Don't stop me now: Rethinking Validation Criteria for Model Parameter Selection
Despite the extensive literature on training loss functions, the evaluation of generalization on the validation set remains underexplored. In this work, we conduct a systematic empirical and statistical study of how the validation criterion used for …
Authors: Andrea Apicella, Francesco Isgrò, Andrea Pollastro
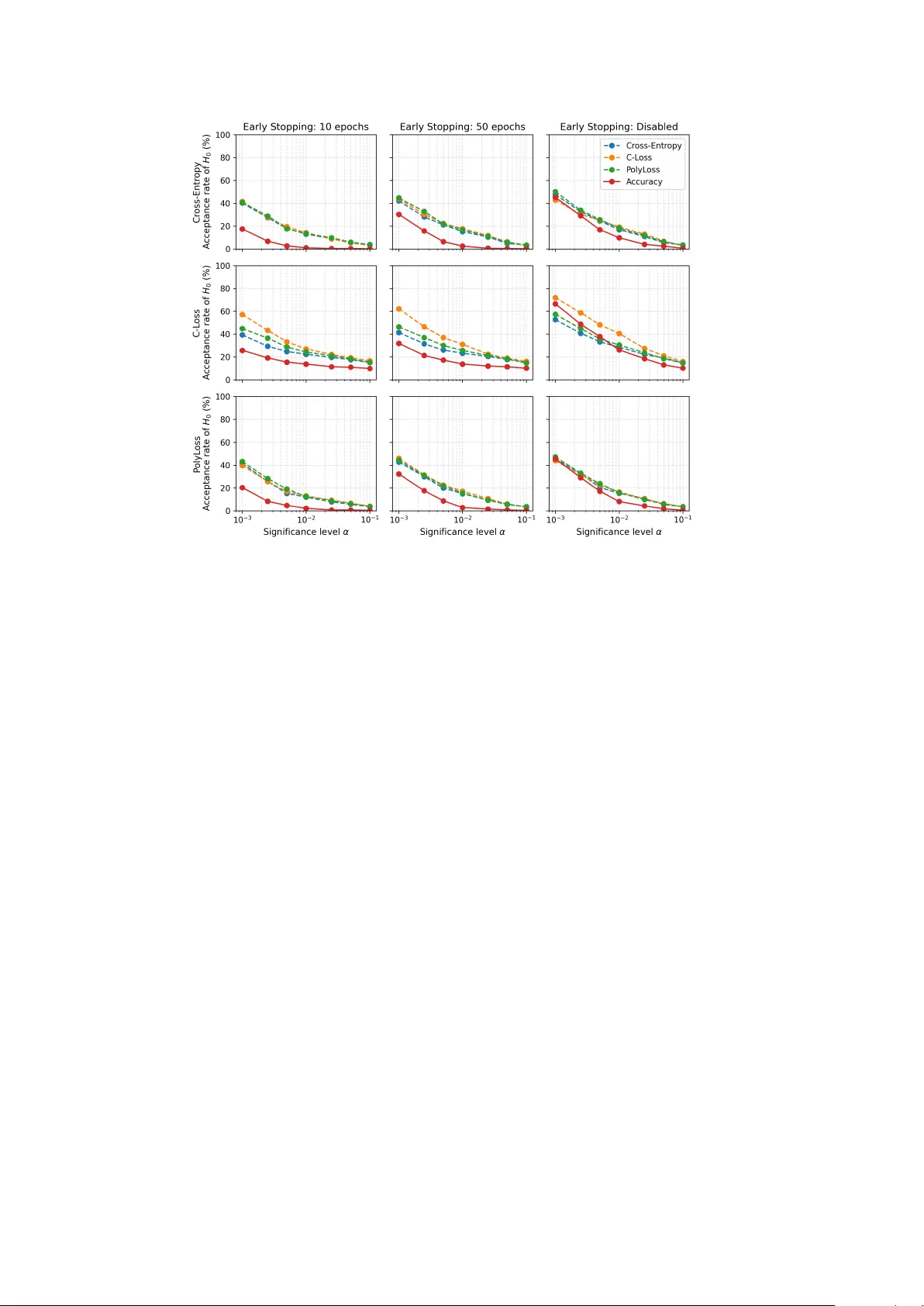
Don ’t stop me now : Rethinking V alidation Criteria for Mo del P arameter Selection Andrea Apicella 2 † , F rancesco Isgr` o 1 † , Andrea P ollastro 1 † , Rob erto Prev ete 1 † 1 Departmen t of Electrical Engineering and Information T echnology , Univ ersity of Naples F ederico I I, Via Claudio 21, Naples, 80125, Italy . 2 Departmen t of Information Engineering, Electrical Engineering, and Applied Mathematics (DIEM), Univ ersity of Salerno, Via Gio v anni P aolo II, 132, Fisciano (Salerno), 84084, Italy . Con tributing authors: andapicella@unisa.it ; francesco.isgro@unina.it ; andrea.p ollastro@unina.it ; rob erto.prev ete@unina.it ; † These authors contributed equally to this w ork. Abstract Despite the extensiv e literature on training loss functions, the ev aluation of gen- eralization on the v alidation set remains underexplored. In this w ork, we conduct a systematic empirical and statistical study of how the v alidation criterion used for mo del selection affects test performance in neural classifiers, with atten tion to early stopping. Using fully connected net works on standard benchmarks under k -fold ev aluation, w e compare: (i) early stopping with patience and (ii) p ost-hoc selection ov er all ep ochs (i.e. no early stopping). Mo dels are trained with cross- en tropy , C-Loss, or PolyLoss; the model parameter selection on the v alidation set is made using accuracy or one of the three loss functions, eac h considered inde- p enden tly . Three main findings emerge. (1) Early stopping based on v alidation accuracy p erforms w orst, consisten tly selecting chec kp oin ts with low er test accu- racy than b oth loss-based early stopping and p ost-hoc selection. (2) Loss-based v alidation criteria yield comparable and more stable test accuracy . (3) Across datasets and folds, an y single v alidation rule often underp erforms the test-optimal c heckpoint. Ov erall, the selected mo del t ypically achiev es test-set p erformance statistically low er than the b est p erformance across all ep ochs, regardless of the Corresp onding author: Andrea Apicella, andapicella@unisa.it Preprin t submitted to a journal for pubblication 1 v alidation criterion. Our results suggest a voiding v alidation accuracy (in partic- ular with early stopping) for parameter selection, fav oring loss-based v alidation criteria. Keyw ords: Machine Learning, ev aluation, data split, Deep Learning, AI 1 In tro duction In neural netw ork mo dels, training and ev aluation t ypically follow an iterative pro ce- dure — except in sp ecific architectures such as radial basis function netw orks — in whic h each iteration corresp onds to an ep o ch , up to a predefined maxim um num b er of ep o c hs. At each ep och, mo del parameters are up dated on a designated tr aining set through an up date rule, usually driven b y the gradient of a differentiable loss func- tion , suc h as cross-en tropy in classification problems. Since each epo c h yields a distinct parameter configuration, a separate validation set is commonly emplo yed to estimate the mo del’s generalization capability and to iden tify the parameter setting exp ected to generalize b est. After training and mo del parameter selection, the chosen mo del is finally ev aluated on a fully unseen test set using a task-dep enden t metric, for example accuracy for balanced classification, F1 score under class imbalance, or A UROC for ranking tasks. This paradigm is standard in sup ervised learning and underlies most mo dern exp erimental proto cols [ 1 ]. In practice, rather than running a fixed n umber of training ep o c hs, it is common to adopt an e arly stopping procedure [ 2 ], whereby training is halted once p erformance on the v alidation set ceases to improv e according to a predefined criterion. Early stopping can b e viewed primarily as a computationally conv enien t trade-off b et ween p erformance and training cost, as it a v oids ev aluating all possible intermediate models generated during training. F rom this persp ective, ov erfitting is not preven ted b y pre- maturely in terrupting optimization p er se, but b y selecting the mo del instance that maximizes an estimate of generalization. Importantly , the effectiv eness of this selection pro cess dep ends on the criterion used to assess generalization on the v alidation set. Despite the widespread use of v alidation-based selection, the criterion adopted to ev aluate generalization is not uniquely sp ecified. While the c hoice of the training loss is t ypically guided b y optimization and statistical considerations, and the test metric is dictated b y the deploymen t ob jectiv e, the v alidation criterion o ccupies an in termediate role that is not clearly tied to either parameter optimization or final ev aluation. As a result, different criteria are often adopted in practice, largely by conv ention. This am biguity is particularly evident in classification problems. Mo del parameters are commonly optimized by minimizing the cross-entrop y loss, whic h arises from maxim um lik eliho o d estimation and pro vides a principled surrogate for learning conditional class probabilities. Final p erformance, how ever, is often assessed using accuracy or other decision-based metrics that dep end on an explicit prediction rule and directly reflect deplo yment-lev el ob jectiv es. Consequently , improv emen ts in the training or v alidation loss do not necessarily translate into impro v ements in the ev aluation metric of interest, giving rise to the well-kno wn loss–metric mismatch [ 3 ]. 2 Motiv ated by this mismatc h, a substantial b o dy of work has explored alternative differen tiable loss functions designed to better align optimization with accuracy- orien ted ob jectiv es. Notable examples include the C-Loss proposed b y [ 4 ], whic h targets classification error through a contin uous surrogate, and P olyLoss [ 5 ], which generalizes cross-en tropy b y incorp orating higher-order polynomial terms. Despite these dev elopments, cross-en tropy remains the dominant optimization ob jectiv e in practice, and mo del parameter selection on the v alidation set is still most commonly p erformed using either v alidation loss or v alidation accuracy . As a consequence, different c hoices of p erformance metric on the v alidation set induce differen t orderings ov er the set of candidate models. In classification tasks, this raises a fundamen tal question: should generalization b e estimated using a proba- bilistic criterion suc h as cross-entrop y , whic h ev aluates the quality of predicted class probabilities, or using a decision-based metric such as accuracy , which directly reflects classification p erformance? These criteria correspond to distinct notions of risk and need not agree in practice, nor coincide with the mo del that maximizes test-set accu- racy . This c hoice b ecomes ev en more consequen tial under early stopping: the monitored v alidation metric not only ranks chec kp oints but also determines when training halts and whic h mo del parameters are actually chosen. As a consequence, misalignmen t b et w een the monitored metric and the task ob jective can therefore terminate training prematurely around a sub optimal lo cal minimum and lo c k in an inferior mo del. While it is well understo od that generalization can b e improv ed through explicit regularization techniques—suc h as w eight deca y , data augmentation, or drop out—as w ell as through implicit mechanisms including early stopping itself [ 6 , 7 ], our analysis addresses a distinct but related question. Rather than mo difying the learning pro cess to induce b etter generalization, we examine how different v alidation criteria estimate generalization for the purp ose of mo del parameter selection. Motiv ated by these considerations, this work inv estigates the practical and statis- tical implications of using v alidation cross-entrop y versus v alidation accuracy , as well as alternative accuracy-aligned loss functions, as criteria for selecting models aimed at maximizing test-set accuracy . Through a systematic empirical analysis on standard sup ervised b enc hmarks under a k -fold cross-v alidation proto col, we assess the extent to which different v alidation criteria lead to statistically meaningful differences in test p erformance. W e consider cross-entrop y , C-Loss [ 4 ], and P olyLoss [ 5 ] as optimization ob jectiv es on the training set. On the v alidation set, generalization is ev aluated using all corre- sp onding losses as well as accuracy , and mo del parameter selection is p erformed b oth within a patience-based early-stopping sc heme and by selecting the best-p erforming mo del across all training epo c hs. T o explore differen t generalization regimes under con- trolled conditions, and follo wing the theoretical insigh ts of Adv ani et al. [ 8 ], w e employ fully connected neural netw orks with a single hidden la yer. This con trolled arc hitec- tural setting allows us to study model selection behavior while limiting confounding factors in tro duced b y depth and complex optimization dynamics. F urther details are pro vided in Section 4.2 . Exp erimen ts were conducted on multiple b enc hmark datasets from the UCI Mac hine Learning Rep ository [ 9 ]. 3 F rom our exp erimen ts, the following main findings emerge: 1) When accuracy is used as the criterion to ev aluate generalization on the v alidation set, we consistently observ e the lo west test-set p erformance relativ e to the b est achiev able accuracy , regard- less of the loss function used during training. This effect is particularly pronounced under early stopping, where accuracy-based v alidation leads to a p oorer alignmen t with test-optimal p erformance compared to loss-based criteria, highligh ting the insta- bilit y of accuracy-based as a stopping criteria. 2) In contrast, when C-Loss, PolyLoss, or standard cross-en tropy are use d as v alidation criteria, the resulting test-set p er- formance is comparable across metho ds, and remains largely indep enden t of the loss function emplo yed during training. 3) Overall, irresp ective of the v alidation criterion, statistical testing indicates that the selected mo del achiev es significantly low er test p erformance than the test-optimal model in the ma jority of cases. In summary , this w ork makes the following contributions: (i) a systematic and statistically grounded exp erimen tal analysis of ho w different v alidation criteria—including cross-en tropy , C-Loss, PolyLoss, and accuracy—affect mo del selection and test-set generalization; (ii) a quantitativ e assessmen t of the loss–metric mismatch in v alidation-based mo del parameter selection with and without early stopping; (iii) practical implications for selecting v alidation criteria in accuracy-based classification tasks. The remainder of the pap er is organized as follows. Section 3 introduces notation, the ev aluation cri- teria and exp erimental proto col; Section 4 presen ts datasets, models, and ev aluation pro cedures; Section 5 rep orts the results discussing implications and limitations; and Section 6 concludes the work with final remarks. 2 Related W ork In sup ervised learning, mo dels are trained on lab eled data b elonging to a given task, with the aim to achiev e high v alues of a task p erformance measure [ 10 ]. How ev er, in sev eral tasks the target metric is often non-differen tiable (e.g., accuracy , F1) or yields flat/unstable gradients for gradient-based optimization. Consequently , training relies on differentiable surr o gate losses (e.g., cross-en tropy) that act as proxies for the task metric. How ev er, minimizing the training loss do es not guarantee improv ements in the deploymen t ev aluation metric (loss–metric mismatch, [ 3 ]). Motiv ated by this gap, sev eral works design losses that more closely reflect the task ob jectives: for example, the C-loss based on cross-corren tropy as a surrogate to the 0-1 risk [ 11 , 12 ], or prob- abilistic p erformance indices that jointly reward correctness, high probability for the true class, and low probabilit y for the others [ 13 ], or score-oriented losses that target confusion-matrix summaries [ 14 , 15 ]. Other w orks in tro duced task- and data-adaptive loss functions (e.g., PolyLoss [ 5 ]), defining parametric families in which standard ob jectiv es, such as cross-entrop y , arise as sp ecial cases. Regardless of the training ob jectiv e, generalization is ultimately assessed on held-out data (v alidation/test). While the test set is usually ev aluated using the effective task-sp ecific metric, the criterion used on the v alidation set can suffer from the same loss-metric mismatch: selecting che ckp oints , i.e., the ep o c h corre- sp onding to the mo del parameters to b e selected, by a surrogate such as cross-entrop y ma y fail to identify the mo del that maximizes the task-sp ecic metric (e.g., accuracy). 4 This observ ation underlies metho ds that explicitly couple training ob jectives with v al- idation feedback [ 3 ] and motiv ates a careful choice of v alidation criteria for mo del selection. F urthermore, when mo dels are ev aluated iteratively on a v alidation set, it is com- mon to use early stopping to truncate optimization b efore con vergence [ 2 ]. It was sho wn that stopping early can yield solutions comparable to those of smaller, optimally sized mo dels [ 16 ], and consistency results are av ailable under sp ecific assumptions [ 17 ]. The b enefit of early stopping dep ends on the loss and the geometry of the opti- mization landscap e: studies of loss surfaces and represen tation dynamics highligh t plateaus, saddle p oin ts, ov erconfidence, and how regularization shapes hidden-lay er enco dings [ 18 – 21 ]. Classical analyses inv estigated o vertraining dynamics for linear net works under quadratic loss and characterized v alidation-based stopping b oth geo- metrically and in time [ 22 – 24 ], while statistical views related early stopping to explicit regularization [ 6 , 7 ]. It is interesting to notice that optimal–stopping effects app ear b ey ond artificial neu- ral net works, notably in b o osting metho ds [ 25 – 28 ], and SVMs [ 29 ], whic h helps explain the widespread use of early stopping. More in general, stopping rules can b e applied either on training data or on a held-out v alidation set [ 30 ]. T raining-monitored criteria include, for example, a log-sensitivit y index for rare outcomes [ 31 ] and rules driven by training-loss tra jectories [ 32 ]; protocol-centric choices around how the hold-out split is constructed ha ve also b een explored [ 33 ]. How ever, some early pro cedures relied solely on training-set criteria or rep eatedly re-sampled “v alidation” from the train- ing p o ol [ 34 , 35 ], practices that can bias selection and inflate p erformance estimates [ 36 ]. V alidation-monitored rules span comparativ e studies and b enc hmarks of families and combinations [ 37 – 39 ], as well as practical heuristics such as fixed v alidation-error thresholds [ 40 ] or marginal-impro vemen t criteria [ 41 ]. In particular, P ACMAN [ 42 ] pro vides generalization b ounds that explicitly account for the discrepancy b et ween cross-entrop y and accuracy , while other works address the loss–metric mismatch through adaptive loss design [ 3 ] or empirical analyses of generalization b ehavior [ 43 ]. How ever, these approac hes do not directly examine the implications of this mismatch for v alidation-based mo del selection. In con trast, our w ork fo cuses on the statistical effectiv eness of mo del selection pro cedures driven by v alidation criteria, explicitly comparing v alidation-selected mo dels against the test- optimal mo del under controlled exp erimen tal settings. In summary , prior w ork highlights three themes that motiv ate our study: (i) mo dels are trained with surrogate losses that ma y not align with task metrics; (ii) v alidation criteria inherit this mismatc h and th us critically determine whic h chec k- p oin t is selected; and (iii) early stopping is often used to av oid running all ep ochs, so the v alidation signal effectively c ho oses the mo del instance among the per-ep o c h c heckpoints—making the choice of v alidation metric esp ecially imp ortant. Our study addresses these themes b y comparing v alidation accuracy with three loss-based v al- idation criteria (cross-entrop y , C-loss, and PolyLoss) within a unified experimental proto col. 5 3 Metho d 3.1 Notation In this work, we adopt the following notation. In supervised machine learning, a dataset D ∈ D consists of N input–lab el pairs D = { ( x ( i ) , y ( i ) ) } N i =1 , where x ( i ) denotes an input instance and y ( i ) the corresp onding ground-truth v alue. The set D denotes the collection of all p ossible datasets for the task under consideration. W e denote by T r ain , V al , T est ∈ D the training, v alidation, and test sets, resp ectiv ely . W e fo cus on a classification setting in which eac h input x ( i ) is assigned to one of K m utually exclusive classes { 1 , 2 , . . . , K } . F or simplicit y and without loss of generalit y , lab els are treated as one-dimensional discrete v alues, i.e., y ( i ) ∈ { 1 , 2 , . . . , K } . Giv en a mo del M ( θ ) with parameters θ and a dataset D ∈ D , let ℓ : D × { 1 , . . . , E } → R and a : D × { 1 , . . . , E } → [0 , 1] denote the loss and accuracy functions of the mo del at iteration e of a training pro ce- dure comp osed of E ∈ N ep ochs. That is, ℓ ( D, e ) and a ( D , e ) represen t, resp ectiv ely , the loss and the accuracy computed on dataset D at ep och e . F or a given dataset D ∈ D , define the optimal loss and accuracy v alues as L ⋆ D = min 1 ≤ e ≤ E ℓ ( D , e ) , A ⋆ D = max 1 ≤ e ≤ E a ( D , e ) . W e further define the corresponding optimal ep ochs as e ⋆ ℓ,D = arg min 1 ≤ e ≤ E ℓ ( D , e ) , e ⋆ a ,D = arg max 1 ≤ e ≤ E a ( D , e ) , i.e., the ep ochs achieving the minimum loss and maxim um accuracy , resp ectiv ely (see Figure 1 ). 3.2 P ost-ho c Checkpoint Selection v ersus Early Stopping W e can distinguish b etw een tw o v alidation-driven proto cols that are often not clearly distinguished in the literature: (i) during training, a v alidation-based criterion is mon- itored and, once it fails, training is halted and the b est chec kp oin t seen so far is retained. This is usually known as e arly stopping ; (ii) training pro ceeds for a fixed n umber of ep o c hs, after which the chec kp oin t with the b est v alidation score among all sa ved mo dels is selected. Here we refer to this as p ost-ho c che ckp oint sele ction . Within 6 e ⋆ ℓ,D e ⋆ a ,D E 0 . 5 1 1 . 5 2 ( e ⋆ ℓ,D , L ⋆ D ) ( e ⋆ a ,D , A ⋆ D ) ep och e Score ℓ ( D , e ) a ( D , e ) Fig. 1 : An example of loss ℓ ( D , e ) and accuracy a ( D , e ) across E ep o c hs on a dataset D . V ertical dashed lines mark the ep ochs achieving the v alidation-loss minimum e ⋆ ℓ,D and the v alidation-accuracy maximum e ⋆ a ,D ; horizontal dotted lines indicate the cor- resp onding v alues L ⋆ D = min e ℓ ( D , e ) (blue) and A ⋆ D = max e a ( D , e ) (orange). an early stopping proto col, training is terminated according to a predefined empirical criterion. A commonly adopted strategy is e arly stopping with p atienc e T , whereby training halts at the first ep och suc h that no improv ement in the v alidation loss has b een observed for T consecutiv e ep ochs. F ormally , this condition is expressed as ∃ ˆ e ℓ,V al : ∀ h ∈ { 1 , 2 , . . . , T } , ℓ ( V al, ˆ e ℓ,V al + h ) ≥ ℓ ( V al , ˆ e ℓ,V al ) . The selected mo del corresp onds to the mo del with loss ˆ L V al = ℓ ( V al , ˆ e ℓ,V al ). Instead, in p ost-ho c che ckp oint sele ction the training pro ceeds for all the fixed E ep ochs and the mo del is selected retrospectively as the one at iteration e ⋆ ℓ,V al = arg min 1 ≤ e ≤ E ℓ ( V al , e ). Figure 2 depicts b oth pro cedures, i.e., p ost-hoc chec kp oin t selection and early stopping—highligh ting. Note that when T = E , i.e., when the patience parameter equals the total num b er of ep ochs, e arly stopping with p atienc e T results in no early termination and is therefore equiv alent to p ost-hoc c heckpoint selection. 3.3 Statistical Comparison of Mo del Selection Criteria T o assess the effect of different model selection criteria on generalization p erformance, w e p erformed a systematic ev aluation comparing the test accuracy A test of models selected in b oth early stopping and p ost-hoc protocols, against the b est ac hiev able test accuracy observed throughout training. Our empirical analysis fo cused on supervised 7 ˆ e ℓ,V al ˆ e ℓ,V al + T e ⋆ ℓ,V al E 0 . 4 0 . 6 0 . 8 early-stopping selection p ost-ho c c hec kp oin t selection T ep ochs ep och e ℓ ( V al , e ) ℓ ( V al , e ) Fig. 2 : An example comparing e arly stopping with p atienc e T and p ost-ho c che ckp oint sele ction on the v alidation loss ℓ (V al , e ). The orange dashed line marks the p erformance v alue returned by early stopping (b est-so-far at ˆ e ℓ, V al , with training halted at ˆ e ℓ, V al + T ), whereas the blue dashed line marks the best v alidation p erformance v alue e ⋆ ℓ, V al iden tified retrosp ectiv ely . It is evident that the early-stopp ed chec kp oin t need not b e the b est-p erforming mo del: it corresp onds to a lo cal minimum reac hed b efore halting, whereas p ost-hoc c heckpoint selection identifies the global minimum ov er all ep ochs. classification tasks, where mo dels w ere trained using the CE loss and ev aluated in terms of accuracy . Our goal w as to quantify the extent to whic h accuracy obtained b y v alidation-based selection, using e ither the minim um v alidation loss L ⋆ V al or the maximum v alidation accuracy A ⋆ V al , deviated from the test-optimal accuracy A ⋆ T est , defined as the mo del instance that attained the highest test accuracy A T est across all training ep ochs. In other words, we wan t to chec k ho w muc h A ⋆ T est differs from a ( T est, e ⋆ ℓ,V al ) and a ( T est, e ⋆ a ,V al ), and similarly , a ( T est, ˆ e ℓ,V al ) and a ( T est, ˆ e a ,V al ) (see Figure 3 for a visual summary). 4 Exp erimen tal assessmen t 4.1 Datasets Exp erimen ts were conducted on multiple b enchmark datasets retrieved from the UCI Mac hine Learning Rep ository [ 9 ]. The list of the datasets inv olved in this work is sho wn in T able 1 . All datasets were prepro cessed using a unified and dataset-agnostic pip eline in order to ensure comparabilit y across exp erimen ts. Sp ecifically , categorical and binary features were transformed via one-hot enco ding, while numerical features were kept 8 Name Instances N. classes Name Instances N. classes Pen-Based Recognition of Handwritten Digits 8409 10 Breast Cancer Coimbra 89 2 Page Blo c ks Classification 5473 5 Maternal Health Risk 776 3 Molecular Biology (Splice-junction Gene Sequences) 2440 3 Spambase 3519 2 Steel Plates F aults 1484 2 Bank Marketing 5999 2 Bloo d T ransfusion Service Center 572 2 Raisin 688 2 W ebsite Phishing 1035 3 Letter Recognition 15300 26 T aiwanese Bankruptcy Prediction 5217 2 W av eform Database Generator (V ersion 1) 3825 3 Statlog (Image Segmentation) 1767 7 Hab erman’s Survival 234 2 V ertebral Column 237 3 Statlog (German Credit Data) 765 2 Optical Recognition of Handwritten Digits 4299 10 Breast Cancer 212 2 Drug Consumption (Quantified) 1442 7 Mammographic Mass 634 2 Y east 1135 10 Credit Approv al 499 2 Contraceptiv e Metho d Choice 1127 3 Hepatitis C Virus (HCV) for Egyptian patients 1059 4 Japanese Credit Screening 499 2 Chess (King-Ro ok vs. King-Pawn) 2445 2 Student Performance on an Entrance Examination 510 4 Predict Students’ Drop out and Academic Success 3384 3 Heart Disease 227 5 SPECT Heart 204 2 Room Occupancy Estimation 7749 4 Differentiated Thyroid Cancer Recurrence 293 2 ISOLET 5965 26 Statlog (V ehicle Silhouettes) 646 4 Musk (V ersion 2) 5048 2 National Poll on Healthy Aging (NPHA) 546 3 Breast Cancer Wisconsin (Diagnostic) 436 2 Hayes-Roth 101 3 Congressional V oting Records 177 2 Cardioto cograph y 1626 10 Cirrhosis Patient Survival Prediction 211 3 Autism Screening Adult 466 2 SPECTF Heart 204 2 Statlog (Heart) 206 2 Image Segmentation 160 7 ILPD (Indian Liver Patient Dataset) 443 2 NHANES 2013-2014 Age Prediction Subset 1743 2 Statlog (Australian Credit Approv al) 527 2 Ionosphere 268 2 Polish Companies Bankruptcy 15275 2 T able 1 : Summary of the datasets used in the exp erimen tal ev aluation retrieved from the UCI Machine Learning Rep ository [ 9 ]. F or each dataset, we rep ort the total n umber of instances and the num b er of target classes. in their original form. No dataset-sp ecific feature engineering or optimization was p erformed. W e emphasize that the goal of this prepro cessing was not to optimize p er- formance on the individual datasets to reach new state-of-the-art results, but rather to pro vide a simple and repro ducible input representation suitable for large-scale comparativ e analysis. Moreo ver, in the analysis of the results, w e explicitly account for differences in dataset complexit y by ordering datasets according to increasing linear separabilit y b et w een classes, as estimated b y the generalized discrimination v alue (GD V) [ 44 ]. This allo ws us to assess ho w model selection b eha vior v aries with dataset simplicity . 4.2 Mo dels F ollowing the theoretical insigh ts of [ 8 ], we employ ed fully connected neural net- w orks with a single hidden la yer and ReLU activ ation functions, in order to preserve arc hitectural simplicity and exp erimen tal controllabilit y while exploring different gen- eralization regimes. Indeed, as sho wn in [ 8 ], generalization b eha vior dep ends critically on the ratio b et ween the num b er of trainable parameters and the num b er of training samples. Accordingly , we define a parameter-to-sample ratio r , where r = 1 corresp onds to an equal n umber of mo del parameters and samples, while v alues b elo w or ab o v e 1 indicate under- and ov er-parameterized regimes, resp ectiv ely . Thus, the use of a shallo w architecture allows us to systematically explore these regimes by v arying the n umber of hidden units so as to con trol the total num b er of trainable parameters relativ e to the size of the training dataset. In our exp eriments, we consider the v alues r ∈ { 0 . 3 , 0 . 5 , 0 . 7 , 0 . 8 , 1 , 1 . 2 , 5 , 10 , 50 } . 9 Notice that w e delib erately focus on shallow neural netw orks with a single hid- den la yer, as our goal is not to ac hieve state-of-the-art p erformance, but to isolate and analyze the effect of v alidation criteria on mo del selection. Deeper arc hitectures in tro duce m ultiple additional factors–suc h as hierarchical representations, lay er-wise implicit regularization, and complex optimization dynamics–that can confound the in terpretation of v alidation-based selection mechanisms. By adopting a con trolled shallow setting, w e are able to systematically v ary the parameter-to-sample ratio and explore different generalization regimes while keep- ing architectural and optimization-related effects to a minimum. This choice enables a clearer assessmen t of how different v alidation criteria influence mo del selection, indep enden tly of depth-related phenomena. 4.3 Adopted losses Cross-en tropy: cross-entrop y loss, widely used in classification tasks, emerges naturally from the principle of maximum likelihoo d estimation under the assumption that the mo del outputs a categorical distribution o ver the classes. It is defined as ℓ CE = − N X i =1 K X k =1 t ( i ) k log Ä m ( i ) k ä where t is the one-hot encoded target vector t ( i ) ∈ { 0 , 1 } K of the actual lab el y ( i ) , i.e. t ( i ) k = 1 if k = y ( i ) , and t ( i ) k = 0 otherwise, and m ( i ) = ( m ( i ) 1 , . . . , m ( i ) K ) is the class output probability distribution of the mo del M on the input x ( i ) . Leng et al. [ 5 ] introduce PolyL oss , a p olynomial reparameterization of cross-en trop y obtained via its T aylor expansion around the correct-class confidence. Denoting by m y ( i ) the predicted probability for the true class of sample i , the loss takes the form ℓ PolyLoss = ∞ X j =1 α j 1 − m y ( i ) j , with coefficients { α j } j ≥ 1 to be tuned. In its natural (infinite) form, P olyLoss is imprac- tical and does not consistently outp erform standard cross-en tropy . T o address this, the authors prop ose a simplified, first-order truncation, ℓ Poly-1 = − log m y ( i ) + ϵ 1 − m y ( i ) , con trolled b y a scalar hyperparameter ϵ . The C-Loss [ 4 , 12 ] is a surrogate for the 0–1 loss built from the c orr entr opy [ 11 ] b et w een true lab els and mo del scores. Unlik e cross-en tropy , the C-Loss can b e more robust to outliers and label noise. In binary classification problems where y ( i ) ∈ {− 1 , 1 } and single output m ( i ) = M ( x ( i ) ), it is defined via a p ositiv e-definite kernel − k ( · ) (t ypically Gaussian): ℓ C ( y ( i ) , m ( i ) ) = β 1 − k σ ( y ( i ) − m ( i ) ) 10 with k σ ( u ) = exp − u 2 2 σ 2 , β and σ parameters prop erly c hosen. Multiclass v ariants can b e built by applying the one-class-versus-the-rest strategy . 4.4 T raining and Ev aluation Proto col Mo dels w ere trained for a maximum of E = 20 , 000 epo chs for eac h dataset using sto c hastic gradient descen t with a batc h size of 64 samples. The learning rate was set to 0 . 01 and fixed through all the training ep o c hs. T o obtain statistically reliable estimates, all results w ere computed under a 10-fold stratified cross-v alidation [ 45 ] sc heme. F or eac h fold, the 15 % of the training set was used for v alidation set V al using stratified sampling [ 45 ]. Prior to each training, all input features were then standardized using z -score nor- malization [ 46 , 47 ]. The normalization parameters (mean and standard deviation) were computed exclusively on the training portion of each fold and subsequently applied to the corresp onding v alidation and test sets, ensuring that no information from the held-out data leaked into the training pro cess [ 36 ]. W e emphasize that, as ab o ve discussed, the ob jective of this work is not to achiev e state-of-the-art p erformance on these b enchmarks, th us we inten tionally adopt simple and uniform prepro cessing rather than dataset-sp ecific prepro cessing prior to eac h training. F or each dataset and eac h fold, the mo del was trained while monitoring v alidation loss ℓ ( V al , e ) and v alidation accuracy a ( V al , e ) at ev ery ep och e . Mo del selection was p erformed based solely on v alidation criteria, but ev aluation was alwa ys carried out on the corresp onding T est fold. Sp ecifically , for each T est fold we computed: 1. the test accuracy of the mo del corresponding to the ep och with the minimum v alidation loss, denoted as a ( T est, e ⋆ ℓ,V al ); 2. the test accuracy of the mo del corresp onding to the ep och with the maxim um v alidation accuracy , denoted as a ( T est, e ⋆ a ,V al ); 3. the test-optimal accuracy , defined as the maximum test accuracy achiev ed across all training ep o c hs, denoted as A ⋆ T est . These three quan tities were collected for each fold, yielding paired samples of test accuracies for every dataset and every comparison. Analyses w ere p erformed through h yp othesis testing. F ormally , we tested: H 0 : µ a ( T est,e ⋆ a ,V al ) = µ A ⋆ T est vs. H 1 : µ a ( T est,e ⋆ a ,V al ) < µ A ⋆ T est , H 0 : µ a ( T est,e ⋆ ℓ,V al ) = µ A ⋆ T est vs. H 1 : µ a ( T est,e ⋆ ℓ,V al ) < µ A ⋆ T est , where µ a ( T est,e ⋆ a ,V al ) denotes the mean test accuracy obtained by selecting, for each fold, the mo del chec kp oin t corresp onding to the ep o c h that maximizes the v alidation accuracy a , and µ a ( T est,e ⋆ ℓ,V al ) denotes the mean test accuracy obtained by selecting the c heckpoint corresponding to the ep o c h that minimizes the v alidation loss ℓ . Sp ecifically , normalit y of the cross-v alidation results was first assessed using the Shapiro-Wilk test [ 46 ]. When normality was not rejected, a paired one-tailed t-test [ 46 ] was applied; otherwise, the one-tailed Wilcoxon signed-rank test [ 46 ] was used. The significance lev el w as set to α = 0 . 05. 11 0 . 5 1 1 . 5 ( e ⋆ ℓ,V al , L ⋆ V al ( e ⋆ a ,V al , A ⋆ V al ) Epo ch e ℓ ( V al , e ) , a ( V al, e ) ℓ ( V al,e ) a ( V al,e ) e ⋆ a ,V al e ⋆ ℓ,V al e ⋆ a ,T est E 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 ( e ⋆ ℓ,V al , a ( T est, e ⋆ ℓ,V al ) e ⋆ a ,V al , a ( T est, e ⋆ a ,V al ) ( e ⋆ a ,T est , A ⋆ T est ) a ( T est, e ) a ( test,e ) Fig. 3 : An example sho wing, in a single panel, the v alidation tra jectories (loss ℓ (V al , e ) in blue and accuracy a (V al , e ) in orange, left axis) together with the test accuracy tra jectory a (T est , e ) (green, righ t axis). V ertical dashed lines indicate the v alidation- selected ep o c hs e ⋆ a , V al and e ⋆ ℓ, V al , as w ell as the test–optimal ep o c h e ⋆ a , T est . Horizontal dotted lines mark L ⋆ V al and A ⋆ V al . The test accuracies achiev ed b y the tw o v alida- tion–driv en selections, a (T est , e ⋆ ℓ, V al ) and a (T est , e ⋆ a , V al ), contrasted with the best ac hiev able A ⋆ T est . 4.5 V alidation Criteria and Loss-Metric Com binations Mo dels were trained in separate runs, each using a single loss function, i.e. cross- en tropy loss, C-Loss, or Poly-1, as the training ob jective. In particular, C-Loss was used with parameters σ = 0 . 5 and β = 1, while P oly-1 was configured with ϵ = 1. F or each training run, the resulting sequence of mo del chec kp oin ts was ev aluated on the same v alidation set V al using the three loss functions ℓ C E , ℓ C , and ℓ P oly − 1 and the accuracy a as v alidation criteria. This pro cedure was designed to disentangle the effect of the training ob jective from that of the mo del selection criterion; accordingly , w e adopted a fully crossed exp erimental design. Precisely , at each training ep och we compute, on the v alidation set, the adopted losses and the classification accuracy , regardless of the loss used for optimization on the training data. Model selection is then p erformed independently for each v alidation criterion by iden tifying the ep o c h that optimizes the corresp onding quan tity . This pro cedure yields, for ev ery training loss, multiple candidate mo dels selected according to different quan tity of v alidation p erformance. By ev aluating all selected mo dels on the same held-out test set, w e can quan tify how different v alidation criteria induce differen t orderings ov er the same set of candidate mo dels, and ho w these orderings translate into test p erformance. Moreo ver, ov er all the ep ochs for each training run, early stopping is sim ulated indep enden tly for each v alidation loss. In the case of loss-based criteria, generalization 12 is considered to ha ve impro ved whenever the v alidation loss decreases; for accuracy- based early stopping, impro vemen t corresponds to an increase in v alidation accuracy W e consider three configurations: p ost-ho c chec kp oin t selection (i.e. no early stopping), corresp onding to selecting the b est ep och across all training iterations (or until near- p erfect fitting of the training data is achiev ed); early stopping with patience T = 10; and a more conserv ative patience of T = 50 ep o c hs. F or each configuration and each v alidation criterion, the mo del selected by early stopping is iden tified as the c heck- p oin t corresp onding to the b est v alidation p erformance observed T ep o c hs b efore the stopping condition is met. The test accuracy of the selected chec kp oint is then com- pared against the test-optimal accuracy A ⋆ T est , defined as the maximum test accuracy attained ov er the entire training tra jectory . This comparison allows us to quantify the exten t to which standard early-stopping practices appro ximate or fail to recov er the test-optimal mo del. 5 Results and discussion In the follo wing, w e report the exp erimen tal results. F or eac h experimental setting, datasets are ordered by increasing linear separability , as measured by the generalized discrimination v alue (GD V), to highlight ho w model selection b eha vior v aries with dataset complexity . Results obtained using cross-entrop y as training ob jective and early stopping with T = 10 are shown in Figure 4 . When cross-en tropy is used as the v alidation criterion, the null h yp othesis is not rejected in 5 . 98 % of the ev aluated configurations, indicating scenarios in whic h the difference betw een the test accuracy ac hieved by v alidation- based mo del selection and the test-optimal accuracy is not statistically significan t. In these cases, models selected based on the v alidation set exhibit test p erformance that is statistically indistinguishable from the test-optimal one. A similar b eha vior is observed when alternativ e loss functions are adopted as v alidation criteria. Sp ecifically , when C-Loss and PolyLoss are used as v alidation criteria, the null h yp othesis is not rejected in the 5 . 34 % and 5 . 98 % of the cases, resp ectiv ely , leading to comparable conclusions. In contrast, a differen t behavior is observ ed when v alidation accuracy is used as the selection criterion. In this case, the null hypothesis is not rejected in the 0 . 43 % of the ev aluated configurations, indicating that accuracy-based v alidation is substan tially less lik ely to select mo dels whose test p erformance is statistically indistinguishable from the test-optimal accuracy . This result suggests that, despite b eing the final ev aluation metric, v alidation accuracy may constitute a less reliable criterion for mo del selection than loss-based alternatives. Figure 5 shows the same setup, but using early stopping with T = 50. When cross- en tropy is used as the v alidation criterion, the null h yp othesis is not rejected in 4 . 91 % of the ev aluated configurations. Using C-Loss as v alidation criterion, this prop ortion increases to 6 . 20 %. With Poly-1, the null hypothesis is not rejected in 5 . 58 % of the configurations. When accuracy is used as the v alidation criterion, the n ull hypothesis is not rejected in 0 . 43 % of the ev aluated configurations. These results confirm that, ev en with a larger early stopping patience, loss-based v alidation criteria provide a 13 Fig. 4 : Graphical represen tation of the h yp othesis testing results obtained using cross- en tropy as the training ob jective and early stopping with patience T = 10. Each heatmap rep orts the p-v alues obtained from hypothesis tests comparing the test accu- racy of mo dels selected using the v alidation set against the test-optimal accuracy A ⋆ T est across cross-v alidation folds. F rom left to right, panels corresp ond to v alidation based on cross-entrop y loss, C-Loss, Poly-1, and v alidation accuracy , resp ectiv ely . Rows rep- resen t datasets and columns corresp ond to differen t parameter-to-sample ratios r . Datasets are ordered from top to b ottom according to increasing linear separability , estimated using the generalized discrimination v alue (GDV). more reliable basis for mo del selection than v alidation accuracy to reach test-optimal accuracy . Figure 6 shows the results without the application of early stopping. When cross- en tropy is adopted as the v alidation criterion, the n ull hypothesis is not rejected in 5 . 56 % of the ev aluated configurations. A comparable b eha vior is observ ed also using the other loss functions as v alidation criterion: using C-Loss, this prop ortion increases to 6 . 84 %, while using the Poly-1, the null hypothesis is not rejected in 6 . 41 % of the cases. Also in this case, when accuracy is used as the v alidation criterion, the n ull hypothesis is not rejected with a lo wer proportion, i.e., 2 . 56 % of the ev aluated configurations. Results obtained using C-Loss and Poly-1 as training ob jectives lead to similar conclusions; detailed statistical analyses and corresp onding figures are rep orted in App endix A. A summary of the p ercen tages of n ull hypothesis acceptance across all training ob jectives, v alidation criteria, and early stopping configurations is reported in T able 2 . Across all training ob jectiv es and early stopping settings, loss-based v alidation criteria consisten tly yield higher prop ortions of configurations in which v alidation-selected 14 Fig. 5 : Graphical represen tation of the h yp othesis testing results obtained using cross- en tropy as the training ob jective and early stopping with patience T = 50. Each heatmap rep orts the p-v alues obtained from hypothesis tests comparing the test accu- racy of mo dels selected using the v alidation set against the test-optimal accuracy A ⋆ T est across cross-v alidation folds. F rom left to right, panels corresp ond to v alidation based on cross-entrop y loss, C-Loss, Poly-1, and v alidation accuracy , resp ectiv ely . Rows rep- resen t datasets and columns corresp ond to differen t parameter-to-sample ratios r . Datasets are ordered from top to b ottom according to increasing linear separability , estimated using the generalized discrimination v alue (GDV). T able 2 : P ercentages of null hypothesis acceptance under differen t v alidation criteria and early stopping strategies, for each training ob jective. The acceptance of the n ull hypothe- sis corresp onds to cases in whic h the v alidation-selected mo del achiev es test performance statistically indistinguishable from the test-optimal mo del. T raining Ob jectiv e Early Stopping Cross-En tropy C-Loss P olyLoss Accuracy Cross-Entrop y T = 10 5 . 98 % 5 . 34 % 5 . 98 % 0 . 43 % T = 50 4 . 91 % 6 . 20 % 5 . 58 % 0 . 43 % Disabled 5 . 56 % 6 . 84 % 6 . 41 % 2 . 56 % C-Loss T = 10 17 . 74 % 19 . 44 % 18 . 38 % 11 . 11 % T = 50 17 . 95 % 19 . 02 % 18 . 38 % 11 . 54 % Disabled 19 . 23 % 21 . 15 % 18 . 59 % 13 . 25 % Poly-1 T = 10 5 . 77 % 6 . 62 % 6 . 20 % 0 . 64 % T = 50 5 . 56 % 5 . 98 % 5 . 77 % 0 . 64 % Disabled 5 . 56 % 6 . 41 % 5 . 98 % 1 . 71 % 15 Fig. 6 : Graphical represen tation of the h yp othesis testing results obtained using cross- en tropy as the training ob jective, without early stopping. Each heatmap rep orts the p-v alues obtained from h yp othesis tests comparing the test accuracy of mo dels selected using the v alidation set against the test-optimal accuracy A ⋆ T est across cross-v alidation folds. F rom left to right, panels correspond to v alidation based on cross-entrop y loss, C-Loss, P oly-1, and v alidation accuracy , resp ectively . Ro ws represent datasets and columns correspond to differen t parameter-to-sample ratios r . Datasets are ordered from top to b ottom according to increasing linear separabilit y , estimated using the generalized discrimination v alue (GDV). mo dels achiev e test performance that is statistically indistinguishable from the test- optimal accuracy . In contrast, v alidation accuracy systematically exhibits the low est acceptance rates in all considered scenarios. Across all training ob jectiv es, different loss-based v alidation criteria exhibit closely aligned acceptance rates, indicating that the b enefit arises from loss-based model selection p er se, rather than from a sp ecific choice of loss function. As a practical con- sequence, this suggests that, among loss-based criteria, simpler and computationally less exp ensiv e losses, such as cross-entrop y , may b e preferred for v alidation without compromising mo del selection effectiv eness. Consistently with this observ ation, despite b eing the final ev aluation metric, v alidation accuracy prov es to b e a weak er signal for mo del selection compared to loss-based alternatives. The observ ed trends are consistent across all considered training ob jectives, indi- cating that the superiority of loss-based v alidation criteria do es not rely on a sp ecific alignmen t betw een training and v alidation losses. Finally , training with C-Loss is asso ciated with higher acceptance rates across v alidation criteria, suggesting a p otentially stronger alignmen t b etw een v alidation- based selection and test-optimal p erformance. How ever, even in this case, the higher 16 acceptance rate remains largely indep enden t of the v alidation loss used for mo del selection. F rom a practical persp ectiv e, these results suggest that monitoring v alidation loss, rather than v alidation accuracy , constitutes a more reliable strategy for mo del selection when the ob jective is to approach test-optimal accuracy . Fig. 7 : Acceptance rate of the null h yp othesis with α = 0 . 05 as a function of the parameter-to-sample ratio r , under differen t training ob jectives, early stopping strate- gies, and v alidation criteria. Rows corresp ond to the training ob jectiv e (cross-entrop y , C-Loss, and Poly-1), while columns rep ort results obtained using early stopping with T = 10, T = 50, and with early stopping disabled. Bars represent different v alida- tion criteria: cross-en trop y , C-Loss, P olyLoss, and v alidation accuracy . The acceptance rate indicates the prop ortion of configurations in which the test accuracy of the mo del selected via v alidation is statistically indistinguishable from the test-optimal accuracy . Figure 7 rep orts the acceptance rate of the n ull hypothesis with resp ect to the parameter-to-sample ratio r , under different training ob jectiv es (rows), early stop- ping strategies (columns), and v alidation criteria (bars). Across all training ob jectives and early stopping configurations, the acceptance rates remain remark ably stable as r v aries ov er several orders of magnitude, ranging from strongly under-parameterized to highly ov er-parameterized regimes. No systematic trend can b e observed as a func- tion of r , suggesting that the abilit y of v alidation-based model selection to identify 17 mo dels whose test accuracy is statistically indistinguishable from the test-optimal one is insensitive to the degree of mo del parameterization. This b eha vior is consistent across all v alidation criteria and early stopping strate- gies. In particular, the relativ e ordering b et ween loss-based v alidation criteria and v alidation accuracy is preserved for all v alues of r , with loss-based criteria consis- ten tly ac hieving higher acceptance rates than accuracy-based v alidation. This suggests that the superiority of loss-based v alidation do es not arise from a sp ecific regime of parameterization, but rather reflects a more general prop ert y of the v alidation signal itself. Ov erall, these results indicate that the observed adv antages of loss-based mo del selection are robust across under-parameterized, critically parameterized, and o ver- parameterized regimes. Consequen tly , the effectiv eness of loss-based v alidation criteria in aligning v alidation-based mo del selection with test-optimal p erformance do es not dep end on fine-tuning the parameter-to-sample ratio, but p ersists across a wide range of mo del capacities. Figure 8 rep orts the acceptance rate of the n ull hypothesis with resp ect to the significance level α . Results are shown for different training ob jectives (ro ws), early stopping strategies (columns), and v alidation criteria (curv es). Across all configura- tions, the acceptance rate exhibits a monotonic increase as α decreases, as exp ected from the behavior of hypothesis testing pro cedures. In terestingly , a consisten t and pronounced separation emerges b et ween loss-based v alidation criteria (dashed lines) and v alidation accuracy (solid). F or all training ob jectiv es and early stopping settings, v alidation based on loss functions yields substantially higher acceptance rates than v alidation accuracy ov er the entire range of significance levels considered. This indi- cates that loss-based criteria are systematically more lik ely to select models whose test p erformance is statistically indistinguishable from the test-optimal one. The three loss-based v alidation criteria exhibit closely aligned trends, with only marginal quantitativ e differences across all v alues of α . This observ ation suggests that the adv an tage of loss-based v alidation does not stem from a particular c hoice of loss function, which is still coheren t to what was observ ed before. In contrast, v alidation accuracy , despite b eing the final ev aluation metric, confirms to provide a weak er and less reliable signal for selecting mo dels that generalize optimally to the test set, as evidenced by its consisten tly lo wer acceptance rates. Finally , differences across training ob jectiv es are also observ able. In particular, training with C-Loss is asso ciated with higher acceptance rates across all v alidation criteria, suggesting a stronger alignmen t betw een v alidation-based mo del selection and test-optimal p erformance. Nonetheless, the relative adv antage of loss-based v alidation o ver accuracy-based selection p ersists uniformly across all training ob jectiv es, reinforc- ing the conclusion that monitoring v alidation loss constitutes a more reliable strategy for model selection than v alidation accuracy when the goal is to approac h test-optimal accuracy . 18 Fig. 8 : Acceptance rate of the n ull h yp othesis as a function of the significance level α , under differen t training ob jectives, early stopping strategies, and v alidation crite- ria. The acceptance rate indicates the prop ortion of configurations in which the test accuracy of the mo del selected via v alidation is statistically indistinguishable from the test-optimal accuracy . Ro ws corresp ond to the training ob jective (cross-entrop y , C-Loss, and Poly-1), while columns rep ort results obtained using early stopping with T = 10, T = 50, and with early stopping disabled. Curv es represent different v alida- tion criteria: loss-based criteria (cross-en tropy , C-Loss, and Poly-1, dashed lines) and v alidation accuracy (solid lines). 6 Conclusions This study examined how different v alidation criteria lead model selection when the deplo yment ob jective is test accuracy . Across datasets, generalization regimes, and early-stopping settings, accuracy , despite b eing the main classification task metric, underp erform as a selection criterion. Indeed, loss-based v alidation (cross-entrop y , C- Loss, P olyLoss) selects chec kp oin ts whose test accuracy is more often statistically close to the test-optimal mo del than those chosen by v alidation accuracy . The gap persists whether early stopping is used with moderate or large patience, or disabled in fa vor of p ost-hoc c heckpoint selection. 19 This can b e due to the fact that accuracy is a discrete, thresholded indicator with lo w sensitivity to incremen tal improv emen ts. It changes only when predictions flip around the decision b oundary , so it pro duces long plateaus and frequent ties across ep ochs—especially on small v alidation sets—making early-stopping triggers noisy and unstable. Moreo ver, accuracy ignores confidence: tw o chec kp oints with equal accu- racy can differ substantially in margins. These finite-sample effects are amplified by patience-based rules, where small random oscillations can halt training early on a merely lo cal optim um. In short, accuracy is excellen t for final rep orting, but it seems a p oor compass to v alidate ov er an iterativ e training pro cess. Con versely , using the adopted v alidation loss leads to higher acceptance rates in our hypothesis tests than v alidation accuracy , regardless of the training loss. The adv antage is robust to stopping regime (early vs. post-ho c) and persists across datasets and mo del sizes. The specific loss used for v alidation matters less than being loss-based. In fact, cross-entrop y , C-Loss, and PolyLoss used on the v alidation set deliver closely aligned acceptance rates. Practically , this means one can prefer the simpler, cheaper cross-en tropy for v alidation without sacrificing selection quality . Finally , acceptance rates show no systematic dep endence from under- to ov er-parameterized. It is also worth noting that, across v alidation criteria, the absolute proportion of accepted null hypothesis remains modest. Indeed, in most cases, v alidation-selected mo dels do not achiev e test performance that is statistically indistinguishable from the test-optimal chec kp oin t. This might suggests that v alidation-based selection alone ma y b e insufficient and motiv ates further inv estigation into alternative analytical and metho dological approaches. This study in tentionally fo cused on accuracy-cen tred ev aluation under standard sup ervised proto cols. Extending the analysis to other endp oin ts (e.g., F1, MCC, PR- A UC), settings with pronounced class imbalance, or larger-scale regimes would clarify when accuracy-based v alidation narro ws the gap. It would also b e v aluable to study v alidation-set size explicitly , and to assess whether combining a loss-based selector with light weigh t p ost-selection threshold tuning further closes the distance to the test-optimal mo del. In conclusion, what we monitor matters. When mo del selection dep ends on a v al- idation tra jectory , esp ecially under early stopping, loss-based criteria provide a more reliable estimate of generalization and, in turn, more dep endable accuracy on unseen data. Ac kno wledgmen t This work was partially funded by the PNRR MUR pro ject PE0000013-F AIR (CUP: E63C25000630006). F unding 20 References [1] Go odfellow, I., Bengio, Y., Courville, A.: Deep Learning. MIT Press, ??? (2016) [2] Bishop, C.M.: Regularization and complexit y con trol in feed-forward net works (1995) [3] Huang, C., Zhai, S., T alb ott, W., Martin, M.B., Sun, S.-Y., Guestrin, C., Susskind, J.: Addressing the loss-metric mismatch with adaptive loss alignment. In: In ternational Conference on Mac hine Learning, pp. 2891–2900 (2019). PMLR [4] Singh, A., P okharel, R., Princip e, J.: The c-loss function for pattern classification. P attern Recognition 47 (1), 441–453 (2014) [5] Leng, Z., T an, M., Liu, C., Cubuk, E.D., Shi, J., Cheng, S., Anguelov, D.: P olyloss: A p olynomial expansion p ersp ectiv e of classification loss functions. In: In ternational Conference on Learning Represen tations (2022) [6] Hagiwara, K.: Regularization learning, early stopping and biased estimator. Neuro computing 48 (1-4), 937–955 (2002) [7] Evgeniou, T., Poggio, T., Pon til, M., V erri, A.: Regularization and statistical learning theory for data analysis. Computational Statistics & Data Analysis 38 (4), 421–432 (2002) [8] Adv ani, M.S., Saxe, A.M., Sompolinsky , H.: High-dimensional dynamics of generalization error in neural netw orks. Neural Netw orks 132 , 428–446 (2020) [9] Asuncion, A., Newman, D., et al.: UCI machine learning rep ository . Irvine, CA, USA (2007) [10] T erv en, J., Cordo v a-Esparza, D.-M., Romero-Gonz´ alez, J.-A., Ram ´ ırez-P edraza, A., Ch´ av ez-Urbiola, E.: A comprehensiv e surv ey of loss functions and metrics in deep learning. Artificial In telligence Review 58 (7), 195 (2025) [11] Santamar ´ ıa, I., Pokharel, P .P ., Princip e, J.C.: Generalized correlation function: definition, properties, and application to blind equalization. IEEE T ransactions on Signal Pro cessing 54 (6), 2187–2197 (2006) [12] Singh, A., Princip e, J.C.: A loss function for classification based on a robust similarit y metric. In: The 2010 In ternational Join t Conference on Neural Netw orks (IJCNN), pp. 1–6 (2010). IEEE [13] W ang, X.-N., W ei, J.-M., Jin, H., Y u, G., Zhang, H.-W.: Probabilistic confusion en tropy for ev aluating classifiers. Entrop y 15 (11), 4969–4992 (2013) [14] Marchetti, F., Guastavino, S., Piana, M., Campi, C.: Score-oriented loss (sol) functions. Pattern Recognition 132 , 108913 (2022) 21 [15] Marchetti, F., Guastavino, S., Campi, C., Benv enuto, F., Piana, M.: A compre- hensiv e theoretical framework for the optimization of neural net works classifica- tion p erformance with resp ect to weigh ted metrics. Optimization Letters 19 (1), 169–192 (2025) [16] Caruana, R., La wrence, S., Giles, C.: Ov erfitting in neural nets: Bac kpropagation, conjugate gradient, and early stopping. Adv ances in neural information pro cessing systems 13 (2000) [17] Ji, Z., Li, J., T elgarsky , M.: Early-stopped neural net works are consisten t. Adv ances in Neural Information Pro cessing Systems 34 , 1805–1817 (2021) [18] Soudry , D., Carmon, Y.: No bad lo cal minima: Data indep enden t training error guarantees for multila yer neural netw orks. arXiv preprint (2016) [19] Swirszcz, G., Czarnecki, W.M., Pascan u, R.: Lo cal minima in training of neural net works. arXiv preprint arXiv:1611.06310 (2016) [20] Go odfellow, I.J., Viny als, O., Saxe, A.M.: Qualitatively characterizing neural net work optimization problems. arXiv preprin t arXiv:1412.6544 (2014) [21] Zhang, J., Ma, C., Liu, J., Shi, G.: Penetrating the influence of regularizations on neural net work based on information bottleneck theory . Neurocomputing 393 , 76–82 (2020) [22] Baldi, P ., Chauvin, Y.: T emp oral ev olution of generalization during learning in linear netw orks. Neural Computation 3 (4), 589–603 (1991) [23] W ang, C., V enk atesh, S., Judd, J.: Optimal stopping and effectiv e machine complexit y in learning. Adv ances in neural information pro cessing systems 6 (1993) [24] Do dier, R.: Geometry of early stopping in linear net works. Adv ances in neural information pro cessing systems 8 (1995) [25] B ¨ uhlmann, P ., Y u, B.: Bo osting with the l 2 loss: regression and classification. Journal of the American Statistical Asso ciation 98 (462), 324–339 (2003) [26] Barron, A.R., Cohen, A., Dahmen, W., DeV ore, R.A.: Appro ximation and learning by greedy algorithms (2008) [27] Chen, H., Li, L., Pan, Z.: Learning rates of m ulti-kernel regression by orthogonal greedy algorithm. Journal of Statistical Planning and Inference 143 (2), 276–282 (2013) [28] W ei, Y., Y ang, F., W ainwrigh t, M.J.: Early stopping for kernel b oosting algo- rithms: A general analysis with localized complexities. Adv ances in Neural 22 Information Pro cessing Systems 30 (2017) [29] Bandos, T.V., Camps-V alls, G., Soria-Oliv as, E.: Statistical criteria for early- stopping of supp ort vector machines. Neuro computing 70 (13-15), 2588–2592 (2007) [30] F erro, M.V., Mosquera, Y.D., Pena, F.J.R., Bilbao, V.M.D.: Early stopping b y correlating online indicators in neural net works. Neural Net works 159 , 109–124 (2023) [31] Ennett, C.M., F rize, M., Scales, N.: Ev aluation of the logarithmic-sensitivit y index as a neural net work stopping criterion for rare outcomes. In: 4th In ternational IEEE EMBS Special T opic Conference on Information T echnology Applications in Biomedicine, 2003., pp. 207–210 (2003). IEEE [32] Lalis, J., Gerardo, B., Byun, Y.: An adaptive stopping criterion for backpropaga- tion learning in feedforward neural netw ork. International Journal of Multimedia and Ubiquitous Engineering 9 (8), 149–156 (2014) [33] W u, X.-x., Liu, J.-g.: A new early stopping algorithm for improving neural net work generalization. In: 2009 Second In ternational Conference on Intelligen t Computation T ec hnology and Automation, vol. 1, pp. 15–18 (2009). IEEE [34] Natara jan, S., Rhinehart, R.R.: Automated stopping criteria for neural netw ork training. In: Pro ceedings of the 1997 American Control Conference (Cat. No. 97CH36041), vol. 4, pp. 2409–2413 (1997). IEEE [35] Iyer, M.S., Rhinehart, R.R.: A nov el metho d to stop neural netw ork training. In: Pro ceedings of the 2000 American Control Conference. A CC (IEEE Cat. No. 00CH36334), vol. 2, pp. 929–933 (2000). IEEE [36] Apicella, A., Isgr` o, F., Prevete, R.: Don’t push the button! exploring data leak- age risks in machine learning and transfer learning. Artificial Intelligence Review 58 (11), 339 (2025) [37] Prechelt, L.: Early stopping-but when? In: Neural Netw orks: T ricks of the T rade, pp. 55–69. Springer, ??? (2002) [38] Lo dwic h, A., Rangoni, Y., Breuel, T.: Ev aluation of robustness and p erformance of early stopping rules with multi lay er p erceptrons. In: 2009 International Joint Conference on Neural Net works, pp. 1877–1884 (2009). IEEE [39] Nguyen, M.H., Abbass, H.A., McKay , R.I.: Stopping criteria for ensemble of ev olutionary artificial neural netw orks. Applied Soft Computing 6 (1), 100–107 (2005) [40] Suliman, A., Omarov, B.: Early stopping criteria for leven b erg-marquardt based 23 neural netw ork training optimization. In ternational Journal of Engineering and T echnology (uae) 7 (4.36), 1194–1198 (2018) [41] Shao, Y., T aff, G.N., W alsh, S.J.: Comparison of early stopping criteria for neural- net work-based subpixel classification. IEEE Geoscience and Remote Sensing Letters 8 (1), 113–117 (2010) [42] V era, M., Rey V ega, L., Piantanida, P .: Pacman: P ac-style bounds accounting for the mismatch betw een accuracy and negative log-loss. Information and Inference: A Journal of the IMA 13 (1), 002 (2024) [43] Liao, Q., Miranda, B., Banburski, A., Hidary , J., P oggio, T.: A surprising lin- ear relationship predicts test p erformance in deep netw orks. arXiv preprint arXiv:1807.09659 (2018) [44] Schilling, A., Maier, A., Gerum, R., Metzner, C., Krauss, P .: Quantifying the separabilit y of data classes in neural netw orks. Neural Netw orks 139 , 278–293 (2021) https://doi.org/10.1016/j.neunet.2021.03.035 [45] Bishop, C.M., Bishop, H.: Deep Learning: F oundations and Concepts. Springer, ??? (2023) [46] Hastie, T.: The elements of statistical learning: data mining, inference, and prediction. Springer (2009) [47] Apicella, A., Isgr` o, F., Pollastro, A., Prevete, R.: On the effects of data normal- ization for domain adaptation on eeg data. Engineering Applications of Artificial In telligence 123 , 106205 (2023) 24
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment