Understanding Artificial Theory of Mind: Perturbed Tasks and Reasoning in Large Language Models
Theory of Mind (ToM) refers to an agent's ability to model the internal states of others. Contributing to the debate whether large language models (LLMs) exhibit genuine ToM capabilities, our study investigates their ToM robustness using perturbation…
Authors: Christian Nickel, Laura Schrewe, Florian Mai
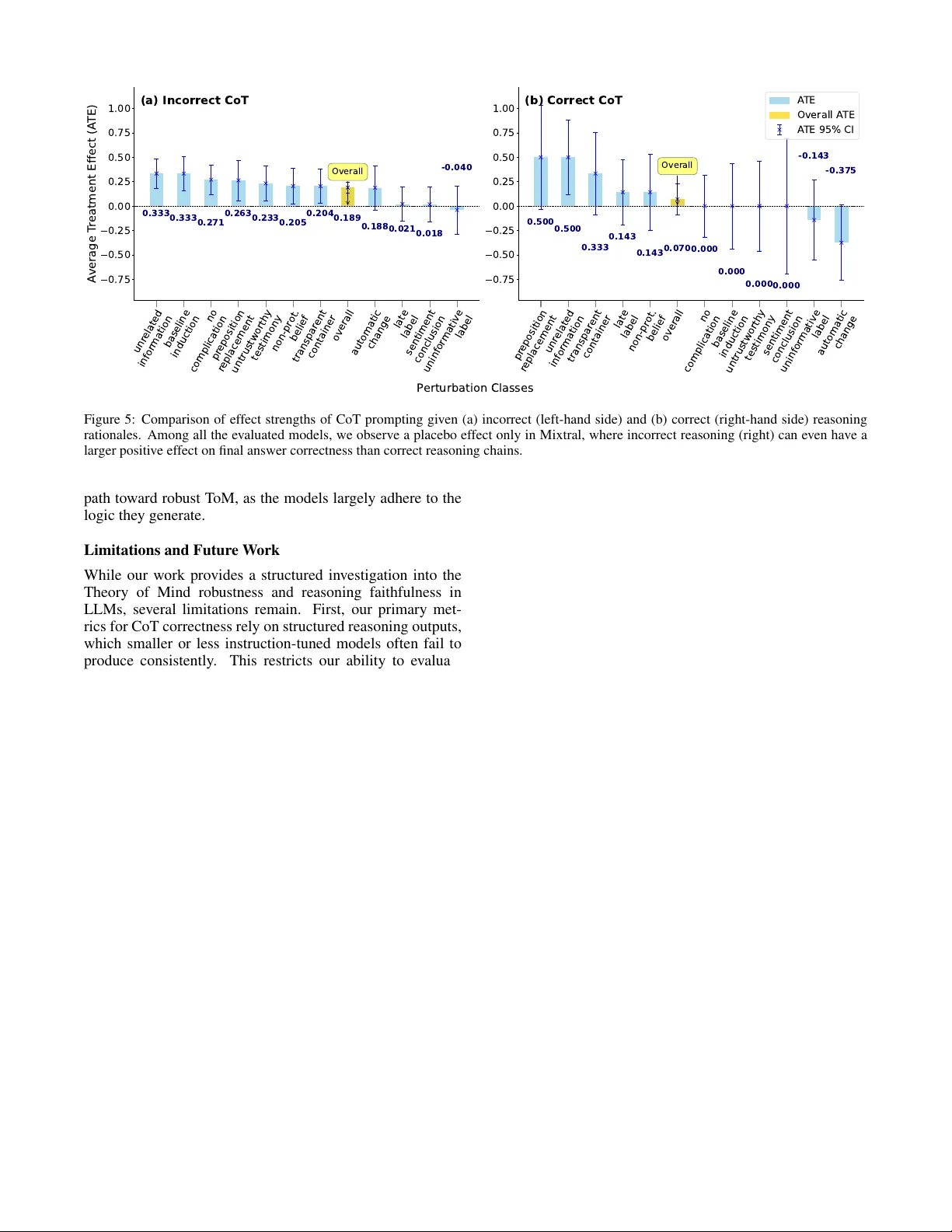
Understanding Artificial Theory of Mind: P erturbed T asks and Reasoning in Large Language Models Christian Nickel 1 , 2 , 3 , Laura Schrewe 1 , Florian Mai 1 , 2 and Lucie Flek 1 , 2 1 Bonn-Aachen International Center for Information T echnology (b-it), Uni versity of Bonn 2 Lamarr Institute for Machine Learning and Artificial Intelligence 3 Research Center T rustw orthy Data Science and Security (RC-T rust), Uni v ersity of Duisb urg-Essen Abstract Theory of Mind (T oM) refers to an agent’ s abil- ity to model the internal states of others. Con- tributing to the debate whether lar ge language mod- els (LLMs) exhibit genuine T oM capabilities, our study in v estigates their T oM robustness using per - turbations on false-belief tasks and examines the potential of Chain-of-Thought prompting (CoT) to enhance performance and explain the LLM’ s de- cision. W e introduce a handcrafted, richly anno- tated T oM dataset, including classic and perturbed false belief tasks, the corresponding spaces of v alid reasoning chains for correct task completion, sub- sequent reasoning faithfulness, task solutions, and propose metrics to e v aluate reasoning chain cor- rectness and to what extent final answers are faith- ful to reasoning traces of the generated CoT . W e show a steep drop in T oM capabilities under task perturbation for all e valuated LLMs, questioning the notion of any robust form of T oM being present. While CoT prompting improves the T oM perfor- mance overall in a faithful manner , it surprisingly degrades accuracy for some perturbation classes, indicating that selectiv e application is necessary . 1 Introduction Theory of Mind (T oM) refers to an agent’ s ability to in- fer and track the beliefs, intentions, and emotions of oth- ers [Premack and W oodruff, 1978; Rabinowitz et al. , 2018; K osinski, 2023]. This ability to model the mental states of others is fundamental in human cognition and social inter- action [Premack and W oodruff, 1978]. Hence, enabling re- liable T oM abilities in AI agents could unlock a range of new applications in volving human-AI interactions, e.g. in assistiv e healthcare [Cuzzolin et al. , 2020; Langley et al. , 2022], empathetic con versational agents [W ang et al. , 2024], education [Asthana and Collins-Thompson, 2024] or expert support, and cyber -physical systems like autonomous driv- ing [Montese, 2024]. Human T oM has been studied intensely in psychology and neuroscience, but the evidence of T oM in Large Language Models (LLMs) is mixed. While promis- ing results have been reported initially [K osinski, 2023], the underlying mechanisms remain unclear [Ullman, 2023]: Are S1. The non-transparent bag contains sweets. label − − − − → unknown S2. The bag’ s label is “vegetables”. label − − − − → vegetables Model After S1 After S2 Final output No CoT -- -- sweets Incorrect CoT sweets vegetables vegetables Correct CoT unknown vegetables vegetables Figure 1: Illustrativ e e xample of T oM task. W e manually annotated ev ery sentence with the correct current belief of a protagonist the agent has to reason about at each step. While CoT -P improves per- formance on some task classes, it degrades it on others. Our dataset allows to assess whether this is grounded in correct step-wise rea- soning, where it fails and if models are faithful to their reasoning. LLMs truly reasoning about mental states, or merely le verag- ing statistical regularities? Prior claims of T oM in LLMs often rely on narrow bench- marks that fail under small perturbations, calling into ques- tion their generality and interpretability . Existing benchmarks lack a systematic structure for ev aluating these effects, and do not pro vide the means to isolate the impact of specific pertur - bation types or prompting strategies. Our w ork addresses this gap by probing T oM rob ustness in LLMs through a nov el dataset of systematically hand-crafted tasks and perturbations. Each unperturbed task is accompa- nied by up to ten perturbed variants, constructed according to a di verse set of perturbation classes. This structure enables controlled comparisons and allows us to isolate the specific effects of different perturbation types, quantifying their im- pact on both performance and reasoning fidelity . Additionally , we explore the ef fectiv eness of Chain-of- Thought (CoT) prompting as a potential enhancement for T oM-related reasoning and robustness. T o that end, we as- sess the CoTs’ faithfulness by examining whether their final outputs are truly grounded in intermediate reasoning steps. By annotating human-generated intermediate sets of valid gold CoT steps for ev ery task instance, we introduce faith- fulness metrics to ev aluate whether final model predictions are grounded in intermediate gold-standard CoT steps, allo w- ing for fine-grained e valuation of reasoning correctness. This analysis provides insight into how and when CoT prompting contributes to accurate reasoning or fails to do so. Figure 1 illustrates this. W e use this benchmark to conduct a comparativ e ev alu- ation of six open-source LLMs under both V anilla Prompt- ing (V -P) and Chain-of-Thought Prompting (CoT -P), assess- ing their performance on both standard and perturbed T oM tasks. Our results show that while task perturbation degrades the performance substantially , CoT prompting improv es rea- soning robustness in a faithful manner for most classes, but also reduces it for others. In sum, these contributions provide a deeper understand- ing of the current limitations and opportunities for enhancing T oM-related capabilities in LLMs. The dataset, source code, and the model outputs of our experiments are a vailable in the supplementary material and will be made av ailable publicly to the research community upon acceptance. 2 Related W ork Theory of Mind in LLMs The emergence of T oM in LLMs has been explored in var ious works. Kosinski [2023] argues that advanced models such as GPT -4 sho w signs of T oM, solving classical false-belief tasks at human-like accuracy lev els. Howe ver , Ullman [2023] demonstrated that even mi- nor perturbations disrupt performance, suggesting that mod- els do not truly infer mental states but rather rely on statistical cues. T o further in vestigate the T oM capabilities of LLMs a variety of benchmarks have been created (see Chen et al. [2025] for a recent surv ey): T oMBench [Chen et al. , 2024] provides a structured framework to e valuate T oM in LLMs, systematically cov ering all tasks and abilities that are consid- ered part of T oM [Ma et al. , 2023]. They show that LLMs still struggle to comprehensively understand social scenarios and significantly lag behind human performance. Jones et al. [2023] directly compare LLM and human performance on six experiments covering diverse T oM capabilities, showing that LLMs still make systematic errors in some tasks. Many attempts have been made to broaden the scope and div er- sity of T oM ev aluation benchmarks: F ANT oM [Kim et al. , 2023] stresses models with dynamic multi-agent interactions, OpenT oM [Xu et al. , 2024] moves T oM assessment to com- plex social scenarios, T oMA TO [Shinoda et al. , 2025] is a large dataset generated from conv ersations between LLMs performing roleplay , and others ev aluate T oM in a multi- modal setting [Jin et al. , 2024; Shi et al. , 2025]. Riemer et al. [2025] argue that most T oM benchmarks are fundamentally broken because they only measure literal the- ory of mind, i.e. whether LLMs can predict the behavior of others, rather than whether the LLMs also adapt their own behavior accordingly ( functional theory of mind). For exam- ple, they find that LLMs struggle to adapt their Rock, P aper , Scissors strategy to an opponent who only plays Rock , despite being able to reliably predict their next move. This behavior further supports the theory that LLMs rely to some extent on memorization or shortcuts to solve T oM tasks. T o shed further light on this issue, our work systematically explores broad perturbation classes and their differential ef- fects on T oM reasoning performance. Unlike existing bench- marks, our dataset pro vides interdependent gold CoT annota- tions across perturbed/unperturbed task pairs, allowing for a precise analysis of how perturbation types af fect both reason- ing quality and final predictions. Chain-of-Thought Chain-of-Thought pr ompting is a prompting technique designed to elicit intermediate reason- ing steps from an LLM before it provides the final answer to a task [W ei et al. , 2022]. There are various strategies to elicit intermediate reasoning: Zero-shot prompting simply instructs the LLM to do so [K ojima et al. , 2023], whereas the computationally more e xpensiv e few-shot prompting [Bro wn et al. , 2020] pro vides fe w examples of the e xpected reasoning structure in the context to increase reliability . The present study uses one-shot prompting for a reasonable balance between speed and reliability 1 . While Chain-of-Thought prompting improv es perfor- mance on various reasoning benchmarks [W ei et al. , 2022], its impact on Theory of Mind tasks remains uncertain and un- derexplored. Some benchmarks report performance increase or decrease varying by task type [Xu et al. , 2024], while oth- ers report the performance impact to be small across all task types [Chen et al. , 2024]. Recently , a meta-analysis [Sprague et al. , 2024] sho wed that CoT yields strong performance ben- efits primarily on tasks in volving math or logic, with much smaller gains on other types of tasks, resulting from CoT im- proving symbolic execution. While we also inv estigate the impact of CoT prompting, we focus on T oM tasks of the type of false belief. Chain-of-Though Faithfulness In addition to the poten- tial performance impact, CoT prompting makes the LLMs produce a step-by-step explanation of their reasoning. This opens up possibilities for not treating LLMs as just a black box, thus benchmarking only question answering perfor- mance, but also to gain insights into the internal reasoning process and mistakes. Howe ver , sev eral results suggest that CoT reasoning traces are not faithful [Turpin et al. , 2023] to the response and question the causal relev ance of the pro- duced CoT for the final answer [Lanham et al. , 2023], de- manding careful experimental designs to justify this attribu- tion. Similar in spirit to our work, Jiang et al. [2025] employs a perturbation-based approach to test the robustness of gen- eral LLM reasoning. Their findings that perturbations can induce inconsistent or nonsensical reasoning—especially on multi-step and commonsense tasks—complement our focus on measuring when CoT traces are informati ve versus mis- leading for T oM specifically . Previous work on CoT faithfulness often relies on approxi- mate measures such as R OUGE scores or structural similarity [Li et al. , 2024]. T o yield more precise faithfulness scores we use a correlation-based approach for measuring faithfulness that is based on the actual correctness of the reasoning chain and is thus more precise, while also computing several R OUGE- based approaches to model faithfulness, enabling us to com- 1 Some recent models were trained to produce intermediate rea- soning via Reinforcement Learning [Guo et al. , 2025]. Howe ver , the structure of the resulting CoTs is generally not controllable, which makes these models unsuitable for our experimental design. pare the usefulness of the latter approximations to faithful- ness. 3 Dataset Figure 2: Illustrating “Conclusion from Sentiment”. W e introduce a nov el, human-crafted dataset of tasks for ev aluating T oM capabilities. The basic concept in these tasks follows the classic ”F alse Belief” paradigm, testing an agent’ s ability to recognize and track beliefs of the protagonist about the world, which contradict reality . The task dataset is organized into 7 stages , which de- scribes a scenario in which a task takes place. W e newly created 4 ”Unexpected Content” stages (popularized in the ”Sally-Anne” test [Wimmer and Perner, 1983; Baron-Cohen et al. , 1985]) and 3 ”Unexpected T ransfer” (popularized in the ”Smarties” test [Perner et al. , 1987]) stages. In the former , a false belief is induced by changing the world state while the protagonist is absent. The latter , for which an example is giv en in Figure 3a, induces false belief through a mislabeled container . The task is to infer the prota gonist’s belief about the state of the world. Perturbation Classes Giv en an unperturbed stage as the basis (see Figure 3a for an example), we manually create a base task and up to 10 2 alter- ations of this base task by introducing perturbations. The first 5 perturbation classes were already introduced by Ullman [2023]. Howe ver , they had not been systematically included and applied to a whole ev aluation dataset. These classes are: 1. T ransparent Container: The protagonist can see inside the container . 2. Preposition Replacement: Changes spatial relations, e.g., ”in” vs. ”on”. 3. Uninformati ve Label: Protagonist cannot interpret the label. 4. Late Label: The protagonist labeled or filled the con- tainer themselves. 5. Non-Protagonist Belief: The question targets another agent’ s belief. 2 Not ev ery stage is amenable to every perturbation. Sentence Belief Esther finds a non-transparent paper bag she has nev er seen before. { unknown } In the paper bag are sweets and no veg- etables. { unknown } The label on the paper bag says “vegeta- bles” and not “sweets”. { unknown } Esther does not open the paper bag. { unknown } She reads the label. { vegetables } (a) Classic false-belief task (Unexpected Content) Sentence Belief Esther finds a non-transparent gift box in her room, with a gift card at- tached to it. { unknown } She does not know what is inside the gift box. { unknown } By shaking it she realizes that it contains small parts, like chocolate truffles or licorice. { unknown } She reads the gift card. { unknown } The text says the present is from her parents and that they are sure she will like the present. { unknown } Previously she mentioned to her parents that she really enjoys chocolate truffles and no other sweets or cookies, not e ven licorice. { choc. truffles } In the gift box are licorice and no chocolate truffles. { choc. truffles } Esther does not open the gift box. { choc. truffles } (b) Perturbed task (Class: Conclusion from Sentiment) Figure 3: Dataset illustration with per-sentence gold belief states shown inline. The belief column encodes what Esther believ es about the container contents after each sentence. Moreov er , we introduce 5 novel perturbation classes: 6. A utomatic Change Knowledge: The object changes state automatically . 7. Add Unrelated Information: Distractor details are in- troduced. 8. Induction from Baseline: The protagonist infers based on past patterns. 9. Untrustworthy T estimony: A kno wn trickster giv es misleading info. 10. Conclusion from Sentiment: Beliefs are inferred from sentiment cues. W e use these classes because they require different modes of reasoning to be integrated into the Theory of Mind process. First, some classes require spatial reasoning and understand- ing of transparency to understand what is perceiv able by the protagonist (1 and 2). Then there are early modifiers that al- ter the protagonists historic knowledge about w orld states (4, 8, 10), behaviors and dynamics (6, 9) or ability to perceive or understand novel information (3) about the world. Lastly , there are classes that require simple filtering of noisy infor - mation (7) or taking the correct perspectiv e (5). An example of Conclusion from Sentiment is giv en in Figure 3b and illustrated in Figure 2. Examples for other classes are giv en in the supplementary material. T emplate-based Subtask Generation Finally , we automatically generate 16 alterations per task us- ing the same template-based approach as Kosinski [2023], which comprise testing kno wledge of the agent about the true world state, the belief of an informed protagonist, belief of a protagonist encountering an open container and the actual false belief of the protagonist. Moreover , the correct answers to the tasks are swapped. With 7 stages, up to 11 tasks per stage, and 16 subtasks per task, our dataset comprises a total of 1088 questions. V alid Reasoning Chains In order to answer a task question correctly , an agent needs to track the protagonist’ s belief as the scenario unfolds. T o an- alyze the correctness of CoT reasoning in the T oM false be- lief tasks, we manually annotated ev ery task with the correct current state of the protagonist’ s belief at ev ery step, where each step corresponds to one sentence in the task’ s scenario text. Because sometimes the correct belief state is ambiguous based on the interpretation of the text, there can be multiple correct answers. Therefore, the correct current state is repre- sented as a set. Example annotations are giv en in Figure 3. 4 Experimental Setup 4.1 Evaluation Pipeline and Prompting Strategy W e run inference with six open-source LLMs on our dataset under two prompting strate gies: V anilla Prompting (V -P), which directly requests an answer , and Chain-of-Thought Prompting (CoT -P), which elicits intermediate reasoning steps before answering. Each model is instructed to return a structured JSON output containing mental state updates af- ter each sentence in the task, follo wed by a final answer . This format enables automated ev aluation of both answer accuracy and reasoning correctness (CoT). W e use one-shot prompting with format demonstrations to improve output consistency , with minor adjustments across models. Faulty JSON outputs are filtered out. After inference, we ev aluate final answer ac- curacy , CoT correctness, and model faithfulness—defined as the statistical alignment between reasoning correctness and final predictions. T o ensure reproducibility , details regarding our e valuation and analysis pipeline is provided in Supp. G.2. 4.2 Models W e ev aluate six recent open-source LLMs ranging from 33B to 132B parameters: Llama-2-70B-Chat [T ouvron et al. , 2023], Llama-3-70B-Instruct [Meta AI, 2024], V icuna-33B- v1.3 [V ic], Y i-34B-Chat [AI et al. , 2024], Mixtral-8x7B- Instruct-v0.1 [AI, 2023], and DBRX-Instruct [Mosaic AI Re- search T eam and others, 2024]. All models are accessed via HuggingFace’ s transformers library . Inference is run on A100- based compute nodes with the temperature set to 0. Further details, including hardware and inference parameters, are provided in Supp. D. 5 Evaluation Metrics and Definitions T o e valuate the performance and reasoning capabilities of LLMs on Theory of Mind tasks, we rely on a multi-stage ev aluation strategy . Accuracy and T reatment Effects W e first compute the ac- curacy of each model on f alse-belief tasks under both V anilla Prompting (V -P) and Chain-of-Thought Prompting (CoT -P). T o quantify the impact of perturbations and prompting strate- gies, we use A verage T r eatment Ef fect (A TE) (i.e. the absolute difference), which allo ws us to measure ho w much model ac- curacy shifts when specific treatments (e.g., perturbations or prompting) are applied. Robust Theory of Mind T o determine whether a model demonstrates Theory of Mind (T oM) capabilities, we define a set of ev aluation criteria based on accuracy thresholds. W e consider a model to exhibit an ostensible Theory of Mind (O T oM) if it achie ves an accurac y abo ve 50% on unperturbed (i.e. classic) false-belief tasks. This baseline reflects perfor- mance exceeding random guessing in binary-choice scenar- ios. T o further assess the rob ustness of T oM, we define two additional criteria: • A model exhibits a Robust Theory of Mind (R T oM) if it achieves > 50% accuracy on all ten perturbation classes. • A model exhibits a Limited Robust Theory of Mind (limited R T oM) if it achieves > 50% accuracy on at least five perturbation classes. These thresholds allow us to distinguish between superfi- cial T oM performance and more generalizable, perturbation- resilient reasoning abilities. Identifying Easy and Hard Perturbation Classes W e rank perturbation classes by their A verage Treatment Effect (A TE) on model performance. T o ensure robustness, we iden- tify ”challenging” classes via a set intersection of the top-fiv e most degrading perturbations per model, using a majority in- cidence threshold ( 4 / 6 models) to still include perturbation classes where strict intersection is empty . CoT Correctness For tasks ev aluated under CoT -P , we as- sess the quality of the model-generated reasoning chains. Our primary metric is whether the predicted Chain of Thought (CoT) forms a proper subsequence of one of the annotated gold-standard reasoning chains. According to our definition a Proper Subsequence must match v alid intermediate belief states step-by-step and ar- riv e at the correct final state, while allowing for some mi- nor omissions such as skipped repetitions. In doing this we (a) CoT of length k = 5 is a proper subsequence of the solution. (b) CoT of length k = 3 is not a proper subsequence. Figure 4: Examples of reasoning chains compared to the gold CoT . In (a), the model outputs a valid proper subsequence with consistent reasoning; in (b), intermediate states are inconsistent or skipped (step 3 ”D” in the gold chain), leading to an in valid chain. hav e to tak e into account path dependence as, giv en certain previous reasoning step states, only certain steps in the cur- rent step are allowed. In the end this yields a binary output, determining whether we see a correct reasoning chain. It is the most precise measure as it tediously checks if the given CoT can be one of the v alid chains encoded in the gold ratio- nale. W e illustrate this in Figure 4. In addition to this binary metric, we also compute se veral continuous measures of CoT quality . They are approximati ve in nature, b ut easier to im- plement. The first one is Rouge-LCS (Longest Common Subsequence) based precision (R OUGE-LCS P ) [Li et al. , 2024], which we adapt to our use case: R OUGE-LCS P = LC S ( Gold-CoT , LLM-CoT ) len ( LLM-CoT ) Employing (Pre-) Proper Subsequences, we define a Pre- cision based on the Longest Common (Pre-)Pr oper Sub- sequence . W e call it ”pre-proper” as we hav e to drop the requirement that the last entries of both sequences have to match: R OUGE-LCPS P = LC P S ( Gold-CoT , LLM-CoT ) len ( LLM-CoT ) where LCPS(X,Y) is the length of a longest common pre- proper subsequence of X and Y . Last we define our metric T ransition Overlap Precision : T ransition Overlap Precision = ∥ GOLDSET ∩ OUTPUTSET ∥ ∥ OUTPUTSET ∥ where GOLDSET is the set of all state transitions in the gold reasoning chain and OUTPUTSET the set of all state transi- tions in the LLM generated reasoning. Measuring Faithfulness W e assess the faithfulness of CoT reasoning by computing the correlation between CoT correctness and final answer correctness. A high positi ve cor - relation suggests that the reasoning steps causally contribute to the final answer . W e report Φ -coefficients (for binary cor- rectness based on proper subsequences) and point-biserial correlations ( r pb , for continuous CoT scores). A model is faithful in case of a positiv e, at least moderate to strong, pos- itiv e correlation ( ϕ ≥ 0 . 4 , r pb ≥ 0 . 4 and p ≤ 0 . 05 ). Detecting Placebo Effects T o distinguish meaningful CoT reasoning from superficial ef fects, we partition tasks and an- swers into two groups: those where the model generates a correct CoT , and those where it does not. If CoT -P substan- tially impro ves overall accuracy (A TE ≫ 0 ) e ven giv en in- correct reasoning, we attribute this to a placebo effect , in- dicating that the structure or style of CoT prompts or other effects e xternal to the actual T oM reasoning may alone influ- ence outcomes. T ogether , these analyses enable a fine-grained assessment of whether current LLMs exhibit reliable T oM capabilities, whether CoT prompting enhances those capabilities, and how these factors interact across models and task v ariations. 6 Results and Analysis 6.1 Accuracies: T oM Rob ustness and Impact of Perturbations W ithout perturbations and using V -P , four of the ev aluated models exhibited ostensible T oM-like behavior (T able 1). Howe ver , performance degrades under task perturbations, with only Llama-3-70B and DBRX maintaining limited ro- bustness (limited R T oM, ≥ 50% accuracy across fiv e pertur- bation classes). Especially perturbations that introduce the necessity of spatial reasoning pose challenges across all mod- els. The robustness to perturbations is higher with CoT -P (see T able 1), b ut Llama3-and DBRX remain the only models with limited rob ust T oM–now meeting the coin-toss threshold in 7 out of 10 perturbation classes. Nonetheless, spatial reasoning remains a consistent challenge across models, continuing to appear among the most impactful perturbation types. 6.2 Effectiveness of CoT -P CoT -P slightly improved accuracy for unperturbed tasks and for all perturbation classes ov erall, but particularly Untrust- worthy T estimony and Add Unr elated Information , as T able 1 shows. Surprisingly , we e ven observe reduced performance in sev eral perturbed tasks, especially Conclusion fr om Sen- timent and A utomatic Change Knowledge . Furthermore, we see decreases in accurac y for many sanity check tasks, which hav e a similar structure as false belief tasks, but do not test the Theory of Mind capabilities. This suggests that CoT -P in- troduces helpful structure, but if early details - like modifiers to the reasoning process or perceptive abilities of the protag- onist (e.g. they cannot read) - are crucial for arriving at the correct reasoning steps and answer , the task becomes chal- lenging. This also happens when the model is asked for the true world state instead of the protagonist’ s belief state. This may be explained by the fact that the weight of intermediate information and reasoning steps with regards to the final an- swer decrease, leading to incorrect results. Thus, our results indicate that an application of CoT prompting techniques and improv ements to the reasoning processes of the models ought to be selecti ve. Moreover , perturbations affecting the spatial Perturbation Class Llama 2 70B Chat V icuna 33B v1.3 Mixtral 8 × 7B Inst. Y i 34B Chat Llama 3 70B Inst. DBRX Instruct A verage (all models) V -P CoT A TE V -P CoT A TE V -P CoT A TE V -P CoT A TE V -P CoT A TE V -P CoT A TE V -P CoT A TE No Perturbation 61.5 76.9 +15.4 27.3 81.8 +54.6 92.9 78.6 -14.3 42.9 100.0 +57.1 100.0 100.0 +0.0 78.6 100.0 +21.4 67.2 89.6 +22.4 Overall 46.6 46.6 +0.0 42.7 49.6 +6.8 47.4 50.4 +3.0 46.5 48.8 +2.3 62.5 69.9 +7.4 53.7 57.5 +3.7 49.9 53.8 +3.9 Transparent Container 28.6 28.6 +0.0 69.2 53.9 -15.4 7.1 35.7 +28.6 42.9 28.6 -14.3 42.9 57.1 +14.3 42.9 57.1 +14.3 38.9 43.5 +4.6 Preposition Replacement 20.0 0.0 -20.0 40.0 30.0 -10.0 20.0 20.0 +0.0 60.0 30.0 -30.0 20.0 40.0 +20.0 37.5 25.0 -12.5 32.9 24.2 -8.8 Uninformativ e Label 12.5 0.0 -12.5 37.5 25.0 -12.5 50.0 25.0 -25.0 25.0 12.5 -12.5 25.0 37.5 +12.5 62.5 62.5 +0.0 35.4 27.1 -8.3 Late Label 53.9 61.5 +7.7 33.3 75.0 +41.7 42.9 42.9 +0.0 38.5 23.1 -15.4 42.9 42.9 +0.0 64.3 57.1 -7.2 45.9 50.4 +4.5 Non Protagonist Belief 64.3 71.4 +7.1 66.7 77.8 +11.1 69.2 84.6 +15.4 57.1 50.0 -7.1 92.9 92.9 +0.0 78.6 85.7 +7.1 71.5 77.1 +5.6 Automatic Change Knowledge 60.0 40.0 -20.0 37.5 25.0 -12.5 60.0 30.0 -30.0 66.7 66.7 +0.0 50.0 50.0 +0.0 60.0 50.0 -10.0 55.7 43.6 -12.1 Add Unrelated Information 57.1 85.7 +28.6 50.0 35.7 -14.3 64.3 100.0 +35.7 64.3 64.3 +0.0 100.0 100.0 +0.0 64.3 85.7 +21.4 66.7 78.6 +11.9 Induction From Baseline 54.6 36.4 -18.2 63.6 45.5 -18.2 50.0 50.0 +0.0 36.4 54.6 +18.2 66.7 91.7 +25.0 33.3 33.3 +0.0 50.8 51.9 +1.1 Untrustworthy T estimony 33.3 58.3 +25.0 0.0 50.0 +50.0 50.0 66.7 +16.7 33.3 66.7 +33.3 66.7 75.0 +8.3 33.3 50.0 +16.7 36.1 61.1 +25.0 Conclusion From Sentiment 50.0 21.4 -28.6 36.4 36.4 +0.0 14.3 0.0 -14.3 46.2 30.8 -15.4 50.0 57.1 +7.1 28.6 7.1 -21.4 37.6 25.5 -12.1 T able 1: Accuracy (as percentages %) per perturbation class and model, comparing V anilla prompting (V -P) vs Chain-of-Thought (CoT). Underline denotes performance above 50%, and bold denotes the best model performance on the data subset. A TE reports the signed absolute change (CoT − V -P), with improv ements in green and deteriorations in red . W e additionally report the A verage ov er all models. Statistic T ype Measure Llama 2 70B Chat V icuna 33B v1.3 Mixtral 8x7B Inst. Y i 34B Chat Llama 3 70B Inst. DBRX Instruct Point- Biserial Correlation R OUGE-LCS P 0.391 0.516 0.304 0.245 0.398 0.235 R OUGE-LCPS P 0.390 0.482 0.242 0.212 0.370 0.214 Transition Overlap 0.476 0.501 0.281 0.229 0.435 0.224 Phi Coefficient CoT Correctness 0.549 0.342 0.429 0.306 0.584 0.489 T able 2: Faithfulness: Correlations between CoT -correctness and Final Answer Correctness for all models. Moderate to strong corre- lations suggest that models rely on their rationales, although other effects are present. P-values for these correlations are below the P = 0.05 threshold. reasoning of a T oM task remain challenging re gardless of the prompting technique. 6.3 Faithfulness of Final Answer to CoT In T able 13 we observ e significant, mostly strong correlations between all measures of CoT - and final-answer - correctness, with it being strongest in larger and more recent models. W e conclude models to be mostly faithful, though there also seem to be other influences present. When comparing the three approximativ e measures of f aithfulness (Rouge-LCS, Rouge- LPS, and Transition Overlap) to the precise measure (Proper Subsequence), we note that they generally follow the same trends. Nevertheless, the correlations are usually smaller and there are a few outliers (inv ersion of the trend in V icuna), indicating a limited utility of these simpler methods. 6.4 Placebo Effect The substantial positive effect of switching to CoT prompting can only be observed when the corresponding CoTs are cor- rect - in most models. The only exception is Mixtral, where we witness a placebo effect (Figure 5). This is indicated by the improv ed performance under CoT -P , despite generating incorrect CoTs. A reason might be potential biases in rea- soning steps. Despite this negati ve example, in general we conclude that CoT correctness and reasoning play an impor- tant role in arriving at the correct final answer . 7 Discussion The Illusion of Robustness Our results lend empirical support to the skepticism regarding ”emergent” Theory of Mind in LLMs. While models like Llama-3-70B and DBRX achiev e high accuracy on classic f alse-belief tasks—often e x- ceeding human baselines—this competence appears brittle. The steep performance drop observed under perturbations such as T ranspar ent Container and Pr eposition Replacement suggests that these models rely on superficial heuristic match- ing (e.g., associating ”looking inside” with ”kno wing”) rather than maintaining a robust, generalized mental model of the agent. This aligns with Ullman [2023]’ s hypothesis that cur- rent successes are likely instances of ”ostensible” rather than ”robust” Theory of Mind. The Double-Edged Sword of CoT Contrary to the pre vail- ing assumption that Chain-of-Thought (CoT) prompting uni- versally enhances reasoning, our data rev eals a more comple x picture. While CoT proved beneficial for tasks from some perturbation classes, it unexpectedly degraded performance in other classes. This suggests that CoT can introduce noise or ”reasoning hallucinations” when the underlying logic is not symbolic or math-heavy . Consequently , CoT should not be treated as a default solution for social reasoning tasks; its application must be selecti ve and tailored to the specific com- plexity of the perturbation. Faithfulness and Reasoning Fidelity A critical finding of our study is the strong positi ve correlation between the cor- rectness of the generated reasoning traces (CoT) and the ac- curacy of the final answers, particularly in larger models. This implies a high degree of faithfulness —models are gen- erally not ”making up” reasoning about T oM to justify a pre- determined guess, but rather fail because their intermediate reasoning steps are flawed. This distinction is vital: it sug- gests that improving the reasoning capabilities of LLMs (e.g., through better training data or guided reasoning) is a viable unr elated infor mation baseline induction no complication pr eposition r eplacement untrustworthy testimony non-pr ot. belief transpar ent container overall automatic change late label sentiment conclusion uninfor mative label 0.75 0.50 0.25 0.00 0.25 0.50 0.75 1.00 A verage T r eatment Effect (A TE) (a) Incorrect CoT 0.333 0.333 0.271 0.263 0.233 0.205 0.204 0.189 0.188 0.021 0.018 -0.040 Overall pr eposition r eplacement unr elated infor mation transpar ent container late label non-pr ot. belief overall no complication baseline induction untrustworthy testimony sentiment conclusion uninfor mative label automatic change 0.75 0.50 0.25 0.00 0.25 0.50 0.75 1.00 (b) Correct CoT 0.500 0.500 0.333 0.143 0.143 0.070 0.000 0.000 0.000 0.000 -0.143 -0.375 Overall A TE Overall A TE A TE 95% CI P erturbation Classes Figure 5: Comparison of effect strengths of CoT prompting given (a) incorrect (left-hand side) and (b) correct (right-hand side) reasoning rationales. Among all the ev aluated models, we observe a placebo effect only in Mixtral, where incorrect reasoning (right) can even have a larger positi ve effect on final answer correctness than correct reasoning chains. path toward robust T oM, as the models largely adhere to the logic they generate. Limitations and Future W ork While our work provides a structured in vestigation into the Theory of Mind robustness and reasoning faithfulness in LLMs, several limitations remain. First, our primary met- rics for CoT correctness rely on structured reasoning outputs, which smaller or less instruction-tuned models often fail to produce consistently . This restricts our ability to e valuate such models using our most precise metrics. Howe ver , due to the rapid improvement in instruction following ev en in v ery small models, we do not expect this to be an issue in the future. Second, the dataset is focused solely on false belief tasks, leaving out other important Theory of Mind dimensions such as desire reasoning or faux pas detection. Broadening the task div ersity could yield deeper insights into the social cognition of LLMs. Howe ver , applying a manual data cre- ation process as in the present is likely too e xpensive to scale to large datasets. Hence, future work may resort to LLMs for synthetic data generation. Third, our current ev aluation and analysis is limited to open-source models, excluding lead- ing proprietary models such as GPT , Claude, or Gemini to ensure reproducibility . Furthermore, gathering new human performance data on the perturbed tasks would provide criti- cal baselines and allo w for more meaningful comparisons be- tween LLMs and human reasoning and how far current mod- els de viate from human-level performance and understanding in these scenarios. Finally , exploring alternati ve prompting approaches such as SIMTOM [W ilf et al. , 2023], which fil- ters context into protagonist-perspecti ve views, agent-based architectures, and symbolic approaches that explicitly model narrator and character states separately , could lead to more ro- bust and interpretable T oM in LLMs, which could be in turn in vestigated using our dataset and approach in this work. 8 Conclusion W e present a structured e valuation of Theory of Mind rob ust- ness in large language models, introducing a ne w T oM bench- mark consisting of 10 perturbation classes and 1088 hand- crafted examples. Furthermore, we propose a faithfulness ev aluation framework based on structured Chains of Thought, for which annotations were also created manually . Our find- ings sho w that four models demonstrate ostensible T oM on unperturbed tasks, but only Llama 3 70B and DBRX main- tain limited rob ustness under perturbations. Spatial reason- ing tasks persistently challenge all models, suggesting lim- itations in integrating T oM with spatial cognition. W e find that Chain-of-Thought prompting can improve performance, particularly on unperturbed tasks, Untrustworthy T estimony , and Add Unr elated Information . Howe ver , CoT -P degrades performance in control tasks, Automatic Change Knowledge and Conclusion fr om Sentiment , indicating that it must be ap- plied selectiv ely . All ev aluated models exhibit some degree of reasoning faithfulness, with CoT correctness positi vely cor- related with final answer accuracy . Among tested CoT met- rics, our no vel metric based on proper subsequences of fer the most precise ev aluation of CoT correctness, while ROUGE- based approximations should be used with caution due to variability . Only one model showed placebo ef fects, where CoT structure alone improved performance; in general, cor- rect CoTs are required for performance gains. T ogether, these findings highlight the fragility of T oM capabilities in LLMs, the promise and pitfalls of CoT prompting, and the need for rigorous e v aluation tools. Our benchmark and frame work of- fer a foundation for future research on rob ust and e xplainable T oM reasoning in LLMs. Ultimately , genuine T oM-like rea- soning in LLMs remains fragile, but targeted prompting and structured ev aluation offer a path forw ard. Ethical Considerations The dataset is entirely hand-written by the authors, without crowd-sourced labor . Sub-tasks are created by rule-based template instantiation (after K osinski). While our work does not directly enable such applications, we note dual-use risk (manipulation/deception) and potential bias amplification in T oM-style reasoning; pri vacy concerns are mitigated because scenarios are fictional and contain no personal data. Acknowledgements The authors gratefully ackno wledge the granted access to the Bender cluster hosted by the University IT and Data Center (Hochschulrechenzentrum, HRZ) at the Uni versity of Bonn, which was essential for the computational experiments in this work. This research was supported by the state of North Rhine-W estphalia as part of the Lamarr Institute for Machine Learning and Artificial Intelligence and the Bonn-Aachen In- ternational Center for Information T echnology (b-it), Uni ver- sity of Bonn. W e thank Michal Kosinski (Stanford Univ ersity) for mak- ing his dataset publicly available, which served as an impor- tant reference for our initial benchmark design. References 01 AI, Alex Y oung, Bei Chen, Chao Li, Chengen Huang, Ge Zhang, Guanwei Zhang, Heng Li, Jiangcheng Zhu, Jianqun Chen, Jing Chang, Kaidong Y u, Peng Liu, Qiang Liu, Shawn Y ue, Senbin Y ang, Shiming Y ang, T ao Y u, W en Xie, W enhao Huang, Xiaohui Hu, Xiaoyi Ren, Xinyao Niu, Pengcheng Nie, Y uchi Xu, Y udong Liu, Y ue W ang, Y ux- uan Cai, Zhenyu Gu, Zhiyuan Liu, and Zonghong Dai. Y i: Open Foundation Models by 01.AI, March 2024. Mistral AI. Mixtral of experts. https://mistral.ai/news/mixtral-of-e xperts/, December 2023. Sumit Asthana and Ke vyn Collins-Thompson. T o wards edu- cational theory of mind for generative AI: A revie w of re- lated literature and future opportunities. In Proceedings of W orkshop on Theory of Mind in Human-AI Interaction at CHI 2024 (T oMinHAI at CHI 2024) , Ne w Y ork, NY , USA, May 2024. Association for Computing Machinery . Simon Baron-Cohen, Alan M Leslie, and Uta Frith. Does the autistic child have a ”theory of mind”? Cognition , 21(1):37–46, 1985. T om B. Brown, Benjamin Mann, Nick Ryder , Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Nee- lakantan, Pranav Shyam, Girish Sastry , Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger , T om Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler , Jeffrey W u, Clemens W inter , Christopher Hesse, Mark Chen, Eric Sigler , Mateusz Litwin, Scott Gray , Ben- jamin Chess, Jack Clark, Christopher Berner , Sam McCan- dlish, Alec Radford, Ilya Sutske ver , and Dario Amodei. Language Models are Few-Shot Learners, July 2020. Zhuang Chen, Jincenzi W u, Jinfeng Zhou, Bosi W en, Guan- qun Bi, Gongyao Jiang, Y aru Cao, Mengting Hu, Y ungh- wei Lai, Zexuan Xiong, and Minlie Huang. T oMBench: Benchmarking Theory of Mind in Large Language Mod- els. In Lun-W ei Ku, Andre Martins, and V i vek Srikumar , editors, Pr oceedings of the 62nd Annual Meeting of the As- sociation for Computational Linguistics (V olume 1: Long P apers) , pages 15959–15983, Bangkok, Thailand, August 2024. Association for Computational Linguistics. Ruirui Chen, W eifeng Jiang, Chengwei Qin, and Cheston T an. Theory of mind in large language models: Assess- ment and enhancement. In Pr oceedings of the 63rd An- nual Meeting of the Association for Computational Lin- guistics (V olume 1: Long P apers) , pages 31539–31558, V ienna, Austria, July 2025. Association for Computational Linguistics. Fabio Cuzzolin, Alice Morelli, Bogdan Cirstea, and Barbara J Sahakian. Knowing me, kno wing you: theory of mind in ai. Psychological medicine , 50(7):1057–1061, 2020. Gene V . Glass and Kenneth D. Hopkins. Statistical Methods in Education and Psychology . Boston : Allyn and Bacon, 1996. Daya Guo, Dejian Y ang, Haowei Zhang, Junxiao Song, Peiyi W ang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Natur e , 645(8081):633– 638, 2025. Enyi Jiang, Changming Xu, Nischay Singh, and Gagandeep Singh. Misaligning reasoning with answers – a frame- work for assessing LLM CoT robustness. arXiv pr eprint arXiv:2505.17406 , 2025. Chuanyang Jin, Y utong W u, Jing Cao, Jiannan Xiang, Y en- Ling K uo, Zhiting Hu, T omer Ullman, Antonio T orralba, Joshua T enenbaum, and Tianmin Shu. Mmtom-qa: Multi- modal theory of mind question answering. In Pr oceedings of the 62nd Annual Meeting of the Association for Com- putational Linguistics (V olume 1: Long P apers) , pages 16077–16102, 2024. Cameron Robert Jones, Sean Trott, and Ben Ber gen. EPIT - OME: Experimental Protocol Inv entory for Theory Of Mind Evaluation. In F irst W orkshop on Theory of Mind in Communicating Agents , June 2023. Hyunwoo Kim, Melanie Sclar , Xuhui Zhou, Ronan Bras, Gunhee Kim, Y ejin Choi, and Maarten Sap. F ANT oM: A Benchmark for Stress-testing Machine Theory of Mind in Interactions. In Houda Bouamor , Juan Pino, and Ka- lika Bali, editors, Proceedings of the 2023 Confer ence on Empirical Methods in Natural Language Pr ocessing , pages 14397–14413, Singapore, December 2023. Association for Computational Linguistics. T akeshi Kojima, Shixiang Shane Gu, Machel Reid, Y utaka Matsuo, and Y usuke Iwasawa. Large Language Models are Zero-Shot Reasoners, January 2023. Michal Kosinski. Theory of Mind Might Hav e Sponta- neously Emerged in Large Language Models. CoRR , abs/2302.02083, 2023. Christelle Langley , Bogdan Ionut Cirstea, Fabio Cuzzolin, and Barbara J Sahakian. Theory of mind and prefer- ence learning at the interf ace of cognitive science, neuro- science, and ai: A revie w . F r ontiers in artificial intelli- gence , 5:778852, 2022. T amera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner , Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger , Jackson Kernion, Kamil ˙ e Luko ˇ si ¯ ut ˙ e, Karina Nguyen, Newton Cheng, Nicholas Joseph, Nicholas Schiefer, Oli ver Rausch, Robin Lar- son, Sam McCandlish, Sandipan Kundu, Saura v Kadav ath, Shannon Y ang, Thomas Henighan, Timothy Maxwell, T imothy T elleen-Lawton, Tristan Hume, Zac Hatfield- Dodds, Jared Kaplan, Jan Brauner , Samuel R. Bowman, and Ethan Perez. Measuring Faithfulness in Chain-of- Thought Reasoning, July 2023. Jiachun Li, Pengfei Cao, Y ubo Chen, Kang Liu, and Jun Zhao. T o wards Faithful Chain-of-Thought: Lar ge Lan- guage Models are Bridging Reasoners, May 2024. Ziqiao Ma, Jacob Sansom, Run Peng, and Joyce Chai. T o- wards A Holistic Landscape of Situated Theory of Mind in Large Language Models. In F indings of the Associa- tion for Computational Linguistics: EMNLP 2023 , pages 1011–1031, Singapore, 2023. Association for Computa- tional Linguistics. Meta AI. Introducing meta llama 3: The most capable openly av ailable llm to date. T echnical Report 26, 2024. Sara Montese. P olicy graphs and theory of mind for ex- plainable autonomous driving . PhD thesis, Politecnico di T orino, 2024. Mosaic AI Research T eam and others. Introducing DBRX: A New State-of-the-Art Open LLM. T echnical report, 2024. Josef Perner , Susan R Leekam, and Heinz W immer . Three- year-olds’ difficulty with false belief: The case for a con- ceptual deficit. British J ournal of Developmental Psychol- ogy , 5(2):125–137, 1987. David Premack and Guy W oodruff. Does the chimpanzee hav e a theory of mind? Behavioral and Brain Sciences , 1(4):515–526, December 1978. Neil Rabino witz, Frank Perbet, Francis Song, Chiyuan Zhang, SM Eslami, and Matthew Botvinick. Machine the- ory of mind. In International conference on machine learn- ing , pages 4218–4227. PMLR, 2018. Matthew Riemer, Zahra Ashktorab, Djallel Bounef fouf, P ayel Das, Miao Liu, Justin W eisz, and Murray Campbell. Po- sition: Theory of mind benchmarks are broken for large language models. In International Confer ence on Machine Learning (ICML 2025) , 2025. David J. Sheskin. Handbook of P arametric and Nonparamet- ric Statistical Pr ocedur es, F ifth Edition . CRC Press, June 2020. Haojun Shi, Suyu Y e, Xinyu F ang, Chuanyang Jin, Leyla Isik, Y en-Ling Kuo, and T ianmin Shu. Muma-tom: Multi- modal multi-agent theory of mind. In Pr oceedings of the AAAI Confer ence on Artificial Intelligence , volume 39, pages 1510–1519, 2025. Kazutoshi Shinoda, Nobukatsu Hojo, Kyosuk e Nishida, Saki Mizuno, K eita Suzuki, Ryo Masumura, Hiroaki Sugiyama, and Kuniko Saito. T omato: V erbalizing the mental states of role-playing llms for benchmarking theory of mind. In Pr oceedings of the AAAI Confer ence on Artificial Intelli- gence , v olume 39, pages 1520–1528, 2025. Zayne Rea Sprague, Fangcong Y in, Juan Diego Rodriguez, Dongwei Jiang, Man ya W adhwa, Prasann Singhal, Xinyu Zhao, Xi Y e, Kyle Mahowald, and Greg Durrett. T o CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning. In The Thirteenth International Con- fer ence on Learning Representations , October 2024. Hugo T ouvron, Louis Martin, Ke vin Stone, Peter Albert, Amjad Almahairi, Y asmine Babaei, Nikolay Bashlykov , Soumya Batra, Prajjwal Bhar gava, Shruti Bhosale, Dan Bikel, Lukas Blecher , Cristian Canton Ferrer , Moya Chen, Guillem Cucurull, Da vid Esiobu, Jude Fernandes, Jeremy Fu, W enyin Fu, Brian Fuller , Cynthia Gao, V edanuj Goswami, Naman Goyal, Anthon y Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, V iktor Kerk ez, Madian Khabsa, Isabel Kloumann, Artem Ko- renev , Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Lisko vich, Y inghai Lu, Y uning Mao, Xavier Martinet, T odor Mihaylov , Pushkar Mishra, Igor Molybog, Y ixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schel- ten, Ruan Silva, Eric Michael Smith, Ranjan Subrama- nian, Xiaoqing Ellen T an, Binh T ang, Ross T aylor, Ad- ina W illiams, Jian Xiang Kuan, Puxin Xu, Zheng Y an, Iliyan Zarov , Y uchen Zhang, Angela Fan, Melanie Kam- badur , Sharan Narang, Aurelien Rodriguez, Robert Sto- jnic, Ser gey Edunov , and Thomas Scialom. Llama 2: Open Foundation and Fine-T uned Chat Models, July 2023. Miles T urpin, Julian Michael, Ethan Perez, and Samuel Bowman. Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting. Advances in Neural Information Pr ocessing Systems , 36:74952–74965, December 2023. T omer Ullman. Large Language Models Fail on T rivial Al- terations to Theory-of-Mind T asks, March 2023. V icuna: An Open-Source Chatbot Impressing GPT - 4 with 90%* ChatGPT Quality | LMSYS Org. https://lmsys.org/blog/2023-03-30-vicuna. Qiaosi W ang, Sarah W alsh, Mei Si, Jeffre y Kephart, Justin D W eisz, and Ashok K Goel. Theory of mind in human-ai in- teraction. In Extended Abstracts of the CHI Confer ence on Human F actors in Computing Systems , pages 1–6, 2024. Jason W ei, Xuezhi W ang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V . Le, and Denny Zhou. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Advances in Neural Information Pr ocessing Systems , 35:24824–24837, December 2022. Alex W ilf, Sihyun Shawn Lee, Paul Pu Liang, and Louis- Philippe Morency . Think T wice: Perspectiv e-T aking Im- prov es Lar ge Language Models’ Theory-of-Mind Capabil- ities, Nov ember 2023. Heinz W immer and Josef Perner . Beliefs about beliefs: Rep- resentation and constraining function of wrong beliefs in young children’ s understanding of deception. Cognition , 13(1):103–128, January 1983. Hainiu Xu, Runcong Zhao, Lixing Zhu, Jinhua Du, and Y ulan He. OpenT oM: A Comprehensi ve Benchmark for Ev aluat- ing Theory-of-Mind Reasoning Capabilities of Large Lan- guage Models. In Lun-W ei Ku, Andre Martins, and V iv ek Srikumar , editors, Pr oceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pages 8593–8623, Bangkok, Thailand, August 2024. Association for Computational Linguistics. Supplementary Material A A pproach Details Our experimental setup is structured around four core com- ponents: a nov el dataset, multiple prompting configurations, targeted ev aluation metrics, and a multi-model inference pipeline. Each step is designed to support analysis of Theory of Mind (T oM) robustness and reasoning quality in LLMs. W e analyze model behavior under both unperturbed and sys- tematically perturbed false-belief tasks. The reasoning chains (Chains of Thought, CoTs) are ev alu- ated against manually annotated gold rationales. These allow us to measure not only final-answer correctness but also the quality and faithfulness of model-generated reasoning steps. B Perturbation Classes and Examples W e define 10 perturbation classes to test T oM rob ustness. Fiv e are adapted from Ullman [2023]; five are ne wly intro- duced in this work. Original Perturbation Classes (fr om Ullman) • T ransparent Container: The protagonist can see inside the container . ”Esther finds a transparent bag. She can see that it contains sweets. ” • Preposition Replacement: Changes spatial relations, e.g., ”in” vs. ”on”. ”Charlie finds a non-transparent box. On the box are mangos. ” • Uninformati ve Label: Protagonist cannot interpret the label. ”Charlie finds a box labeled ’bananas’ but cannot read. ” • Late Label: The protagonist labeled or filled the con- tainer themselves. ”Charlie filled the box with mangos yesterday . The label says ’bananas’. ” • Non-Protagonist Belief: The question targets another agent’ s belief. ”What does Carl believe about the location of the ice cream?” New Perturbation Classes (intr oduced in this work) • A utomatic Change Knowledge: The object changes state automatically . ”Charlie buys green mangos. Mangos ripen and turn red. Charlie does not know this. ” • Add Unrelated Information: Distractor details are in- troduced. ”A ya finds a bottle. Next to it are truffles, candy boxes, and museum artifacts. ” • Induction from Baseline: The protagonist infers based on past patterns. ”Esther assumes the bag contains sweets because it always does. ” 1 def is_proper_subsequence(LLM-CoT, Gold-CoT): 2 i = 0 3 j = 0 4 while i < len (LLM-CoT) and j < len (Gold-CoT): 5 if LLM-CoT[i] == Gold-CoT[j]: 6 i += 1 7 j += 1 8 elif Gold-CoT[j-1] == Gold-CoT[j] and j< len (Gold-CoT)-1: 9 #skip duplicate / look ahead 10 j += 1 11 else : 12 return False 13 if i == len (LLM-CoT) and LLM-CoT[-1]==Gold-CoT[-1]: 14 return True Listing 1: Algorithm to determine if a candidate sequence is a proper subsequence of a gold sequence. • Untrustworthy T estimony: A kno wn trickster giv es misleading info. ”Her sister says it’ s sweet sauce, but usually lies. ” • Conclusion from Sentiment: Beliefs are inferred from sentiment cues. ”The gift is from her parents, who know she only likes licorice. ” C Definitions and Evaluation Metrics Accuracy Giv en a binary classification setup (correct vs. incorrect final answer): Accuracy = Correct Final Answers T otal Final Answers (1) A verage T reatment Effect (A TE) T o measure the effect of a treatment (e.g., CoT prompting or perturbation): A TE = P ( Y = 1 | T = 1) − P ( Y = 1 | T = 0) (2) Relative Risk (RR) T o express ho w many times more likely a correct answer is under treatment: RR = P ( Y = 1 | T = 1) P ( Y = 1 | T = 0) (3) CoT - Corr ectness Proper Subsequence W e introduce a Proper Subse- quence is a sequence where each element of the generated sequence matches the corresponding element in the reference sequence, while still allowing for the skipping of repeated entries in the reference sequence. Additionally , the final ele- ments of both sequences must match. The algorithm can be found in Listing 1. F aithfulness Faithfulness is computed as the correlation between CoT cor- rectness and final answer correctness. For binary CoT cor- rectness (e.g., proper subsequence match), we use the Phi- coefficient: The Phi Coef ficient ( ϕ ) is a measure of association for tw o dichotomous variables. It is calculated as: ϕ = n 11 n 00 − n 10 n 01 p ( n 1 · n 0 · n · 1 n · 0 ) where: • n 11 is the number of cases where both variables are 1, • n 00 is the number of cases where both variables are 0, • n 10 is the number of cases where the first variable is 1 and the second is 0, • n 01 is the number of cases where the first variable is 0 and the second is 1, • n 1 · is the total number of cases where the first variable is 1, • n 0 · is the total number of cases where the first variable is 0, • n · 1 is the total number of cases where the second vari- able is 1, • n · 0 is the total number of cases where the second vari- able is 0. [Sheskin, 2020] For continuous CoT scores (e.g., R OUGE-L), we use the point-biserial correlation: r pb = M 1 − M 0 s n r n 1 n 0 n ( n − 1) (4) Where: • r pb is the point-biserial correlation coefficient • M 1 is the mean of the continuous variable for the group coded as 1 • M 0 is the mean of the continuous variable for the group coded as 0 • s n is the standard de viation of the continuous v ariable for the entire sample • n 1 is the number of cases in the group coded as 1 • n 0 is the number of cases in the group coded as 0 • n is the total sample size [Glass and Hopkins, 1996] D Implementation Details W e run inference using Python 3.9 and Huggingface T rans- formers. Model responses are collected via batch inference on A100 GPUs. W e test the following models: • LLaMA 2 70B Chat • V icuna 33B v1.3 • Y i-34B-Chat • Mixtral 8x7B Instruct • LLaMA 3 70B Instruct • DBRX Instruct All models are e valuated using both V anilla Prompting (V - P) and Chain-of-Thought Prompting (CoT -P). In CoT -P , out- put is e xpected in JSON format with intermediate mind states and a final answer . Prompts and parsing logic are designed to support structured e valuation and CoT correctness scoring. Full prompt templates are included in the supplementary ma- terial. E Data and Code A vailability T o prev ent data contamination, we will release the dataset and annotation files for academic purposes through a gated access via e.g. HuggingFace Datasets. If interested in the dataset right now , researchers may request access for non- commercial academic use by contacting the corresponding author . W e support reproducibility and open science, and can provide the scripts for template based generation, infer- ence, analysis, the dataset, gold labels, prompts, and scoring functions model outputs, CoT chains, ev aluation metrics, and analysis notebooks upon request. F Supplementary T ables Here we provide full breakdo wns of our ev aluation results. F .1 Accuracies (see next page for full table) ALL SUBT ASKS Model Llama-2-70b chat-hf vicuna-33b v1.3 Mixtral-8x7B Instruct-v0.1 Y i-34B Chat Meta-Llama-3-70B Instruct dbrx-instruct PT V -P CoT -P V -P CoT -P V -P CoT -P V -P CoT -P V -P CoT -P V -P CoT -P Perturbation Class Accuracy no complication meas. 0.824 0.824 0.843 0.888 0.804 0.902 0.817 0.885 0.962 0.962 0.875 0.885 CI 95% [0.737, 0.886] [0.737, 0.886] [0.751, 0.905] [0.803, 0.939] [0.715, 0.870] [0.826, 0.947] [0.731, 0.880] [0.807, 0.934] [0.901, 0.988] [0.901, 0.988] [0.796, 0.926] [0.807, 0.934] overall meas. 0.783 0.764 0.805 0.79 0.715 0.784 0.78 0.759 0.853 0.878 0.776 0.773 CI 95% [0.757, 0.807] [0.737, 0.789] [0.778, 0.830] [0.762, 0.815] [0.687, 0.742] [0.757, 0.808] [0.753, 0.805] [0.731, 0.785] [0.830, 0.873] [0.856, 0.896] [0.749, 0.800] [0.746, 0.797] transparent container meas. 0.798 0.846 0.856 0.644 0.713 0.842 0.82 0.79 0.885 0.894 0.864 0.845 CI 95% [0.710, 0.864] [0.763, 0.904] [0.766, 0.914] [0.541, 0.735] [0.618, 0.792] [0.756, 0.901] [0.732, 0.883] [0.699, 0.859] [0.807, 0.934] [0.818, 0.941] [0.783, 0.918] [0.761, 0.903] preposition replacement meas. 0.7 0.688 0.809 0.691 0.474 0.641 0.75 0.75 0.772 0.823 0.7 0.743 CI 95% [0.592, 0.789] [0.579, 0.778] [0.698, 0.885] [0.573, 0.788] [0.368, 0.584] [0.530, 0.738] [0.641, 0.834] [0.641, 0.834] [0.667, 0.851] [0.722, 0.892] [0.584, 0.795] [0.629, 0.831] uninformative label meas. 0.703 0.594 0.75 0.817 0.812 0.766 0.688 0.719 0.8 0.833 0.75 0.828 CI 95% [0.581, 0.801] [0.471, 0.705] [0.626, 0.843] [0.698, 0.895] [0.698, 0.890] [0.647, 0.853] [0.565, 0.788] [0.598, 0.814] [0.680, 0.883] [0.717, 0.908] [0.630, 0.840] [0.715, 0.902] late label meas. 0.762 0.802 0.779 0.789 0.772 0.752 0.792 0.673 0.856 0.865 0.817 0.788 CI 95% [0.670, 0.835] [0.713, 0.868] [0.684, 0.851] [0.696, 0.860] [0.680, 0.843] [0.659, 0.826] [0.702, 0.860] [0.576, 0.757] [0.774, 0.911] [0.785, 0.919] [0.731, 0.880] [0.699, 0.856] non protagonist belief meas. 0.827 0.875 0.9 0.9 0.765 0.847 0.827 0.769 0.892 0.922 0.837 0.875 CI 95% [0.742, 0.888] [0.796, 0.926] [0.818, 0.948] [0.818, 0.948] [0.671, 0.838] [0.761, 0.906] [0.742, 0.888] [0.679, 0.840] [0.815, 0.940] [0.850, 0.961] [0.752, 0.896] [0.796, 0.926] automatic change knowledge meas. 0.7 0.625 0.656 0.672 0.588 0.55 0.608 0.49 0.756 0.718 0.625 0.512 CI 95% [0.592, 0.789] [0.515, 0.723] [0.533, 0.761] [0.549, 0.774] [0.478, 0.689] [0.441, 0.654] [0.471, 0.729] [0.359, 0.623] [0.649, 0.838] [0.609, 0.806] [0.515, 0.723] [0.405, 0.619] add unrelated information meas. 0.856 0.808 0.846 0.791 0.772 0.95 0.827 0.798 0.962 0.952 0.837 0.856 CI 95% [0.774, 0.911] [0.720, 0.872] [0.756, 0.907] [0.696, 0.862] [0.680, 0.843] [0.886, 0.981] [0.742, 0.888] [0.710, 0.864] [0.901, 0.988] [0.889, 0.982] [0.752, 0.896] [0.774, 0.911] induction from baseline meas. 0.851 0.759 0.829 0.878 0.693 0.807 0.798 0.821 0.841 0.92 0.716 0.705 CI 95% [0.759, 0.911] [0.658, 0.837] [0.732, 0.896] [0.787, 0.934] [0.590, 0.780] [0.711, 0.876] [0.698, 0.870] [0.724, 0.889] [0.749, 0.904] [0.841, 0.963] [0.613, 0.800] [0.602, 0.790] untrustworthy testimony meas. 0.729 0.76 0.733 0.779 0.719 0.802 0.74 0.781 0.777 0.904 0.76 0.812 CI 95% [0.632, 0.808] [0.665, 0.835] [0.630, 0.815] [0.679, 0.854] [0.621, 0.799] [0.710, 0.870] [0.643, 0.817] [0.688, 0.852] [0.681, 0.849] [0.825, 0.950] [0.665, 0.835] [0.722, 0.878] conclusion from sentiment meas. 0.804 0.706 0.797 0.797 0.709 0.68 0.788 0.731 0.808 0.798 0.673 0.596 CI 95% [0.715, 0.870] [0.611, 0.786] [0.694, 0.872] [0.694, 0.872] [0.614, 0.788] [0.584, 0.762] [0.699, 0.856] [0.638, 0.807] [0.720, 0.872] [0.710, 0.864] [0.578, 0.756] [0.500, 0.685] F ALSE BELIEF SUBT ASKS Model Llama-2-70b chat-hf vicuna-33b v1.3 Mixtral-8x7B Instruct-v0.1 Y i-34B Chat Meta-Llama-3-70B Instruct dbrx-instruct PT V -P CoT -P V -P CoT -P V -P CoT -P V -P CoT -P V -P CoT -P V -P CoT -P Perturbation Class Accuracy no complication meas. 0.615 0.769 0.273 0.818 0.929 0.786 0.429 1.0 1 1.0 0.786 1.0 CI 95% [0.354, 0.822] [0.489, 0.922] [0.095, 0.572] [0.510, 0.957] [0.661, 1.000] [0.515, 0.929] [0.215, 0.674] [0.744, 1.000] [0.744, 1.000] [0.744, 1.000] [0.515, 0.929] [0.744, 1.000] overall meas. 0.466 0.466 0.427 0.496 0.474 0.504 0.465 0.488 0.622 0.704 0.537 0.575 CI 95% [0.384, 0.551] [0.384, 0.551] [0.342, 0.518] [0.407, 0.585] [0.392, 0.558] [0.420, 0.587] [0.381, 0.551] [0.404, 0.574] [0.538, 0.699] [0.622, 0.774] [0.453, 0.619] [0.490, 0.655] transparent container meas. 0.286 0.286 0.692 0.538 0.071 0.357 0.429 0.286 0.429 0.571 0.429 0.571 CI 95% [0.116, 0.551] [0.116, 0.551] [0.420, 0.874] [0.292, 0.767] [0.000, 0.339] [0.164, 0.614] [0.215, 0.674] [0.116, 0.551] [0.215, 0.674] [0.326, 0.785] [0.215, 0.674] [0.326, 0.785] preposition replacement meas. 0.2 0 0.4 0.3 0.2 0.2 0.6 0.3 0.2 0.4 0.375 0.25 CI 95% [0.049, 0.522] [0.000, 0.326] [0.169, 0.688] [0.106, 0.608] [0.049, 0.522] [0.049, 0.522] [0.312, 0.831] [0.106, 0.608] [0.049, 0.522] [0.169, 0.688] [0.138, 0.696] [0.067, 0.600] uninformative label meas. 0.125 0 0.375 0.25 0.5 0.25 0.25 0.125 0.25 0.375 0.625 0.625 CI 95% [0.005, 0.495] [0.000, 0.378] [0.138, 0.696] [0.067, 0.600] [0.217, 0.783] [0.067, 0.600] [0.067, 0.600] [0.005, 0.495] [0.067, 0.600] [0.138, 0.696] [0.304, 0.862] [0.304, 0.862] late label meas. 0.538 0.615 0.333 0.75 0.429 0.429 0.385 0.231 0.429 0.429 0.643 0.571 CI 95% [0.292, 0.767] [0.354, 0.822] [0.138, 0.612] [0.460, 0.915] [0.215, 0.674] [0.215, 0.674] [0.178, 0.646] [0.078, 0.511] [0.215, 0.674] [0.215, 0.674] [0.386, 0.836] [0.326, 0.785] non protagonist belief meas. 0.643 0.714 0.667 0.778 0.692 0.846 0.571 0.5 0.923 1.0 0.786 0.857 CI 95% [0.386, 0.836] [0.449, 0.884] [0.351, 0.880] [0.441, 0.943] [0.420, 0.874] [0.563, 0.966] [0.326, 0.785] [0.269, 0.731] [0.642, 1.000] [0.729, 1.000] [0.515, 0.929] [0.586, 0.970] automatic change knowledge meas. 0.6 0.4 0.375 0.25 0.6 0.3 0.667 0.667 0.5 0.5 0.6 0.5 CI 95% [0.312, 0.831] [0.169, 0.688] [0.138, 0.696] [0.067, 0.600] [0.312, 0.831] [0.106, 0.608] [0.296, 0.904] [0.296, 0.904] [0.238, 0.762] [0.238, 0.762] [0.312, 0.831] [0.238, 0.762] add unrelated information meas. 0.571 0.857 0.5 0.357 0.643 1.0 0.643 0.643 1 1.0 0.643 0.857 CI 95% [0.326, 0.785] [0.586, 0.970] [0.269, 0.731] [0.164, 0.614] [0.386, 0.836] [0.744, 1.000] [0.386, 0.836] [0.386, 0.836] [0.744, 1.000] [0.744, 1.000] [0.386, 0.836] [0.586, 0.970] induction from baseline meas. 0.545 0.364 0.636 0.455 0.5 0.5 0.364 0.545 0.667 0.917 0.333 0.333 CI 95% [0.281, 0.786] [0.152, 0.648] [0.352, 0.848] [0.214, 0.719] [0.255, 0.745] [0.255, 0.745] [0.152, 0.648] [0.281, 0.786] [0.388, 0.862] [0.621, 1.000] [0.138, 0.612] [0.138, 0.612] untrustworthy testimony meas. 0.333 0.583 0 0.5 0.5 0.667 0.333 0.667 0.667 0.75 0.333 0.5 CI 95% [0.138, 0.612] [0.319, 0.806] [0.000, 0.326] [0.238, 0.762] [0.255, 0.745] [0.388, 0.862] [0.138, 0.612] [0.388, 0.862] [0.388, 0.862] [0.460, 0.915] [0.138, 0.612] [0.255, 0.745] conclusion from sentiment meas. 0.5 0.214 0.364 0.364 0.143 0 0.462 0.308 0.5 0.571 0.286 0.071 CI 95% [0.269, 0.731] [0.071, 0.485] [0.152, 0.648] [0.152, 0.648] [0.030, 0.414] [0.000, 0.256] [0.233, 0.708] [0.126, 0.580] [0.269, 0.731] [0.326, 0.785] [0.116, 0.551] [0.000, 0.339] T able 5: Theory of Mind Accuracies: All Models and Perturbation Classes. Upper table created using ”All-Subtasks”. Lo wer table measurements on ”False Belief” T asks. V -P: V anilla - Prompting; CoT -P: Chain of Thought - Prompting. F .2 A TE with P erturbations as T reatment, All-Subtasks (see next page for full table) Model meta-llama/Llama-2-70b-chat-hf lmsys/vicuna-33b-v1.3 mistralai/Mixtral-8x7B-Instruct-v0.1 01-ai/Y i-34B-Chat meta-llama/Meta-Llama-3-70B-Instruct databricks/dbrx-instruct Effect A TE RR A TE RR A TE RR A TE RR A TE RR A TE RR CoT Perturbation Class Statistic Without CoT Overall meas. -0.040 0.951 -0.037 0.956 -0.089 0.890 -0.037 0.955 -0.108 0.887 -0.099 0.887 CI 95% [-0.119, 0.038] [0.864, 1.047] [-0.118, 0.044] [0.868, 1.053] [-0.171, -0.006] [0.802, 0.987] [-0.116, 0.042] [0.866, 1.052] [-0.157, -0.060] [0.843, 0.934] [-0.169, -0.029] [0.817, 0.962] Transparent Container meas. -0.025 0.969 0.013 1.015 -0.091 0.887 0.003 1.003 -0.077 0.920 -0.011 0.988 CI 95% [-0.133, 0.082] [0.849, 1.106] [-0.094, 0.119] [0.895, 1.151] [-0.208, 0.025] [0.759, 1.036] [-0.104, 0.109] [0.881, 1.142] [-0.154, -0.000] [0.845, 1.001] [-0.105, 0.083] [0.886, 1.100] Preposition Replacement meas. -0.124 0.850 -0.034 0.960 -0.330 0.590 -0.067 0.918 -0.189 0.803 -0.175 0.800 CI 95% [-0.247, 0.000] [0.719, 1.005] [-0.155, 0.087] [0.828, 1.112] [-0.462, -0.197] [0.461, 0.756] [-0.189, 0.055] [0.784, 1.074] [-0.291, -0.088] [0.707, 0.912] [-0.299, -0.051] [0.676, 0.946] Uninformative Label meas. -0.120 0.854 -0.093 0.890 0.009 1.011 -0.130 0.841 -0.162 0.832 -0.125 0.857 CI 95% [-0.253, 0.012] [0.713, 1.023] [-0.225, 0.040] [0.750, 1.056] [-0.115, 0.132] [0.868, 1.177] [-0.264, 0.004] [0.699, 1.013] [-0.272, -0.051] [0.727, 0.952] [-0.248, -0.002] [0.732, 1.004] Late Label meas. -0.061 0.926 -0.064 0.924 -0.032 0.961 -0.025 0.969 -0.106 0.890 -0.058 0.934 CI 95% [-0.172, 0.050] [0.804, 1.066] [-0.177, 0.049] [0.803, 1.064] [-0.144, 0.081] [0.833, 1.108] [-0.134, 0.084] [0.846, 1.110] [-0.187, -0.025] [0.812, 0.976] [-0.157, 0.041] [0.830, 1.051] Non Protagonist Belief meas. 0.003 1.004 0.057 1.068 -0.039 0.952 0.010 1.012 -0.069 0.928 -0.038 0.956 CI 95% [-0.101, 0.108] [0.885, 1.140] [-0.043, 0.158] [0.951, 1.200] [-0.152, 0.075] [0.823, 1.101] [-0.095, 0.114] [0.891, 1.149] [-0.145, 0.007] [0.854, 1.008] [-0.135, 0.059] [0.853, 1.071] Automatic Change Knowledge meas. -0.124 0.850 -0.186 0.779 -0.216 0.731 -0.209 0.744 -0.205 0.787 -0.250 0.714 CI 95% [-0.247, 0.000] [0.719, 1.005] [-0.324, -0.049] [0.640, 0.947] [-0.347, -0.086] [0.596, 0.896] [-0.359, -0.060] [0.590, 0.938] [-0.309, -0.101] [0.689, 0.898] [-0.373, -0.127] [0.595, 0.857] Add Unrelated Information meas. 0.032 1.039 0.003 1.004 -0.032 0.961 0.010 1.012 0.000 1.000 -0.038 0.956 CI 95% [-0.069, 0.134] [0.921, 1.173] [-0.104, 0.111] [0.884, 1.140] [-0.144, 0.081] [0.833, 1.108] [-0.095, 0.114] [0.891, 1.149] [-0.061, 0.061] [0.938, 1.066] [-0.135, 0.059] [0.853, 1.071] Induction From Baseline meas. 0.027 1.033 -0.013 0.984 -0.111 0.862 -0.020 0.976 -0.121 0.875 -0.159 0.818 CI 95% [-0.080, 0.134] [0.909, 1.173] [-0.126, 0.099] [0.860, 1.126] [-0.233, 0.012] [0.729, 1.019] [-0.134, 0.094] [0.847, 1.124] [-0.209, -0.032] [0.789, 0.969] [-0.273, -0.045] [0.704, 0.950] Untrustworthy T estimony meas. -0.094 0.885 -0.110 0.869 -0.085 0.894 -0.078 0.905 -0.185 0.808 -0.115 0.869 CI 95% [-0.210, 0.021] [0.761, 1.030] [-0.230, 0.010] [0.744, 1.016] [-0.203, 0.033] [0.764, 1.046] [-0.192, 0.037] [0.780, 1.050] [-0.279, -0.091] [0.718, 0.908] [-0.222, -0.008] [0.760, 0.994] Conclusion From Sentiment meas. -0.020 0.976 -0.045 0.946 -0.095 0.882 -0.029 0.965 -0.154 0.840 -0.202 0.769 CI 95% [-0.127, 0.088] [0.856, 1.114] [-0.162, 0.072] [0.820, 1.093] [-0.211, 0.021] [0.755, 1.030] [-0.137, 0.079] [0.843, 1.104] [-0.241, -0.066] [0.757, 0.932] [-0.312, -0.092] [0.661, 0.895] With CoT Overall meas. -0.060 0.927 -0.098 0.890 -0.118 0.869 -0.126 0.858 -0.084 0.913 -0.112 0.874 CI 95% [-0.139, 0.019] [0.842, 1.021] [-0.171, -0.025] [0.818, 0.968] [-0.184, -0.053] [0.807, 0.936] [-0.194, -0.057] [0.792, 0.929] [-0.132, -0.036] [0.868, 0.960] [-0.180, -0.043] [0.807, 0.945] Transparent Container meas. 0.023 1.027 -0.243 0.726 -0.060 0.933 -0.095 0.893 -0.067 0.930 -0.040 0.955 CI 95% [-0.080, 0.125] [0.909, 1.162] [-0.362, -0.125] [0.613, 0.860] [-0.154, 0.034] [0.837, 1.040] [-0.196, 0.007] [0.789, 1.011] [-0.142, 0.008] [0.857, 1.010] [-0.135, 0.055] [0.855, 1.066] Preposition Replacement meas. -0.136 0.835 -0.196 0.779 -0.261 0.711 -0.135 0.848 -0.139 0.856 -0.142 0.840 CI 95% [-0.261, -0.011] [0.704, 0.991] [-0.324, -0.069] [0.655, 0.926] [-0.381, -0.140] [0.596, 0.847] [-0.250, -0.019] [0.732, 0.982] [-0.234, -0.044] [0.765, 0.958] [-0.261, -0.022] [0.720, 0.979] Uninformative Label meas. -0.230 0.721 -0.071 0.920 -0.136 0.849 -0.166 0.812 -0.128 0.867 -0.056 0.936 CI 95% [-0.368, -0.091] [0.580, 0.896] [-0.191, 0.049] [0.797, 1.062] [-0.256, -0.017] [0.731, 0.986] [-0.291, -0.040] [0.688, 0.960] [-0.233, -0.023] [0.766, 0.980] [-0.169, 0.056] [0.819, 1.070] Late Label meas. -0.022 0.974 -0.098 0.889 -0.149 0.834 -0.211 0.761 -0.096 0.900 -0.096 0.891 CI 95% [-0.129, 0.086] [0.853, 1.112] [-0.205, 0.008] [0.782, 1.012] [-0.253, -0.046] [0.733, 0.950] [-0.322, -0.101] [0.654, 0.886] [-0.176, -0.016] [0.823, 0.984] [-0.197, 0.005] [0.789, 1.008] Non Protagonist Belief meas. 0.051 1.062 0.012 1.014 -0.055 0.939 -0.115 0.870 -0.040 0.958 -0.010 0.989 CI 95% [-0.048, 0.150] [0.945, 1.195] [-0.082, 0.107] [0.913, 1.127] [-0.149, 0.039] [0.842, 1.047] [-0.218, -0.013] [0.766, 0.987] [-0.110, 0.030] [0.889, 1.033] [-0.101, 0.081] [0.892, 1.097] Automatic Change Knowledge meas. -0.199 0.759 -0.216 0.757 -0.352 0.610 -0.394 0.554 -0.244 0.747 -0.372 0.579 CI 95% [-0.326, -0.071] [0.628, 0.917] [-0.347, -0.084] [0.630, 0.910] [-0.474, -0.230] [0.497, 0.748] [-0.541, -0.248] [0.419, 0.732] [-0.351, -0.136] [0.646, 0.863] [-0.496, -0.248] [0.465, 0.722] Add Unrelated Information meas. -0.016 0.981 -0.096 0.891 0.049 1.054 -0.087 0.902 -0.010 0.990 -0.029 0.967 CI 95% [-0.122, 0.091] [0.861, 1.117] [-0.204, 0.011] [0.782, 1.016] [-0.028, 0.125] [0.969, 1.146] [-0.186, 0.013] [0.800, 1.018] [-0.073, 0.054] [0.926, 1.058] [-0.122, 0.065] [0.869, 1.077] Induction From Baseline meas. -0.065 0.921 -0.010 0.989 -0.095 0.895 -0.063 0.929 -0.041 0.957 -0.180 0.796 CI 95% [-0.181, 0.051] [0.794, 1.069] [-0.110, 0.090] [0.883, 1.108] [-0.198, 0.007] [0.791, 1.011] [-0.167, 0.041] [0.821, 1.050] [-0.116, 0.033] [0.884, 1.037] [-0.293, -0.067] [0.685, 0.927] Untrustworthy T estimony meas. -0.063 0.923 -0.109 0.878 -0.100 0.889 -0.103 0.883 -0.057 0.940 -0.072 0.918 CI 95% [-0.176, 0.050] [0.800, 1.066] [-0.219, 0.002] [0.766, 1.005] [-0.200, 0.000] [0.789, 1.003] [-0.207, 0.001] [0.777, 1.003] [-0.133, 0.019] [0.866, 1.021] [-0.173, 0.029] [0.814, 1.036] Conclusion From Sentiment meas. -0.118 0.857 -0.090 0.898 -0.222 0.753 -0.154 0.826 -0.163 0.830 -0.288 0.674 CI 95% [-0.232, -0.003] [0.735, 0.999] [-0.202, 0.022] [0.785, 1.028] [-0.330, -0.115] [0.651, 0.873] [-0.259, -0.048] [0.721, 0.946] [-0.252, -0.075] [0.746, 0.923] [-0.401, -0.176] [0.568, 0.800] T able 7: Perturbation Effect Strengths: All Models. All-Subtasks. A TE: A verage Treatment Ef fect; RR: Relativ e Risk. F .3 A TE with P erturbations as T reatment, F alse Belief T asks (see next page for full table) Model meta-llama/Llama-2-70b-chat-hf lmsys/vicuna-33b-v1.3 mistralai/Mixtral-8x7B-Instruct-v0.1 01-ai/Y i-34B-Chat meta-llama/Meta-Llama-3-70B-Instruct databricks/dbrx-instruct Effect A TE RR A TE RR A TE RR A TE RR A TE RR A TE RR CoT Perturbation Class Statistic Without CoT Overall meas. -0.149 0.758 0.155 1.567 -0.454 0.511 0.037 1.085 -0.378 0.622 -0.248 0.684 CI 95% [-0.398, 0.099] [0.498, 1.153] [-0.100, 0.409] [0.638, 3.849] [-0.643, -0.266] [0.396, 0.657] [-0.208, 0.281] [0.616, 1.911] [-0.529, -0.226] [0.518, 0.747] [-0.471, -0.025] [0.504, 0.928] Transparent Container meas. -0.330 0.464 0.420 2.538 -0.857 0.077 0.000 1.000 -0.571 0.429 -0.357 0.545 CI 95% [-0.649, -0.010] [0.198, 1.088] [0.090, 0.749] [0.997, 6.461] [-1.097, -0.618] [0.007, 0.830] [-0.325, 0.325] [0.469, 2.133] [-0.834, -0.309] [0.247, 0.743] [-0.666, -0.048] [0.300, 0.991] Preposition Replacement meas. -0.415 0.325 0.127 1.467 -0.729 0.215 0.171 1.400 -0.800 0.200 -0.411 0.477 CI 95% [-0.748, -0.083] [0.094, 1.126] [-0.225, 0.480] [0.494, 4.356] [-1.020, -0.438] [0.065, 0.713] [-0.175, 0.518] [0.703, 2.786] [-1.069, -0.531] [0.061, 0.658] [-0.758, -0.063] [0.217, 1.051] Uninformative Label meas. -0.490 0.203 0.102 1.375 -0.429 0.538 -0.179 0.583 -0.750 0.250 -0.161 0.795 CI 95% [-0.829, -0.152] [0.028, 1.496] [-0.265, 0.469] [0.436, 4.335] [-0.758, -0.099] [0.297, 0.976] [-0.530, 0.173] [0.177, 1.925] [-1.046, -0.454] [0.085, 0.732] [-0.508, 0.187] [0.474, 1.336] Late Label meas. -0.077 0.875 0.061 1.222 -0.500 0.462 -0.044 0.897 -0.571 0.429 -0.143 0.818 CI 95% [-0.410, 0.256] [0.489, 1.566] [-0.276, 0.397] [0.396, 3.775] [-0.785, -0.215] [0.262, 0.813] [-0.372, 0.284] [0.399, 2.018] [-0.834, -0.309] [0.247, 0.743] [-0.449, 0.163] [0.528, 1.268] Non Protagonist Belief meas. 0.027 1.045 0.394 2.444 -0.236 0.746 0.143 1.333 -0.077 0.923 0.000 1.000 CI 95% [-0.297, 0.352] [0.623, 1.752] [0.038, 0.750] [0.936, 6.387] [-0.520, 0.047] [0.512, 1.085] [-0.182, 0.468] [0.683, 2.604] [-0.297, 0.143] [0.732, 1.164] [-0.293, 0.293] [0.689, 1.451] Automatic Change Knowledge meas. -0.015 0.975 0.102 1.375 -0.329 0.646 0.238 1.556 -0.500 0.500 -0.186 0.764 CI 95% [-0.365, 0.334] [0.548, 1.734] [-0.265, 0.469] [0.436, 4.335] [-0.638, -0.019] [0.404, 1.033] [-0.143, 0.619] [0.770, 3.142] [-0.792, -0.208] [0.292, 0.857] [-0.517, 0.146] [0.460, 1.267] Add Unrelated Information meas. -0.044 0.929 0.227 1.833 -0.286 0.692 0.214 1.500 0.000 1.000 -0.143 0.818 CI 95% [-0.372, 0.284] [0.534, 1.614] [-0.105, 0.559] [0.682, 4.930] [-0.568, -0.004] [0.466, 1.028] [-0.107, 0.536] [0.791, 2.845] [-0.181, 0.181] [0.834, 1.199] [-0.449, 0.163] [0.528, 1.268] Induction From Baseline meas. -0.070 0.886 0.364 2.333 -0.429 0.538 -0.065 0.848 -0.333 0.667 -0.452 0.424 CI 95% [-0.414, 0.274] [0.487, 1.613] [0.020, 0.708] [0.896, 6.079] [-0.726, -0.131] [0.319, 0.908] [-0.403, 0.273] [0.357, 2.019] [-0.603, -0.064] [0.457, 0.973] [-0.767, -0.138] [0.199, 0.906] Untrustworthy T estimony meas. -0.282 0.542 -0.273 0.000 -0.429 0.538 -0.095 0.778 -0.333 0.667 -0.452 0.424 CI 95% [-0.615, 0.051] [0.242, 1.214] [-0.562, 0.016] [0.000, nan] [-0.726, -0.131] [0.319, 0.908] [-0.425, 0.235] [0.319, 1.895] [-0.603, -0.064] [0.457, 0.973] [-0.767, -0.138] [0.199, 0.906] Conclusion From Sentiment meas. -0.115 0.812 0.091 1.333 -0.786 0.154 0.033 1.077 -0.500 0.500 -0.500 0.364 CI 95% [-0.444, 0.213] [0.447, 1.478] [-0.253, 0.435] [0.440, 4.042] [-1.042, -0.530] [0.040, 0.597] [-0.297, 0.363] [0.513, 2.263] [-0.764, -0.236] [0.310, 0.808] [-0.800, -0.200] [0.162, 0.815] With CoT Overall meas. -0.303 0.606 -0.322 0.606 -0.282 0.641 -0.512 0.488 -0.296 0.704 -0.425 0.575 CI 95% [-0.535, -0.071] [0.434, 0.846] [-0.563, -0.082] [0.437, 0.840] [-0.505, -0.059] [0.470, 0.875] [-0.665, -0.358] [0.393, 0.606] [-0.445, -0.147] [0.595, 0.832] [-0.578, -0.273] [0.474, 0.697] Transparent Container meas. -0.484 0.371 -0.280 0.658 -0.429 0.455 -0.714 0.286 -0.429 0.571 -0.429 0.571 CI 95% [-0.791, -0.176] [0.165, 0.837] [-0.606, 0.046] [0.392, 1.105] [-0.734, -0.123] [0.230, 0.900] [-0.967, -0.462] [0.132, 0.619] [-0.691, -0.166] [0.375, 0.871] [-0.691, -0.166] [0.375, 0.871] Preposition Replacement meas. -0.769 0.000 -0.518 0.367 -0.586 0.255 -0.700 0.300 -0.600 0.400 -0.750 0.250 CI 95% [-1.040, -0.498] [0.000, nan] [-0.854, -0.182] [0.152, 0.884] [-0.900, -0.271] [0.076, 0.855] [-0.982, -0.418] [0.129, 0.699] [-0.889, -0.311] [0.207, 0.774] [-1.046, -0.454] [0.085, 0.732] Uninformative Label meas. -0.769 0.000 -0.568 0.306 -0.536 0.318 -0.875 0.125 -0.625 0.375 -0.375 0.625 CI 95% [-1.057, -0.482] [0.000, nan] [-0.916, -0.220] [0.102, 0.919] [-0.873, -0.198] [0.106, 0.955] [-1.151, -0.599] [0.018, 0.891] [-0.932, -0.318] [0.176, 0.798] [-0.682, -0.068] [0.393, 0.994] Late Label meas. -0.154 0.800 -0.068 0.917 -0.357 0.545 -0.769 0.231 -0.571 0.429 -0.429 0.571 CI 95% [-0.473, 0.165] [0.498, 1.284] [-0.387, 0.251] [0.610, 1.379] [-0.666, -0.048] [0.300, 0.991] [-1.021, -0.518] [0.089, 0.595] [-0.834, -0.309] [0.247, 0.743] [-0.691, -0.166] [0.375, 0.871] Non Protagonist Belief meas. -0.055 0.929 -0.040 0.951 0.060 1.077 -0.500 0.500 0.000 1.000 -0.143 0.857 CI 95% [-0.362, 0.252] [0.613, 1.406] [-0.377, 0.296] [0.623, 1.451] [-0.228, 0.349] [0.755, 1.536] [-0.764, -0.236] [0.310, 0.808] [-0.186, 0.186] [0.830, 1.205] [-0.374, 0.088] [0.662, 1.110] Automatic Change Knowledge meas. -0.369 0.520 -0.568 0.306 -0.486 0.382 -0.333 0.667 -0.500 0.500 -0.500 0.500 CI 95% [-0.707, -0.031] [0.257, 1.054] [-0.916, -0.220] [0.102, 0.919] [-0.811, -0.160] [0.159, 0.918] [-0.663, -0.004] [0.415, 1.070] [-0.792, -0.208] [0.292, 0.857] [-0.792, -0.208] [0.292, 0.857] Add Unrelated Information meas. 0.088 1.114 -0.461 0.437 0.214 1.273 -0.357 0.643 0.000 1.000 -0.143 0.857 CI 95% [-0.202, 0.377] [0.778, 1.597] [-0.779, -0.144] [0.220, 0.868] [-0.029, 0.458] [0.950, 1.706] [-0.616, -0.098] [0.443, 0.934] [-0.181, 0.181] [0.834, 1.199] [-0.374, 0.088] [0.662, 1.110] Induction From Baseline meas. -0.406 0.473 -0.364 0.556 -0.286 0.636 -0.455 0.545 -0.083 0.917 -0.667 0.333 CI 95% [-0.735, -0.076] [0.226, 0.988] [-0.701, -0.026] [0.299, 1.032] [-0.606, 0.035] [0.365, 1.110] [-0.738, -0.171] [0.337, 0.882] [-0.312, 0.145] [0.719, 1.169] [-0.936, -0.397] [0.162, 0.687] Untrustworthy T estimony meas. -0.186 0.758 -0.318 0.611 -0.119 0.848 -0.333 0.667 -0.250 0.750 -0.500 0.500 CI 95% [-0.511, 0.140] [0.459, 1.254] [-0.663, 0.026] [0.338, 1.103] [-0.434, 0.196] [0.545, 1.321] [-0.603, -0.064] [0.457, 0.973] [-0.511, 0.011] [0.540, 1.042] [-0.776, -0.224] [0.301, 0.830] Conclusion From Sentiment meas. -0.555 0.279 -0.455 0.444 -0.786 0.000 -0.692 0.308 -0.429 0.571 -0.929 0.071 CI 95% [-0.854, -0.255] [0.102, 0.762] [-0.789, -0.121] [0.213, 0.927] [-1.029, -0.542] [0.000, nan] [-0.953, -0.431] [0.145, 0.651] [-0.691, -0.166] [0.375, 0.871] [-1.141, -0.716] [0.007, 0.768] T able 9: Perturbation Effect Strengths: All Models. False-Belief-T asks. A TE: A verage Treatment; Ef fect RR: Relativ e Risk. F .4 A TE with CoT -P as T reatment (see next page for full table) ALL SUBT ASKS Model meta-llama/Llama-2-70b-chat-hf lmsys/vicuna-33b-v1.3 mistralai/Mixtral-8x7B-Instruct-v0.1 01-ai/Yi-34B-Chat meta-llama/Meta-Llama-3-70B-Instruct databricks/dbrx-instruct Effect A TE RR A TE RR A TE RR A TE RR A TE RR A TE RR Perturbation Class Statistic no complication meas. 0.000 1.000 0.045 1.053 0.098 1.122 0.067 1.082 0.000 1.000 0.010 1.011 CI 95% [-0.105, 0.105] [0.880, 1.136] [-0.058, 0.148] [0.935, 1.187] [0.000, 0.196] [0.998, 1.261] [-0.031, 0.165] [0.964, 1.216] [-0.061, 0.061] [0.938, 1.066] [-0.081, 0.101] [0.912, 1.121] overall meas. -0.020 0.975 -0.016 0.981 0.068 1.095 -0.021 0.973 0.024 1.029 -0.003 0.996 CI 95% [-0.056, 0.017] [0.930, 1.022] [-0.053, 0.022] [0.936, 1.027] [0.031, 0.106] [1.041, 1.152] [-0.058, 0.016] [0.927, 1.021] [-0.005, 0.054] [0.994, 1.065] [-0.039, 0.033] [0.951, 1.044] transparent container meas. 0.048 1.060 -0.211 0.753 0.129 1.181 -0.030 0.963 0.010 1.011 -0.019 0.978 CI 95% [-0.056, 0.152] [0.933, 1.204] [-0.333, -0.089] [0.633, 0.896] [0.016, 0.242] [1.017, 1.371] [-0.140, 0.080] [0.840, 1.105] [-0.079, 0.098] [0.915, 1.116] [-0.117, 0.079] [0.872, 1.096] preposition replacement meas. -0.012 0.982 -0.118 0.855 0.167 1.351 0.000 1.000 0.051 1.066 0.043 1.061 CI 95% [-0.153, 0.128] [0.802, 1.203] [-0.260, 0.025] [0.704, 1.038] [0.016, 0.317] [1.021, 1.788] [-0.136, 0.136] [0.834, 1.199] [-0.075, 0.176] [0.910, 1.247] [-0.103, 0.189] [0.866, 1.300] uninformative label meas. -0.109 0.844 0.067 1.089 -0.047 0.942 0.031 1.045 0.033 1.042 0.078 1.104 CI 95% [-0.270, 0.051] [0.657, 1.086] [-0.080, 0.213] [0.902, 1.314] [-0.188, 0.094] [0.788, 1.127] [-0.124, 0.186] [0.838, 1.304] [-0.106, 0.173] [0.878, 1.236] [-0.062, 0.219] [0.923, 1.322] late label meas. 0.040 1.052 0.011 1.014 -0.020 0.974 -0.119 0.850 0.010 1.011 -0.029 0.965 CI 95% [-0.074, 0.153] [0.910, 1.217] [-0.106, 0.127] [0.873, 1.176] [-0.137, 0.097] [0.836, 1.136] [-0.239, 0.001] [0.719, 1.005] [-0.086, 0.106] [0.905, 1.131] [-0.137, 0.079] [0.843, 1.104] non protagonist belief meas. 0.048 1.058 0.000 1.000 0.082 1.107 -0.058 0.930 0.029 1.033 0.038 1.046 CI 95% [-0.050, 0.146] [0.942, 1.188] [-0.092, 0.092] [0.903, 1.108] [-0.029, 0.192] [0.964, 1.271] [-0.167, 0.051] [0.811, 1.067] [-0.054, 0.113] [0.942, 1.133] [-0.059, 0.135] [0.934, 1.172] automatic change knowledge meas. -0.075 0.893 0.016 1.024 -0.037 0.936 -0.118 0.806 -0.038 0.949 -0.113 0.820 CI 95% [-0.218, 0.068] [0.718, 1.110] [-0.144, 0.175] [0.805, 1.303] [-0.187, 0.112] [0.719, 1.219] [-0.303, 0.067] [0.572, 1.137] [-0.175, 0.098] [0.788, 1.143] [-0.262, 0.037] [0.628, 1.071] add unrelated information meas. -0.048 0.944 -0.055 0.935 0.178 1.231 -0.029 0.965 -0.010 0.990 0.019 1.023 CI 95% [-0.150, 0.054] [0.834, 1.068] [-0.167, 0.057] [0.815, 1.073] [0.084, 0.273] [1.095, 1.383] [-0.135, 0.078] [0.846, 1.100] [-0.073, 0.054] [0.926, 1.058] [-0.080, 0.119] [0.910, 1.151] induction from baseline meas. -0.092 0.892 0.049 1.059 0.114 1.164 0.024 1.030 0.080 1.095 -0.011 0.984 CI 95% [-0.209, 0.025] [0.769, 1.034] [-0.061, 0.159] [0.930, 1.205] [-0.012, 0.240] [0.981, 1.381] [-0.095, 0.143] [0.889, 1.193] [-0.019, 0.178] [0.977, 1.226] [-0.144, 0.121] [0.817, 1.186] untrustworthy testimony meas. 0.031 1.043 0.047 1.063 0.083 1.116 0.042 1.056 0.128 1.164 0.052 1.068 CI 95% [-0.091, 0.154] [0.885, 1.229] [-0.081, 0.174] [0.898, 1.259] [-0.036, 0.203] [0.952, 1.308] [-0.078, 0.162] [0.902, 1.237] [0.023, 0.232] [1.024, 1.324] [-0.063, 0.168] [0.922, 1.238] conclusion from sentiment meas. -0.098 0.878 0.000 1.000 -0.029 0.959 -0.058 0.927 -0.010 0.988 -0.077 0.886 CI 95% [-0.215, 0.019] [0.751, 1.027] [-0.125, 0.125] [0.855, 1.170] [-0.153, 0.095] [0.802, 1.147] [-0.173, 0.058] [0.796, 1.080] [-0.118, 0.099] [0.863, 1.131] [-0.205, 0.051] [0.722, 1.086] F ALSE BELIEF SUBT ASKS Model meta-llama/Llama-2-70b-chat-hf lmsys/vicuna-33b-v1.3 mistralai/Mixtral-8x7B-Instruct-v0.1 01-ai/Y i-34B-Chat meta-llama/Meta-Llama-3-70B-Instruct databricks/dbrx-instruct Effect A TE RR A TE RR A TE RR A TE RR A TE RR A TE RR Perturbation Class Statistic no complication meas. 0.154 1.250 0.545 3.000 -0.143 0.846 0.571 2.333 0.000 1.000 0.214 1.273 CI 95% [-0.165, 0.473] [0.779, 2.006] [0.218, 0.873] [1.200, 7.502] [-0.410, 0.125] [0.614, 1.166] [0.309, 0.834] [1.345, 4.047] [-0.181, 0.181] [0.834, 1.199] [-0.029, 0.458] [0.950, 1.706] overall meas. 0.000 1.000 0.068 1.160 0.030 1.062 0.023 1.050 0.081 1.131 0.037 1.069 CI 95% [-0.118, 0.118] [0.776, 1.288] [-0.057, 0.194] [0.882, 1.525] [-0.088, 0.147] [0.835, 1.352] [-0.097, 0.143] [0.816, 1.351] [-0.030, 0.193] [0.955, 1.339] [-0.080, 0.155] [0.866, 1.321] transparent container meas. 0.000 1.000 -0.154 0.778 0.286 5.000 -0.143 0.667 0.143 1.333 0.143 1.333 CI 95% [-0.308, 0.308] [0.340, 2.939] [-0.482, 0.175] [0.449, 1.347] [0.004, 0.568] [0.430, 58.188] [-0.459, 0.174] [0.263, 1.692] [-0.182, 0.468] [0.683, 2.604] [-0.182, 0.468] [0.683, 2.604] preposition replacement meas. -0.200 1.000 -0.100 0.750 0.000 1.000 -0.300 0.500 0.200 2.000 -0.125 0.667 CI 95% [-0.487, 0.087] [0.000, inf] [-0.461, 0.261] [0.260, 2.161] [-0.335, 0.335] [0.188, 5.330] [-0.661, 0.061] [0.195, 1.282] [-0.151, 0.551] [0.519, 7.708] [-0.511, 0.261] [0.182, 2.448] uninformative label meas. -0.125 1.000 -0.125 0.667 -0.250 0.500 -0.125 0.500 0.125 1.500 0.000 1.000 CI 95% [-0.434, 0.184] [0.000, inf] [-0.511, 0.261] [0.182, 2.448] [-0.639, 0.139] [0.149, 1.673] [-0.487, 0.237] [0.054, 4.657] [-0.261, 0.511] [0.409, 5.507] [-0.394, 0.394] [0.532, 1.880] late label meas. 0.077 1.143 0.417 2.250 0.000 1.000 -0.154 0.600 0.000 1.000 -0.071 0.889 CI 95% [-0.256, 0.410] [0.639, 2.045] [0.088, 0.745] [1.038, 4.876] [-0.325, 0.325] [0.469, 2.133] [-0.473, 0.165] [0.196, 1.836] [-0.325, 0.325] [0.469, 2.133] [-0.393, 0.250] [0.522, 1.515] non protagonist belief meas. 0.071 1.111 0.111 1.167 0.154 1.222 -0.071 0.875 0.077 1.083 0.071 1.091 CI 95% [-0.242, 0.385] [0.698, 1.768] [-0.253, 0.476] [0.700, 1.945] [-0.150, 0.458] [0.815, 1.833] [-0.397, 0.254] [0.474, 1.614] [-0.147, 0.301] [0.855, 1.372] [-0.211, 0.354] [0.772, 1.542] automatic change knowledge meas. -0.200 0.667 -0.125 0.667 -0.300 0.500 0.000 1.000 0.000 1.000 -0.100 0.833 CI 95% [-0.567, 0.167] [0.306, 1.453] [-0.511, 0.261] [0.182, 2.448] [-0.661, 0.061] [0.195, 1.282] [-0.429, 0.429] [0.525, 1.904] [-0.370, 0.370] [0.477, 2.098] [-0.469, 0.269] [0.423, 1.643] add unrelated information meas. 0.286 1.500 -0.143 0.714 0.357 1.556 0.000 1.000 0.000 1.000 0.214 1.333 CI 95% [-0.014, 0.585] [0.947, 2.376] [-0.465, 0.180] [0.327, 1.561] [0.098, 0.616] [1.071, 2.259] [-0.318, 0.318] [0.609, 1.641] [-0.181, 0.181] [0.834, 1.199] [-0.082, 0.510] [0.880, 2.021] induction from baseline meas. -0.182 0.667 -0.182 0.714 0.000 1.000 0.182 1.500 0.250 1.375 0.000 1.000 CI 95% [-0.536, 0.172] [0.292, 1.520] [-0.536, 0.172] [0.362, 1.408] [-0.346, 0.346] [0.500, 2.000] [-0.172, 0.536] [0.658, 3.420] [-0.054, 0.554] [0.911, 2.075] [-0.335, 0.335] [0.366, 2.736] untrustworthy testimony meas. 0.250 1.750 0.500 1.000 0.167 1.333 0.333 2.000 0.083 1.125 0.167 1.500 CI 95% [-0.090, 0.590] [0.767, 3.992] [0.191, 0.809] [1.000, 1.000] [-0.174, 0.508] [0.728, 2.443] [-0.002, 0.669] [0.903, 4.432] [-0.245, 0.412] [0.705, 1.795] [-0.174, 0.508] [0.632, 3.559] conclusion from sentiment meas. -0.286 0.429 0.000 1.000 -0.143 1.000 -0.154 0.667 0.071 1.143 -0.214 0.250 CI 95% [-0.596, 0.024] [0.147, 1.250] [-0.351, 0.351] [0.381, 2.623] [-0.374, 0.088] [0.000, inf] [-0.482, 0.175] [0.271, 1.639] [-0.254, 0.397] [0.620, 2.108] [-0.490, 0.062] [0.021, 3.019] T able 12: Chain of Thought Effect Strengths: All Models and Perturbation Classes. Upper table created using ”All-Subtasks”. Lo wer table measurements on ”False Belief” T asks. A TE: A verage T reatment Effect; RR: Relati ve Risk. Statistic T ype Measure Metric Llama 2 70B Chat V icuna 33B v1.3 Mixtral 8x7B Inst. Y i 34B Chat Llama 3 70B Inst. DBRX Instruct Point- Biserial Correlation R OUGE-L Corr . 0.391 0.516 0.304 0.245 0.398 0.235 P-V alue 2 . 0 × 10 − 6 0 3 . 1 × 10 − 4 4 . 0 × 10 − 3 2 . 0 × 10 − 6 6 . 0 × 10 − 3 R OUGE-L (Pre-Proper) Corr . 0.39 0.482 0.242 0.212 0.37 0.214 P-V alue 3 . 0 × 10 − 6 0 4 . 6 × 10 − 3 1 . 3 × 10 − 2 1 . 0 × 10 − 5 1 . 2 × 10 − 2 Transition Overlap Corr . 0.476 0.501 0.281 0.229 0.435 0.224 P-V alue 0 0 9 . 4 × 10 − 4 7 . 4 × 10 − 3 0 8 . 8 × 10 − 3 Phi Coefficient CoT Correctness Corr . 0.549 0.342 0.429 0.306 0.584 0.489 P-V alue 0 6 . 7 × 10 − 5 1 . 0 × 10 − 6 3 . 5 × 10 − 4 0 0 T able 13: Faithfulness: Correlations and P-V alues between CoT -correctness and Final Answer Correctness for all models. Moderate to strong correlations suggest that models rely on their rationales, although other effects are present. F .5 F aithfulness G Supplementary Figures For a more intuiti ve understanding of both the dataset and the ev aluation pipeline we provide some visual representations. G.1 Dataset Structure The dataset structure from stage via task to subtasks can be observed in Figure 6 G.2 Evaluation and Analysis Pipeline The whole process from dataset to ev aluation results is illustrated in Figure 7. Figure 6: Structure of our dataset. Each of the 7 stages contains one unperturbed base task and up to 10 perturbed variants. Each task includes 16 subtasks probing different types of understanding. Figure 7: T oM ev aluation and analysis pipeline. Our dataset is used to benchmark six open-source LLMs under V anilla and Chain-of- Thought prompting. Model answers are ev aluated for final answer accuracy , CoT correctness, and faithfulness.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment