Selecting representative community partitions under modularity degeneracy: the STAR method
Community detection based on modularity maximization is one of the most widely used approaches for uncovering mesoscale structures in complex networks. However, it is well known that the modularity function exhibits a highly degenerate optimization l…
Authors: Francesca Grassetti, Rossana Mastr, rea
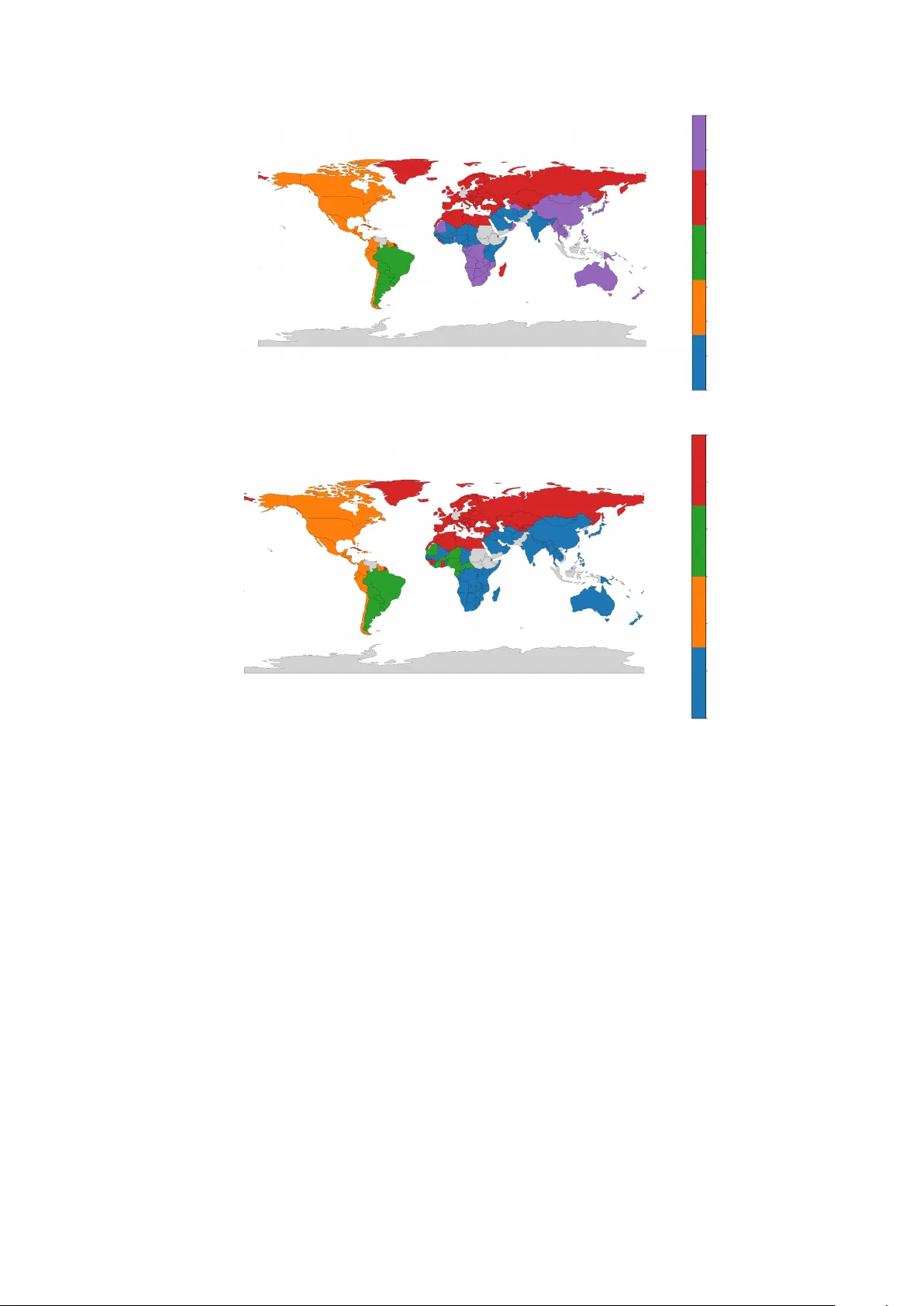
Selecting represen tativ e comm unit y partitions under mo dularit y degeneracy: the ST AR metho d F rancesca Grassetti 1 and Rossana Mastrandrea 2* 1 Departmen t of Economics, So ciet y , P olitics, Universit y of Urbino, via Saffi 42, Urbino, 61029, Italy , OR CID: 0000-0001-8703-3232. 2 Departmen t of Managemen t, Universit y of T urin, Corso Unione So vietica 218bis, T urin, 10134, Italy , ORCID: 0000-0001-8596-6389. *Corresp onding author(s). E-mail(s): rossana.mastrandrea@unito.it ; Con tributing authors: francesca.grassetti@uniurb.it ; Abstract Comm unity detection based on mo dularity maximization is one of the most widely used approac hes for uncov ering mesoscale structures in complex net works. Ho wev er, it is w ell kno wn that the mo dularit y function exhibits a highly degen- erate optimization landscap e: a large num ber of structurally distinct partitions attain close mo dularit y v alues. This degeneracy raises issues of instabilit y , repro- ducibilit y , and in terpretabilit y of the detected comm unities. W e prop ose a simple and user-friendly p ost-pro cessing metho d to address this problem by selecting a representativ e partition among the set of high-modularity solutions. The pro- p osed approach is model-agnostic and can b e applied a p osteriori to the output of any mo dularit y-based communit y detection algorithm. Rather than seeking the optimal partition in terms of mo dularit y , our method aims to iden tify a solution that b est represents the structural features shared across degenerate partitions. W e compare our approach with consensus clustering metho ds, which pursue a similar ob jective, and show that the resulting partitions are highly consisten t, while b eing obtained through a substan tially simpler pro cedure that do es not require additional optimization steps or external softw are pac k ages. Moreo ver, unlik e standard consensus clustering tec hniques, the proposed metho d can b e applied to netw orks with b oth p ositiv e and negative edge weigh ts, mak- ing it suitable for a wide range of applications inv olving signed net works and correlation-based systems, such as so cial, financial, and neuroscience netw orks. Ov erall, the metho d provides a practical and robust to ol for handling degener- acy in mo dularity-based communit y detection, combining simplicity with broad applicabilit y across differen t types of netw orks and real-world problems. 1 Keyw ords: Communit y detection, Modularity maximization, Degeneracy , Consensus clustering, Signed net works 1 In tro duction Man y real-w orld systems – spanning natural, social, tec hnological, and economic domains – are c haracterized by complex patterns of in teractions among their constituen t elements, giving rise to collective b eha viors, non-trivial structural orga- nization, and emergen t phenomena that cannot b e fully understo od b y analyzing individual components in isolation. By representing such systems as netw orks, where no des denote entities and edges enco de interactions, graph theory provides a principled approach to mo del, analyze, and in terpret complex interdependencies, enabling insights into system robustness, dynamics, information flo w, and functional organization ( M. Newman , 2018 ; P´ osfai & Barab´ asi , 2016 ). Within this broader context, a fundamental task in net work analysis is Comm u- nit y Detection (CD), also kno wn as graph or netw ork clustering ( F ortunato & Hric , 2016 ). The ob jective of CD is to partition the nodes of a net work in to substructures or comm unities (or clusters/mo dules), where no des within a group are densely connected while no des b elonging to differen t groups are sparsely link ed. Identifying these meso- scopic structures is crucial for revealing the laten t functions, organizational principles, and op erational pro cesses of complex netw ork systems ( Jin et al. , 2023 ). CD is a ver- satile net work analysis technique applied across numerous scientific and technological domains, with significant impact in fields ranging from so cial sciences to biology and b ey ond ( Karatas & S ¸ ahin , 2018 ). Sp ecific application contexts include so cial netw orks ( Bedi & Sharma , 2016 ), p olitical science, neuroscience and genetics ( Shai, Stanley , Granell, T aylor, & Mucha , 2021 ), as well as economics with the iden tification of asset clusters in financial mark ets for portfolio diversification and risk managemen t ( Almog, Besam usca, MacMahon, & Garlasc helli , 2015 ; Bazzi et al. , 2016 ; Musmeci, Aste, & Di Matteo , 2015 ; Zanin et al. , 2016 ), the detection of anomalies and fraud in banking and trading net works ( Mazzarisi et al. , 2024 ; Safdari & De Bacco , 2022 ), the analy- sis of in terlo c king netw orks of firms ( Drago & Ricciuti , 2017 ; Heemskerk, Daolio, & T omassini , 2013 ; Mastrandrea, Amato, & Patuelli , 2025 ), the grouping of countries or banks in the interbank lending system and international trade net work ( Bargigli & Gallegati , 2013 ; Barigozzi, F agiolo, & Mangioni , 2011 ; Grassi, Bartesaghi, Benati, & Clemen te , 2021 ; Siudak , 2023 ). The problem of CD is inherently ill-defined, lac king a universal and unambiguous definition of what constitutes a “comm unity”. Over the y ears, numerous metho dolo- gies hav e b een prop osed. Classical approac hes include hierarchical clustering, spectral clustering, and statistical inference ( Li et al. , 2024 ). Statistical mo deling is promi- nen t, notably through Probabilistic Graphical Mo dels suc h as the Sto c hastic Blo c k Mo del, which formalizes a generative pro cess based on probabilit y distributions ( Abb e , 2018 ). More recen tly , new research lines ha ve emerged lev eraging the capacity of deep learning to handle high-dimensional net w ork data and learn lo w-dimensional represen- tations of net work structures, encompassing metho ds lik e those based on auto-enco ders 2 and Graph Conv olutional Netw orks ( Liu, W ei, & Xu , 2023 ; Y uan, Zeng, Zuo, & W ang , 2023 ; W. Zhang, Shang, Li, Sun, & Du , 2023 ). Among the optimization-based approac hes, mo dularity maximization is the most p opular and extensively studied metho d for CD. Mo dularit y , defined by M.E.J. Newman and Girv an ( 2004 ) and gen- erally indicated with Q , is a quality function that measures the fraction of links falling within communities compared to its exp ected n umber according to a n ull mo de pre- serving no de connections. Finding the global optimum of Q is known to b e NP-hard ( Brandes et al. , 2008 ). Consequen tly , heuristic algorithms, suc h as the Louv ain metho d ( De Meo, F errara, Fiumara, & Pro vetti , 2011 ) and the Clauset-Newman-Mo ore algo- rithm ( Gulbahce & Lehmann , 2008 ), are widely employ ed to find highly mo dular partitions. Despite its ubiquity , mo dularity maximization suffers from critical limitations. F oremost among these is the resolution limit, a bias resulting from the underlying null mo del that prev ents the detection of smaller communities in large net works ( F ortunato & Barth´ elemy , 2007 ; Lancichinetti & F ortunato , 2011 ). Crucially , the optimization pro cess is highly susceptible to finding degenerate solutions. F ormally , let G = ( V , E ) b e a finite graph and let P ( V ) denote the set of all partitions of the v ertex set V . Modularity maximization consists in solving the discrete optimization problem Q max := max P ∈P ( V ) Q ( P ) , where Q : P ( V ) → R is the mo dularity functional. This problem is NP-hard and the ob jective function is neither con vex nor submo dular ov er the partition lattice. Bey ond computational intractabilit y , the mo dularit y landscap e exhibits a pro- nounced structural near-degeneracy . In net works composed of k weakly in terconnected mo dular building blo cks, the num b er of structurally distinct partitions attaining ob jec- tiv e v alues arbitrarily close to Q max gro ws at least as 2 k − 1 , and ma y in general increase sup er-exponentially with k . At the same time, the mo dularit y v ariation induced by merging or rearranging modules scales as O ( k − 2 ), implying that large families of parti- tions differ com binatorially while remaining nearly indistinguishable in ob jectiv e v alue Go od, de Mon tjoy e, and Clauset ( 2010 ). T o formalize this phenomenon, for ε > 0 let us define the ε -optimal set P ε = { P ∈ P ( V ) : Q max − Q ( P ) ≤ ε } F or sufficiently small ε , the set P ε ma y already ha ve exp onen tial cardinalit y in the n umber of mesoscopic structures. Consequently , the global maximizer is typically not isolated but em b edded in a high-dimensional plateau of near-optimal solutions. Imp ortan tly , partitions in P ε ma y exhibit substantial structural v ariability despite negligible differences in mo dularit y . Therefore, mo dularit y maximization do es not generically yield a structurally stable solution, and selecting a represen tative parti- tion within the near-optimal set P ε constitutes a secondary optimization and inference problem ov er a highly degenerate solution manifold. T o address the ambiguit y arising from degeneracy and structural v ariabilit y , sev eral strategies hav e b een prop osed. Consensus Clustering (CC) ( Lancichinetti & F ortu- nato , 2012 ) aims to merge the information from an ensem ble of degenerate partitions 3 in to a single, more stable solution. CC typically uses a consensus matrix based on the co-o ccurrence of no des in the same comm unity across the ensemble. Ho wev er, consensus solutions can sometimes inadverten tly blur relev ant information captured b y individual partitions ( Calata yud, Bernardo-Madrid, Neuman, Ro jas, & Rosv all , 2019 ). An alternative approach is the recursive significance clustering sc heme, which iden tifies subsets of no des that maintain stable joint communit y assignments under net work p erturbation, representing the p ersisten t and w ell-supp orted features of the net work structure, distinguishable from unstable no des ( Economou, Norman, & Gen- tleman , 2025 ). The Bay an algorithm ( Aref, Mosta jab da veh, & Chheda , 2023 ) make use of integer programming to approximate the global maxim um of mo dularity , elim- inating degeneracy b y ensuring consistent, high-quality partitions - though at higher computational cost. Other methods hav e also been employ ed to maximize modular- it y and detect statistically significant comm unities and hierarc hies, they include the message passing for mo dularity ( P . Zhang & Mo ore , 2014 ), a prop er assignment of w eights to the edges ( Khadivi, Ajdari Rad, & Hasler , 2011 ), and the mo delling of mixed p opulations of partitions ( P eixoto , 2021 ). Despite the substan tial bo dy of work addressing degeneracy in mo dularit y-based CD, an open c hallenge remains the developmen t of a selection criterion that is b oth simple and broadly applicable, without in tro ducing additional mo deling assumptions or significant computational ov erhead. Moreov er, most existing metho ds implicitly assume non-negativ e edge w eights, thereb y excluding signed net works and correlation- based systems. This restriction is particularly limiting in empirical settings where in teractions naturally admit both positive and negativ e v alues, such as in Social Science and Financial netw orks. In this w ork, w e in tro duce a simple and user-friendly p ost-processing method aimed at selecting a represen tative partition from an ensemble of high-mo dularity solutions. The prop osed metho d is fully agnostic with resp ect to the underlying CD algorithm and can b e applied a posteriori to an y mo dularity-based approach, indep enden tly of the sp ecific heuristic or optimization strategy used to generate the candidate parti- tions. Imp ortan tly , the metho d fo cuses on extracting a partition that b est represents the structural information shared across degenerate solutions. The rationale b ehind this approach is that, in the presence of a highly degenerate mo dularit y landscap e, the pursuit of an optimal partition is often neither robust nor informative. Small v ari- ations in the netw ork or in the optimization pro cess may lead to mark edly differen t solutions with comparable mo dularity v alues. In suc h settings, a representativ e parti- tion – capturing the most recurren t and structurally stable features of the ensem ble – provides a more reliable and interpretable description of the mesoscale organization of the net work. W e explicitly relate our method to CC ( Lancichinetti & F ortunato , 2012 ), as b oth approac hes pursue the same ob jective of stabilizing communit y assignmen ts in the presence of degeneracy . Ho wev er, the proposed framework ac hieves comparable results through a substan tially simpler procedure. F urthermore, our metho d naturally extends to net works with b oth p ositiv e and negativ e edge weigh ts, allo wing it to b e applied to signed net works and correlation-based matrices without any ad ho c mo dification, a limit of the CC method. 4 Ov erall, the con tribution of this paper is t wofold. First, we provide a parsimo- nious and easily implementable to ol for selecting representativ e communit y structures in mo dularit y-based CD, without sacrificing the quality of the resulting parti- tions. Second, w e extend the applicability of representativ e partition selection to all types of netw orks, including signed netw orks, thereby broadening the scop e of mo dularit y-based metho ds across a wide range of theoretical and applied contexts. The remainder of the pap er is organized as follows. Section Method in tro duces the prop osed selection procedure and outlines the asso ciated selection framework. Section Data describ es the benchmark and real-world datasets considered in the analysis. Section Results reports the empirical p erformance of the metho d on syn- thetic benchmark netw orks with known ground truth and on real economic netw orks. Finally , Sections Discussion and Conclusion summarize the main findings and discuss implications and possible extensions. 2 Metho d In this section, we describ e the metho dology adopted to select a representativ e comm unity partition from an ensemble of mo dularit y-based solutions. 2.1 Net work prop erties Let us consider a graph G = ( V , E ), where V is the set of no des with size | V | = N and E is the set of edges with size | E | = L . The structure of the graph is encoded in the binary adjacency matrix A ≡ ( a ij ) 1 ≤ i,j ≤ N , where a ij = 1 if an edge exists from no de i to no de j , 0 otherwise. F or directed netw orks, in general a ij = a j i . When edges are asso ciated with weigh ts, the net work is characterized by the weigh ted adjacency matrix W ≡ ( w ij ) 1 ≤ i,j ≤ N , where w ij denotes the w eight of the edge from no de i to no de j . As in the binary case, weigh ts may b e asymmetric in directed net works ( M. Newman , 2018 ; P´ osfai & Barab´ asi , 2016 ). In a binary directed netw ork, each no de i is characterized by its out-degree and in-degree, defined respectively as k out i = X j a ij , k in i = X j a j i , whic h measure the num b er of edges lea ving and entering no de i , respectively . In a weigh ted directed net work, the corresp onding quan tities are the out-strength and in-strength, defined by s out i = X j w ij , s in i = X j w j i , represen ting the total weigh t exiting from and incoming to no de i , resp ectiv ely . The total num b er of edges in the net work - L - and the total v olume of exchanges - w tot - 5 can b e represented in terms of degree and strength: L = X i,j a ij = X i k in i = X i k out i , w tot = X i,j w ij = X i s out i = X i s in i , 2.2 Mo dularit y maximization Mo dularit y is one of the most widely used quality functions for CD, providing a quan- titativ e criterion for ev aluating how well a given partition captures the mesoscale organization of a netw ork. The mo dularit y–maximization approach ( M.E.J. Newman , 2006 ; M.E.J. Newman & Girv an , 2004 ) do es not require sp ecifying the num b er of comm unities a priori . Instead, it attempts to automatically uncov er the mesoscale structure of the netw ork based on tw o fundamen tal assumptions: (i) nodes b elonging to the same comm unity are more likely to be connected than no des in different com- m unities, and (ii) a random netw ork constructed under appropriate constraints does not exhibit an y intrinsic communit y structure. Modularity thus measures the exten t to which the observ ed density of intra–comm unity connections exceeds what would b e exp ected under a suitable n ull model. F ormally , mo dularit y is defined as Q = 1 L X i,j ∈ V ( a ij − p ij ) δ ( c i , c j ) , (1) where the Kronec ker delta δ ( c i , c j ) equals 1 if no des i and j b elong to the same comm unity and 0 otherwise. The term p ij in tro duces the notion of r andomness , repre- sen ting the exp ected probability of an edge b etw een no des i and j under a b enchmark n ull mo del preserving selected structural properties of the observ ed net work. In binary and weigh ted netw orks, the most commonly adopted null mo dels are, resp ectiv ely , the follo wing: p ij = k in i , k out j L , p ij = s in i , s out j w tot (2) corresp onding, resp ectiv ely , to the exp ected num b er of edges joining no des i and j b y rewiring links to preserv e the degree and the expected edge-w eight b etw een no des i and j preserving the strength of all vertices, on av erage. Mo dularit y maximization formulates CD as a global optimization problem in which one searches, ov er all p ossible partitions of a net work, for the division of vertices that yields the highest v alue of a mo dularit y function ( 2 ). Mo dularit y is in prac- tice maximized using approximate metho ds. Widely used approac hes include greedy and m ultilevel agglomerative schemes that iteratively merge no des or communities to increase mo dularit y ( M.E.J. Newman , 2004 ), sp ectral algorithms based on the eigen- v ectors of the mo dularit y matrix ( Richardson, Mucha, & Porter , 2009 ), metaheuristic strategies suc h as extremal optimization ( Brandes et al. , 2008 ) or simulated anneal- ing ( Guimer` a & Amaral , 2005 ) that sto chastically explore the space of partitions, and mathematical programming formulations that provide exact or approximate solutions ( Chen, Kuzmin, & Szymanski , 2014 ). 6 F or our purpose, w e adopted the Louv ain algorithm ( Blondel, Guillaume, Lam- biotte, & Lefebvre , 2008 ) to address the computational complexity of mo dularit y maximization. The Louv ain metho d is a greedy , hierarc hical optimization procedure that is sp ecifically designed to handle large net works efficien tly . It iteratively impro ves mo dularit y through local node mo vemen ts and successiv e aggregation of communi- ties, enabling the detection of comm unity structure at m ultiple scales. Therefore, it offers a fav orable balance b et w een accuracy , scalability , and computational efficiency . Finally , it is applicable to both weigh ted and unw eighted netw orks making it partic- ularly well suited for the netw ork structures analyzed in this study . 2.3 Similarit y-based T op ARI Representativ e metho d W e in tro duce the Similarity-based T op ARI Representativ e (ST AR) metho d to address the degeneracy inheren t in mo dularit y maximization. The metho d is fully agnostic with resp ect to the sp ecific optimization heuristic used to generate candidate partitions and can b e applied to the output of any mo dularit y-maximization algorithm. F or concreteness, in the follo wing we generate candidate partitions b y rep eatedly applying the Louv ain algorithm. Giv en the graph G , w e repeat T times the modularity maximization procedure using the Louv ain algorithm obtaining T optimal partitions σ = { σ 1 , . . . , σ T } and corresp onding modularities Q = { Q ( σ 1 ) , . . . , Q ( σ T ) } . W e emplo y the Adjusted Rand Index (ARI) ( Hub ert & Arabie , 1985 ) to quan- tify pairwise similarities b et ween the T partitions of the graph G . ARI ev aluates the agreemen t b et ween tw o partitions by considering all pairs of no des and correcting for c hance agreemen t, yielding an exp ected v alue of zero for random and indep enden t partitions. This prop ert y is particularly imp ortan t when comparing multiple solutions generated b y sto c hastic and degenerate optimization pro cedures such as mo dularity maximization. Alternativ e measures commonly used in CD include the Normalized Mutual Infor- mation (NMI) ( Danon, Diaz-Guilera, Duc h, & Arenas , 2005 ) and the V ariation of Information (VI) ( Meil˘ a , 2007 ). Although NMI is widely adopted, it do es not explic- itly correct for c hance agreement and is known to b e biased by the num b er and size of comm unities, p otentially leading to inflated similarity v alues when comparing unre- lated partitions ( Vinh, Epps, & Bailey , 2009 ). VI, on the other hand, defines a metric distance b et ween partitions , but lacks a natural baseline for random agreement and is less intuitiv e when interpreted as a similarit y measure. In con trast, ARI is in v arian t under p erm utation of comm unity labels, accommo dates partitions with differing num- b ers of clusters, and pro vides a robust and in terpretable notion of similarity , making it well suited for identifying a representativ e solution among degenerate partitions. Let σ i and σ j b e tw o partitions with cluster sets C [ i ] = { C [ i ] 1 , . . . , C [ i ] l } and C [ j ] = { C [ j ] 1 , . . . , C [ j ] y } . F or each pair of clusters ( C [ i ] u , C [ j ] v ), define n uv = C [ i ] u ∩ C [ j ] v , represen ting the num b er of no des assigned simultaneously to cluster u in partition i and cluster v in partition j . Summing across ro ws and columns gives the marginal 7 totals: n u · = y X v =1 n uv , n · v = l X u =1 n uv . Using these quan tities, let us define z = l X u =1 y X v =1 n uv 2 , b = l X u =1 n u · 2 , c = y X v =1 n · v 2 , M = N 2 . The ARI is then computed as ARI( σ i , σ j ) = z − bc M 1 2 ( b + c ) − bc M In this form ula, z counts the num b er of pairs of no des that are clustered together in b oth partitions, while b and c count the total num b er of pairs in each partition separately . The term bc/ M represen ts the expected n umber of agreemen ts betw een the partitions under a random assignment of nodes to clusters. The ARI corrects for this exp ected chance agreement, yielding a v alue of 1 when the partitions are identical, 0 when the similarity is no better than random, and negative v alues when the partitions agree less than exp ected by chance. This makes the ARI particularly suitable for comparing partitions of different sizes or cluster coun ts, and it treats cluster splitting and merging symmetrically . P airwise ARI v alues are used to build a w eighted undirected net work in whic h no des represen t the T partitions of the graph G and edge weigh ts corresp ond to the pairwise ARI b et ween them and whose adjacency matrix is indicated by R ≡ ( r ij ) 1 ≤ i,j ≤ T . W e can compute the strength of eac h no de in this netw ork as s i = T X i =1 r ij = T X j =1 r ij Since the similarit y netw ork is fully connected by construction, the strength of the no de can b e in terpreted as an av erage measure of ho w similar a given partition is to the remaining T − 1 partitions 1 . Within this framework, the algorithm first iden tifies the partitions with maximal strength and then selects, among these, the partition(s) with the highest modularity v alue. This procedure is designed to identify the partition(s) that are most r epr esen- tative of the entire ensemble while simultaneously fa voring solutions that are closest to the optimal mo dularit y , thereb y balancing representativ eness and quality . W e stress that the goal of the ST AR metho d is not to impro ve the optimum of the ob jectiv e function. Global qualit y functions suc h as modularity are known to exhibit strong degeneracy ( F ortunato & Barth ´ elemy , 2007 ; Lancic hinetti & F ortunato , 2011 ), and insisting on the absolute optimum often do es not lead to meaningful or 1 Indeed, it is sufficien t to divide the strength of eac h no de b y T − 1, after setting the main diagonal of the ARI matrix–corresponding to self-similarity v alues – to zero. 8 stable partitions ( Lancic hinetti & F ortunato , 2012 ). ST AR instead selects a repre- sen tative solution among degenerate partitions, fo cusing on consistency rather than optimization through a simple and user-friendly approach. F or clarit y , the main steps of the prop osed pro cedure are summarized in the pseudo- algorithm rep orted b elo w. Algorithm 1 Pseudo-algorithm: Similarit y-based T op ARI Represen tative (ST AR) metho d Require: Graph G , num b er of repetitions T Ensure: Representativ e partition of G with high mo dularit y 1: Rep eat mo dularit y maximization T times on G 2: Collect resulting partitions σ = { σ 1 , . . . , σ T } and modularities Q = { Q ( σ 1 ) , . . . , Q ( σ T ) } 3: Compute pairwise similarities b et ween partitions using ARI 4: Construct a fully connected w eighted netw ork of partitions (nodes corresp ond to the T partitions, edges to the pairwise ARI) 5: Compute the strength of eac h partition as the sum of its edge weigh ts 6: Identify the partition(s) with maximal strength 7: Among these, select the partition(s) with the highest mo dularit y v alue In the following, we assess the p erformance of the prop osed metho d on b oth syn thetic b enchmark netw orks with known ground truth and on real-w orld netw orks. 3 Data In this section, we describ e the datasets used to ev aluate the proposed metho d. W e consider t wo complemen tary t yp es of data: syn thetic benchmark net works with kno wn ground-truth communit y structure, and real-world economic netw orks. This com bina- tion allows us to assess the p erformance of the metho d under controlled conditions and to illustrate its b eha vior in applied settings. 3.1 Benc hmarks with ground-truth W e ev aluate the proposed approac h on artificial b enc hmark graphs with planted com- m unity structure using the LFR b enchmark ( Lancichinetti, F ortunato, & Radicchi , 2008 ), a standard framework for assessing clustering algorithms. LFR graphs repro- duce key prop erties of real netw orks, including p ow er-law distributions of no de degree and communit y size. A central quantit y is the mixing parameter µ ∈ [0 , 1], whic h con- trols the fraction of links eac h no de shares outside its o wn communit y . Lo wer v alues of µ corresp ond to well-defined communities, while higher v alues indicate increasing o verlap b et w een comm unities, sharply reducing the performance of mo dularit y-based metho ds. W e consider w eighted, undirected net works of size N = 1000 and generate 100 graph instances for each v alue of µ ∈ { 0 . 1 , 0 . 2 , . . . , 0 . 9 } . 9 This benchmark setting allows us to directly ev aluate the qualit y of the selected represen tative partition by comparing it with the known ground-truth communit y structure. 3.2 Real Data W e apply our pro cedure to tw o economic datasets: international trade relationships among world coun tries and equity market data from the FTSE 100 index. In ternational trade data are obtained from the CEPI I database 2 . Eac h observ ation rep orts the exp orter, the imp orter, the deflated trade flo w (in billions of US dollars), and the reference y ear. W e focus on the y ear 2015, which includes the largest n um b er of coun tries (193) within the 2000–2020 p erio d. The resulting W orld T rade W eb (WTW) is mo deled as a netw ork whose no des represent countries and links are weigh ted with the total v alue of exported and imp orted go ods and services. The second dataset consists of daily equity price time series for firms included in the FTSE 100 index. Data were retriev ed from Refinitiv via the LSEG W orkspace plat- form under an academic license from Univ ersity of T urin. F or eac h stock, daily adjusted closing prices w ere collected, accounting for corp orate actions suc h as sto ck splits and dividend pa yments. W e retain 2,544 trading days per sto c k, cov ering appro ximately ten years from April 1, 2016 to Decem b er 31, 2025. Stocks with excessiv e missing obser- v ations were excluded, while remaining gaps were filled using forw ard-fill imputation. Eac h firm was assigned to a sector based on the Datastream Industrial Sector Clas- sification (Level 2), mapped to the Industry Classification Benchmark. Log-returns w ere computed and pairwise correlations w ere estimated, yielding a correlation matrix that was subsequently filtered using Random Matrix Theory and eigendecomp osition tec hniques to remo ve mark et-wide and random effects ( MacMahon & Garlaschelli , 2015 ). These datasets w ere selected for t wo main reasons. First, they represent struc- turally differen t netw orks: the WTW is w eighted and directed, whereas the FTSE 100 netw ork is based on a correlation matrix (symmetric and semidefinite p ositiv e) that includes negative v alues, making it unsuitable for the CC metho d. Second, b oth datasets illustrate applied contexts in which CD serves as a preliminary step for fur- ther analysis, underscoring the imp ortance of a simple and reliable partition selection metho d. 4 Results In this section we present the empirical p erformance of the ST AR metho d. W e first v alidate the pro cedure on synthetic b enc hmark netw orks with plan ted communit y structure (LFR graphs), assessing both accuracy with resp ect to the ground truth and the asso ciated mo dularit y v alues. W e then illustrate the method on tw o real-w orld economic net works – the WTW and the FTSE100 correlation netw ork – to highligh t its behavior in applied settings, including cases with signed w eights where standard consensus approaches are not directly applicable. 2 https://cepii.fr/CEPII/en/bdd mo dele/bdd mo dele item.asp?id=8 10 4.1 Benc hmark The purp ose of the b enc hmark analysis is to ev aluate the abilit y of the ST AR metho d to select a representativ e partition that is b oth structurally meaningful and consistent with the underlying communit y organization, in a setting where the ground truth is kno wn. Synthetic b enc hmarks allow us to isolate the effect of partition selection from confounding factors and to systematically in vestigate ho w p erformance c hanges as comm unities become increasingly mixed. T o this end, we rely on LFR b enc hmark netw orks, which are sp ecifically designed to repro duce key statistical prop erties of real-w orld netw orks – suc h as heterogeneous degree distributions and comm unity sizes – while providing a well-defined plan ted partition. F or each v alue of the mixing parameter µ ∈ { 0 . 1 , 0 . 2 , . . . , 0 . 9 } , whic h con trols the fraction of inter-comm unity links and thus the level of communit y fuzziness, w e generate 100 indep enden t net works with 1000 nodes. All remaining parameters are fixed across realizations in order to isolate the effect of increasing µ . The chosen parameter configuration follo ws standard practice in the literature and is consistent with previous b enc hmark studies on CC ( Lancic hinetti & F ortunato , 2012 ), ensuring that observed differences are not driven by idiosyncratic settings. F or each netw ork realization, we generate an ensemble of candidate partitions by running the Louv ain algorithm 150 times. This step reflects the intrinsic sto chasticit y and degeneracy of mo dularit y maximization: even on the same net work, rep eated optimizations typically yield multiple near-optimal but structurally distinct solutions. F rom each ensemble of partitions, a single represen tative solution is extracted using the ST AR metho d and, for comparison, the CC. Once a representativ e partition is selected for each netw ork realization, its quality is assessed by comparing it with the planted ground-truth partition using ARI. F or eac h v alue of µ , this results in 100 ARI v alues per metho d. F ollowing standard practice in the communit y-detection literature ( F ortunato , 2010 ), we summarize these results b y rep orting the mean ARI as a function of µ . This allows us to explicitly track how the accuracy of the representativ e partition deteriorates as comm unities b ecome less w ell defined. The corresp onding curv es are rep orted in Fig. 1 , panel (a) together with the standard deviation (shaded areas). In parallel, we ev aluate the mo dularity asso ci- ated with the representativ e partitions selected by each metho d. F or eac h v alue of µ , mean mo dularit y v alues are computed o ver the 100 realizations and rep orted in Fig. 1 , panel (b). This second set of results is crucial to assess whether selecting a represen- tativ e partition comes at the cost of a substantial loss in modularity , or whether high represen tativeness can b e ac hieved while remaining close to the mo dularity optimum. T o further contextualize the benchmark results, w e additionally consider teo purely mo dularit y-driv en selection criteria, whereby the representativ e partition is chosen as the one with the highest mo dularity and the one app earing most frequently among the 150 Louv ain runs. F or these baselines, we compute b oth the ARI with resp ect to the ground truth and the corresponding mo dularit y v alues, and include the resulting a verages and standard deviations in Fig. 1 , panels (a)–(b). These comparisons high- ligh t the extent to whic h maximizing mo dularity alone or choosing the most frequen t partition as the most represen tative one ma y lead to clusters that are less faithful to 11 the underlying communit y structure, despite achieving marginally higher mo dularit y scores. Finally , we in vestigate the robustness of the ST AR metho d with respect to the size of the partition e nsem ble. Sp ecifically , we rep eat the en tire pro cedure using only 50 Louv ain runs instead of 150. (a) (b) Fig. 1 The parameters of the LFR benchmark graphs are: av erage degree = 20, maxim um degree = 50, minimum comm unity size = 10, maxim um comm unity size = 50, degree exp onen t = 2, and communit y size exp onen t = 3. The results provide a clear picture of how different selection criteria b eha ve as the lev el of communit y mixing increases. As sho wn in panel (a), for lo w v alues of µ , all methods ac hieve similarly high ARI v alues , indicating that when communities are well separated the degeneracy of mo dularit y maximization is limited and differen t represen tative partitions largely coincide. As µ increases and the planted communit y structure becomes progressively less pronounced, differences b et w een selection strate- gies emerge. In this regime, CC achiev es the highest agreement with the ground truth. The ST AR metho d closely trac ks the consensus performance across the en tire range of µ , with only marginal deviations, showing that ST AR is able to capture essentially the same structural information despite relying on a muc h simpler selection mecha- nism. Notably , reducing the num b er of input partitions from 150 to 50 has a negligible impact on ST AR performance, as b oth ARI v alues and standard deviations (shaded areas) remain virtually unchanged. This indicates that the metho d is robust and do es not require large ensembles of candidate partitions to yield reliable results. In con- trast, selecting the partition solely based on maximum mo dularit y , as well as choosing the most frequently o ccurring partition among Louv ain runs, leads to systematically p oorer agreement with the plan ted structure. P anel (b) rep orts the mo dularit y v alues asso ciated with the representativ e parti- tions. F or lo w and in termediate v alues of µ (up to appro ximately µ = 0 . 7), all methods yield almost identical mo dularit y scores. F or larger v alues of µ , CC exhibits sligh tly lo wer mo dularit y v alues, although differences o ccur where mo dularit y is already low for all methods. 12 Ov erall, the benchmark analysis shows that the ST AR metho d provides a reliable and robust criterion for selecting represen tative partitions in mo dularit y-based CD. It achiev es accuracy comparable to CC while maintaining mo dularit y v alues close to the optim um, and remains effective ev en with a substantially reduced num b er of input partitions. These results supp ort the use of ST AR as a practical alternativ e for representativ e partition se lection in settings characterized by strong mo dularity degeneracy . 4.2 Real Data After v alidating the prop osed selection pro cedure on LFR b enc hmark netw orks, we apply the m ethod to t wo real-world systems, namely the WTW and the FTSE100 correlation netw ork.In the WTW case, communities are iden tified using the Louv ain algorithm, producing an ensem ble of 150 partitions. W e then select a representativ e solution according to three criteria: CC, ST AR, and the partition attaining the max- im um mo dularit y . In the second case, the presence of negativ e weigh ts preven ts the application of CC; hence, only the ST AR partition and the maximum-modularity partition are considered. 4.2.1 The W orld T rade W eb The WTW considered in this application refers to the y ear 2015 and includes 193 no des, representing coun tries, connected by 26,015 directed and weigh ted links. The resulting net work is highly dense, with a link density of appro ximately 0.7, and encodes a total trade volume of 1 . 19 × 10 10 US dollars. These structural features are kno wn to p ose challenges for CD, particularly for mo dularit y-based approac hes. Indeed, multiple candidate partitions are obtained from rep eated Louv ain runs. The ST AR selection criterion and the consensus-based approach consistently iden tify the same partition (hereafter ST AR/Consensus partition), while the partition maximizing the standard mo dularit y function (Max-mod partition) differs from the ST AR-consensus solution. This discrepancy highlights the well-kno wn tendency of mo dularit y maximization to fa vor large and weakly structured communit ies in dense and highly heterogeneous net works suc h as International T rade. The ST AR/Consensus partition displays a geographically coheren t and economi- cally interpretable communit y structure. North America forms a unified blo c k, South America is largely group ed into a single cluster cen tered on Brazil and its regional trade partners, and Europe app ears as a w ell-defined and compact communit y . Asia is split in to tw o ma jor blo c ks, broadly distinguishing East Asia and Oceania from South and Cen tral Asia, while Sub-Saharan Africa exhibits a differen tiated structure consistent with known trade patterns. Overall, the partition reflects well-documented regional trade integration patterns in the WTW, such as the strong in tra-Europ ean trade core, the North American in tegration, and the regional clustering of South American economies. In con trast, the maxim um-mo dularit y partition app ears less aligned with established economic geograph y . While Europ e and North America remain coheren t clusters, large parts of Africa and Asia are aggregated into broader and less economi- cally homogeneous communities. In particular, several African economies are merged 13 (a) ST AR/Consensus partition ( Q = 0 . 2649) (b) Max-mo d partition ( Q = 0 . 2720) Fig. 2 W orld T rade W eb 2015. Countries are colored according to the communities identified by (a) the ST AR/consensus metho d and (b) the maximum mo dularit y criterion. in to a single large block despite substantial heterogeneity in their trade link ages, and parts of Asia are group ed in a wa y that blurs the distinction b et ween ma jor regional trade h ubs. Although this partition ac hieves the highest mo dularit y v alue, it does so at the cost of reduced economic interpretabilit y and w eaker corresp ondence with kno wn regional trade agreemen ts and trade intensit y patterns. T aken together, these results illustrate the w ell-known degeneracy of the mo dular- it y landscap e: partitions with v ery similar modularity v alues ma y differ substantially in their structural comp osition. In the WTW case, the ST AR-selected partition app ears 14 more consistent with established trade blo cs and regional in tegration patterns, suggest- ing that maximizing modularity alone do es not necessarily yield the most economically meaningful communit y structure. 4.2.2 FTSE100 sto ck mark et The second application concerns the FTSE100 equit y mark et, represen ted as a w eighted net work of sto cks, where no des corresp ond to companies included in the FTSE100 index and links encode pairwise correlations betw een their return time series. Suc h financial netw orks are known to exhibit strong heterogeneity and high lev els of in terconnectedness, making them a relev ant test case for CD and selection methods .W e selected all sto c ks for which complete data are av ailable during the perio d under study ending up with 93 stocks. They can be classified in ten top-lev el ”sectors”: Basic Materials, Consumer Discretion, Consumer Staples, Energy , Financials, Health Care, Industrials T ec hnology , T elecommunications, Utilities. The filtered correlation matrix contains negative v alues, which mak es standard CC pro cedures not directly applicable and motiv ates the use of ST AR in this setting. In Figure 3 , panel (a), we report the histogram of mo dularit y v alues ov er 150 parti- tions obtained with Louv ain algorithm confirming the degeneracy problem. The ST AR metho d returns a representativ e partition that differs from the one asso ciated with the maximum mo dularit y v alue among the 150 detected partitions. The difference in mo dularit y is negligible (∆ Q = 0 . 0087); ho wev er, the resulting comm unity structures differ b oth in num b er and comp osition, with ST AR identifying four comm unities and the maximum-modularity solution yielding five clusters (Figure 3 , panels (b)–(c)). The ST AR partition exhibits a clearer sectoral organization (Figure 3 , panel (b)). Financial firms are more coheren tly grouped, Industrials form a dominant and w ell- defined blo c k, and defensive sectors such as Consumer Staples and Utilities tend to cluster together. Ov erall, the resulting comm unities display lo wer in ternal sectoral heterogeneit y and align more closely with standard GICS classifications an d with w ell- established patterns of sectoral co-mo vemen t in equit y mark ets. This suggests that the ST AR pro cedure selects a partition that is structurally central within the ensemble and economically in terpretable in terms of common risk exp osures. By contrast, the maxim um-mo dularit y partition, while optimizing the graph- theoretic ob jective function, pro duces a more fragmented sectoral structure (Figure 3 , panel (c)). Although Financials remain prominen t, several comm unities mix heteroge- neous sectors, and sectoral concentration app ears less pronounced. This is consisten t with the fact that mo dularit y maximization iden tifies an extremal solution in the ob jective landscap e, which do es not necessarily coincide with the most represen ta- tiv e or economically coheren t configuration when the mo dularit y surface is highly degenerate. T aken together, the comparison highlights that, in correlation-based financial net- w orks, maximizing mo dularity and selecting a structurally central partition ma y lead to different outcomes. In such near-degenerate settings, the ST AR criterion pro vides a partition that b etter reflects kno wn economic structure, whereas the maximum- mo dularit y solution strictly optimizes the ob jective function without imp osing additional stability considerations, while CC is not appliable. 15 (a) Histogram of mo dularit y v alues. (b) ST AR partition ( Q = 0 . 3654). (c) Maximum-modularity partition ( Q = 0 . 3741). Fig. 3 Communities of FTSE100 market. Partitions are generated using the Louv ain algorithm on the filtered correlation matrix (REF) for 150 runs. (a) Histogram of the mo dularity v alues asso- ciated to the 150 partitions. Comm unity organization in sectors of (b) the representativ e partition obtained with the ST AR metho d and (c) the partition asso ciated to the maximum mo dularit y v alue. 5 Discussion In this paper we introduce a simple and user-friendly post-pro cessing method designed to supp ort the selection of a represen tative partition among the degenerate solutions 16 pro duced by mo dularit y-based CD algorithms. The prop osed approach is delib erately mo del-agnostic: it can b e applied a p osteriori to any CD metho d relying on modular- it y maximization and is indep endent of the sp ecific optimization heuristic emplo yed. Moreo ver, it is applicable to any netw ork top ology , including weigh ted, directed, and signed netw orks. The motiv ation for dev eloping such a method stems from w ell-known limitations of mo dularit y maximization. Despite its widespread use, the mo dularit y function is c har- acterized by a highly rugged optimization landscap e, where an exp onen tial num b er of structurally distinct partitions may exhibit similar or nearly iden tical mo dularit y v alues. As a consequence, the notion of a single “b est” partition – identified solely as the global or lo cal maximizer of mo dularity – is often ill-defined. In practice, optimal or near-optimal solutions may be unstable across runs, sensitiv e to algorithmic ran- domness, or even asso ciated with comm unity structures that are difficult to interpret from a modeling or empirical p ersp ectiv e. F or this reason, our approach do es not aim at identifying the best partition in terms of mo dularit y v alue. Instead, it seeks a representativ e partition, namely a solu- tion that captures the most robust and recurren t structural features of the ensem ble of high-mo dularit y partitions. This conceptual shift reflects the idea that, in complex net- w orks, a meaningful description of the system should prioritize structural consistency and interpretabilit y ov er marginal improv ements in an ob jective function. Similar considerations ha ve motiv ated the developmen t of CC metho ds ( Lancichinetti & F or- tunato , 2012 ), which aim to extract a stable partition summarizing a set of comp eting solutions. W e explicitly compare our method with CC because b oth approaches pursue the same o verarc hing goal: selecting a partition that is representativ e of the under- lying netw ork structure rather than arbitrarily choosing among degenerate optima. Our results sho w that the partitions obtained with the prop osed metho d are highly consisten t with those pro duced by CC, b oth in terms of communit y comp osition and structural coherence. Imp ortan tly , this is ac hieved through a substan tially simpler pro cedure, which does not require the construction of auxiliary netw orks or the use of additional optimization steps, and can b e implemen ted using standard outputs of mo dularit y-based algorithms without relying on external pack ages. Bey ond simplicity , a k ey adv antage of the proposed metho d lies in its general- it y . Standard CC techniques are typically defined for non-negative edge weigh ts and therefore cannot b e directly applied to net works with negative weigh ts. This limita- tion excludes a wide class of relev ant applications, including signed so cial netw orks, correlation-based netw orks in finance, neuroscience, and climatology , as w ell as an y setting in which p ositiv e and negative interactions co exist. In con trast, our metho d naturally extends to netw orks with both positive and negativ e w eights, thereby provid- ing a unified framew ork for partition selection across a broad sp ectrum of real-w orld problems. Ov erall, the contribution of this w ork is t wofold. First, w e offer a parsimonious and easily implemen table to ol for selecting representativ e communit y structures without sacrificing the quality of the results typically obtained b y more elab orate consensus- based approaches. Second, we extend the applicability of represen tativ e partition 17 selection to all t yp es of net works, including signed net works, thus broadening the scop e of mo dularit y-based CD in b oth theoretical and applied contexts. 6 Conclusion In this pap er w e addressed one of the central challenges of mo dularit y-based commu- nit y detection, namely the degeneracy of high-mo dularit y partitions and the resulting am biguity in the selection of a meaningful comm unit y structure. Rather than pursuing the iden tification of a single optimal solution, we prop osed a simple p ost-pro cessing metho d aimed at selecting a representativ e partition that captures the most robust structural features shared across degenerate mo dularit y-maximizing solutions. The prop osed approach can b e applied a p osteriori to the output of an y mo dularit y-based comm unity detection metho d. By fo cusing on representativ eness rather than optimal- it y , the metho d pro vides a stable and interpretable alternativ e to the selection of a “b est” partition in contexts where the mo dularit y landscap e is highly rugged and near-optimal solutions are structurally div erse. A key strength of the prop osed frame- w ork lies in its simplicit y and generality . Compared with consensus clustering, which pursues a similar ob jective, our metho d achiev es comparable results through a substan- tially simpler pro cedure. Moreo ver, unlik e standard consensus-based approac hes, the metho d naturally extends to net works with b oth p ositiv e and negativ e edge w eights, making it suitable for signed net works and correlation-based systems that arise in a wide range of applications, including social, financial, and neuroscience netw orks. The numerical exp eriments confirm that the representativ e partitions selected b y the prop osed method are structurally coheren t, robust across realizations, and consisten t with those obtained through more elab orate stabilization tec hniques. These results suggest that the metho d provides a practical and reliable tool for handling degener- acy in mo dularit y-based communit y detection without sacrificing the quality of the inferred communit y structure. Ac knowledgemen ts. R.M ac knowledges supp ort from the PRIN 2022 pro ject “The Role of the Public and Priv ate Sectors in Pharmaceutical Breakthrough Innov a- tions (3PBI)” (CUP 2022S4EAS9). R.M. is member of GNAMP A (Grupp o Nazionale p er l’Analisi Matematica, la Probabilit‘a e le loro Applicazioni) at INdAM (Istituto Nazionale di Alta Matematica). Declarations • F unding. No funding was received for conducting this study . • Conflict of in terest/Comp eting interests. The authors hav e no relev ant finan- cial or non-financial interests to disclose. • Data a v ailability . T rade data are publicly av ailable from the CEPI I database h ttps://cepii.fr/CEPI I/en/b dd mo dele/b dd modele item.asp?id=8 . Financial data are accessed through a p ersonalized license agreemen t with the LSEG database at the Universit y of T urin and cannot b e shared due to licensing restrictions. 18 • Co de av ailability . ht tps://github.com/RossanaMastrandrea/ST AR-partition • Author con tribution. The authors contributed equally to this w ork. References Abb e, E. (2018, 06). Communit y detection and sto c hastic blo c k mo dels. F ounda- tions and T r ends in Communic ations and Information The ory , 14 (1-2), 1-162, h ttps://doi.org/10.1561/0100000067 Almog, A., Besamusca, F., MacMahon, M., Garlaschelli, D. (2015). Mesoscopic comm unity structure of financial markets revealed by price and sign fluctua- tions. Plos one , 10 (7), , https://doi.org/h ttps://doi.org/10.1371/journal.p one .0133679 Aref, S., Mosta jab dav eh, M., Chheda, H. (2023). Heuristic Mo dularit y Maximization Algorithms for Communit y Detection Rarely Return an Optimal Partition or An ything Similar. International Confer enc e on Optimization and L e arning (OL 2023). Bargigli, L., & Gallegati, M. (2013). Finding communities in credit netw orks. Ec onomics , 7 (1), 20130017, h ttps://doi.org/doi:10.5018/economics-ejournal.ja .2013-17 Barigozzi, M., F agiolo, G., Mangioni, G. (2011). Identifying the communit y structure of the international-trade multi-net w ork. Physic a A: statistic al me chanics and its applic ations , 390 (11), 2051–2066, Bazzi, M., P orter, M.A., Williams, S., McDonald, M., F enn, D.J., Howison, S.D. (2016). Communit y detection in temporal multila y er netw orks, with an appli- cation to correlation netw orks. Multisc ale Mo deling and Simulation , 14 (1), , h ttps://doi.org/https://doi.org/10.1137/15M1009615 Bedi, P ., & Sharma, C. (2016). Comm unity detection in social netw orks. WIREs Data Mining and Know le dge Disc overy , 6 (3), 115-135, https://doi.org/h ttps:// doi.org/10.1002/widm.1178 Blondel, V.D., Guillaume, J.-L., Lambiotte, R., Lefeb vre, E. (2008). F ast unfolding of communities in large netw orks. Journal of Statistic al Me chanics: The ory and Exp eriment , 2008 (10), P10008, h ttps://doi.org/10.1088/1742-5468/2008/10/ P10008 19 Brandes, U., Delling, D., Gaertler, M., Gork e, R., Hoefer, M., Nik oloski, Z., W agner, D. (2008). On mo dularit y clustering. IEEE T r ansactions on Know le dge and Data Engine ering (V ol. 20, pp. 172–188). Calata yud, J., Bernardo-Madrid, R., Neuman, M., Ro jas, A., Rosv all, M. (2019). Exploring the solution landscape enables more reliable netw ork communit y detection. Physic al R eview E , 100 , 052308, h ttps://doi.org/https://doi.org/ 10.1103/Ph ysRevE.100.052308 Chen, M., Kuzmin, K., Szymanski, B.K. (2014). Comm unity detection via maximiza- tion of modularity and its v ariants. IEEE T r ansactions on Computational So cial Systems , 1 (1), 46-65, https://doi.org/10.1109/TCSS.2014.2307458 Danon, L., Diaz-Guilera, A., Duc h, J., Arenas, A. (2005). Comparing comm u- nit y structure identification. Journal of statistic al me chanics: The ory and exp eriment , 2005 (09), P09008, De Meo, P ., F errara, E., Fiumara, G., Pro vetti, A. (2011). Generalized louv ain method for comm unity detection in large net works. 2011 11th international c onfer enc e on intel ligent systems design and applic ations (p. 88-93). Drago, C., & Ricciuti, R. (2017). Communities detection as a tool to assess a reform of the italian interlocking directorship netw ork. Physic a A: Statistic al Me chanics and its Applic ations , 466 , 91–104, Economou, K.N., Norman, C.R., Gentleman, W.C. (2025). Identifying robust fea- tures of communit y structure in complex netw orks. Physic al R eview E , 111 (4), 044303, h ttps://doi.org/10.1103/PhysRevE.111.044303 F ortunato, S. (2010). Communit y detection in graphs. Physics r ep orts , 486 (3-5), 75–174, F ortunato, S., & Barth´ elem y , M. (2007). Resolution limit in communit y detection. Pr o c e e dings of the National A c ademy of Scienc es , 104 (1), 36–41, h ttps://doi .org/10.1073/pnas.0605962104 F ortunato, S., & Hric, D. (2016). Comm unity detection in netw orks: A user guide. Physics R ep orts , 659 , 1–44, https://doi.org/10.1016/j.ph ysrep.2016.09.002 20 Go od, B.J., de Montjo ye, Y.A., Clauset, A. (2010). Performance of mo dularit y max- imization in practical con texts. Physic al R eview E , 81 (4), , h ttps://doi.org/ 10.1103/ph ysreve.81.046106 Grassi, R., Bartesaghi, P ., Benati, S., Clemente, G.P . (2021). Multi-attribute comm unity detection in international trade net work. Netw Sp at Ec on , 21 , , h ttps://doi.org/https://doi.org/10.1007/s11067-021-09547-4 Guimer` a, R., & Amaral, L.A.N. (2005, feb). Cartography of complex netw orks: mo dules and universal roles. Journal of Statistic al Me chanics: The ory and Exp eriment , 2005 (02), P02001, h ttps://doi.org/10.1088/1742-5468/2005/02/ P02001 Gulbahce, N., & Lehmann, S. (2008). The art of comm unity detection. BioEssays , 30 (10), 934-938, h ttps://doi.org/https://doi.org/10.1002/bies.20820 Heemsk erk, E.M., Daolio, F., T omassini, M. (2013). The communit y structure of the europ ean netw ork of interlocking directorates 2005–2010. PloS one , 8 (7), e68581, Hub ert, L., & Arabie, P . (1985). Comparing partitions. Journal of classific ation , 2 (1), 193–218, Jin, D., Y u, Z., Jiao, P ., P an, S., He, D., W u, J., . . . Zhang, W. (2023). A Surv ey of Comm unity Detection Approaches: F rom Statistical Mo deling to Deep Learn- ing. IEEE T r ansactions on Know le dge and Data Engine ering , 35 (1), 159–179, h ttps://doi.org/10.1109/TKDE.2021.3104155 Karatas, A., & S ¸ ahin, S. (2018). Application areas of communit y detection: A review. 2018 international c ongr ess on big data, de ep le arning and fighting cyb er terr orism (ibigdelft) (p. 65-70). Khadivi, A., Ajdari Rad, A., Hasler, M. (2011, Apr). Netw ork comm unity-detection enhancemen t by proper w eighting. Phys. R ev. E , 83 , 046104, https://doi.org/ 10.1103/Ph ysRevE.83.046104 Lancic hinetti, A., & F ortunato, S. (2011). Limits of mo dularit y maximization in comm unity detection. Physic al R eview E , 84 (6), 066122, h ttps://doi.org/ 10.1103/Ph ysRevE.84.066122 21 Lancic hinetti, A., & F ortunato, S. (2012). Consensus clustering in complex netw orks. Scientific R ep orts , 2 , 336, https://doi.org/10.1038/srep00336 Lancic hinetti, A., F ortunato, S., Radicchi, F. (2008). Benchmark graphs for testing comm unity detection algorithms. Physic al R eview E , 78 , 046110, Li, J., Lai, S., Shuai, Z., T an, Y., Jia, Y., Y u, M., . . . Lu, Y. (2024). A comprehen- siv e review of communit y detection in graphs. Neur o c omputing , 600 , 128169, h ttps://doi.org/https://doi.org/10.1016/j.neucom.2024.128169 Retrieved from h ttps://www.sciencedirect.com/science/article/pii/S0925231224009408 Liu, H., W ei, J., Xu, T. (2023). Communit y detection based on comm unity p erspec- tiv e and graph conv olutional netw ork. Exp ert Systems with Applic ations , 231 , 120748, h ttps://doi.org/https://doi.org/10.1016/j.esw a.2023.120748 MacMahon, M., & Garlaschelli, D. (2015). Comm unity detection for correlation matrices. Physic al R eview X , 5 (2), 021006, Mastrandrea, R., Amato, S., P atuelli, A. (2025). The con text matters: A netw ork p erspective on in terlo c king directorates in italian man ufacturing firms. Networks and Sp atial Ec onomics , 1–32, Mazzarisi, P ., Rav agnani, A., Deriu, P ., Lillo, F., Medda, F., Russo, A. (2024). A mac hine learning approach to support decision in insider trading detection. EPJ Data Sci. , 13 (66), , h ttps://doi.org/https://doi.org/10.1140/ep jds/s13688-024 -00500-2 Meil˘ a, M. (2007). Comparing clusterings—an information based distance. Journal of multivariate analysis , 98 (5), 873–895, Musmeci, N., Aste, T., Di Matteo, T. (2015). Relation betw een financial market structure and the real econom y: Comparison b et w een clustering metho ds. PL oS ONE , 10 (3), , https://doi.org/h ttps://doi.org/10.1371/journal.p one.0116201 Newman, M. (2018). Networks . Oxford universit y press. 22 Newman, M.E.J. (2004, Jun). F ast algorithm for detecting comm unity structure in net works. Phys. R ev. E , 69 , 066133, https://doi.org/10.1103/Ph ysRevE.69 .066133 Newman, M.E.J. (2006). Mo dularit y and communit y structure in netw orks. Pr o c e e d- ings of the National A c ademy of Scienc es , 103 (23), 8577–8582, h ttps://doi.org/ 10.1073/pnas.0601602103 Newman, M.E.J., & Girv an, M. (2004). Finding and ev aluating communit y struc- ture in netw orks. Physic al R eview E , 69 (2), 026113, h ttps://doi.org/10.1103/ Ph ysRevE.69.026113 P eixoto, T.P . (2021, Apr). Revealing consensus and dissensus b et ween netw ork parti- tions. Phys. R ev. X , 11 , 021003, h ttps://doi.org/10.1103/PhysRevX.11.021003 Retriev ed from https://link.aps.org/doi/10.1103/Ph ysRevX.11.021003 P´ osfai, M., & Barab´ asi, A.-L. (2016). Network scienc e (V ol. 3). Cambridge Univ ersity Press Cambridge, UK:. Ric hardson, T., Mucha, P .J., Porter, M.A. (2009, Sep). Sp ectral tripartitioning of net works. Phys. R ev. E , 80 , 036111, https://doi.org/10.1103/Ph ysRevE.80 .036111 Retriev ed from https://link.aps.org/doi/10.1103/Ph ysRevE.80.036111 Safdari, H., & De Bacco, C. (2022). Anomaly detection and communit y detection in netw orks. J Big Data , 9 (122), , https://doi.org/h ttps://doi.org/10.1186/ s40537-022-00669-1 Shai, S., Stanley , N., Granell, C., T aylor, D., Muc ha, P .J. (2021, 01). Case studies in net work comm unity detection. The oxfor d handb o ok of so cial networks. Oxford Univ ersity Press. Siudak, D. (2023). Cohesion and segregation in the v alue migration net work: Evidence from net work partitioning based on sector classification and clustering. So c. Netw. Anal. Min. , 12 (26), , h ttps://doi.org/https://doi.org/10.1007/s13278 -023-01027-6 Vinh, N.X., Epps, J., Bailey , J. (2009). Information theoretic measures for clusterings comparison: is a correction for chance necessary? Pr o c e e dings of the 26th annual international c onfer enc e on machine le arning (pp. 1073–1080). 23 Y uan, S., Zeng, H., Zuo, Z., W ang, C. (2023). Overlapping communit y detection on complex net works with graph conv olutional netw orks. Computer Communic a- tions , 199 , 62-71, https://doi.org/h ttps://doi.org/10.1016/j.comcom.2022.12 .008 Zanin, M., Papo, D., Sousa, P ., Menasalv as, E., Nicchi, A., Kubik, E., Boccaletti, S. (2016). Com bining complex netw orks and data mining: Wh y and how. Physics R ep orts , 635 , 1-44, https://doi.org/h ttps://doi.org/10.1016/j.physrep.2016.04 .005 Zhang, P ., & Mo ore, C. (2014). Scalable detection of statistically significant commu- nities and hierarc hies, using message passing for mo dularit y . Pr o c e e dings of the National A c ademy of Scienc es , 111 (51), 18144–18149, h ttps://doi.org/10.1073/ pnas.1412592111 Zhang, W., Shang, R., Li, Z., Sun, R., Du, J. (2023). P ersonalized w eb page ranking based graph con volutional netw ork for communit y detection in attribute net- w orks. IEEE A c c ess , 11 , 84270-84282, h ttps://doi.org/10.1109/ACCESS.2023 .3303210 24
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment