Group Orthogonalized Policy Optimization:Group Policy Optimization as Orthogonal Projection in Hilbert Space
We present Group Orthogonalized Policy Optimization (GOPO), a new alignment algorithm for large language models derived from the geometry of Hilbert function spaces. Instead of optimizing on the probability simplex and inheriting the exponential curv…
Authors: Wang Zixian
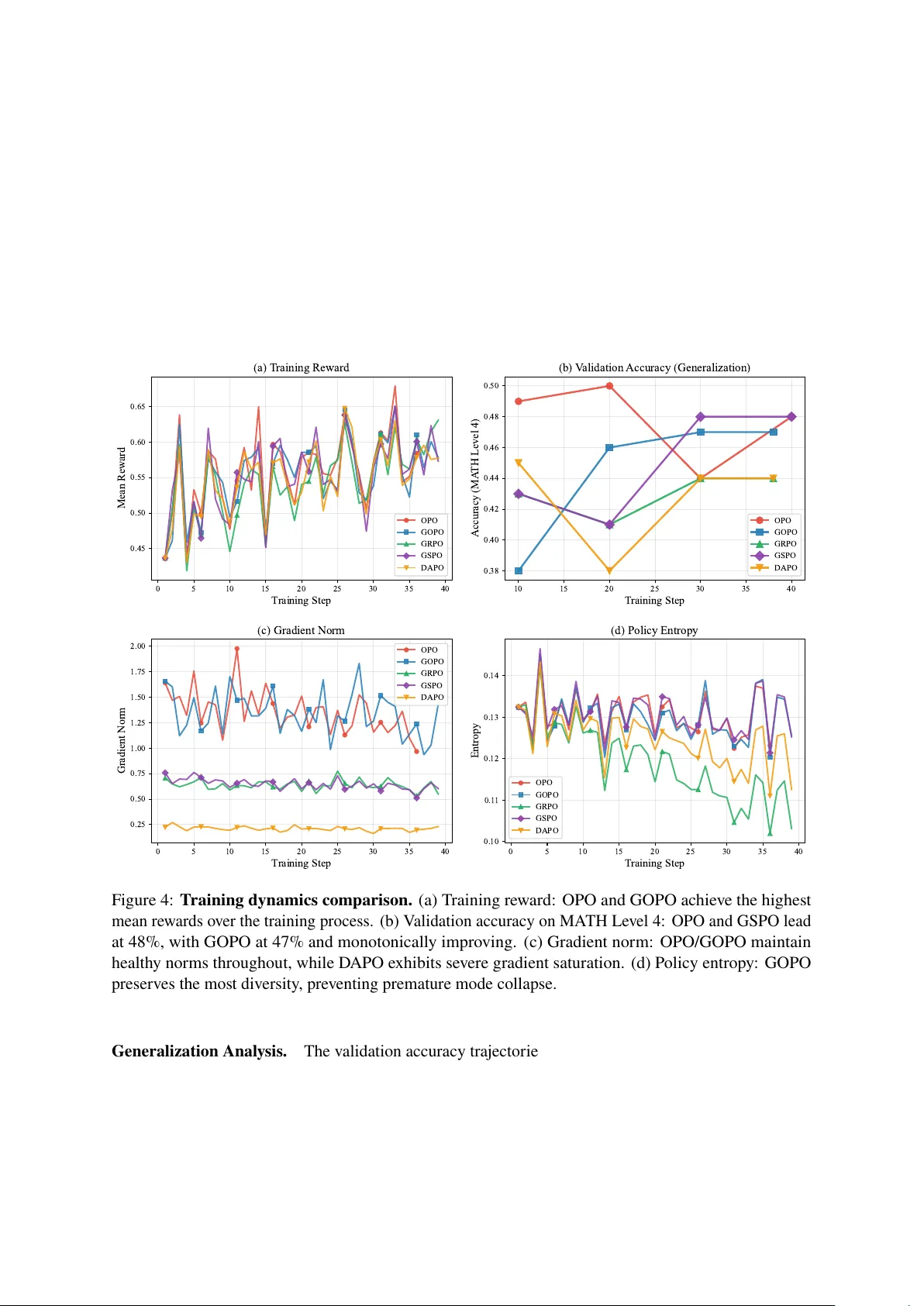
Gr oup Orthogonalized P olicy Optimization Group P olicy Optimization as Or thogonal Projection in Hilber t Space W ang Zixian China Mobile Communications Group Shandong Co., Ltd. T ai’an Branch wangzixian@sd.chinamobile.com Abstract W e present Group Orthogonalized P olicy Optimization (GOPO) , a new alignment algorithm f or larg e language models der iv ed entirel y from the geometry of Hilber t function spaces. Unlik e e xisting methods that f ormulate alignment as constrained optimization on the probability simplex—ine vitably inheriting the exponential curvature of Kullback –Leibler diver g ence—w e propose a fundamentall y different approach: lifting the problem into the Hilber t space 𝐿 2 ( 𝜋 𝑘 ) of square-integrable functions with respect to the current reference policy . In this function space, we make three obser vations that jointly yield a principled algor ithm. First, the probability simplex constraint reduces to a single linear or thogonality condition ⟨ 𝑣 , 1 ⟩ = 0 , defining a codimension-one closed subspace H 0 . Second, the alignment objective emer g es naturally from the Geometric Principle of Minimum Distance : minimizing the geometric distance betw een 𝑣 and the unconstrained tar g et 𝑢 ∗ algebraicall y yields the wor k -dissipation functional J ( 𝑣 ) = ⟨ 𝑔, 𝑣 ⟩ − 𝜇 2 ∥ 𝑣 ∥ 2 . The global maximum of this functional is then giv en elegantl y by the Hilbert Projection Theorem. Third, enf orcing the non-negativity boundary 𝑣 ≥ − 1 upgrades the solution to a Bounded Hilbert Pr ojection (BHP), yielding ex act sparsity : catastrophicall y poor actions receiv e zero targ et probability via a hard analytical threshold. T o br idge the gap betw een this global functional theor y and practical training, GOPO transitions the projection from the infinite-dimensional 𝐿 2 ( 𝜋 𝑘 ) to a finite-dimensional empirical subspace induced b y group sampling. A ke y structural result emerges: because g roup-nor malized adv antag es inherentl y sum to zero, the Lagrange multiplier (chemical potential) enforcing probability conser vation exactly vanishes , collapsing the constrained projection into an unconstrained empirical loss. The resulting objectiv e features constant Hessian curvature 𝜇 𝐼 , non-saturating linear gradients, and an intrinsic dead-zone mec hanism—all without heuristic clipping. Experiments on mathematical reasoning benchmarks demonstrate that GOPO ac hiev es competitiv e g eneralization while sustaining healthy gradient dynamics and entropy preser vation in regimes where clipping-based methods plateau. 1 Introduction Aligning Lar g e Languag e Models (LLMs) with human preferences via Reinf orcement Learning from Human Feedbac k (RLHF) [ 5 , 6 ] has become a standard practice. Dominant algor ithms—Pro ximal P olicy Optimization (PPO) [ 2 ], Direct Pref erence Optimization (DPO) [ 1 ], and Group Relativ e P olicy Optimization (GRPO) [ 4 ]—all share a common structural element: they regular ize policy updates via the Kullbac k –Leibler (KL) diver gence, either e xplicitl y as a penalty ter m or implicitly through ratio clipping in log-probability space. KL -regularized objectiv es carr y an inherent g eometric limitation. The KL div ergence 𝐷 KL ( 𝜋 𝜃 ∥ 𝜋 ref ) induces an exponential g eometr y: its Hessian in log-ratio coordinates scales as 𝜎 ( 𝑚 ) ( 1 − 𝜎 ( 𝑚 ) ) , where 𝑚 is the logit margin. This data-dependent cur vature means that as the policy becomes more confident—producing large log-ratios—the gradient signal deca ys e xponentiall y . The resulting gr adient satur ation f orces practitioners to either accept premature plateaus or resor t to heur istic mechanisms suc h as agg ressiv e ratio clipping [ 2 ], asymmetric clip bounds [ 17 ], or entrop y bonuses. W e ar gue that this limitation is not intrinsic to alignment but rather to the c hoice of g eometric space in which optimization is perf ormed. The probability simple x, equipped with KL geometry , conflates tw o 1 independent design c hoices: what to lear n (the sampling/advantag e signal) and how to r egularize (the optimization cur vature). A djusting one inevitabl y perturbs the other . A Hilbert Space Perspectiv e. In this w ork, w e abandon the probability simplex altog ether and ref or mulate alignment as an optimization problem in the Hilbert function space 𝐿 2 ( 𝜋 𝑘 ) . This shift yields three str uctural adv antages: 1. The probability conser vation constraint Í 𝑦 𝜋 ( 𝑦 ) = 1 becomes a linear or thogonality condition ⟨ 𝑣 , 1 ⟩ 𝜋 𝑘 = 0 , where 𝑣 ( 𝑦 ) = 𝜋 ( 𝑦 ) / 𝜋 𝑘 ( 𝑦 ) − 1 is the density fluctuation field. This defines a closed linear subspace H 0 ⊂ 𝐿 2 ( 𝜋 𝑘 ) . 2. The optimal policy update is obtained naturally by the Hilber t Pr ojection Theor em : the ph ysicall y v alid probability distribution that is geometrically closest to the unconstrained targ et. No heuristic clipping or ad-hoc nor malization is needed; the classic w ork -dissipation functional emerg es strictly as an alg ebraic consequence of this minimum distance. 3. The Hessian of the resulting objectiv e is the cons tant scalar 𝜇 𝐼 , completel y independent of the data distribution or the current policy state. This constant cur vatur e guarantee ensures that gradients remain linear and non-saturating throughout training. Building on the functional-analytic f oundation established in Or thogonalized P olicy Optimization (OPO) [ 18 ], w e der ive Group Orthogonalized P olicy Optimization (GOPO) , which seamlessl y transitions the orthogonal projection from the infinite-dimensional global space 𝐿 2 ( 𝜋 𝑘 ) to a finite- dimensional empirical subspace induced by group sampling. A par ticularl y eleg ant result emerg es at the g roup lev el: because standardized advantag es structurally sum to zero, they already reside in the zero-mean subspace, and the chemical potential enf orcing probability conservation exactly vanishes . GOPO thus reduces to a simple, unconstrained quadratic loss o v er policy ratios. Contributions. • W e f or mulate LLM alignment as a constrained optimization in 𝐿 2 ( 𝜋 𝑘 ) and show that the optimal policy is the or thogonal projection of the adv antage-driven targ et onto the probability-conserving subspace. • W e e xtend the unconstrained projection to the Bounded Hilbert Pr ojection (BHP), whic h enforces non-negativity of the targ et policy and yields e xact sparsity f or catas trophically poor actions. • W e derive GOPO as the empirical realization of this frame w ork, proving that the chemical potential v anishes under group nor malization, producing a practical loss with constant cur v ature and an intrinsic dead-zone mechanism. • Experiments on mathematical reasoning benchmarks demonstrate competitiv e generalization (47% on MA TH Le vel 4 vs. 44% f or GRPO/D APO), monotonicall y impro ving v alidation accuracy , and the healthiest gradient dynamics among all tes ted methods. 2 R elated W ork Pref erence Op timization and RLHF . RLHF [ 5 , 6 ] typically inv ol v es learning a re w ard model from pref erences and optimizing a policy via PPO [ 2 ]. DPO [ 1 ] simplifies this by der iving a closed-f or m solution to the KL -constrained problem. IPO [ 7 ] adds a regular ization ter m; SimPO [ 8 ] simplifies the ref erence-free objectiv e. GRPO [ 4 ] eliminates the cr itic netw ork b y using group-relativ e advantag es. All these methods inher it the e xponential geometry of KL diver g ence, leading to gradient saturation in high-confidence regimes. 2 𝑓 -Div ergences and Alternativ e Geometries. The 𝑓 -div ergence famil y [ 9 , 10 ] pro vides a unified frame w ork f or distr ibutional discrepancy . The P earson 𝜒 2 div ergence, a member of this f amily , induces quadratic rather than e xponential penalties. Prior w ork has e xplored 𝑓 -div ergences in v ar iational inf erence [ 11 ], GANs [ 12 ], and imitation lear ning [ 13 ]. In RL, 𝛼 PPO [ 14 ] studied 𝛼 -div ergence as a trust-region constraint. APO [ 15 ] explored combining f orward and rev erse KL dynamics. OPO [ 18 ] first proposed lifting alignment into 𝐿 2 ( 𝜋 𝑘 ) and der iving the optimal update via the Hilbert Projection Theorem. GOPO extends this framew ork from the global Hilber t space to empirical group-lev el subspaces, pro ving that the c hemical potential vanishes under g roup normalization and introducing the Bounded Hilber t Projection f or e xact sparsity . T rust-R egion Methods. TRPO [ 3 ] enforces stability via e xplicit KL constraints. PPO [ 2 ] approximates this with ratio clipping. D APO [ 17 ] introduces dynamic clip bounds and entrop y management. ADPO [ 16 ] uses anchored coordinates f or implicit tr ust regions. GOPO replaces all such mechanisms with a single quadratic penalty in ratio space, whose geometric jus tification is the Hilber t Projection Theorem rather than heur istic appro ximation. 3 Theore tical Framew or k: P olicy Optimization in Hilbert Space W e dev elop the mathematical apparatus underl ying GOPO. The central idea is to reformulate policy optimization in the Hilber t space 𝐿 2 ( 𝜋 𝑘 ) , where the probability simple x constraint becomes a linear subspace condition and the optimal policy update is obtained by or thogonal projection. 3.1 The Hilbert Space of Density Fluctuations Let 𝜋 𝑘 denote the current ref erence policy (typicall y the policy from the pre vious iteration under on-policy anchoring). W e define the ambient space as the Hilbert space of square-integrable functions with respect to 𝜋 𝑘 : H = 𝐿 2 ( 𝜋 𝑘 ) , ⟨ 𝑓 , 𝑔 ⟩ 𝜋 𝑘 = E 𝜋 𝑘 [ 𝑓 ( 𝑦 ) 𝑔 ( 𝑦 ) ] (1) with induced norm ∥ 𝑓 ∥ 𝜋 𝑘 = ⟨ 𝑓 , 𝑓 ⟩ 𝜋 𝑘 . Instead of directl y optimizing the probability vector 𝜋 ( 𝑦 | 𝑥 ) on the simple x, w e shift to a centered coordinate system. Define the density fluctuation field : 𝑣 ( 𝑦 ) = 𝜋 ( 𝑦 ) 𝜋 𝑘 ( 𝑦 ) − 1 (2) The target policy is e xactly reco vered as 𝜋 ( 𝑦 ) = 𝜋 𝑘 ( 𝑦 ) ( 1 + 𝑣 ( 𝑦 ) ) . The field 𝑣 liv es in H and represents the relative deviation of the targ et policy from the ref erence. This coordinate c hang e is the k e y step that transf or ms the non-linear simple x g eometr y into a linear Hilber t space geometry . 3.2 Probability Conserv ation as Orthogonality An y valid probability distr ibution must satisfy Í 𝑦 𝜋 ( 𝑦 ) = 1 . In the fluctuation coordinate, this fundamental ph y sical law simplifies dramaticall y: 𝑦 𝜋 ( 𝑦 ) = 𝑦 𝜋 𝑘 ( 𝑦 ) ( 1 + 𝑣 ( 𝑦 ) ) = 1 + 𝑦 𝜋 𝑘 ( 𝑦 ) 𝑣 ( 𝑦 ) = 1 + E 𝜋 𝑘 [ 𝑣 ] = 1 (3) Hence, probability conservation is equiv alent to the zero-mean condition: E 𝜋 𝑘 [ 𝑣 ] = ⟨ 𝑣 , 1 ⟩ 𝜋 𝑘 = 0 (4) This is a sing le linear constraint in H , defining a closed subspace of codimension one: H 0 = { 𝑓 ∈ H : ⟨ 𝑓 , 1 ⟩ 𝜋 𝑘 = 0 } (5) 3 Remar k 3.1 (Geometr ic Inter pretation) . H 0 is precisel y the or thogonal complement of the one-dimensional subspace spanned b y the constant function 1 in 𝐿 2 ( 𝜋 𝑘 ) . Ev er y valid policy fluctuation must be orthogonal to 1 —probability mass gained at some outputs must be e xactly compensated b y mass lost else where. The term “orthogonalized” in our method name ref ers directl y to this g eometric f act. 3.3 The Driving F orce: Metric Modulation In reinf orcement lear ning, the optimization is driven b y the advantag e function 𝐴 ( 𝑦 ) . T o incor porate adv anced sampling strategies, w e define a Me tric Modulation Operator M 𝛼 that reshapes the ra w adv antag e into an effective dr iving field. Let 𝐸 𝛼 ( 𝑦 ) be an 𝛼 -parameterized escor t multiplier that rew eights contr ibutions according to the density ratio: 𝐸 𝛼 ( 𝑦 ) = 𝜋 ( 𝑦 ) 𝜋 𝑘 ( 𝑦 ) 𝛼 (6) The multiplication operator M 𝛼 acts on functions in H as ( M 𝛼 𝑓 ) ( 𝑦 ) = 𝐸 𝛼 ( 𝑦 ) 𝑓 ( 𝑦 ) . The effectiv e driving field is: 𝑔 𝛼 ( 𝑦 ) = 𝐸 𝛼 ( 𝑦 ) · 𝐴 ( 𝑦 ) (7) When 𝛼 = 0 , the ra w adv antag e drives the update directly . Nonzero 𝛼 f ocuses the dr iving f orce to ward regions where the policy already assigns significant mass, controlling the e xploit-explore tradeoff independentl y of the optimization g eometry . 4 Methodology : Group Orthogonalized P olicy Optimization W e no w deriv e GOPO in f our stag es: (i) identifying the unconstrained targ et and f or mulating the geometric minimum-distance pr inciple, (ii) showing that the classic work -dissipation functional emerg es algebraicall y from this dis tance, (iii) obtaining the closed-f or m solution via the Hilber t Projection Theorem and its bounded extension, and (iv) transitioning to the empirical g roup-lev el objectiv e. 4.1 The Geometric Principle: Minimum Distance to the U nconstrained T arget Suppose f or a moment that there were no ph ysical constraints on the probability distribution. Dr iv en entirel y b y the e xternal metr ic-modulated field 𝑔 𝛼 , the ideal, unconstrained policy fluctuation would simpl y align with the driving f orce, scaled b y a compliance (or stiffness) parameter 𝜇 > 0 : 𝑢 ∗ = 𝑔 𝛼 𝜇 (8) Ho we ver , the reality is that any valid fluctuation field 𝑣 must strictly obey probability conservation, locking it within the zero-mean h yper plane H 0 . The unconstrained targ et 𝑢 ∗ typicall y violates this constraint because E 𝜋 𝑘 [ 𝑔 𝛼 ] ≠ 0 . What is the mos t geometric and pr incipled w ay to resol ve this? W e seek the v alid fluctuation 𝑣 ∈ H 0 that is g eometrically closest to the ideal tar g et 𝑢 ∗ in the Hilbert space. Mathematicall y , this cor responds to minimizing the 𝐿 2 distance (scaled b y 𝜇 / 2 f or dimension consistency): min 𝑣 ∈ H 0 𝜇 2 ∥ 𝑣 − 𝑢 ∗ ∥ 2 𝜋 𝑘 (9) 4 4.2 Emergence of the W or k -Dissipation Functional By algebraicall y e xpanding this pure geometric distance, a remarkable phy sical structure naturally emerg es. Substituting 𝑢 ∗ = 𝑔 𝛼 / 𝜇 , w e ha ve: 𝜇 2 𝑣 − 𝑔 𝛼 𝜇 2 𝜋 𝑘 = 𝜇 2 ∥ 𝑣 ∥ 2 𝜋 𝑘 − 2 𝜇 ⟨ 𝑔 𝛼 , 𝑣 ⟩ 𝜋 𝑘 + 1 𝜇 2 ∥ 𝑔 𝛼 ∥ 2 𝜋 𝑘 (10) = 𝜇 2 ∥ 𝑣 ∥ 2 𝜋 𝑘 | {z } Dissipation − ⟨ 𝑔 𝛼 , 𝑣 ⟩ 𝜋 𝑘 | {z } W ork + 1 2 𝜇 ∥ 𝑔 𝛼 ∥ 2 𝜋 𝑘 | {z } Constant independent of 𝑣 (11) Minimizing the geometric distance is therefore str ictly equivalent to maximizing the negativ e of the 𝑣 -dependent terms. Thus, the alignment objectiv e becomes: arg min 𝑣 ∈ H 0 𝜇 2 ∥ 𝑣 − 𝑢 ∗ ∥ 2 𝜋 𝑘 ≡ arg max 𝑣 ∈ H 0 ⟨ 𝑔 𝛼 , 𝑣 ⟩ 𝜋 𝑘 | {z } External W ork − 𝜇 2 ∥ 𝑣 ∥ 2 𝜋 𝑘 | {z } Quadratic Dissipation (12) The classic “w ork -dissipation ” functional J ( 𝑣 ) = ⟨ 𝑔 𝛼 , 𝑣 ⟩ 𝜋 𝑘 − 𝜇 2 ∥ 𝑣 ∥ 2 𝜋 𝑘 is not an arbitrar ily constructed objectiv e; it is the algebraic inevitability of measuring sq uared distance in a Hilber t space. 4.3 The Orthogonal Projection Solution Because the problem is fundamentally one of finding the closes t point in a closed subspace H 0 to a targ et v ector 𝑢 ∗ , we do not need to rely on Lagrangian differentiation. The Hilber t Projection Theorem directl y yields the unique global optimum as the or thogonal projection: Theorem 4.1 (Optimal Fluctuation via Or thogonal Projection) . The optimal probability-conserving fluctuation 𝑣 ∗ is the orthogonal projection of t he unconstrained targ et 𝑢 ∗ onto H 0 : 𝑣 ∗ = 𝑃 H 0 ( 𝑢 ∗ ) = 𝑢 ∗ − ⟨ 𝑢 ∗ , 1 ⟩ 𝜋 𝑘 1 = 1 𝜇 𝑔 𝛼 − E 𝜋 𝑘 [ 𝑔 𝛼 ] · 1 (13) Pr oof. Since H 0 = { 1 } ⊥ , the orthogonal projection 𝑃 H 0 onto H 0 is: 𝑃 H 0 ( 𝑓 ) = 𝑓 − ⟨ 𝑓 , 1 ⟩ 𝜋 𝑘 ∥ 1 ∥ 2 𝜋 𝑘 1 = 𝑓 − E 𝜋 𝑘 [ 𝑓 ] · 1 (14) using ∥ 1 ∥ 2 𝜋 𝑘 = E 𝜋 𝑘 [ 1 ] = 1 . Applying this to 𝑓 = 𝑢 ∗ = 𝑔 𝛼 / 𝜇 yields the result. Remar k 4.2 (The Chemical P otential) . The subtracted term 𝜆 ∗ = E 𝜋 𝑘 [ 𝑔 𝛼 ] / 𝜇 is the Lagrang e multiplier enf orcing probability conser vation. In our frame work, it obtains the purest g eometric inter pretation: it is e xactly the orthogonal component of the targ et vector 𝑢 ∗ along the illegal normal direction (the constant function 1 ) that is e xplicitly sliced off by the projection. 4.4 Bounded Hilbert Projection and Exact Sparsity The uncons trained projection ( 13 ) ma y produce 𝑣 ∗ ( 𝑦 ) < − 1 f or actions with strongly negativ e driving signals, yielding in v alid negativ e probabilities. T o enf orce the ph y sical constraint 𝜋 ( 𝑦 ) ≥ 0 , equivalentl y 𝑣 ( 𝑦 ) ≥ − 1 , w e e xtend the projection to a Bounded Hilbert Pr ojection (BHP). Define the positiv e orthant C + = { 𝑓 ∈ H : 𝑓 ( 𝑦 ) ≥ − 1 , ∀ 𝑦 } and the f easible conv e x set: K = H 0 ∩ C + (15) The BHP problem seeks the point in K closest to 𝑔 𝛼 / 𝜇 . W e formulate the KKT conditions via the Lagrangian: L ( 𝑣 , 𝜆, 𝜂 ) = E 𝜋 𝑘 h 𝑔 𝛼 𝑣 − 𝜇 2 𝑣 2 − 𝜆 𝑣 + 𝜂 ( 𝑣 + 1 ) i (16) where 𝜆 enf orces E 𝜋 𝑘 [ 𝑣 ] = 0 and the KKT multiplier 𝜂 ( 𝑦 ) ≥ 0 enforces 𝑣 ( 𝑦 ) ≥ − 1 . 5 Theorem 4.3 (Bounded Projection Solution) . The KKT complementarity condition 𝜂 ( 𝑦 ) ( 𝑣 ( 𝑦 ) + 1 ) = 0 yields the closed-f or m bounded solution: 𝑣 ∗ ( 𝑦 ) = max − 1 , 𝑔 𝛼 ( 𝑦 ) − 𝜆 ∗ 𝜇 (17) wher e the dynamic c hemical potential 𝜆 ∗ is the unique v alue ensuring E 𝜋 𝑘 [ 𝑣 ∗ ] = 0 . This result has a prof ound theoretical consequence: Corollary 4.4 (Exact Sparsity) . Actions satisfying 𝑔 𝛼 ( 𝑦 ) < 𝜆 ∗ − 𝜇 ar e assigned 𝑣 ∗ ( 𝑦 ) = − 1 , i.e., t heir targ et pr obability is e xactly zero : 𝜋 ( 𝑦 ) = 𝜋 𝑘 ( 𝑦 ) ( 1 + 𝑣 ∗ ( 𝑦 ) ) = 0 . The BHP thus pro vides an analytical mec hanism for eliminating catastr ophically poor outputs (e.g., hallucinations) via a har d, data-adaptiv e thr eshold, without r equiring any ext ernal filt ering heuristic. 1 (Constant Function) U nconstrained T arg et 𝑢 ∗ = 𝑔 𝛼 / 𝜇 𝜆 ∗ (Chemical Potential) T r uncation (Dead Zone) GOPO P olicy 𝑣 ∗ = 𝑃 K ( 𝑢 ∗ ) Ref erence 𝜋 𝑘 ( 𝑣 = 0 ) Feasible Pol ytope K = H 0 ∩ C + H 0 : Probability Conserving Subspace ⟨ 𝑣 , 1 ⟩ 𝜋 𝑘 = 0 Figure 1: Geometric interpretation of GOPO. The theory operates in 𝐿 2 ( 𝜋 𝑘 ) . The ref erence policy 𝜋 𝑘 sits at the or igin ( 𝑣 = 0 ). V alid policies must reside in H 0 (gray plane) and satisfy non-neg ativity , restricting them to the f easible pol ytope K (green). The unconstrained targ et 𝑢 ∗ = 𝑔 𝛼 / 𝜇 (red) is first projected v er ticall y onto H 0 b y subtracting the c hemical potential 𝜆 ∗ , then tr uncated along the plane onto the K boundar y (dead zone), yielding the final bounded GOPO update 𝑣 ∗ (blue). 4.5 From Global to Em pirical: The GOPO Objectiv e Optimizing the dis tance minimization ( 9 ) in the global space 𝐿 2 ( 𝜋 𝑘 ) requires access to the full distribution, which is computationall y intractable f or autoregressive language models. GOPO br idges this gap b y transitioning the orthogonal projection to an empir ical discrete subspace. For a giv en prompt 𝑥 , sample a g roup of 𝐺 responses G = { 𝑦 1 , . . . , 𝑦 𝐺 } ∼ 𝜋 𝑘 ( · | 𝑥 ) . Define the empirical inner product space ˆ 𝐿 2 ( G ) with metric: ⟨ 𝑓 , 𝑔 ⟩ G = 1 𝐺 𝐺 𝑖 = 1 𝑓 ( 𝑦 𝑖 ) 𝑔 ( 𝑦 𝑖 ) (18) 6 The probability conservation constraint is naturall y relaxed to the empir ical zero-mean condition: ˆ H 0 = ( 𝑣 ∈ ˆ 𝐿 2 ( G ) : 1 𝐺 𝐺 𝑖 = 1 𝑣 ( 𝑦 𝑖 ) = 0 ) (19) The V anishing Chemical Po tential. In standard RLHF pipelines, ra w re wards are nor malized into group-relativ e advantag es 𝐴 𝑖 = 𝑟 𝑖 − ¯ 𝑟 , satisfying Í 𝐺 𝑖 = 1 𝐴 𝑖 = 0 b y construction. Consequentl y , the empir ical driving vector 𝑨 = [ 𝐴 1 , . . . , 𝐴 𝐺 ] ⊤ intrinsically resides in ˆ H 0 . Because the dr iving f orce is already or thogonal to 1 , the projection operator 𝑃 ˆ H 0 acts as the identity on 𝑨 : 𝑃 ˆ H 0 ( 𝑨 ) = 𝑨 − 1 𝐺 𝐺 𝑖 = 1 𝐴 𝑖 · 1 = 𝑨 (20) The chemical potential 𝜆 ∗ required to enf orce probability conservation exactly v anishes at the empirical group le vel. Remar k 4.5 (Structural Simplification) . This v anishing is not a numerical appro ximation but a s tructural consequence of group nor malization. It eliminates the need to solv e f or 𝜆 ∗ , collapsing the constrained projection into an unconstrained optimization problem. The GOPO Loss Function. Substituting the empir ical advantag e 𝐴 𝑖 f or the dr iving field 𝑔 𝛼 , and replacing the anal ytical fluctuation 𝑣 ( 𝑦 𝑖 ) with the parameterized density ratio 𝜌 𝜃 ( 𝑦 𝑖 ) = 𝜋 𝜃 ( 𝑦 𝑖 | 𝑥 ) / 𝜋 𝑘 ( 𝑦 𝑖 | 𝑥 ) , the constrained functional maximization ( 12 ) reduces to: L GOPO ( 𝜃 ) = − E 𝑥 ∼ D " 1 𝐺 𝐺 𝑖 = 1 h 𝐴 𝑖 𝜌 𝜃 ( 𝑦 𝑖 ) − 𝜇 2 𝜌 𝜃 ( 𝑦 𝑖 ) − 1 2 i # (21) Structural Comparison with GRPO. It is instructive to contras t ( 21 ) with the GRPO loss [ 4 ]: L GRPO ( 𝜃 ) = − E 𝑥 ∼ D " 1 𝐺 𝐺 𝑖 = 1 1 | 𝑦 𝑖 | | 𝑦 𝑖 | 𝑡 = 1 min 𝜌 𝜃 ( 𝑦 𝑖 , 𝑡 ) ˆ 𝐴 𝑖 , clip ( 𝜌 𝜃 ( 𝑦 𝑖 , 𝑡 ) , 1 − 𝜖 , 1 + 𝜖 ) ˆ 𝐴 𝑖 − 𝛽 𝐷 KL ( 𝜋 𝜃 ∥ 𝜋 𝑘 ) # (22) where ˆ 𝐴 𝑖 denotes the s tandardized advantag e, 𝜌 𝜃 ( 𝑦 𝑖 , 𝑡 ) is the tok en-le v el density ratio, and 𝜖 is the clip radius. The tw o losses share the same fundamental motiv ation—optimizing a policy via group-sampled responses and normalized adv antag es—but differ in three fundamental w a ys: 1. T rust region mechanism. GRPO enf orces the trust region via hard clipping of the token-le vel ratio 𝜌 𝜃 ( 𝑦 𝑖 , 𝑡 ) alongside an e xplicit KL penalty , whic h introduces a non-smooth, piecewise-linear landscape with zero-gradient plateaus wherev er | 𝜌 𝜃 − 1 | > 𝜖 . GOPO replaces this with a smooth quadr atic penalty 𝜇 2 ( 𝜌 𝜃 − 1 ) 2 on the sequence-le vel ratio that continuousl y penalizes de viation from the ref erence—the ratio can mo v e freel y while the restor ing f orce g ro w s linearl y , ne v er producing a gradient dead zone. 2. Optimization curv ature. The Hessian of GRPO’ s clipped sur rogate is either 0 (inside the flat clipped region) or undefined (at the clip boundary); its effective cur vature is data- and s tate- dependent. GOPO’ s Hessian is the constant 𝜇 , yielding a uniforml y conv e x landscape with predictable conv erg ence (Theorem 5.1 ). 3. Gradient behavior at con v ergence. As 𝜌 𝜃 → 1 and the policy approaches the reference, the GRPO gradient is dominated by the adv antage-w eighted policy g radient ˆ 𝐴 𝑖 ∇ 𝜃 log 𝜋 𝜃 , whic h scales with the adv antag e magnitude but does not account f or the distance already tra v eled. GOPO’ s gradient − 𝐴 𝑖 + 𝜇 ( 𝜌 𝜃 − 1 ) is proportional to the displacement from equilibrium , pro viding a natural deceleration as the policy approaches its tar get 𝜌 ∗ = 1 + 𝐴 𝑖 / 𝜇 . 7 In summar y , GOPO trades GRPO’ s hard combinator ial constraint (clip) f or a soft geometric one (projection), gaining smoothness, constant cur vature, and a pr incipled equilibr ium structure at no additional computational cost. Bounded GOPO Loss. The BHP tr uncation logic is absorbed into the loss bounds via: L BHP GOPO ( 𝜃 ) = 1 𝐺 𝐺 𝑖 = 1 max 0 , − 𝐴 𝑖 𝜌 𝜃 ( 𝑦 𝑖 ) + 𝜇 2 𝜌 𝜃 ( 𝑦 𝑖 ) − 1 2 (23) where the max ( 0 , ·) acts as a ReL U-like floor , halting gradients once 𝜌 𝜃 ( 𝑦 𝑖 ) → 0 f or highl y negativ e adv antag es. 5 Theore tical Analy sis 5.1 Constant Curvatur e and Decoupled Geometry The primary vulnerability of PPO, DPO, and GRPO is their reliance on the e xponential div erg ence 𝐷 KL . The Hessian of KL -based objectiv es scales non-linearl y with the policy output, causing gradient saturation that must be mitigated via heuristic clipping. Theorem 5.1 (Constant Curvature Optimization) . Let ℓ ( 𝜌 ) = − 𝐴 𝜌 + 𝜇 2 ( 𝜌 − 1 ) 2 be the pointwise un- truncated GOPO loss. The Hessian with r espect to the density r atio 𝜌 is the constant scalar 𝜇 , independent of the adv antag e signal 𝐴 , t he current policy s tate, or t he data distribution. Pr oof. ∇ 𝜌 ℓ = − 𝐴 + 𝜇 ( 𝜌 − 1 ) , hence ∇ 2 𝜌 ℓ = 𝜇 . This constant curvature has immediate consequences f or the decoupling of design axes: Corollary 5.2 (S tr uctural Decoupling) . In the GOPO objectiv e, t he first-or der driving for ce depends on the advantag e signal: ∇ 𝜌 ℓ = − 𝐴 + 𝜇 ( 𝜌 − 1 ) (24) while the second-or der curvatur e ∇ 2 𝜌 ℓ = 𝜇 is independent of 𝐴 . Consequently , c hanging the adv antag e w eighting (sampling g eometry) does not alter the optimization landscape cur vatur e (optimization g eometr y), and vice ver sa. Remar k 5.3 (Contrast with KL-Based Methods) . In DPO, the effective loss is ℓ DPO ≈ − log 𝜎 ( 𝛽 𝑚 ) , where 𝑚 is the logit margin. The local curvature 𝛽 2 𝜎 ( 𝑚 ) ( 1 − 𝜎 ( 𝑚 ) ) depends on both the temperature 𝛽 and the current mar gin 𝑚 . Changing 𝛽 simultaneousl y alters the gradient magnitude and the stability profile. This data-dependent curvature is the root cause of gradient saturation. Corollary 5.4 (Global Linear Con v erg ence) . Gr adient descent in ratio space on the GOPO objective f ollow s t he linear sy st em: 𝜌 𝑘 + 1 − 𝜌 ∗ = ( 1 − 𝜂 𝜇 ) ( 𝜌 𝑘 − 𝜌 ∗ ) (25) wher e 𝜌 ∗ = 1 + 𝐴 / 𝜇 . F or step size 0 < 𝜂 < 2 / 𝜇 , this exhibits g lobal contr action to the unique equilibrium at rate | 1 − 𝜂 𝜇 | , independent of the adv antag e distribution. 5.2 Gradient Dynamics: Non-Saturation Guarantee W e quantify the gradient behavior to contras t with KL -based methods. Gradient Saturation in DPO. For logistic losses, the gradient magnitude satisfies | ∇ 𝑚 ℓ DPO | = | 𝛽 𝜎 ( 𝑚 ) ( 1 − 𝜎 ( 𝑚 ) ) | ≤ 𝛽 / 4 , and cr ucially , | ∇ 𝑚 ℓ DPO | → 0 exponentiall y as | 𝑚 | → ∞ . 8 Non-Saturating Gradient in GOPO. For the GOPO loss, the g radient magnitude is: | ∇ 𝜌 ℓ GOPO | = | − 𝐴 + 𝜇 ( 𝜌 − 1 ) | = 𝜇 | 𝜌 − 𝜌 ∗ | (26) This is e xactl y propor tional to the distance from equilibrium. For an y non-equilibr ium s tate with | 𝜌 − 𝜌 ∗ | ≥ 𝛿 : | ∇ GOPO | ≥ 𝜇 𝛿 (27) The g radient maintains a linear driving f orce that ne v er v anishes aw ay from eq uilibrium, pre v enting the saturation endemic to KL -based methods. 5.3 Dead Zone Dynamics and Gradient Hard Stops The BHP truncation es tablishes an implicit “dead zone ” f or g radient flow . T aking the der ivativ e of the bounded GOPO loss ( 23 ): ∇ 𝜃 L BHP GOPO ∝ 1 𝐺 𝐺 𝑖 = 1 I 𝜌 𝜃 ( 𝑦 𝑖 ) > 0 | {z } Dead Zone Gate · − 𝐴 𝑖 + 𝜇 ( 𝜌 𝜃 ( 𝑦 𝑖 ) − 1 ) | {z } Res toring Force ∇ 𝜃 𝜌 𝜃 ( 𝑦 𝑖 ) (28) When an action receiv es an e xtremely negativ e adv antag e 𝐴 𝑖 ≪ 0 , the ratio 𝜌 𝜃 ( 𝑦 𝑖 ) is rapidl y suppressed. Once it approaches the phy sical boundar y 𝜌 𝜃 → 0 (equiv alently 𝑣 ( 𝑦 𝑖 ) → − 1 ), the indicator function triggers a har d st op : the g radient f or this action is e xactly zeroed out. This mec hanism pre v ents the network from w asting representational capacity on already-suppressed outputs, redirecting gradient bandwidth ex clusiv el y to w ard distinguishing among higher -quality responses. 5.4 Connection to 𝜒 2 Div ergence The Hilber t space frame work pro vides a natural connection to s tatistical div erg ences. Proposition 5.5 ( 𝜒 2 Inter pretation) . The dissipation term in the GOPO functional is proportional to t he P earson 𝜒 2 div er g ence: 1 2 E 𝜋 𝑘 ( 𝑣 ( 𝑦 ) ) 2 = 1 2 E 𝜋 𝑘 " 𝜋 ( 𝑦 ) 𝜋 𝑘 ( 𝑦 ) − 1 2 # = 𝐷 𝜒 2 ( 𝜋 ∥ 𝜋 𝑘 ) (29) Thus, t he GOPO objectiv e can be equiv alently r ead as maximizing adv antag e-weight ed w ork subject to a 𝜒 2 trust region. Proposition 5.6 (T otal V ar iation Bound) . Bounding E [ 𝑣 2 ] ≤ 𝜖 via the 𝜒 2 penalty guarant ees, by Jensen’ s inequality : TV ( 𝜋 , 𝜋 𝑘 ) = 1 2 E [ | 𝑣 | ] ≤ 1 2 E [ 𝑣 2 ] ≤ √ 𝜖 2 (30) pr oviding a distributional stability guar antee in T o tal V ariation dis tance. 5.5 Comparison with P arametric L2 Regularization A natural ques tion is whether GOPO’ s quadratic penalty differs from standard weight decay 𝜆 2 ∥ 𝜃 − 𝜃 0 ∥ 2 . The distinction is fundamental: 1. Functional vs. Parametric : GOPO’ s penalty 𝜇 2 E [ 𝑣 2 ] acts in the function space of probability ratios. It penalizes de viations where the policy assigns probability mass. W eight decay acts unif ormly in parameter space, blind to output-le v el consequences. 9 2. A daptiv e Restoring F orce : The gradient 𝜇 ( 𝜌 − 1 ) pulls each specific output ratio back tow ard unity . W eight decay suppresses all weights unif or mly , potentiall y hindering the f or mation of shar p, high-confidence reasoning chains. 3. Geometric Guarantee : The 𝜒 2 penalty pro vides distr ibutional bounds (Theorem 5.6 ). W eight deca y offers no such output-space guarantee. 6 Algorithm and Implementation Algorithm 1: Gr oup Orthogonalized P olicy Optimization (GOPO) Input : Initial policy 𝜋 𝜃 , stiffness 𝜇 , group size 𝐺 , lear ning rate 𝜂 f or each iteration do 1. Set Ref erence: 𝜋 𝑘 ← 𝜋 𝜃 (on-policy anchoring) 2. Sample Group: F or each prompt 𝑥 , sample G = { 𝑦 1 , . . . , 𝑦 𝐺 } ∼ 𝜋 𝑘 ( · | 𝑥 ) 3. Score and N ormalize: Compute rew ards 𝑟 𝑖 ; set 𝐴 𝑖 = 𝑟 𝑖 − ¯ 𝑟 ( Í 𝐴 𝑖 = 0 ) 4. Compute Ratios: 𝜌 𝜃 ( 𝑦 𝑖 ) = 𝜋 𝜃 ( 𝑦 𝑖 | 𝑥 ) / 𝜋 𝑘 ( 𝑦 𝑖 | 𝑥 ) 5. Compute Loss: L = − 1 𝐺 Í 𝐺 𝑖 = 1 𝐴 𝑖 𝜌 𝜃 ( 𝑦 𝑖 ) − 𝜇 2 ( 𝜌 𝜃 ( 𝑦 𝑖 ) − 1 ) 2 6. U pdate: 𝜃 ← 𝜃 − 𝜂 ∇ 𝜃 L end for Figure 2: GOPO algorithm. Step 3 guarantees that the adv antag e vector lies in the zero-mean subspace ˆ H 0 , eliminating the chemical potential. Steps 4–5 implement the empirical or thogonal projection with quadratic dissipation. Cur rent P olicy 𝜋 𝜃 Group Sampling G R e w ard & Normalize 𝐴 𝑖 Hilbert Projection 1. Ratio 𝜌 = 𝜋 𝜃 / 𝜋 𝑘 2. W ork: 𝐴 𝑖 𝜌 𝑖 3. Dissipation: 𝜇 2 ( 𝜌 𝑖 − 1 ) 2 U pdate 𝜃 Ne xt Iteration Figure 3: GOPO flo w chart. The core operation (green) implements the empirical orthogonal projection: the advantag e signal pro vides the linear driving f orce, while the quadratic dissipation term pro vides the constant-curvature regularization. Implementation Notes. GOPO introduces no additional model f or ward/bac kward passes compared to GRPO. The onl y o v erhead is the computation of ( 𝜌 𝜃 − 1 ) 2 , whic h is negligible. The reference policy 𝜋 𝑘 is set to the policy from the s tar t of each iteration (on-policy anchoring), ensur ing that the tr ust region 𝜌 ≈ 1 holds locall y . No cr itic network is req uired. 10 7 Experiments W e e valuate GOPO ag ainst f our strong baselines on mathematical reasoning tasks, f ocusing on out-of- distribution g eneralization perf or mance. 7.1 Setup Model and Data. W e use Qw en3-1.7B as the base model, trained with the VERL framew ork [ 19 ] on 4 × R TX 4090 GPUs. T o stress-test sample efficiency and generalization, w e deliberately use a small training set: appro ximately 10% of MA TH Lev el 3 problems (sampled with seed 42). V alidation is performed e v ery 10 training steps on 100 held-out MA TH Le vel 4 problems—a strictly harder difficulty tier not seen dur ing training—to measure out-of-distribution generalization. All methods share identical h yperparameters: batc h size 48, lear ning rate 2 × 10 − 6 , 8 epochs o ver the training data, and 𝐺 = 6 rollout g enerations per prompt. Baselines. • OPO [ 18 ]: The full Or thogonalized Policy Optimization with importance-sampling re w eighting ( 𝜔 𝛼 ), from which GOPO is derived. • GRPO [ 4 ]: T oken-le v el policy gradient with g roup-normalized advantag es and PPO-sty le ratio clipping ( 𝜖 = 0 . 2 ). • GSPO : Sentence-lev el v ar iant of GRPO with step-le vel advantag e normalization. • D APO [ 17 ]: A dvanced baseline with asymmetr ic clip bounds, unnor malized advantag es, and o ver long re ward shaping. GOPO uses stiffness 𝜇 = 0 . 5 , escort e xponent 𝛼 = 0 . 5 , and on-policy anc horing. 7.2 Results Ov erall P er formance. T able 1 summarizes the final metrics f or all methods. T able 1: Comparison of policy optimization algorithms on MA TH benchmarks. All methods use Qw en3-1.7B trained on ∼ 10% of MA TH Le v el 3, validated on 100 MA TH Le vel 4 problems. Re ward is a v eraged o v er the entire training process. Algorithm Mean Re w ard ↑ V al Acc (L4) ↑ Grad Norm Entrop y GRPO 0.544 44% 0.674 0.115 D APO 0.548 44% 0.213 0.126 GSPO 0.553 48% 0.623 0.128 OPO 0.558 48% 1.279 0.126 GOPO (Ours) 0.555 47% 1.029 0.134 Analy sis. • Generalization vs. T raining Re war d. OPO and GOPO achie ve the highest mean rew ards (0.558 and 0.555) ov er the training process, whic h directly translates to their superior g eneralization per f or mance (48% and 47% validation accuracy). In contrast, GRPO str uggles with the low est mean rew ard (0.544) and poorest generalization (44%), s truggling to efficiently lear n from the small training set. GOPO ac hiev es competitiv e v alidation accuracy while maintaining an upward trajectory (F igure 4 b). 11 • Gradient Dynamics. OPO and GOPO maintain substantiall y higher g radient norms (1.28 and 1.03) than ratio-clipped methods (GRPO: 0.67, GSPO: 0.62, D APO: 0.21), empir ically confir ming the non-saturation prediction of Theorem 5.1 . D APO’ s se v erely diminished gradients ( ∼ 0.21) indicate the conser vativ e clipping is o v er l y restr ictiv e. • Entrop y Preservation. GOPO maintains the highes t policy entropy (0.134) among all methods. W e attribute this to the sequence-lev el nature of the GOPO update: unlike tok en-lev el methods (GRPO, D APO) that impose dense per -tok en super vision f orcing rapid mode collapse, GOPO aligns total tra jectory probability without micromanaging individual tok ens. T raining Dynamics. F igure 4 sho ws the full training tra jector ies across f our diagnostic metr ics. Figure 4: T raining dynamics com parison. (a) T raining rew ard: OPO and GOPO achie ve the highest mean rew ards o ver the training process. (b) V alidation accuracy on MA TH Le vel 4: OPO and GSPO lead at 48%, with GOPO at 47% and monotonically impro ving. (c) Gradient nor m: OPO/GOPO maintain health y nor ms throughout, while D APO exhibits sev ere g radient saturation. (d) P olicy entrop y: GOPO preserves the mos t diversity , prev enting premature mode collapse. Generalization Analy sis. The v alidation accuracy trajectories (F igure 4 b) re v eal important dynamics: • GOPO sho w s monotonic impro v ement in generalization (38% → 46% → 47%), sugg esting the algorithm has not y et plateaued and w ould benefit from long er training. • OPO s tarts strong (49% at s tep 10) but e xhibits non-monotonic beha vior (50% → 44% → 48%), consistent with the impor tance-sampling v ar iance inherent in the full OPO frame w ork. 12 • GRPO and D APO plateau at 44%, despite GRPO’ s higher training re ward—a signature of the re ward hacking phenomenon where clipping-based methods exploit the training distribution rather than learning g eneralizable reasoning patterns. 8 Discussion Wh y Hilbert Space? Our frame work is not merel y a notational chang e but a deliberate choice of the mathematical arena best suited to the problem’s intr insic structure. P olicy alignment fundamentally operates in an abstract, high-dimensional space where the action v ocabular y can range from tens of thousands of tok ens to unbounded sequences. In finite-dimensional Euclidean space, optimization ov er such objects req uires explicit coordinates and encounters the curse of dimensionality . The Hilbert space 𝐿 2 ( 𝜋 𝑘 ) , b y contrast, is pur pose-built f or abstract infinite-dimensional anal y sis: it pro vides a complete inner product structure that makes distances, angles, and projections well-defined r eg ardless of the underlying dimensionality . Consequentl y , mappings and constraints that appear intractably nonlinear on the probability simplex—suc h as the nor malization condition Í 𝑦 𝜋 ( 𝑦 ) = 1 —collapse into elementar y linear -algebraic operations (inner products, closed subspaces, or thogonal projections) once lifted into this space. The probability simple x, eq uipped with KL g eometry , fundamentally entangles the sampling signal with the optimization cur vature; the Hilber t space disentangles them entirely . The Hilber t Projection Theorem provides a pr incipled replacement f or heur istic clipping, and the chemical potential emerg es as a natural geometric b y-product of the projection rather than an ad-hoc normalization cons tant. Abstract Representations and the Geometry of Distance. The adoption of Hilber t space is not without precedent in sciences that confront fundamentall y abstract, high-dimensional state spaces. In quantum mechanics, the state of a phy sical system is a v ector in a Hilber t space, and all measurable predictions—probabilities, e xpectation values, transition amplitudes—reduce to inner products and projections within that space [ 20 ]. The po w er of this f ormalism lies precisel y in its coordinat e-fr ee nature: the mathematical apparatus operates identicall y whether the state space is tw o-dimensional (a qubit) or infinite-dimensional (a quantum field), because the inner product provides a complete metric structure—distance, angle, and projection—independent of any par ticular basis. A structurally parallel situation ar ises in language model alignment. The output of an LLM is a probability dis tr ibution o v er an astronomicall y larg e discrete space of possible utterances. What w e seek to optimize is not any individual coordinate of this distr ibution, but its g lobal g eometric relationship to a tar g et: ho w “close ” the aligned policy is to the ideal, cons trained by the requirement of remaining a v alid distribution. The 𝐿 2 ( 𝜋 𝑘 ) frame w ork pro vides e xactl y the right notion of dis tance ( ∥ 𝑣 − 𝑢 ∗ ∥ 𝜋 𝑘 ) f or this task —one that is complete, g eometr ically meaningful, and agnostic to the dimensionality of the action space. The alignment problem thus reduces to its purest geometric essence: find the neares t valid point t o an ideal tar g et , an operation that Hilbert space is uniquel y eq uipped to perform via its Projection Theorem. This perspectiv e also connects to a broader trend in computational cognitiv e science, where abs tract representational spaces—from semantic embeddings to conceptual structures—are increasingl y modeled as inner product spaces in which “similar ity” corresponds to geometric proximity [ 21 , 22 ]. The Hilber t space frame w ork ma y thus offer a principled mathematical language not onl y f or policy optimization but f or an y domain where the fundamental task is to na vigate distances between abstract, high-dimensional representations under structural cons traints. The Role of Group Normalization. The v anishing chemical potential at the group lev el is a s tructural consequence of the geometry . Group normalization ensures that the advantag e v ector already lies in the zero-mean subspace ˆ H 0 , so no projection is needed along the 1 direction. This eliminates an entire class of potential f ailure modes related to improper constraint enforcement. 13 Relation to Existing Methods. • Setting 𝜇 → 0 recov ers an unconstrained policy gradient (no regularization). • GOPO’ s quadratic penalty can be view ed as the Bregman diver g ence induced b y the Euclidean mir ror map Ψ ( 𝑣 ) = 1 2 ∥ 𝑣 ∥ 2 , connecting to the mirror descent literature. How ev er , the Hilber t space derivation is more direct and re v eals additional s tructure (subspaces, projections, chemical potential). • The dead-zone mechanism (Section 5.3 ) provides a principled alternativ e to the clip-higher strategy of D APO [ 17 ], with the advantag e of ar ising from the g eometr y rather than being hand-designed. Limitations. GOPO introduces the stiffness parameter 𝜇 , whic h ma y require tuning. Our e xper iments f ocus on mathematical reasoning; validation on div erse domains (instr uction f ollo wing, code generation) remains future w ork. The BHP truncation is cur rently implemented via a soft ReL U approximation rather than the e xact hard threshold der iv ed in Theorem 4.3 ; studying the impact of this appro ximation g ap is an open direction. 9 Conclusion W e hav e presented Group Orthogonalized Policy Optimization (GOPO) , an alignment algorithm derived entirely from the g eometry of Hilber t function spaces. By lifting policy optimization from the probability simplex into 𝐿 2 ( 𝜋 𝑘 ) , w e transf or m the nonlinear nor malization constraint into a linear or thogonality condition. The alignment objective itself emerg es alg ebraicall y from the geometric principle of minimum distance to the unconstrained tar g et, and its closed-f orm solution is giv en by the Hilbert Projection Theorem. The Bounded Hilbert Projection extends this to enf orce non-neg ativity , yielding e xact sparsity for catastrophic outputs. At the empir ical group lev el, the chemical potential vanishes under s tandard adv antag e nor malization, producing a simple loss with constant curvature, non-saturating gradients, and an intrinsic dead-zone mechanism. Exper iments on mathematical reasoning benchmarks confirm that GOPO sustains lear ning in high-confidence regimes where clipping-based methods plateau, achie ving competitiv e generalization per f ormance with the healthiest gradient dynamics and entropy preservation among all tested methods. R ef erences [1] R. Rafailo v , A. Shar ma, E. Mitchell, S. Er mon, C. D. Manning, and C. Finn. Direct Preference Optimization: Y our Language Model is Secretl y a R e ward Model. N eurIPS , 2023. [2] J. Schulman, F . W olski, P . Dhariwal, A. Radf ord, and O. Klimo v . Pro ximal Policy Optimization Algorithms. arXiv :1707.06347, 2017. [3] J. Schulman, S. Le vine, P . Mor itz, M. I. Jordan, and P . A bbeel. T rust Region Policy Optimization. ICML , 2015. [4] Z. Shao, P . W ang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . K. Li, Y . W u, and D. Guo. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Languag e Models. arXiv:2402.03300, 2024. [5] P . Chr istiano, J. Leike, T . B. Bro wn, M. Mar tic, S. Legg, and D. Amodei. Deep Reinf orcement Learning from Human Pref erences. N eurIPS , 2017. [6] L. Ouyang, J. W u, X. Jiang, D. Almeida, C. L. W ain wr ight, P . Mishkin, et al. T raining Language Models to Follo w Instr uctions with Human Feedback. N eurIPS , 2022. [7] M. G. Azar , M. R o wland, B. Piot, D. Guo, D. Calandr iello, M. V alko, and R. Munos. A General Theoretical Paradigm to U nderstand Learning from Human Pref erences. AIST ATS , 2024. 14 [8] Y . Meng, M. Xia, and D. Chen. SimPO: Simple Pref erence Optimization with a R ef erence-Free R e w ard. N eurIPS , 2024. [9] I. Csiszár . Inf or mation-type measures of difference of probability dis tributions and indirect obser v a- tions. Studia Sci. Math. Hung ar . , 2:299–318, 1967. [10] S. M. Ali and S. D. Silv e y . A General Class of Coefficients of Div erg ence of One Distribution from Another . JRSS-B , 28(1):131–142, 1966. [11] Y . Li and R. E. T ur ner . R ényi Div erg ence V ar iational Inf erence. N eurIPS , 2016. [12] S. No w ozin, B. Cseke, and R. T omioka. f-G AN: T raining Generativ e N eural Samplers Using V ariational Div erg ence Minimization. N eurIPS , 2016. [13] S. K. S. Ghasemipour, R. Zemel, and S. Gu. A Div erg ence Minimization P erspectiv e on Imitation Learning Methods. CoRL , 2020. [14] H. Xu e t al. Impro ving Pro ximal Policy Optimization with Alpha Diver gence. N eur ocomputing , 2023. [15] Z. W ang. APO: Alpha-Div erg ence Preference Optimization. arXiv :2512.22953, 2025. [16] Z. W ang. ADPO: Anchored Direct Pref erence Optimization. arXiv :2510.18913, 2025. [17] Q. Y u et al. D APO: An Open-Source LLM R einforcement Learning Sy st em. arXiv :2503.14476, 2025. [18] Z. W ang. Or thogonalized P olicy Optimization: Policy Optimization as Orthogonal Projection in Hilber t Space. arXiv:2601.12415, 2026. [19] G. Sheng, C. Xu, S. Y uan, et al. Hybr idFlo w : A Flexible and Efficient RLHF Framew ork. arXiv:2409.19256, 2024. [20] J. v on Neumann. Mathematical F oundations of Quantum Mechanics . Spr inger , 1932. (English translation: Princeton U niv ersity Press, 1955.) [21] P . Gärdenf ors. Concep tual Spaces: The Geometry of Thought . MIT Press, 2000. [22] J. R. Buseme y er and P . D. Bruza. Quantum Models of Cognition and Decision . Cambridge U niv ersity Press, 2012. A Proofs and Deriv ations A.1 Deriv ation of the Projection Operator Pr oof of Theor em 4.1 . The Hilber t space H = 𝐿 2 ( 𝜋 𝑘 ) admits the or thogonal decomposition H = H 0 ⊕ span { 1 } . For any 𝑓 ∈ H , the projection onto H 0 is: 𝑃 H 0 ( 𝑓 ) = 𝑓 − ⟨ 𝑓 , 1 ⟩ 𝜋 𝑘 ⟨ 1 , 1 ⟩ 𝜋 𝑘 1 = 𝑓 − E 𝜋 𝑘 [ 𝑓 ] (31) As der ived in Section 4.2 , minimizing 𝜇 2 ∥ 𝑣 − 𝑢 ∗ ∥ 2 o ver 𝑣 ∈ H 0 is equivalent to maximizing J ( 𝑣 ) = ⟨ 𝑔 𝛼 , 𝑣 ⟩ − 𝜇 2 ∥ 𝑣 ∥ 2 , since the two differ onl y b y the constant 1 2 𝜇 ∥ 𝑔 𝛼 ∥ 2 . The minimum-distance problem has the unique solution 𝑣 ∗ = 𝑃 H 0 ( 𝑢 ∗ ) = 𝑃 H 0 ( 𝑔 𝛼 / 𝜇 ) b y the Hilbert Projection Theorem. Appl ying the projection formula: 𝑣 ∗ = 𝑔 𝛼 𝜇 − E 𝜋 𝑘 𝑔 𝛼 𝜇 = 1 𝜇 𝑔 𝛼 − E 𝜋 𝑘 [ 𝑔 𝛼 ] (32) 15 A.2 Deriv ation of the Bounded Hilbert Projection Pr oof of Theor em 4.3 . The KKT stationar ity condition f or the Lagrangian giv es: 𝑔 𝛼 ( 𝑦 ) − 𝜇 𝑣 ( 𝑦 ) − 𝜆 + 𝜂 ( 𝑦 ) = 0 (33) Combined with the complementar ity condition 𝜂 ( 𝑦 ) ( 𝑣 ( 𝑦 ) + 1 ) = 0 and 𝜂 ( 𝑦 ) ≥ 0 : Case 1 : 𝑣 ( 𝑦 ) > − 1 . Then 𝜂 ( 𝑦 ) = 0 , so 𝑣 ( 𝑦 ) = ( 𝑔 𝛼 ( 𝑦 ) − 𝜆 ) / 𝜇 . Case 2 : 𝑣 ( 𝑦 ) = − 1 . Then 𝜂 ( 𝑦 ) = 𝜆 − 𝜇 − 𝑔 𝛼 ( 𝑦 ) ≥ 0 , whic h requires 𝑔 𝛼 ( 𝑦 ) ≤ 𝜆 ∗ − 𝜇 . These cases unify as 𝑣 ∗ ( 𝑦 ) = max ( − 1 , ( 𝑔 𝛼 ( 𝑦 ) − 𝜆 ∗ ) / 𝜇 ) , where 𝜆 ∗ sol v es E 𝜋 𝑘 [ 𝑣 ∗ ] = 0 . A.3 Log-Ratio Appro ximation Lemma A.1 (Log-Ratio Approximation Er ror) . Let Δ 𝜃 ( 𝑦 ) = log 𝜋 𝜃 ( 𝑦 ) − log 𝜋 𝑘 ( 𝑦 ) and 𝑣 𝜃 ( 𝑦 ) = e xp ( Δ 𝜃 ) − 1 . F or 𝛿 = ∥ Δ 𝜃 ∥ ∞ < 1 : | 𝑣 𝜃 − Δ 𝜃 | ≤ 1 2 𝛿 2 𝑒 𝛿 , | 𝑣 2 𝜃 − Δ 2 𝜃 | ≤ 𝛿 3 𝑒 2 𝛿 (34) The GOPO loss using log-ratios Δ 𝜃 in place of 𝑣 𝜃 = 𝜌 𝜃 − 1 incurs an appr oximation error of 𝑂 ( E [ Δ 3 𝜃 ] ) , whic h is contr olled by the on-policy trust r egion. A.4 𝜒 2 -Constrained Maximization Duality Proposition A.2 (Lagrang e Dual Equiv alence) . The constr ained pr oblem max 𝑣 ∈ 𝐿 2 ( 𝜋 𝑘 ) E 𝜋 𝑘 [ 𝑔 𝛼 𝑣 ] subject to E 𝜋 𝑘 [ 𝑣 2 ] ≤ 𝜖 has Lagr angian relaxation equal to the GOPO functional J ( 𝑣 ) = E [ 𝑔 𝛼 𝑣 ] − 𝜇 2 E [ 𝑣 2 ] , wher e 𝜇 is the dual v ariable corresponding to the cons tr aint radius 𝜖 . The optimal solution 𝑣 ∗ = 𝑔 𝛼 / 𝜇 confirms that the stiffness 𝜇 pur ely controls the trust-r egion r adius while 𝑔 𝛼 pur ely shapes the alignment dir ection. 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment