2 . 1 . “ P L A T O N I C ” B O A R D R E P R E S E N TA T I O N G E O M E T RY W e first ev aluate the similarity of the linear probes trained for each game variant. Each board state probe consists of a R 192 × 512 matrix in which each row corresponds to a vector w i,c which represents a direction in the activ ation space corresponding to a specific board feature (e.g., “tile C3 is Mine”). W e pair probe weights from Classic and variant probes trained on the mixed-model residual stream and calculate their cosine similarities, yielding 192 v alues per layer . Figure 2 reports av erages and 95% confidence interval; individual tile-lev el v alues appear in Appendix Figure 11 . Probe weight alignment methodology . T o assess whether probe weights encode the same features up to a rotation, we compute per-layer Procrustes alignment: for each layer ℓ , we find the orthogonal matrix R ℓ ∈ R 512 × 512 that best aligns W ℓ Classic to W ℓ V ariant via SVD of W ℓ V ariant ⊤ W ℓ Classic . W e then report cosine similarities be- tween corresponding rows of W ℓ Classic and W ℓ V ariant . Since we compare learned parameters rather than model outputs, no train/test split is required. For Classic vs. NoMidFlip, we observe high raw cosine similarity ( ≈ 0 . 95 ) in early and later layers where Procrustes alignment yields only modest further improvement ( ≲ 0 . 05 ). For Classic vs. DelFlank, raw similarity is moderate ( ≈ 0 . 67 ), but Procrustes alignment moves it to > 0 . 90 across the majority of layers. Both aligned similarities substantially exceed the random baseline ( ≈ 0 . 68 for Procrustes-aligned random matrices; Figure 2), confirming that the geometric correspondence reflects learned structure rather than high- dimensional coincidence. 4 MetaOthello: A Controlled Study of Multiple W orld Models in T ransformers 5 . 2 . 2 . C AU S A L E FFI C AC Y A N D C RO S S - P R O B E I N T E RV E N T I O N Representational similarity alone does not prove that the model uses these features in the same way . T o test the functional equiv alence of these board state representations, we perform a cross-probe intervention e xperiment. W e replicate the causal intervention from previous work on Othello-GPT ( Nanda et al. , 2023 ; Li et al. , 2024 ). W e use the probe weights to intervene on the board state, B , to con vince the model that the board state is altered, B ′ . W e alter the board state by either flipping the piece from “mine” to “yours” or vice-versa or by erasing it from the board. Concretely , we accomplish this by adding the corresponding probe weight vector to the acti vations h l ( s ) at each layer: h l ( s ) → h l ( s ) + γ w l i,c (2) where γ is a scaling factor and i, c index the tile and its post-intervention state. Follo wing ( Nanda et al. , 2023 ) we apply this steering across all eight layers at once. 2 W e then compute the error rate, the number of false positiv es and false neg ati ves for top- k predictions. As shown in Figure 3 , cross-probe interventions (hatched coral bars) are nearly as effecti ve as “correct-probe” in- terventions (blue bars) at steering the model’ s predicted board state. This dissociation between raw representational similarity and causal ef ficacy is notable: ev en when probe similarity is moderate (as in Classic–DelFlank), the Classic probe can intervene on DelFlank boards with comparable accuracy . 5.3. Syntax In variance: The Iago Experiment The preceding analyses examined g ames sharing tokeniza- tion but dif fering in rules. W e no w ask the complementary question: when games are computationally isomorphic but use permuted token vocab ularies, does the model still learn a shared latent representation? Probe weight analysis. Raw cosine similarity between Classic and Iago probes is indistinguishable from a ran- dom baseline ( ≈ 0 . 03 ; Figure 2 , center). Howe ver , after per-layer Procrustes alignment, similarity reaches 0.98— substantially exceeding the random-alignment baseline of 0.68. The model learns the same latent structure for both games, differing only by a rotation induced by the input vocab ularies. 2 All-layer intervention maximizes steering strength but may ov er-interv ene. γ = 5 for current work, b ut is not fully optimized. Single-layer ablations and potential compensation effects ( Mc- Grath et al. , 2023 ) remain open for circuit-le vel analysis; Section 5.4 partially addresses layer specificity . Classic NoMidFlip Game V ariant 0.0 0.5 1.0 1.5 2.0 2.5 Prediction Error 1.3 0.2 0.2 1.4 0.3 0.3 Classic vs NoMidFlip Classic DelFlank Game V ariant 1.3 0.2 0.2 2.1 0.2 0.2 Classic vs DelFlank Null Correct Cross F igure 3. Global intervention error across conditions. Gray bars show null baseline (no intervention); blue bars sho w correct-probe intervention; orange bars show cross-probe intervention. Error bars denote 95% CI. W e see that cross-probe intervention is nearly as effecti ve as the correct probe in steering board states. Residual stream alignment. W e test whether this rota- tional equiv alence extends to the full residual stream. W e estimate a single global transformation Ω ∈ R 512 × 512 via orthogonal Procrustes on paired Classic/Iago acti vations, pooling across all layers and positions, on a training set. W e then feed a test set of Classic sequences into the mix ed model, apply Ω at a specific intervention layer ℓ ′ , and mea- sure performance on corresponding Iago mov es. As shown in Figure 4 , intervening at any layer (e xcept for 8) recov ers near-baseline Iago performance. This is much higher than accuracy of Iago mo ves on Classic sequences ( α ≈ − 2 . 9 ) These results suggest that the transformer’ s board-state rep- resentations are largely syntax-in variant up to a token permu- tation. The same abstract state geometry can be reco vered via an approximately orthogonal transformation. Impor- tantly , this observ ation alone does not determine ho w such in variance is implemented internally . The aligned geome- try could reflect a single shared representation or multiple representations with similar structure, or something more nuanced. Our results therefore support representational iso- morphism across syntaxes, but stop short of establishing whether the model maintains one shared world model or multiple distinct instantiations with similar structure. 5.4. How do the models handle ambiguous sequences? Results from the previous section indicated that although the Classic and DelFlank/NoMidFlip board representations differ substantially for particular tile locations, states, and layers, intervening on the variant representation can still causally influence the Classic next token predictions approx- 5 MetaOthello: A Controlled Study of Multiple W orld Models in T ransformers 0 10 20 30 40 50 Move Number 0.90 0.92 0.94 0.96 0.98 1.00 Mean Iago Alpha Score Intervention layer Classic baseline Layer 1 Layer 2 Layer 3 Layer 4 Layer 5 Layer 6 Layer 7 Layer 8 F igure 4. Classic-to-Iago activ ation alignment via orthogonal Procrustes. W e feed Classic sequences to the mix ed Classic-Iago model, apply a learned orthogonal rotation Ω to the residual stream at layer l ′ , and measure ho w well the model predicts corresponding Iago mov es ( α score). imately as well as intervening on the Classic representation. As we indicate in the prior section, it is tempting to inter- pret this as causal evidence for the existence of a single shared linear board state representation in the model: a so- called “Platonic” representation ( Huh et al. , 2024 ). But in the mixed game conte xt – particularly Classic-NoMidFlip – this result raises a conundrum. There are many sequences s ∗ present in the languages of both games which generate nonequal board states and different v alid move sets: B ( s ∗ , g 1 ) = B ( s ∗ , g 2 ) , V ( s ∗ , g 1 ) = V ( s ∗ , g 2 ) . W e call these ambiguous sequences. For the model to per - form well on these sequences, it must predict a weighted combination of next tok ens drawing on the board states of both games, ev en though the prior results seem to sho w that there is effecti vely a single causal board state representation. Note that optimal prediction of a next token x for ambiguous sequences under the cross entropy loss is: P ( x | s ∗ , { g 1 , g 2 } ) = P ( g 1 | s ∗ ) 1 [ x ∈ V ( s ∗ , g 1 )] | V ( s ∗ , g 1 ) | + P ( g 2 | s ∗ ) 1 [ x ∈ V ( s ∗ , g 2 )] | V ( s ∗ , g 2 ) | . (3) In such cases of dif fering ne xt mo ve sets under s ∗ , ho w well does the model handle next-token prediction, how does it represent the board state(s), and how does it manage poten- tially conflicting representations? W e start by in vestigating these questions in the Classic-NoMidFlip model, where am- biguity is common. W e then mo ve to the Classic-DelFlank model, which presents an interesting edge case because of the lar ge difference in the sizes of the two games’ languages. 5.5. Diver ging games: Steering vectors gover n layerwise specialization In the Classic–NoMidFlip model games share v alidation rules and board dimensions but dif fer in update dynamics. This setup creates wide-spread ambiguity: sequences often remain v alid in both games until a specific mo ve triggers the div ergent update rules. This ambiguity can be quantified as the av erage entropy of the game identity conditionalized on a sequence sampled from the mixed game dataset, E [ H ( g | s
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment