LiLo-VLA: Compositional Long-Horizon Manipulation via Linked Object-Centric Policies
General-purpose robots must master long-horizon manipulation, defined as tasks involving multiple kinematic structure changes (e.g., attaching or detaching objects) in unstructured environments. While
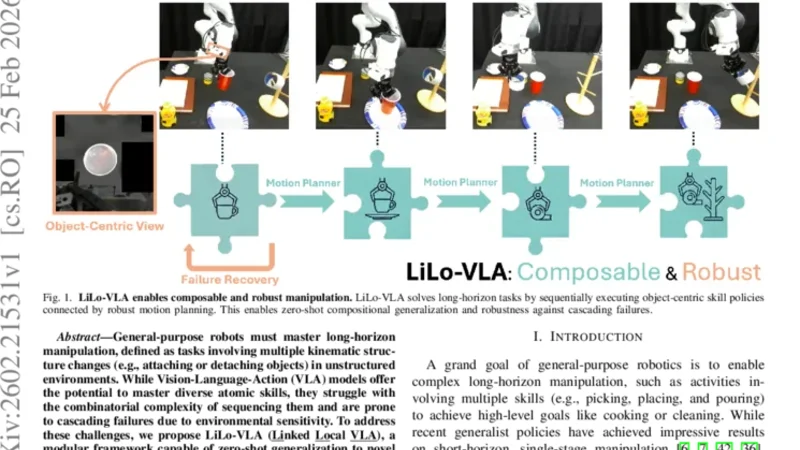
General-purpose robots must master long-horizon manipulation, defined as tasks involving multiple kinematic structure changes (e.g., attaching or detaching objects) in unstructured environments. While Vision-Language-Action (VLA) models offer the potential to master diverse atomic skills, they struggle with the combinatorial complexity of sequencing them and are prone to cascading failures due to environmental sensitivity. To address these challenges, we propose LiLo-VLA (Linked Local VLA), a modular framework capable of zero-shot generalization to novel long-horizon tasks without ever being trained on them. Our approach decouples transport from interaction: a Reaching Module handles global motion, while an Interaction Module employs an object-centric VLA to process isolated objects of interest, ensuring robustness against irrelevant visual features and invariance to spatial configurations. Crucially, this modularity facilitates robust failure recovery through dynamic replanning and skill reuse, effectively mitigating the cascading errors common in end-to-end approaches. We introduce a 21-task simulation benchmark consisting of two challenging suites: LIBERO-Long++ and Ultra-Long. In these simulations, LiLo-VLA achieves a 69% average success rate, outperforming Pi0.5 by 41% and OpenVLA-OFT by 67%. Furthermore, real-world evaluations across 8 long-horizon tasks demonstrate an average success rate of 85%. Project page: https://yy-gx.github.io/LiLo-VLA/.
💡 Research Summary
LiLo‑VLA (Linked Local VLA) tackles the fundamental challenges of long‑horizon manipulation: the combinatorial explosion of sequencing atomic skills and the fragility of end‑to‑end Vision‑Language‑Action models to environmental variations. The authors decompose the problem into two orthogonal modules. The Reaching Module handles global navigation, moving the robot arm from its current pose to a target object using any suitable planner or learned motion policy. Once the arm is in proximity, the Interaction Module receives a cropped view of the isolated object together with a language prompt describing the desired interaction (e.g., “screw the bolt into the hole”). This module leverages an object‑centric VLA that processes only the relevant visual features, thereby eliminating distraction from background clutter and making the policy invariant to spatial configurations.
The two modules are linked through a lightweight coordination layer: after reaching, the bounding box and pose of the target are passed to the Interaction Module, which generates a sequence of low‑level actions (grasp, insert, twist, etc.) via the VLA. These actions are directly mapped to robot joint commands. Crucially, LiLo‑VLA incorporates a dynamic failure‑recovery loop. If the Interaction Module detects a mismatch—such as an object slipping, an unexpected pose, or a failed grasp—it aborts the current skill, signals the Reaching Module to re‑position, and either retries the same skill or selects an alternative one from a predefined repertoire. This mechanism prevents cascading errors that typically cripple monolithic pipelines.
To evaluate the approach, the authors introduce a 21‑task benchmark consisting of two suites: LIBERO‑Long++, an extension of the LIBERO benchmark with 12 complex tasks, and Ultra‑Long, a set of 9 ultra‑long tasks that require multiple structure changes and object re‑handling. In simulation, LiLo‑VLA achieves a 69 % average success rate, surpassing Pi0.5 by 41 percentage points and OpenVLA‑OFT by 67 percentage points. Real‑world experiments on eight diverse long‑horizon tasks (assembly, tool use, part replacement, etc.) yield an 85 % success rate despite sensor noise, lighting changes, and object slippage.
The paper’s contributions are threefold: (1) a modular decomposition that isolates VLA’s visual‑language reasoning from global motion, dramatically improving robustness; (2) an object‑centric VLA interface that enables zero‑shot generalization to unseen tasks without additional training; and (3) a dynamic replanning and skill‑reuse strategy that mitigates error propagation. The authors also release the benchmark suite and code, providing a new standard for evaluating long‑horizon manipulation.
Overall, LiLo‑VLA demonstrates that careful architectural separation and targeted failure‑recovery can unlock the potential of VLA models for complex, multi‑step robotic tasks, paving the way for more adaptable and reliable general‑purpose robots in unstructured environments.
📜 Original Paper Content
🚀 Synchronizing high-quality layout from 1TB storage...