Deepfake Word Detection by Next-token Prediction using Fine-tuned Whisper
Deepfake speech utterances can be forged by replacing one or more words in a bona fide utterance with semantically different words synthesized by speech generative models. While a dedicated synthetic
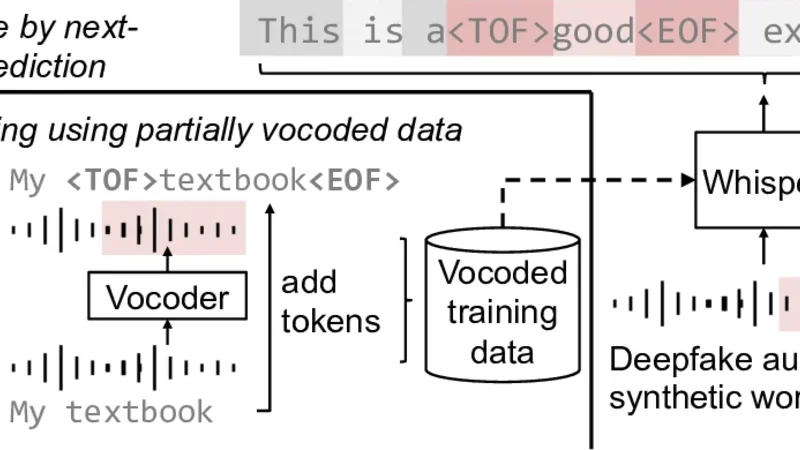
Deepfake speech utterances can be forged by replacing one or more words in a bona fide utterance with semantically different words synthesized by speech generative models. While a dedicated synthetic word detector could be developed, we investigate a cost-effective method that fine-tunes a pre-trained Whisper model to detect synthetic words while transcribing the input utterance via next-token prediction. We further investigate using partially vocoded utterances as the fine-tuning data, thereby reducing the cost of data collection. Our experiments demonstrate that, on in-domain test data, the fine-tuned Whisper yields low synthetic-word detection error rates and transcription error rates. On out-of-domain test data with synthetic words produced by unseen speech generative models, the fine-tuned Whisper remains on par with a dedicated ResNet-based detection model; however, the overall performance degradation calls for strategies to improve its generalization capability.
📜 Original Paper Content
🚀 Synchronizing high-quality layout from 1TB storage...