Personalized Prediction of Perceived Message Effectiveness Using Large Language Model Based Digital Twins
Perceived message effectiveness (PME) by potential intervention end-users is important for selecting and optimizing personalized smoking cessation intervention messages for mobile health (mHealth) platform delivery. This study evaluates whether large…
Authors: Jasmin Han, Janardan Devkota, Joseph Waring
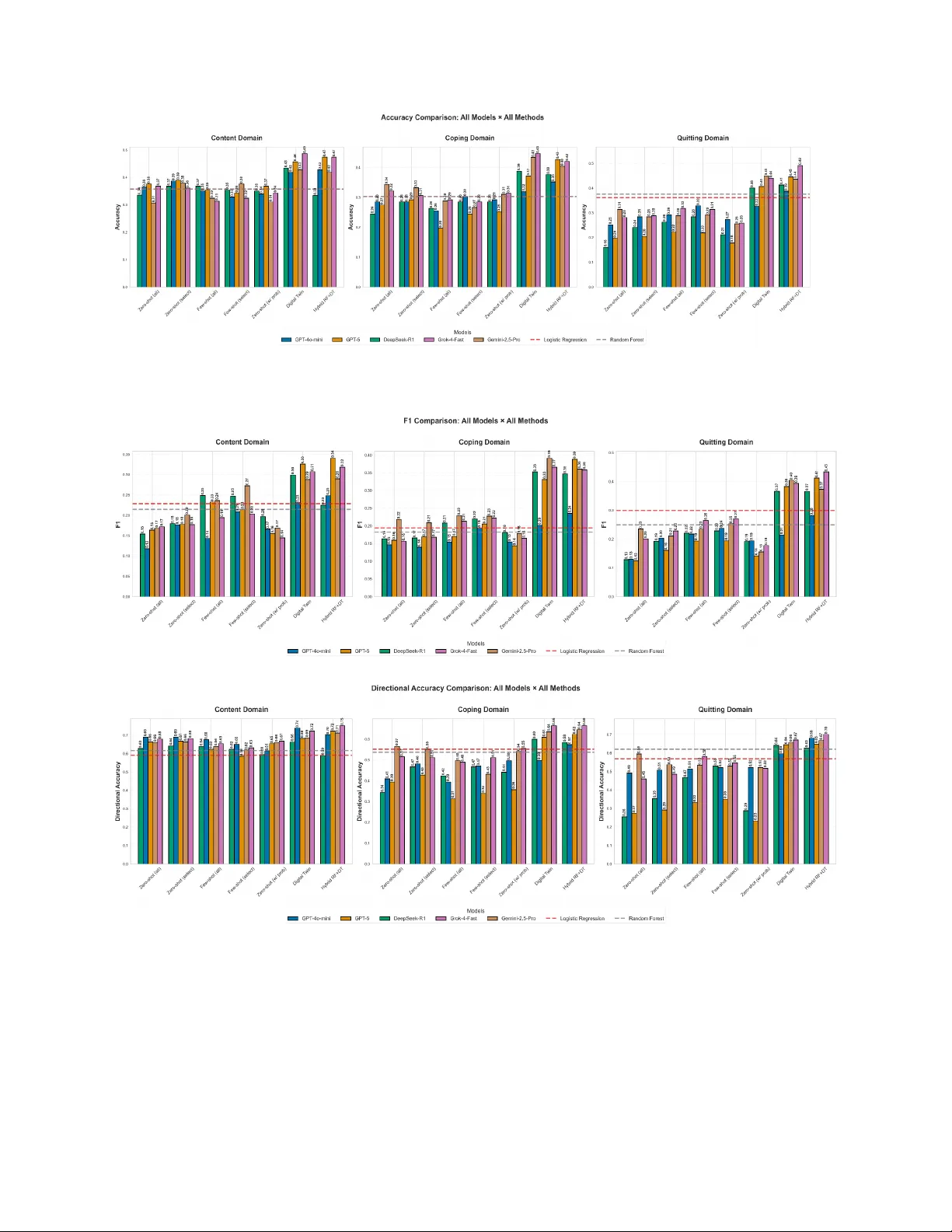
P ers onaliz ed Pred iction o f P erceiv ed Mes sag e Eectiv eness U sing Larg e Languag e Model – Based Digital T wins Jasmin Han 1 , Janardan Devko ta 1 , Joseph W aring 1 , Amanda Luken 2 , Felix Naughton 3 , Roge r Vilardaga 4 , Jonathan Bricker 5 ,6 , Ca rl Latk in 7 , Meghan Moran 7 , Y iqun Chen 8 ,9 , * , Johannes Thrul 1,10,11* 1 Department of Mental Health, Johns Hopk ins Bloomberg School of Public Health, Baltimore , M D , USA 2 Department of Health S ciences, T ow son University , T owson, USA 3 Addiction Research Group , University of East Anglia, Nor wich, UK 4 Department of Impleme ntation Science, W a k e Forest Univ e rsity School of Medicine, Winston - Salem, USA 5 Fr ed H utchinson Cancer Center , Seattle , US A 6 Department of Ps ychology , Uni ver s ity of W ashing ton, Se attle , USA 7 Department of Health, Behavior and S ociety , Johns Hopkins Bloomberg School of Public Health, Baltimore , USA 8 Department of Biostatistics , Johns Hopkins Bloomberg School of Public Health, Baltimore , USA 9 Department of Computer S cience , Johns Hopkins Whiting S chool of Engine ering, Baltimore , U SA 10 Sidney Kimmel Comprehensi ve Cancer Center at Johns Hopkins, Baltimore , USA 11 Centre for Alcohol Policy Resear ch, La T robe Uni ver s ity , Melbourne, Austr alia * Drs. Chen and Thrul share last authorship Correspond ing auth or : Jasmin Han, Department of Me ntal Health, Johns Hopkins Bloomberg School of P ub lic Health, Baltimore, MD , jhan 94@jhu . e du Abstract (2 50/250 ) Objectiv e: P er ceived me ssa ge eectiv enes s (PME) by potential intervention end - us ers is important for selecting and optimizin g personalized smoking ces sation i ntervention message s for mobile health (mHealth) p latf o rm deliver y . T his study evaluates whethe r large language model s (LLMs ) can accura tely pre dict PME for smokin g cessation me ssa ges. Mater ials and M ethods: W e evalu ated multiple models for predicting PME of smok ing ces sation messag es ac ros s three domains: content quality , co ping support, and quitting support. The dataset comprised 3, 010 message r atings (5 - point L i ke r t - scale) from 30 1 young adult smok ers. W e compared (1) super vised learning mode ls tr ained on labe led data , (2) ze ro - /few - shot LLMs prompted without tas k - spe cific fine - tuning , and (3) LLM - based digital twins , which incorpor ate individual characteristics and prior PME histories to gener ate personaliz ed predictions . Model performance was asses sed on three held - o ut (of ten) mes sages per participant usin g accuracy , C ohen’ s κ, and F1. Results: LLM - based digital twins outperformed zer o - /fe w - shot ( +12 percentage points on aver age ) LLMs and super vised baselines ( +13 percentage points ) , achi evin g accuracies of 0.49 (content ), 0.45 (copin g), and 0.49 (quitti ng), with correspondin g directional a ccur a cies of 0.75, 0.66, and 0. 70 for simpl ified 3 - poi nt scale . Digital twin predictions also showed grea ter dispersion ac ross r ating ca tegories , indicating impr oved sensitiv ity to individual dier ences . Discu ssion: We f ou n d that integr ating personal pr ofiles with LLMs cap ture s pers on - spe cific die rences in PME and outperform s super vised learning and ze ro - /fe w - shot LLM approache s. This improved PME prediction could enable mo re t ai lo red inter vention content in mHealth. Conc lusion: LLM - base d digital twin models show potential for predicting PME and may support personalization of mobile smoking cessation and other substance use and health behavior change inter ventions. K ey w ords: Large langua ge models (LL Ms); digita l twins; perceiv ed mes sage eec tivenes s (PME); smoking cessation; personalized inter ventions Introduct ion Despite the decline in US smoki ng prevalence (Centers for Disease Co ntrol and Prevention, 2024; Meza et al ., 20 23) , combustible tobacco use remains a major health issue among young adults . Y oung ad ulthood is a critical developmental pe riod for smoking initiation (V illanti et al. , 2015) an d the formation of l ong - term nic otine dependenc e traj ectorie s ( U.S. Departme nt of Health a nd Human S er vices, 2017) . With the r apid expansion of wear ab le sensors and smartphone - based data col lec tion, flexible and low bur de n mobile health (mHealth) in ter ventions, especially text - based interventions, have demonstr ated strong feasibility , acceptability , and initial eica cy in promoting smok ing cessation (S . Li et al. , 2025; Z hou et al. , 2023) . A centr a l princi ple unde rlying the eecti veness of mHealth inter vention s in recent years is personalizat ion ( Casu et al. , 2025; Kash efi et al ., 2024) . P ersonalized smoking cessation progr a ms aim to move beyond one - s ize - fits - all mes saging by using ind ividual -lev el informa tio n, such as demographic char acteristics, smoking history , mo tivational stat es, psy chological profiles, and momentar y behavior al patt erns (Businelle e t al., 2022; Hébert et al., 2025; Li et al. , 2024; Lin et al., 2 023; Luken et al., 2023; Thrul et al., 2025) , to tailo r message content, timin g, and i ntensity . As a result, understanding and predicting individual - specific perceptions of messag e eectiveness are importa nt tasks in developing evidence - based, personaliz ed mHeal th inter ventions, because pe rceived mes sage ee ctiveness (PME) is associated with downst r eam changes i n beliefs, intentions , and even smoking cessa tion be havior (Noar et al., 2020) and is the ref ore pivotal for intervention optimization and t rial design. Accordingly , much f ormat i ve w ork in mHealth has relied o n user - centered quali tative methods, including f ocus group s, in - depth interviews , and iter ativ e co - d esign, to identif y which f eatur es, mes sage fr ami ngs , and interaction patterns user s lik e or disli k e, or adding additional rounds to refine prototypes across multiple cycles (Abroms et al ., 2015; Ja mison et al., 2013; N agawa et al. , 2022; T ucker et al., 2020) . Building on qualitativ e work, quantitat ive techni ques, including surveys and experimental designs have also been used to understand PME. Despite providing valu able insights for messag e de velopment, these approache s add conside r able lead - in ti me to th e de velopment and dep loyment of mHealth studies . Super vised learning models , including reg ression and tree - based models , have been widely used to an alyze ho w factors such as mess age attributes, demogr aphics, smoking behaviors, and behavior al - economic t r aits ar e rela ted to PME (Hamoud et al., 2025; S olnick et al., 20 21; Thr as her et al ., 201 8; T ripp et al. , 2021) . However , most of this work is explanat or y in n ature , focusing on est i mating correlational relationships or asse ssing variable importance ra t her than gene r ating individual - lev e l predictions of PME. Moving from e xplan ation to prediction is critical for intervention design, as personalized mes sage s election r equire s reliable predic tion of how a specific ind ividual is likely to respond to a given mess age. With the rise of ar tificial intellige nce (AI), recent years have witnes sed a r a pid expansion of studies adapting o - the - she lf large language models (LLMs) to per form predictive tasks. One growing line of work examines the use of LLM s in ze ro - shot and few - shot learning settings (Brown et al., 20 20; Li, 2023 ) , where mo dels oper ate wi th little or no prior example s with known outcomes fr om the t arget study population. These approache s have gained increasing attention in health - related domains (Fernánde z - Pichel et al., 2024; Jin et al. , 202 5; L abr ak e t al., 2024 ) , where data annotation is res ou rce - intensive and often limited in scale. Emer ging evide nce suggests tha t, e ven with minimal task - s pecific supervision, LLMs can support a r ange of downstr e am health applications by tr ansferring gener al domain k nowledge acqu ired durin g large - scal e pretr aining (A grawal et al., 2022; Ge et al. , 2023; Ne ves et al., 2025; Si nghal et al., 202 5) . For e xamp le, Singhal et al. (2025) used thi s approach to genera te answers to medical questions. Among these health app lications are classification tasks, which are also the tasks addr essed in this paper . On the other hand, another line of re search has fo cused o n personalizat ion and explored pers ona - based prompting and detaile d contextual backs tories to conditio n large language model outputs on individual attributes . Thi s work is referr ed to as digital twi n (Katsoulakis et al. , 2024) approaches. Digital twins use individua lized conditioning, such as prior decisions , clinical hist ories, behavior al tr ajectori es, or psyc h ome tric profiles, to condition LLM outputs to represent a specific person (Chen et al., 2025; R. Li et al., 20 25; Makarov et al., 2025; Sprin t et al., 2024; T oubia et al., 2025) . By conditioning on real - w o rld data, digital twins aim to approximate not only typical human behavior but the i diosyncr atic decision - making patterns of a particular individual, and could be useful to assist in development and r efineme nt of health behavior change intervention approaches . For instance, Sprint et al. (2024) used this approach to predict pa tient cognitive health diagnosis. T ak en together , developments in LLMs and LLM - based digital twi ns have the pote ntial to dramatically reduce the time and fi nancial reso urc es req u ire d fo r e a rl y - stage hypothesis testin g, inte rvention refinement, and product development, which is particularly valuable for mHealth personaliz ed i nter ventions such as those designed for smoking cessa tion. In this study , we analyzed data fr om a pane l of young adult smoker s w ho evaluated smoking cess ation messages . Usi ng these da ta , we sys tematically benchmarked a broad suite of LLMs and prompting techniqu es to predict PM E at the indivi dual le vel. Our contri b utions are twof o ld: (1) we explore pr edictive mo deling of PME by eva luati ng seven dier ent pro mp t ing s tr a tegies acr oss fiv e LLM s, and (2) we introduce a pilot an alyti c fr amework that gener alizes to intervention - evaluation settings within and beyond smokin g cess at io n , particularly u nder realistic pers onal ization conditions charac terized by limited per - person da ta . 2. Method s 2.1 Study d esign and populat ion W e conducted a secondar y analysis of data from an online panel study in which young adult smokers evaluated smoki ng cessa tio n messages (Hamoud et al. , 2025) . The parent study was designe d to asses s the eectiveness of evid ence - based digital he alth inter ventions gr ounded in Cognitive Behavior al Ther apy (CB T) (P erk ins et al. , 2013) and Acceptance and Comm itment Therapy (A CT) (Kwan et al ., 2024) fr ameworks for promoting smoking cess ation am ong divers e young adults: CB T - based message s emphasize str ategies for mana ging cr avin gs by redirecting attention th rough specific tas ks or behaviors that serve as distr ac tions. In contr ast, AC T - based message s e ncour age individuals to acknowledge and accept cravings without judgment while maintaining focus on the pres en t moment. Both ther apeutic approaches have been extensively investig ated in prior behavioral intervention res e arch and provide empirically s up port ed fou ndat io ns for digital cessation progr a ms. The study population consisted of 301 young adults aged 18 to 30 years , recruited through an online Qualtrics research panel. Eligible participants had smoked at least 100 cigarettes in their lifetime , reported smok ing every day or on some days , and were e ither currently attempting to quit or intending to quit within the next month. During t he trial, participants evalu ated 12 4 smoking ces sat ion mess ages tha t were d eveloped b y the res earch t eam based on evidence from prior studies and paired with image conte nt obtained fr om free stock photo websites (P exels and Uns plash). E ach participa nt r ated 10 r ando mly selected message s, includi ng five based on CB T stra t egies and five based on ACT str ategies, res ulting in a total of 3,010 message r atings or an aver age of 24 r atings per messag e (Kim & Cappella, 2019) . P articipants completed an online survey in whi ch they ra ted eac h messag e across four domains: perceived quality of content (“How would you r ate the c ontent (that i s, the wor ds and meaning ) of this message ?”); (2) pe rceived quality of design (“H ow would you r ate the design (that is, how the message looks) of this message ?”); (3) perceive d mess age support for copin g with smok ing urges (“How helpful would thi s message be to support you in coping with a smokin g urge or cr aving ?”); (4) p erceived message support for quitting smoking (“H ow helpful would thi s message be to support you in quittin g or reducing smoking ?”). Resp onses for content and desi gn were r ated on a five - poi nt Lik ert scale with the follo wing optio ns: V er y poor , P oor , Acceptable , Good, and V ery goo d. Responses for coping suppor t and qui tting support were r ated on a five - point Likert scale with the follo wing options : Not at all helpful, S omewhat helpful, Mode r ately helpful, V er y he lpful, and Extremely helpful. Par ti cipants were also given the option to prov i de written feedback on the message s. In addition to message r atings , participants comple ted questions asses sin g their sociode mographic characteristics (age , sex, se xual orie ntati on, r ace/ ethnicity , household income , and educati on level), smok ing beha viors and cessation factor s (number o f days smoked in the past 30 days, aver age cigarettes per smok ing day , living with smoker s, having friends who smoke , past - year quit attempts, moti vation to quit, social support for qui tting , current daily s mokin g status , time to first ci garette , and qu it intention), and psychological fle xibility , whi ch was measured using the 7 - item A cceptan ce and Action Questionnaire – II (AAQ - II (Bond e t al., 2011)). 2.2 Mo dels T o e xpl ore how LLMs can supp ort the des ign of more eective smok ing ces sation inter ventions , we implemented a series of models to predict multiple dime nsions of smoking cess ation message r ating s. In this pap er , we fo cus on three of the four r ating dimens i ons, i. e., content, copin g, and qui tting , since desi gn reflects the characteristics of the accompanying image. W e excl ude d the design dimension for both methodological and pr actical consi der ations. Pr eli minary analysis revealed high corr el ations between de sign and content r atings, indicating that participants evaluated mes sages holistically r ather than distinctly separ ating visual design eleme nts from te x tual content. Additionally , given that current LLMs (Octo ber 2025 ) perform mar kedly better on text than image inputs, focusing our analysis on the three text - based r atings could improve modelin g eiciency while maintaining the c ore pr edi ctive capabilities needed to asse ss PME, aligned with our primar y interest in op timiz ing the text conte nt of in ter vention m essa g es. We evaluated methods across thr ee categories: (1) tr ad itional super vised le arning baselines, (2) LLMs wit h ze ro -/ few - shot settings, and (3) “ digita l twin ” approache s, impleme nted as LLMs conditioned on (i) structu red participant profiles and (ii) parti cipant - specific hi stories of pri or mes sages and r atings. For the LLMs and di gital twin cate gories, we evaluated five popular LL Ms with default API par ameters : G PT - 4o - mini and GPT - 5 (OpenA I), DeepSeek - R1 (DeepSeek), Gr ok -4- Fast (xAI), and Ge mini - 2.5 - Pro (Google ). For all the mode ls, w e used within - participant splits (7 mes sages for training/histor y; 3 held out for testing). Su per vised baseli nes were fit on the 7 labele d messages and evaluated on the 3 held - out messages . Zero -/ fe w - shot LLMs receiv ed only th e held - out message text (plus instructi ons/ demonstr ati ons). Di gital - twin LLMs additionally received the participant profile and the 7 history mes sage – r ating pairs , but never the held - out messages o r rat i n g s . Prom pts were progr ammatically ass emble d from mes sage IDs to ensure held - out items could not be inclu ded in the history block; results are r e ported on held - ou t messages unless noted. 2.2. 1 Supervised learn ing models b ased o n patien t char acteri stics only T wo conventional machine learning model s served as non - LLM baselines: a reg ula riz ed logistic regres s ion (L2 p enalty with C= 1.0) and a r ando m fore s t classifiers (default par ameters in scikit - learn; Kramer , 2016) . Both models utilized part icipant - level f eatur es only , including age , ge nder , r ace/ ethnicity , ni cotine depende nce (time to first cigarette ) , cigarette s pe r day , and psy chological flexibility . Model training and evaluation f ollowed the same data splits applied to the LLM - based methods described above . 2.2.2 Z ero - shot and few - shot LLMs For LLMs, w e compared five prompt s t ra t e g i e s that varied in the a mount of participant conte x t and calibr ation structur e provided to th e model. We include the detailed prompts in Appendix A1 . 1. Zer o - shot with all features ( Ze ro - shot (a ll) ): Thi s template includ ed all individual char acteristics (sociodemogr aphi c variables, smoking behaviors and cess ation factor s, and psychological flexibil ity items, totaling 23 fe ature s ) and queried the LLMs to genera te cate gorical predictions for content, coping, and quitting. 2. Zer o - shot with sele cted features ( Ze ro - shot ( select)): Here , we res tri cted the me tadata to five hi gh - c overage variables associa ted with s moking patterns and cessa tion readiness : A ge, sex , r ace/ ethnicity , self - r eported motivation to quit, and perceived social support. These variables wer e c hosen based on the magnitude of correlation. The anal ysis was designed to test whether a s mall yet informative set of individual char a cteristic s could lead to performant LLM predictions compared to 1. 3. Few - shot wi th all features ( Few - s hot (all) ): Th is temp late extended the zero - sh ot prompt in 1. by prepending two r andom ly - selec ted exam ples with extreme r atings per domain (“V er y good”/“E xtremely help ful” and “V er y po or”/ “Not at all helpf ul”) sample d from the tr aining set. E ach example included participants ’ char acteristics , message content, and r atings. This setup allows the mode l to obser ve how dierent messages are evaluated by participants with dierent profiles a cros s the full r ange of r atin gs , be for e gener a ting its predictions . 4. Few - shot wi th selecte d featur es ( Fe w - s hot (select) ): This template mirrored the configura ti on described in 3 but trun cated participant features in both the example and the target quer y to the five selecte d char acte ristics. It was designed to test whether reference example s con tinue to improv e performance when the prompt is ag gressiv el y compr essed. 5 . Z ero - shot w ith selected f eatur es and probability - lik e outputs : ( Ze ro - shot (w/ prob) ): This variant used the same c onfigur ati on as the z e ro - s hot with selec ted, while prompting the LLM to provide relative lik el ihood scores for each r ating categor y . Although these scor es are directly r epo rted by the LLM and do not repre sent calibrat ed probabilities, they are trea ted as probability - lik e outputs to support the final classification . 2.2. 3 LLM - base d d igital t wins This fr amework can be viewed as an extension of the fe w - shot LLM paradigm , with the f ew - shot example s now contextualiz e d at the individual level, incorpora tin g each participant’ s persona and 7 historical response s (T oub ia et a l., 2025) to build participant profiles . Using these profiles , we evaluated two configu r ations : (1) a basic profile with all individual char a cteri stics, and (2) an enhanced p rofile that also incorpora ted random - fores t predictions as prior information. An example prompt for the digital t win s is pro vided in A ppendix A1 . 2.3 Eval uation m etr ics We evaluated model performance us ing five me trics. F irst, we used exact accuracy , defined as the proporti on of predictions that matched the true message r ating on the five - point Lik er t scale . This metric is s tr aightforward to interpret but might be non - discrim inative in the presence of clas s imbalance , e .g., our dataset skewed towar d the two most positive categories (“V er y good/E xtremely he lpful” and “Good/V er y help ful”). Moreover , accuracy does not dierentiate be tween types of predi ction errors (e .g., ov er - vers us under - predictio n of the scores) . Second, we used Co hen's κ, which quantifies the model - vs. - ground truth agreement af ter adjusting for chance. Thir d, we included macr o - aver aged F1 acros s the five Lik er t scale s . F1 scor e balances precision (how many pr edicted positives were correct) and recall (how many a ctual positi ves wer e de tected), and the ma cro - a v e ra g e a llow s each clas s to contribute equally to the over all performance , but might ove r - penaliz e errors on r are clas ses. While accura te ly predicti ng the granular five classes was our primar y goal , pr actical mes sage optimization of ten only needs the rat ings to be directional correct . We theref ore collapsed r ating s into three cate gories, mapping V ery helpful and Extremely hel pful to positive , S omewhat helpful and Not at all helpful to negativ e, and retaining Neutr al. Based on these categories, w e computed (1) directional accuracy , which capt ures whether predictions ali gn with th e correct direction o f change, and (2) directional macro - F1, computed on directional agreement r ather than exact r ating match. We also r ep ort bootstr ap confidence inter vals for the metrics in A ppendi x A2, comple menting the point estimates in the mai n text. 2.4 T op - K Message Sele ction E valuation From a tr anslational perspective , investigato rs seek to lever age these models to prio ritiz e inter vention content for r eal - world deployment. T o evaluate the pr actical utili ty of LLM - based mes sage scoring, we as sessed whether Digital T win prompting e nables e icient identifi cation of highly r ated messages . We treated ordinal r ating scales as numeric (1 – 5) to enable quantitativ e comparison. For each domain, we selected the top - K message s (K = 5, 10, 15, 20, 25) usi ng three str ategies: (1) LLM predicte d r atings with Digital T win prompting, (2) a human "or acle" using a ctual human r atings, and (3) r an dom selec tion. Code to reproduce our analysis is available at https:// github . com/yiq unchen/LLM - smoking - c essa ti on / . The source mes sage data can be found at https:// osf .io/4ux8q/ over view . Results Figur e 1 presents the overvie w of the study design. D etailed descriptive analyses of participant char acteristics can be found in Hamoud et al (H amoud et al., 2025) . We display the best - performing con figur ation for e ach mode l acros s r ating doma ins in Figure 2. Over all, pers o nalized LLM - based digital twinshad the best performance. The best - performing personal ized LLM pipe lines achieve d exact accur acies of 0.49 (conten t), 0.45 (coping ), and 0. 49 (quitt ing), and directional accuracies of 0.75, 0.66, and 0.70, respectively . These results outperformed both zer o -/ few - shot prompting (≤0. 39) and super vised baseli nes (≤0.38). GPT - 5's hybrid model achie ved 0.47 acc ur acy ( κ =0.25 ) fo r content, 0.4 3 ( κ=0. 24) for coping, and 0.45 ( κ=0. 27) for quitt in g. Grok -4- Fast' s hybrid configura ti on attained the over all highest quitting a ccur acy (0.49, κ=0. 30), while its digit al twin achieved 0.49 ( κ=0. 24) for content and 0.45 ( κ= 0.24) for copin g. Ge mini - 2.5 - P ro's digital twin pe rformed best for quittin g (0.45, κ=0. 26) and coping (0.43, κ=0.23). Digital twin personalizat ion also elevated DeepS eek - R1 (0.44, κ=0.2 0 for content) d espite modest zero - shot performance . Lo gistic regr ession and r a ndom for est baselines ranged from 0.3 0 - 0.38 accur acy with κ ≤0. 12 a cr oss d om ai ns. 3.1 Comparison of m odeling s t rategies Ze ro - s hot prom ptin g across all LLMs pr oduced 24.2 - 39.1% accu r acy (mean 28 - 32% per model) with κ values ne ar zer o, only mar gin ally ex ceedi ng supervised baselines. Incorpor ating six to ten example s in fe w - s hot prompts yiel ded modest gai ns (≤4 percentage points). In contr ast, digital twin personalization increased accur acy into the low - to - mi d 40% r ange and raised κ to 0.18 - 0.24. Hyb rid pipelines further improved performance for GPT - 5 and Grok -4- Fast , adding 1 - 6 perc e ntage points over the corresponding digital twin configura ti ons. P erformance he terogeneity across LLM vendors reached 10 perce ntage points with in the same me thod family , reinforcing that model choice materially ae cts downstream a ccur a cy . Directional metrics highlight p r actical utility even when exact agreement is limited. Hybrid GPT - 5 a chieved 72.2% directional accuracy for content (D irectional F1 =0.56), 62.2% for coping (Directional F1= 0.54), and 64.8% fo r quitti ng (Di rectional F1 =0. 55). Gro k -4- Fa st 's hybrid quitti ng model yi elded 70.0% directional accur acy (Di rectional F1=0.54). Macro - F 1 scores r ema ined mode st (0.34 - 0.43), reflecting class imbalance and human var iability , yet stil l ex ceeded sup er vised ba selines b y 8 - 12 poi nts. 3.2 Distrib ution of predicted s core s acro ss m odels Figur e 3 show s the distribution o f predicted score s acros s models . The true s core distribution was concentr ated in three categories , i. e. , the one neutr al and two more fav or able c ategori es, while the t wo nega tive c ategor ies wer e selected but le ss frequent ly . T r aditional super vised learning models and zero - sh ot/fe w - s hot LLMs te nded to concentr ate their predictions within one or two categorie s. In contrast, the digital twin models p roduced predictio ns that wer e more spr ead across all five categories . 3.3 Contrasting message s selected by LLM v e rsus human r ate rs Figur e 4 show s that LLM - selec ted mes sages , especially those chosen by Grok - 4 and GPT -5 , consistently achieved higher mean human ra tin gs than r andom selection across al l three domains . All LLMs fel l b ehind the human oracle , but the gap was small (<0. 5 on a five - point scale) and decreased a s more me ssag es wer e selected. Discu ssion In this study , we evaluated the capacity o f LLMs to predict the perceived eecti veness of smoking cess ation inter vention mes sages, an essenti al step towards persona lized digital health inte rventi ons. Acros s three mess age domains (content, copin g, and qu itting ), zero - shot and few - shot LLMs performend similarly (b est accur a cies: 0.39, 0. 34, and 0.33, respectively) to tr aditio nal machine learning baselines (accur acies: 0.30 - 0.38). Not ably , personaliz ed digital twi n models substantial ly outperformed all other approac hes (best accur a cies: 0.49 for co ntent, 0.45 for c oping, and 0.49 for quitting). When ev aluated using direction al a ccur a cy me trics, whi ch assess whe ther mod els co rrectl y predi cted the relative or de ring of message eectiveness , the best - pe rforming digital twin models achieved directional accur acies of 0.75 (content), 0. 66 (coping ), an d 0. 70 (quitting ). In addition to higher accuracy , digital twin p redictions exhibited gr eater dis pe rsi o n a cross r ating categ ori es compared with tr aditional ML and zer o /few - shot LLMs , indicating impr oved sensitivit y to individual - lev el heter ogeneity in mess age percep tion. Digital twin - bas e d modeling presents substant ial opportunities to advance the development of personalized mH ealth inter ventions for smoking ces sation. For example , it enables the personalized selection of previously tested messages , as well as the evaluation of new messages f or each indi vidual , based on the prefer ences learned from their digital twin. In addition to LLM - power ed digital twins th at are condition ed on static history like our study , the y can also be conditioned on dyna mically changing information (Makarov et al., 2025; Silva & V ale, 2025) . As wearable sensor s, smartphones, and passiv e monitoring technologies continue to genera te r ich str e ams of real - world behavior al and physiological data, reco rd s such as an individual’ s momentar y behavior patterns, conte x tual state s, and prior responses to treatment (Businelle et al. , 2022; H ébert et al., 2025; Li et al ., 2024; Lin et al. , 2023; Luken et al ., 2023; Th rul et al. , 2025) could be valuable . Within smoking c es sation, these data streams a re par ticularly valuable given the pronounced hetero gene ity in triggers , m otivational tr aje ctories , withdr awal symptoms, and relapse dynamics acr oss individuals. By modeling these personalized patterns , digital twins may support the design of adaptive and context - aware intervention protocols , su ch as selectin g coping me ssage s most lik el y to be eecti ve for a specific user at a specific moment or ta iloring conten t to match dynami c risk states . Our findings also hi ghlight p otential li mitations of usin g models focusing on population level trends (e.g., traditional super vised learni ng and o - th e - shelf ze ro - shot or few - s hot LLMs) for identif yi ng speci fic individual behavi or , such as PME. Al though prior work has mostly applied regr ession and super vised learning models to identif y linguistic or contextual features associa ted with PM E (Ham oud et al., 2025; So lnick et al., 2021; T ripp et al., 2021) , in our study , traditional models’ accuracy r anged from 30.3% to 37.6%. Simila rly , despite gro wing evide nce that zer o - shot and few - shot LLMs (Brown et al. , 2020; Li, 2023) can appro ximate human judgments, their per formance in this task remained limited, achie ving a ccur a cies o f onl y 0.3 3 - 0.39. In cont r ast, personalized digital twin models produced meaningful improv eme nts, r eachin g 0.45 - 0.49 a cross the three message domains. While these gains highlight the promise of individual - level conditioning , the best - performing digital twins still leave room f o r improv ement in fully predicting par ticipants’ exac t r atings . One plau sible explanation is the inherently noisy natur e of individual human behavior . E ven within - person consi stency is impe rfect: the test - r e test reliability for individual choices in pri or work has been estimated at appr oximately 81% (P a rk et al., 2024; T oubia e t al., 2 025) . This suggests that a substantial pr oportion of variance in PME reflects intr a - i ndividual fluctuations, such as m omentar y aect, context, attention, or cognitive load, that are neither captured in static metadata nor easily recov erable fr o m simple prompt s. Evaluated on dir ec tional consistency ra ther tha n exact ca tegory a greement, digital twin models achieved accurac ies of 0.66 – 0.75, indi cating that even when models missed the precise r ating , they of te n correctly inferred pos itive , n eutr al, or negative attitu des . This distinc tion is meaningful becaus e PME in our study relied o n a 5 - point scale , and prior work suggests that indi viduals may var y in how they apply such scales due to factor s such as personality and culture (Kemmelmeier , 2016; N aemi et al. , 2009; P ok ropek et al. , 2023) . As a res ult, some individuals fav or the endpoints of the scale, wher eas others gr avitate towar d midpoints regar dless of underlying judgments. Given this k nown variability in r ating behavior , the pr actical v alue of exact - categ or y prediction for personalized intervention design remains an open question. For many applications in digital heal th, particularly those aimed at sele ctin g or tailorin g message conten t, a model’ s capacity to correctly identif y whether a message elicits a positive or nega tive reaction from an individual may be more cons e quential than matching the exact intensi ty of that r eac tion. The distribution of predicted scor es fur ther helps contextualize why digital twin models outperformed both super vised learning and o - the - shelf ze ro -/ fe w - s hot LLMs. Digital twins’ broader sc ore dispe rsion suggests that the y wer e more sensitive to capture nuanced dierenc es in individuals ’ PME acros s mes sages, r ather than defaulting to a narro w band of response s. Such behavi or is consistent with the f act that di gital twins i n c o r p o ra t e pe rso n - spe cific histori cal cha r acteristics and ra tin g data, enabling them to learn indi vidual prefer ence patterns r ather than popu lation - lev el aver age s. For mH ealth inter ventions focused on per sonali zation , suc h as tailoring text - based smoking ces sation inter ventions , this sensitivity is particularly valuable. Despite their promising performance , sever al li mitations of this study warrant consider atio n and highlight important dir ections for futur e work. Fir st, this study dr aws on data fr om 301 young adult smoker s who were members of an online mark et res earch pane l, which may limit gener alizability . T r aining digital twins on larger , more diver se samples would impr ove external validity and help determine whe ther the obser ved performance gains extend acr oss demographic and behavioral s ub groups . S econd, the high noise of human rating s constr ained the pe rformance of the tested models. Futur e work may bene fit from collecting mul tiple repe ated asse ssments per message . Thi rd, ex cept for the models reported in this paper , we al so e xplored incorpo r ating pretr ained language model embeddi ngs to pr ovide richer semantic representations of mes sage conte nt, these features did not meaning fully impro ve predictive accur acy . This sug gests that static embed ding - based semantic information alo ne may b e insuicien t for modeling fine - gr ained, i ndividual - lev el dier ences in PME. Fourt h , incorpor ating domain knowl edg e about message cate gor ies (e . g., CB T vs. A CT) produced only modes t per formance gains. This suggests that while domain information has potential value, its impact may be limited in static modeli ng setti ngs . Future research could explore integr ating time - s eri es data within both LLM - based digital twins and other modeling framewo r ks , i ncluding tr ansformer - based seq uence architectur es.Finally , while PME is a useful pr oximal indic ator of intervention message quality , i t may not fully capture actual behavioral impact (O’Keef e , 2018) . Future st udies s hould e xamine the applicatio n of LLM - based digital twin approache s i n real - wo rld inte rvention settings to de termine the ir abili ty to optimi ze behavior al outcomes. Conc lusion In conclusion , this stud y evaluated the eicacy of LLM - based approaches for pr edicting PME in the context of s moking cess ation inter vention mess ages. Digital twin models, which condition predictions on an individual’ s historical data, demonstr ated the hig hest accur acy . These findings highlight the potential of LLM - based digital twins to support the development of more personalized and ee ctive mobile health inter ventions for smoking ces sation and other he alth behavior change targets. Furt her validation is needed in larger , more div e rs e populations and in prospective studies designed to evaluate real -w orld optimization and behavioral outc omes. Refer ences Abroms, L. C ., Whi ttak e r , R., Free , C ., V an Alstyne, J . M. , & Schi ndler - Ruwi sch, J . M. (2015). Developing and pretes ti ng a text mes saging progr am for health behavior change: rec ommended s teps. JMIR mHeal th and uHealth , 3 (4), e49 17. A gr awal, M., Hegselmann, S., L ang, H., Kim, Y ., & Sontag , D . (2022). L arge language models ar e few - shot clinical information ex tractors . ar Xiv preprin t arXi v:2205. 126 89 . Bond , F . W ., Haye s, S . C ., Baer , R. A., Carpen ter , K. M., Gueno le , N., Or cutt, H. K.,… Zettle , R. D . (2011). Preliminar y psychometric properti es of the A cceptance and Action Questionnair e – II: A revised measure of ps ychological inflexibility and experiential avoidance . Behavior therapy , 42 (4), 676 - 688. Br own, T ., Man n, B., Ryder , N., Subbi ah, M., K aplan, J . D ., Dhariwal, P .,…Ask ell, A. (20 20). Language models are few - shot learners. Advances in neural inf orm ation proces sing sys te ms , 33 , 18 77 - 1901. Businel le , M. S ., Gar ey , L., Ga llagh er , M. W ., Hébert, E. T ., V ujan ovic , A., Ale xander , A .,…M ontgomer y , A . (2022). An integra te d mHea lth app for smoking cessation in Black smok ers with anx iety: protocol for a r andomized control le d trial. JMIR Research P rotocols , 11 (5), e38 905. Casu, M., Guarner a, F ., L a Rosa, G. R. M., Battiato , S., Caponne tto , P ., Polosa, R., & Emma, R. (2025). Smokin g Detection and Cessation: An Updated S copi ng Revi ew of Digital and Mobile Health T echnologies. IEEE Journal of Biomedi cal and Health Informatics . Centers for Disease Co ntrol and Prevention. (2024 ). Current cigarette smoking among adults in the United States . https://ww w . cdc .gov/ tobacco/php/ data - statis tics/ adult - data - cigarettes/index.html Chen, S., L alor , J . P ., Y an g, Y . , & Abbasi, A . (2025). P e rsona T wi n: A Multi - Tier Prompt Conditioning Fr amework for Gener ating and Evaluating P ersonaliz ed D igital T wins. Proceedings of the Fourth Work shop on Gene r ation, Evaluation and Me trics (GE M²), Fernánde z - Pichel , M., Losad a, D . E., & P i chel, J. C . (2024). Large langua ge models for binary he alth - rela ted question ans wering: A zer o - and few - shot evaluation. International Confer e nce on Computational S cience , Ge , Y ., Guo , Y ., Das , S., Al - Gar adi , M. A ., & S arker , A . (2023). Few - shot learning for medical text : A review of advances, tr e nds, and opportunities. Journal of Biome dical Informatics , 144 , 10445 8. Hamou d, J ., Devk ota, J ., Re gan, T ., Luk en, A., W aring, J ., Han, J . J .,…Latkin, C . (2 025). Smoking c essa tion message testing to inform a pp - based i nterventions for young adults– an online experiment. BMC public health , 25 (1), 1 852. Hébert , E. T ., K endz or , D . E., Vidr ine , D . J ., Langf ord, J . S ., Ke zber s, K. M., Montgomery , A .,… Che n, S. (2025). Just - in - Time Adaptive Intervention for Smoking Cessa tion in Low - Income Adults: A Randomized Clinical T rial. J AMA Net work Open , 8 (8), e2526691 - e 252669 1. Jamison, J., Naughton, F ., Gilbert, H., & Su tton, S. (2013). Del ivering smoking c ess ation support by mobil e phone text mes sage: what information do smokers want? A focus gro up study . Journal of A pplied Biobeh avioral Research , 18 (1), 1 - 23. Jin, Y ., L iu, J ., Li, P . , W ang, B ., Y an, Y ., Zhang, H., …Bu, Y . (2 025). The Appli catio ns of Lar ge Language Models in Me ntal Health: S coping Revie w . Journal of Medical Internet Research , 27 , e69284. Kash efi, A ., Bo ssc haerts , K., Murp hy , S., V an Hoeck e , S ., V ande n Abeele , M., De M are z, L.,…Conr adie , P . (2024). Unlocking the potent ial of mhealth for smokin g cessa tion: An expert viewpoint. Int ernational confer ence on human - computer in teraction, Ka tsoula kis, E., W ang, Q ., W u, H., Shah riyari, L ., Fletch er , R., Li u, J .,…Deng, J . (202 4). Digital twins for health: a scoping review . NP J Digit Med , 7 (1), 77. https: // d oi.or g/10. 1038/ s 41746 - 024 - 0 1073 - 0 Kemmelmeier , M. (201 6). Cultu r al die rences in sur vey re s ponding: Issues an d insights i n the study of response biases . Intern ational Journal of Psychology , 51 (6), 439 - 444. Kim, M., & Capp ella, J. N. (2019). A n eicient message evaluation pr o tocol: two empi rical analyses on positional eects and optimal sample size . Journal of Health Communi cation , 24 (1 0), 761 - 7 69. Kr amer , O . (2016). S ciki t - learn. In Machine lear ning for evolution str ategies (pp. 45 - 53). Springe r . Kwan, Y . K. , La u, Y ., Ang, W . W ., & Lau, S. T . (2024). Imme diate , short - term, med ium - term, and long - term ee cts of acce ptance and co mmitme nt therap y for sm oking cess ation: a systematic review and me ta - analysis. Nicotine and T obacco Research , 26 (1), 1 2 - 22. Labr ak, Y ., Ro uvier , M., & Du four , R. (2 024). A z ero - shot and few - shot s tudy of instru ction - finetuned large language models applied to clinical and biomedical tasks . Proc ee dings of the 2024 Joint International Co nference on Computa ti onal Linguistic s, Langu age Resources and Evaluatio n (LREC - COLING 2024), Li, R. , Xia, H., Y uan, X., Do ng, Q ., Sha, L. , Li, W ., & Sui, Z. (2025). How far are l l ms from bein g our digital twins? a be nchmark for pe rsona - based behavior chain simu lation. arXiv preprint a rXiv:25 02.1 4642 . Li, S ., Li, Y ., X u, C ., T ao , S., Su n, H., Y ang, J .,…Ma, X . (2025) . Eicacy o f digit al interven tions for smoking ces sation by type an d method : a systematic review and network me ta - analysis. Natur e Huma n Behaviour , 1 - 12. Li, Y . (2023). A practical sur vey on zero - shot prompt design for in - context learning. ar Xiv preprint a rXiv:23 09.1 3205 . Li, Y ., Lu k, T . T ., Ch eung, Y . T . D ., Zhao , S ., Zeng, Y ., T ong, H. S. C .,… W an g, M. P . (2 024). Engagement with a mobile chat - based inter vention f or smoking cessation: a secondary anal ysis of a r ando miz e d clinical trial. JAMA Network Open , 7 (6), e241779 6 - e24177 96. Lin, H., L i, X., Zhan g, Y ., Wen , Z., Guo , Z., Y ang, Y ., & Chang, C . (2023 ). A r andomiz ed controlled trial of pers o nalized te xt messages for smoking ces sation, China. B ulle tin of the Worl d Health Organization , 101 (4), 271. Luk en, A., Desja rdins , M. R., Mor an, M. B ., Mend elson, T ., Zip unnik ov , V ., Kir chner , T . R., … Thrul, J . (2023). Using smar tphone sur vey and GP S data to inform smok ing ces sation in ter vention delivery: case study . JMIR mHealth and uHealth , 11 (1), e43990. Maka rov , N., Bor duk ova , M., Quengdae ng, P ., G arger , D ., Rodrig uez - Esteban, R., Schmich, F ., & Menden, M. P . (2025). Large lang uage model s forecast pa tie nt heal th tr ajectories enabling di gital twins. npj Digital Medicine , 8 ( 1), 588. Meza, R., Cao, P ., Jeon , J ., W arner , K. E. , & Lev y , D . T . (2023). T rends in US adu lt smoking prevalence, 2011 to 2 022. JAMA H ealth Foru m, Naemi, B . D ., Beal, D. J ., & P ayne, S . C. (2009). P ersonality predictors of extreme r esp onse s ty l e. Journal of pe rsonality , 77 (1), 261 - 286. Nagaw a, C . S., Lane , I. A., McK ay , C . E., Kamb eri, A ., Shenet te , L. L., K ell y , M. M.,…Sadas ivam, R. S. ( 202 2). Use of a rapid qualitative method to i nform the development of a text mess aging inter vention for people with se rious mental illnes s who smoke: fo rmative resea rch study . JMIR Formative Resear ch , 6 (1 1), e409 07. Neve s, B ., Mor eir a, J . M., Gon çalve s, S ., Cer ejo , J ., da Silva, N. A ., Leite , F ., & Silv a, M. J . (2025). Z ero - s hot learning for clinical phenot yping: Comparing LLMs a nd rule - based methods. Computers in Biology and M edicine , 192 , 110 181. Noar , S. M., Barker , J., Bell, T ., & Y zer , M. (20 20). Does pe rceived mes sage e ectiveness predict the act ual eectiveness of tobacco ed ucation messages ? A systematic review and meta - analysis. Health communication , 35 ( 2), 148 - 1 57. O’Keefe , D . J. (2018). Message pretesting using assessments of expected or perceived persu as ivenes s: E vidence about diagnosticity of relative actual persuasivenes s. Journal of Com munication , 68 (1), 120 - 142. P ark, J . S., Zou, C. Q ., Shaw , A ., Hill, B. M. , Cai, C ., Mor ris, M. R.,…Berns tein, M. S . (202 4). Gener ative agent simulations of 1, 000 people . arXiv preprint ar Xiv:2 411. 10109 . P erkin s, K. A ., Conklin, C. A., & Levine, M. D . (2013). Cogniti ve - behavioral ther apy for smoking cessation: a practical guidebo ok to th e most eective treatments . Routledge . P okropek, A., Khorr amd el, L. , & von Davier , M. (2023). Detecting a nd Dierentiating Extreme and Midpoint R esponse Styles in Rating S cales using T ree - Based Item Respo nse Models: Si mula tion Study an d Empirica l Evidence . P sychological T est and Asses sment Modeling . Silva, A., & V ale, N. (2025). Digital T wins in P ersonali zed Medicine: Brid ging Inn ovation and Clinical Reality . Journal of P ersonaliz ed Medicin e , 15 (11), 503. Singh al, K., T u, T ., Got tweis , J ., Sayr es, R., Wulc zyn, E., Amin , M.,… Col e - Lew is, H. (2025). T oward e xpert - level me dical question answ erin g with large language models. Nat ure Medicine , 31 (3), 943 - 950. Solnick, R. E., C hao , G ., Ros s, R. D ., K r aft - T odd, G. T ., & K oche r , K. E. (2021). Emergency physicians and pers ona l narr atives impro ve the perceived eectiv eness of COVID - 19 public health recommendations on social media: a randomiz ed experiment. Aca demic Emergen cy Medicine , 28 (2), 172 - 183. Sprint, G ., Schmitte r - Edgecombe, M., & Cook, D . (2024). Buil ding a hu man digital twin (hdtwin) using large language mode ls for cogni tive diagnos is: Algori thm development and validation. JMIR Format i ve Research , 8 , e63866. Thr asher , J . F ., Islam, F ., Davis , R. E., P opo va, L., L ambe rt, V ., Cho , Y . J .,…Hamm ond, D . (2018). T esting cessation messages f or cigarette package inserts: findings from a best/wor st di screte choice experiment. Inte rnational Journal of Environmental Research and Publ ic H ealth , 15 (2 ), 282. Thrul , J ., Devk ota, J ., W aring, J . J ., Desjar dins , M. R., Hamo ud, J ., Han, J ., …Latkin, C . (2025). App - Based Smoki ng Urge Reduction Inter vention for Y oung Adu lts: Protocol Combining a Micror andomized T rial and Conventional Between - Subject Randomized T rial. JMIR Research Pr otocols , 14 (1), e7438 8. T oubia , O ., Gui, G . Z., P eng, T ., Merlau, D . J ., Li, A., & Chen, H. (2025) . Databa se rep ort: Tw i n - 2k - 50 0: A data set for building digital twins of over 2,000 people based on their answ e rs to over 500 questions. Mark eting S cience , 44 ( 6), 1446 - 1 455. T ripp , H. L., Stric kland, J . C ., Mer cincav age , M., Aud r ain - McGo vern, J ., Donn y , E. C ., & Str asser , A . A . (2021). T a ilored cigarette warnin g mes sages: how individualized loss aversion and delay discounting r ate s can influence perceived mes sage eecti venes s . Inter nati onal journal of envir onmental resear ch and public health , 18 (19), 10492. T uck er , J . S ., Linnemayr , S., P eder sen, E. R ., Shadel, W . G ., Z utshi, R ., & Mendo za - Gr af , A. (2020). De veloping a text messaging - based smoking cessa ti on intervention for young smok ers experiencing homelessnes s. Journal of S moking Cessa tion , 15 (1), 35 - 43. U. S. Departme nt of Health and Hu man Se rvi ces. (2017). Preventing tobacco use among youth and young adu lts: Fact sheet . https://w w w .hhs.gov/ sur geongener al/reports - and - publications/ tobacco/prev enting - you th - t obacco - use - f acts heet/i ndex.html Villanti, A. C ., P earson, J . L. , Cantrell, J . , V a llone, D . M., & Rath, J. M. (2015). Pa tterns of combustible tobacco use in US young adults and potential response to gr aphic cigarette health warning labels. Addictive behav iors , 42 , 1 19 - 125. Zhou, X ., W ei, X., Ch eng, A ., Liu, Z ., Su, Z., Li , J .,…Huang, Z. ( 2023). Mobi le phone – based inter ventions for s moking cess ation among young pe ople: systema tic review and meta - analysis. JMIR mHealth and uHealth , 11 (1), e48253. Figure 1. Over view of st udy design , model typ es, and k ey find ings in evaluating l arge languag e models f or pr edicting s elf - r ated smoki ng - ce ssa t io n mess age e e c ti ve n ess. P anel 1 su mmarizes the study dataset of 301 young adul ts (ages 18 – 30) who r ated 124 cognitiv e - behavio r al and acceptance - co mmitment – b ased message s (3,010 total ra ti ngs). P anel 2 outlines the mo deling approaches , i ncluding traditional s upe rv ised machine - lear ning baselines, z ero - shot and few - shot la rge language models (LLMs), and personaliz ed L LM - based “digital - twi n ” mode ls. P anel 3 highl ights ou r findings. Figure 2. B est - perform ing con figur at ion for each mod el across r ating domain s . Comparison of five evaluation metrics (a ccuracy , F1 , di rectional accu r a cy , di rectional ma cro - F1, and Cohen's κ) acros s mode ls (GPT - 4o - mini, GPT - 5, DeepSeek - R1, Gr ok -4- Fas t, and Gemini - 2.5 - P ro) and configurations (z e ro - s hot with all feat ures, z ero - shot with select ed feat ures , f ew - shot with all fea tures, z ero - shot with selected features and probability - lik e outputs , digital twin with all features , and di gital twin with r andom forest results as priors) for predicting participant ra tings in the Content, Copi ng, and Quittin g domains. Each bar corresponds to a s pecific model – configur ation combination. Dashed horizont al lines denote baseline per formance fr om lo gistic re gression (red) and r andom fore st ( gr ay ). Figure 3. Distr ibution of predic ted scores acr os s models . S cor e frequency dist ributions in the content, copin g and quitting domai n s across mod e ls and configur ations . Histograms show the distributio n of true participan t scores (top ro w) and predicte d scores from z ero - sh ot/fe w - s hot prom ptin g, digital twin/hybrid approaches , and baseline machine - learning models (random fore s t and logisti c regr ession). Columns correspond to lan guag e models. Figure 4 . Mean human r ating of top - K messages selected by LLMs (D igital T win prompti ng), human or acle, and r andom selection across three evalua tion domain s. Shaded gr ay region indica tes 95% CI for r andom selection . LLM - se lected mes sages cons istently outp erform r ando m selection a nd approach human or acle performance , particularly for larger K. Supp lementary Materi als fo r Personali zed Predictio n of Perceived Messa ge Effecti veness Using Large Language Models Appendix Appendix A1 : Prom pt templat es for L LMs . In this section, we provide the LLM prompt templates for the dierent configura tions described in S ections 2 .2.2 and 2.2.3. Throughout the document: - {{input_mes sage}}, {{response_id}}, etc . are placeholders filled by the evaluation pipeline . - {{metadata _block }} includes all participant feature s, and {{selected_metadata_block}} only includes a ge , gender identity , r ace/ ethnicity , motivation to quit, and perceived social support. - {{few_shot_e xamples_all}} and {{few_shot_e xa mples_select}} summarize the pre - sampled example s (u p to five examples) . - {{prob_meta data_bloc k}} mi rrors the sel ected - fe atu res l ist {{selected_metada ta_block}} but retains the short labe ls used in the probability prompt. A1.1. Zero - s hot wit h all features (Ze ro - s hot (al l) ) Description. This template include d all individ ual ch aracteris tics (s ociodemograp hic variables , smoki ng history, and psych ologic al fle xibility ite ms, totalin g 23 featu res) and queried the LLMs to generate categorical p redictions for con tent, design, c oping, and quitti ng. You are an ex pert in smoki ng - cessati on comm unicatio n and interv ention. Person a Setup - Descri be the p rovided image i n one s enten ce to gr ound yo urself v isuall y. - Then s tep into the sh oes of t he part icipa nt descr ibed be low and judge a new m essage from the ir exac t perspe ctive. Rating Dimens ions | Dime nsion | What it capt ures | Allowed ratings | | cont ent | W ords + meanin g quali ty | Ver y poor / Poor / Accept able / Goo d / Ver y good | | desi gn | Vi sual presenta tion | Very poo r / Poo r / Acce ptable / Goo d / V ery g ood | | copi ng | He lpful ness for in - the - mome nt ur ges | No t at al l helpfu l / Som ewhat helpful / Mo derately helpfu l / Very helpfu l / Extr emely h elpfu l | | quit ting | Helpf ulness f or long - term quit ting | Not at all he lpful / So mewhat helpful / Mode rately hel pful / Very hel pful / Extre mely helpf ul | Decisi on Rule s - Stay cons istent wit h the partic ipant's mo tivation , nicotine dependenc e, envir onment, and expresse d preferen ces. - Favor ext reme ratin gs when the messa ge strongl y fits or clash es with th eir hist ory; do not def ault to the middle . - Keep e xplanati ons to two sent ences p er di mension, pointi ng to th e most releva nt part icipa nt facto rs. Inputs Messag e to rate: "{{i nput_me ssage}}" Partic ipant m etada ta (full set): {{meta data_bl ock}} Requir ed JSON Outp ut { "response _id": " {{respon se_id}} ", "input_me ssage": "{{esca ped_inp ut_me ssage}}" , "image_de scripti on": "One - sentence descri ption of any pr ovided i mage.", "predicte d_conte nt": "Ve ry poor /Poor /Accepta ble/Goo d/Very g ood", "predicte d_desig n": "Ver y poor/ Poor/ Acceptab le/Good /Very go od", "predicte d_copin g": "Not at all help ful/Some what he lpful/Mo deratel y hel pful/V ery hel pful/ Extremel y helpf ul", "predicte d_quitt ing": "N ot at a ll he lpful/So mewhat helpful/ Moderat ely h elpful /Very h elpfu l/Extrem ely hel pful", "explanat ion": " <=2 sent ences p er di mension describ ing why this pa rtici pant w ould re spond that wa y." } A1.2. Zero - shot with select ed fe ature s (Zero - shot (se lect)) Description. We restri cted the metada ta to f ive hi gh - coverage variable s assoc iated with smoking patterns and c ess ation readiness: Age, gende r identity, race/ethnici ty, self - reported motivation t o quit, and perce ived social support. Thes e variables were selected by cor relatio n magn itude and used to test whe ther a c ompac t yet inf ormative s et of characteristic s could match the perfo rmance of the full template. Template d elta. Reuse the Zero - sh ot (all) ins truc tions ve rbatim exce pt replace the metadata block with: Partic ipant m etada ta (sele cted fe atures o nly): {{sele cted_me tadat a_block} } A1.3. Few - sh ot with all featur es (F ew - shot ( all)) Description. Extends Zero - shot (all ) by prepe nding two exemplars wit h extreme ra tings pe r domain (“V ery good”/ “Extre mely helpfu l” and “ Very poor”/ “Not at all helpfu l”) sampled from the training set. Each e xample includes participant characteristics and ratings so the model can contrast message c ontent with profile s while seeing the full rating spec trum before answering. Few - Sh ot Exam ple Prea mble Here a re part icipa nt - specifi c demons tration s sho wing how demogr aphics i nf luence rating s. Tr eat them as gro und - truth lab els drawn fr om the traini ng split . {{few_ shot_ex ample s_all}} Now, b ased on the examples above, evaluat e the f ollowing messag e for the given pa rticipan t and output the JSON speci fied in Zero - sh ot (all). A1.4. Fe w - shot with select ed fea tures ( Few - shot (select)) Description. Mirrors Fe w - sh ot (all) but truncat es both the e xemplar p articip ant featu res and the target que ry to the five selec ted characteristics. T his variant tests whether reference example s continue to improve pe rformance when the p rompt is aggress ively compressed . Few - Sh ot Exam ple Prea mble (S elected Feature s) The fo llowing demo nstratio ns show the ful l ratin g spectr um whil e onl y exp osing the fiv e sel ected pa rticipa nt featu res. {{few_ shot_ex ample s_select }} Now, b ased on the examples above, evaluat e the f ollowing messag e for the given pa rticipan t using the Zer o - shot (se lect) instru ctions a nd JSON cont ract. A1.5. Cont inuous zero - s hot wit h sele cted feat ures (Z ero - shot (w/ prob)) Description. Uses the same configuration as the c ontinuous zero - shot with a natu ral - language profile but presents participant information in a concise bullet list rather th an prose. Ratings are c ontinu ous (1.0 – 5.0) and ac companied by confiden ce scores; this variant isolates the effect of presentation format from info rmation con tent. You are an ex pert in smoki ng cessati on communi cation. Predict how th is pa rticip ant would ra te the qualit y of a smoking - ce ssation support message b y prov iding n umeri cal scor es betw een 1.0 and 5.0 for eac h dimen sion. Instru ctions 1. Descr ibe any provi ded image in one sentence . 2. Rat e conte nt, d esign, c oping, and quit ting on continu ous 1.0 – 5.0 scale s (dec imals a llowe d) using the ma ppings: - 1.0 = Very poor / Not at a ll help ful, 5.0 = Ve ry good / Extre mely he lpful. 3. Provi de a confiden ce score (1. 0 – 5.0) for each ra ting and kee p the ex pl anatio n to <= 2 sen tences t otal. Input Me ssage "{{inp ut_mess age}} " Partic ipant meta data (sele cted bulle t list): {{prob _metada ta_bl ock}} Return JSON { "response _id": " {{respon se_id}} ", "input_me ssage": "{{esca ped_inp ut_me ssage}}" , "image_de scripti on": "One - sentence descri ption of any pr ovided i mage.", "predicte d_conte nt": , "predicte d_desig n": , "predicte d_copin g": , "predicte d_quitt ing": , "confiden ce_cont ent": , "confiden ce_desi gn": , "confiden ce_copi ng": , "confiden ce_quit ting": < float 1 .0 – 5.0>, "explanat ion": " <=2 sent ences c overi ng all f our dim ensions. " } A1.6 LLM - based Digital T wins This framework extends the few - shot pa radigm by contextualiz ing example s at the individual level, incorporating each participant’ s persona and enti re historic al responses to build participant p rofiles. Using these profiles , we evaluated two co nfigurations. Basic pro file (genera te_digita l_twin_pro mpt) Description. Combines the participant’s full metadata wi th up to se ven prior mess ages and their ratings. The model is instructed to simulate the participant, anchor predictions in message simil arity, and stay faithfu l to historic al responses. Role & Task You ar e an AI assi stant si mulatin g this p articip ant. Pre dict ho w the y wil l rate a new messa ge by co mparing it to t heir me tadata a nd prev iousl y rat ed messa ges. Ground Rules - Stay f aithful to past ratings and fr ee - text feedbac k when a vailabl e. - Anchor your re asoning in simi laritie s bet ween the new me ssage an d the s tored hi story. - Keep copi ng/quit ting judgm ents sensi tive to messa ge type when ever that inform ation i s pre sent. Inputs Messag e to rate: "{{i nput_me ssage}}" Partic ipant m etada ta and h istory: {{meta data_bl ock}} {{prof ile_mes sages _block}} Output JSON C ontra ct { "response _id": " {{respon se_id}} ", "predicte d_conte nt": "Ve ry poor /Poor /Accepta ble/Goo d/Very g ood", "predicte d_desig n": "Ver y poor/ Poor/ Acceptab le/Good /Very go od", "predicte d_copin g": "Not at all help ful/Some what he lpful/Mo deratel y hel pful/V ery hel pful/ Extremel y helpf ul", "predicte d_quitt ing": "N ot at a ll he lpful/So mewhat helpful/ Moderat ely h elpful /Very h elpfu l/Extrem ely hel pful", "explanat ion": " <=2 sent ences p er di mension grounde d in the partic ipant 's pro file an d pas t reacti ons." } Enhan ced profile w ith RF prio rs (gener ate_h ybrid_rf_dig ital_twin_ prom pt) Description. Adds Random Fo rest predic tions (trained o n the full feature set) as auxi liary priors. The prompt inse rts a sec tion summarizing the RF outputs and i nstructs the LLM to treat them as one inpu t among many, ne ver as ground truth. ... (B asic pr ofile templat e) --- Additi onal Co ntext : Prior Model P redictio ns A Rand om Fore st mo del trai ned on particip ant cha racteris tics pr edict s: - Conten t: {{rf_co ntent_la bel}} - Design : {{rf_d esign_l abel}} - Coping : {{rf_c oping_l abel}} - Quitti ng: {{rf _quitti ng_label }} These priors are n ot perfe ctly ac curate. Use the m alongs ide the part icipa nt’s h istory, the new mess age con tent, an d your own judg ment. ### OU TPUT FO RMAT (reuse J SON con tract) Appendix A 2: Uncerta inty quantifica t ion for LLM performance metrics . In this section, we present results from bootstr ap ana lysis wi th n=1,000 resamples to quantify un certainty in our per formanc e estimates . For each bootstrap iter ation, we res ampled pairs of ground tr uth and predicted r atings with replacement and recomputed three metrics: (1) accuracy on the 5 - poin t ordinal scale, (2) directional accur ac y on a collapsed 3 - point scale (low: 1 – 2, neutr al: 3, high: 4 – 5), and (3) Cohen's kappa to as sess agreement beyond cha nce. Confidence inter vals are computed using the 2. 5th an d 97.5th percentiles of th e bootstrap distributions (pe rcentile metho d). We listed the performance for digita l twin (with CB T / AC T instruc tions); few shot (all feature s ); and zero - sho t (all features) in T a bles S2 - 4. The bootstr ap confidence inter vals largely confirm the trends we summarized in th e main text: Acros s prompting str ategies, the CIs reveal a clear hier archy . Digital T win prompting achieved statistically signi ficant agreement ( Cis for cohen’ s kappa excluding z e ro) in 15/15 model - domain combi nations, compared to only 2/15 for Few - shot a nd 1/1 5 for Ze ro - shot. Acros s models wi thin a prompting str ategy , Grok -4- Fast a chieved the highest 5 - cl ass accur ac y (43.7% – 48.1% acros s doma ins) and most consistent direc tional accu r acy (65.9% – 7 1.1%), wi th CIs that cons istently rank among the highest. GPT - 4o - mini s how ed the l owe st accur acy with CIs that occasionally overlap with but gener a lly f all below other models. Finally , acros s doma ins, the CIs reveal that Co ping is consi stently the most diicult domain acros s mode ls — showing the lowe st accuracy (32.8% – 43.7%) and directional accur acy with CI gener ally r an k ed be low other domains. Mo del Domain Accur acy [95% CI] Dir. Acc. [95% CI] Kappa [95% CI] GPT - 4o - min i Content 0.416 [0.363, 0.469] 0.730 [0.680, 0.780] 0.114 [0.048, 0.180] GPT - 4o - min i Cop ing 0.328 [0.279, 0.378] 0.505 [0.449, 0.554] 0.109 [0.059, 0.160] GPT - 4o - min i Quitting 0.325 [0.272, 0.378] 0.598 [0.545, 0.647] 0.095 [0.044, 0.150] GPT -5 Content 0.453 [0.404, 0.509] 0.674 [0.624, 0.724] 0.208 [0.134, 0.285] GPT -5 Cop ing 0.378 [0.325, 0.430] 0.613 [0.554, 0.669] 0.165 [0.099, 0.236] GPT -5 Quitting 0.406 [0.356, 0.461] 0.647 [0.598, 0.700] 0.210 [0.145, 0.279] Deep Seek - R1 Content 0.438 [0.385, 0.491] 0.661 [0.612, 0.711] 0.201 [0.129, 0.274] Deep Seek - R1 Cop ing 0.387 [0.331, 0.443] 0.598 [0.542, 0.647] 0.180 [0.105, 0.250] Deep Seek - R1 Quitting 0.402 [0.359, 0.455] 0.644 [0.594, 0.693] 0.205 [0.147, 0.269] Grok -4- Fast Content 0.481 [0.432, 0.540] 0.711 [0.665, 0.758] 0.230 [0.163, 0.308] Grok -4- Fast Cop ing 0.437 [0.384, 0.492] 0.659 [0.607, 0.715] 0.226 [0.156, 0.297] Grok -4- Fast Quitting 0.437 [0.384, 0.486] 0.672 [0.622, 0.724] 0.232 [0.161, 0.292] Gemin i - 2.5 - Pro Content 0.422 [0.366, 0.475] 0.674 [0.621, 0.724] 0.163 [0.085, 0.233] Gemin i - 2.5 - Pro Cop ing 0.433 [0.378, 0.489] 0.635 [0.579, 0.687] 0.233 [0.158, 0.302] Gemin i - 2.5 - Pro Quitting 0.449 [0.393, 0.502] 0.659 [0.607, 0.709] 0.256 [0.183, 0.327] T ab le S1. Bootst r ap con fidence in ter vals for Digita l T win method. P erformance metrics inclu de exact 5 - class a ccuracy , directi onal 3 - class acc uracy and Cohen's kappa with 95% CIs calculated us ing the pe rcentile method with n=1,000 mess age - level bootstr ap re samples. Mo del Domain Accur acy [95% CI] Dir. Acc. [95% CI] Kappa [95% CI] GPT - 4o - min i Content 0.350 [0.299, 0.409] 0.675 [0.624, 0.726] 0.006 [ - 0.040, 0.052] GPT - 4o - min i Cop ing 0.255 [0.204, 0.307] 0.394 [0.336, 0.453] - 0.009 [ - 0.068, 0.049] GPT - 4o - min i Quitting 0.292 [0.237, 0.347] 0.515 [0.456, 0.569] 0.057 [0.002, 0.115] GPT -5 Content 0.354 [0.296, 0.409] 0.624 [0.569, 0.682] 0.052 [ - 0.018, 0.115] GPT -5 Cop ing 0.197 [0.153, 0.252] 0.314 [0.263, 0.369] - 0.049 [ - 0.105, 0.014] GPT -5 Quitting 0.223 [0.175, 0.277] 0.332 [0.270, 0.391] 0.025 [ - 0.033, 0.082] Deep Seek - R1 Content 0.369 [0.314, 0.423] 0.639 [0.580, 0.697] 0.076 [0.015, 0.145] Deep Seek - R1 Cop ing 0.263 [0.215, 0.314] 0.423 [0.369, 0.489] 0.020 [ - 0.040, 0.083] Deep Seek - R1 Quitting 0.263 [0.212, 0.318] 0.467 [0.409, 0.526] 0.037 [ - 0.023, 0.101] Grok -4- Fast Content 0.314 [0.259, 0.365] 0.653 [0.595, 0.712] - 0.019 [ - 0.091, 0.052] Grok -4- Fast Cop ing 0.292 [0.234, 0.347] 0.489 [0.427, 0.548] 0.013 [ - 0.052, 0.078] Grok -4- Fast Quitting 0.318 [0.266, 0.369] 0.580 [0.522, 0.639] 0.068 [ - 0.001, 0.135] Gemin i - 2.5 - Pro Content 0.325 [0.270, 0.383] 0.639 [0.577, 0.701] 0.018 [ - 0.051, 0.094] Gemin i - 2.5 - Pro Cop ing 0.288 [0.237, 0.336] 0.496 [0.438, 0.551] 0.033 [ - 0.032, 0.093] Gemin i - 2.5 - Pro Quitting 0.288 [0.234, 0.343] 0.533 [0.474, 0.591] 0.029 [ - 0.042, 0.101] T ab le S2. Bootst r ap con fidence in ter vals for Few Shot (All) meth od. P er formance metrics inclu de exact 5 - class a ccuracy , directi onal 3 - class acc uracy and Cohen's kappa with 95% CIs calculated us ing the pe rcentile method with n=1,000 mess age - level bootstr ap resamples. Mo del Domain Accur acy [95% CI] Dir. Acc. [95% CI] Kappa [95% CI] GPT - 4o - min i Content 0.365 [0.310, 0.420] 0.690 [0.631, 0.741] 0.004 [ - 0.017, 0.029] GPT - 4o - min i Cop ing 0.285 [0.234, 0.336] 0.409 [0.354, 0.464] 0.017 [ - 0.041, 0.075] GPT - 4o - min i Quitting 0.252 [0.201, 0.307] 0.493 [0.431, 0.555] - 0.021 [ - 0.069, 0.031] GPT -5 Content 0.376 [0.321, 0.431] 0.664 [0.609, 0.719] 0.041 [ - 0.005, 0.095] GPT -5 Cop ing 0.274 [0.223, 0.325] 0.394 [0.332, 0.456] 0.018 [ - 0.042, 0.073] GPT -5 Quitting 0.197 [0.153, 0.245] 0.274 [0.226, 0.332] 0.031 [ - 0.007, 0.071] Deep Seek - R1 Content 0.336 [0.281, 0.391] 0.628 [0.569, 0.679] 0.006 [ - 0.052, 0.062] Deep Seek - R1 Cop ing 0.245 [0.193, 0.296] 0.343 [0.285, 0.398] 0.017 [ - 0.043, 0.077] Deep Seek - R1 Quitting 0.161 [0.120, 0.204] 0.255 [0.204, 0.310] 0.025 [ - 0.014, 0.065] Grok -4- Fast Content 0.369 [0.314, 0.427] 0.679 [0.624, 0.734] 0.030 [ - 0.043, 0.107] Grok -4- Fast Cop ing 0.321 [0.266, 0.376] 0.515 [0.456, 0.573] 0.033 [ - 0.022, 0.092] Grok -4- Fast Quitting 0.281 [0.230, 0.332] 0.460 [0.405, 0.518] 0.053 [ - 0.010, 0.108] Gemin i - 2.5 - Pro Content 0.307 [0.259, 0.361] 0.661 [0.609, 0.715] - 0.037 [ - 0.107, 0.040] Gemin i - 2.5 - Pro Cop ing 0.343 [0.288, 0.401] 0.566 [0.511, 0.624] 0.066 [0.008, 0.126] Gemin i - 2.5 - Pro Quitting 0.314 [0.255, 0.365] 0.595 [0.540, 0.650] 0.051 [ - 0.014, 0.108] T ab le S3. Bootst r ap con fidence in ter vals for Zero Shot (All) met hod. P er formance metrics inclu de exact 5 - class a ccuracy , directi onal 3 - class acc uracy and Cohen's kappa with 95% CIs calculated us ing the pe rcentile method with n=1,000 mess age - level bootstr ap resamples. Appendix A3: A ccuracy o f di gita l - twin configurations by numb er of training ra t i n gs . Supplementar y Figur e 1 illustr ates the performance of the digital - twin prompt v a riants as a function of the number of historical r atings available for each participant (i.e ., r atings of other messages used to condition the digital twin). Acros s mode ls, acc ur acies remain remarkably s table e ven when using as few as o ne to seven prior mes sage ra tings. Accur acy exhibits substant ially less variability than F1 or r ank - based metrics such as Cohen’ s κ, which are more sensitive to clas s imbalanc e. These pr e liminary findi ngs suggest that a light weight onboar din g pr o cedure , such as collecting onl y a sma ll seed se t of message - r ating e xamples , may be suicie nt for initializing reliable personaliz e d digital - twin predictions before delivering tailor ed inter vention content. Figure 5. Model predi ction accurac y for digit al twin p rompt configurations ac ros s tr aining s et siz es. D ierent co lor indica tes di erent mo dels.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment