Spatiotemporal double machine learning to estimate the impact of Cambodian land concessions on deforestation
Environmental policy evaluation frequently requires thoughtful consideration of space and time in causal inference. We use novel statistical methods to analyze the causal effect of land concessions on deforestation rates in Cambodia. Standard approac…
Authors: Anika Arifin, Duncan DeProfio, Layla Lammers
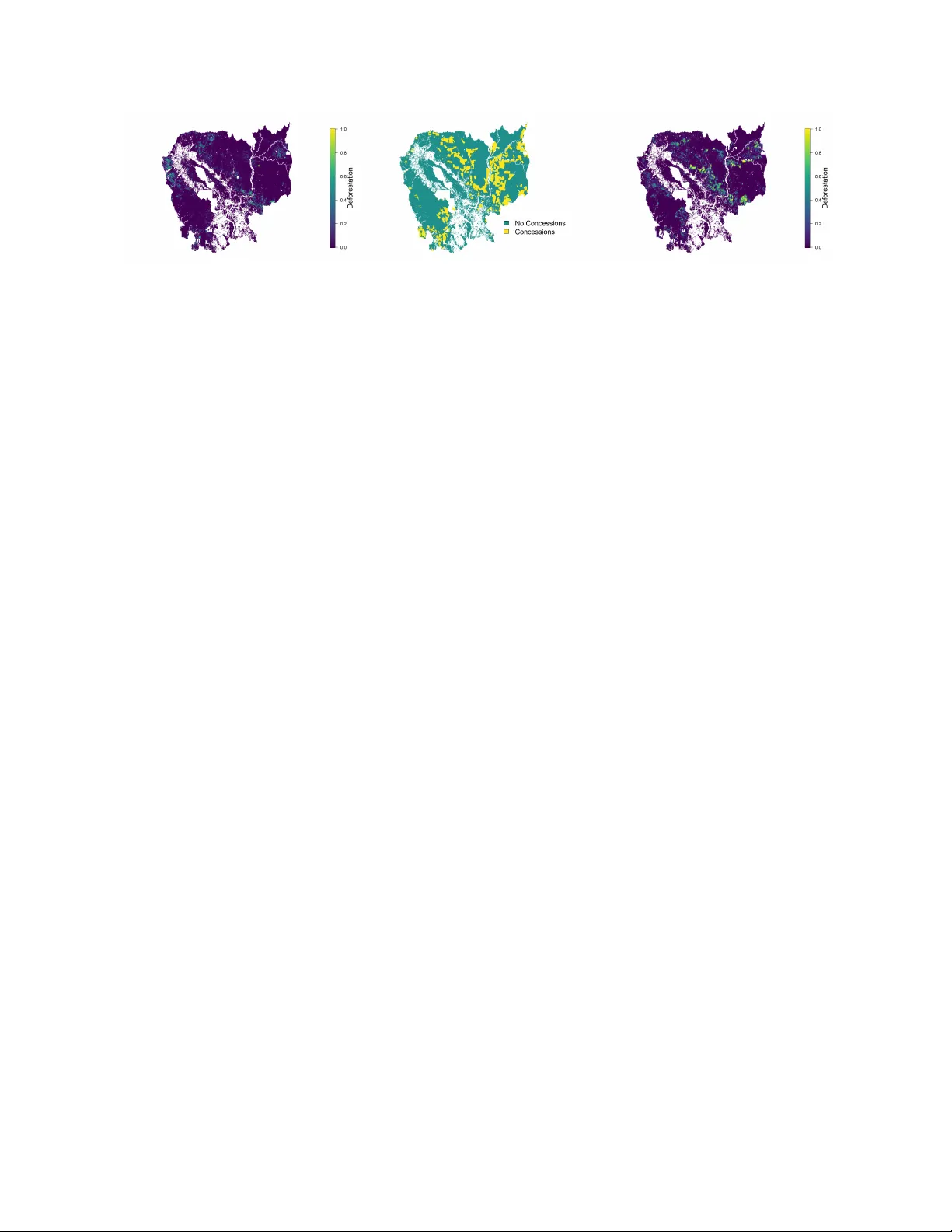
Spatiotemporal double machine learning to estimate the impact of Cambodian land concessions on deforestation Anika Arifin 1 , Duncan DeProfio 2 , Layla Lammers 3 , Benjamin Shapiro 4 , Brian J Reich 5 , Henry Uddyback 5 and Joshua M Gray 5 February 24, 2026 Abstract En vironmental policy e v aluation frequently requires thoughtful consideration of space and time in causal inference. W e use nov el statistical methods to analyze the causal ef fect of land concessions on deforestation rates in Cambodia. Standard approaches, such as difference-in- dif ferences regression, ef fecti vely address spatiotemporally-correlated treatments under some conditions, but the y are limited in their ability to account for unobserved confounders affect- ing both treatment and outcome. Double Spatial Regression (DSR) is an approach that uses double machine learning to address these scenarios. DSR resolv es the confounding v ariables for both treatment and outcome, comparing the residuals to estimate treatment effecti veness. W e improv e upon DSR by considering time in our analysis of policy interventions with spatial ef fects. W e conduct a large-scale simulation study using Bayesian Additiv e Regression T rees (B AR T) with spatial embeddings and find that, under certain conditions, our DSR model out- performs standard approaches for addressing unobserved spatial confounding. W e then apply our method to e valuate the polic y impacts of land concessions on deforestation in Cambodia. K ey words: Causal inference; Geostatistics; Policy e valuation; Spatial confounding. 1 Intr oduction Large-scale e v aluation of en vironmental polic y frequently relies on observ ational data with spatial and temporal dependence. As with all observational studies, drawing casual concludions requires carefully considering confounding variables. Causal inference for spatial applications is chal- lenging because spatial dependence violates the common assumptions of causal inference (Ru- bin, 1974). Ho wev er , nov el methodology has recently been dev eloped (for recent re views, see K eller and Szpiro, 2020; Reich et al., 2021; Bolin and W allin, 2024; Dupont et al., 2024), such 1 Smith College 2 W illiams College 3 Rhodes College 4 Univ ersity of Florida 5 North Carolina State Univ ersity 1 as case-control matching, neighborhood adjustments by spatial smoothing, and propensity score weighting. Most related to our approach is W iecha et al. (2025), who b uild on the double/debiased machine learning (DML) approach of Chernozhuk ov et al. (2018) to include a spatial ef fect on the confounding variable of interest. This approach first removes spatial trends from the outcome and treatment v ariables and then performs re gression on the residuals to estimate the causal ef fect. W e extend this approach from the spatial to spatiotemporal setting. Many pre vious adv ances in the field of spatiotemporal causal inference ha ve centered around a linear dif ference-in-differences (DID) model to account for treatment effects across time. Howe ver , a standard DID model does not ef fectiv ely predict a treatment ef fect when there are correlations in treatment and outcome across nearby locations. Ne wer methods, howe ver , allo w the DID model to account for correlation in treatment across adjacent spaces (Delgado and Florax, 2015). This permits the use of DID despite violation of the stable unit treatment v alue assumption traditionally required in DID, a phenomenon known as “interference. ” Even so, spatial causal inference prob- lems often must capture larger -range spatial correlation beyond correlation of adjacent locations. Bardaka et al. (2019) achie ve progress to ward this objecti ve in their spatiotemporal policy ev alu- ation of expanded light rail in Den ver , Colorado. They use Delgado and Florax (2015)’ s spatial DID model but focus especially on the presence of “spillo ver ef fects, ” when an intervention in one specific region may hav e similar effects on nearby areas that it does not directly target. Ev en af- ter these model innov ations, sev eral persistent shortcomings remained in the DID model. Further adv ances hav e accounted for effects of spillovers that are not based only on proximity but rely in- stead upon some other, non-distance factor (Butts, 2021). (Butts, 2021) also dev elops a procedure to adjust for spatial effects of the treatments when the interventions do not occur simultaneously . All of the above methods in volv e a “parallel trends” assumption, assuming that treated areas, if not exposed to intervention, would experience the same outcome variable change as untreated ar- eas. (Abadie, 2005) dev elop a flexible DID approach can predict treatment effects accurately ev en when the parallel trends assumption does not hold. This method also does not require observ ations for the same indi viduals both before and after treatment. This permits better control of cov ariates’ ef fects when contrasted with standard DID approaches. Finally , DID has been extended and com- 2 bined with nonlinear models, seeking to account for confounding variables that change with time (Bhuyan et al., 2021). This methodology utilizes in verse propensity weighted DID estimators for av erage treatment ef fects to account for unknown interactions between time and co variates. Despite advances in DID methods, v arious biases and shortcomings necessitate the develop- ment of other types of analysis to conduct ef fectiv e spatiotemporal causal inference. One example is the use of a Bayesian Multi-Stage Spatiotemporal Evolution Hierarchy Model (BMSSTEHM) to estimate population-weighted ground-lev el O 3 concentrations in China (Li et al., 2023). This model combines a Bayesian Spatiotemporal Hierarchal Model (BSTHM) with piecewise regres- sion to model different linear trends before and after the trends shift direction. DML exists as an- other popular causal inference method. P ast simulations have shown that hyperparameter choices can effect the efficacy of DML predictions; for example, crossfitting on the full sample or on multiple folds performs better in small samples than using a split sample approach (Bach et al., 2024). As another alternativ e to DID, doubly-robust estimators, such as targeted maximum like- lihood estimation (TMLE), frequently prove effecti ve in causal inference problems. K ¨ uhne et al. (2022) emphasize these methods and the use of a correct g-formula model to prev ent bias. This helps to confront challenges of using causal inference for medical research and health decisions. Also studying fields of health, V andenbrouck e et al. (2016) illustrate potential pitfalls of the Re- stricted Potential Outcome Approach (RPO A) to causal inference. They suggest that RPO A ranks e vidence in a way that neglects important experimental context, resulting in errors in the field of epidemiology . Finally , dimension reduction can provide additional insight into causal inference problems. In climate science, dimension reduction promotes accurate estimation by con verting a highly dimensional climate field into a smaller set of regionally constrained patterns for analysis (Falasca et al., 2024). In the presence of large amounts of unobserved spatial confounding, the DID approach, ev en with the adjustments described above, often outputs a biased or otherwise inaccurate estimate of the treatment ef fect. Out of all alternativ e methods, we select DML for our analysis to improve upon the av ailable DID inference methodologies (Chernozhukov et al., 2018). Past applications of DML to spatial statistics provide a starting point for our methodology in 3 this spatiotemporal causal inference problem. Our paper builds on W iecha et al. (2025) to describe the ef fects of a policy intervention—public land conceded to pri v ate businesses—on deforestation in Cambodia. Double Spatial Regression (DSR) is a DML approach that can account for spatially correlated data, but its use has been restricted to analysis at one specific point in time (W iecha et al., 2025). W e apply the methods of DSR to analyze the effect of policy interv entions ov er time accounting for spatial confounding variables in the pre-treatment response, treatment allocation, and post-treatment response. W e further expand on Wiecha et al. (2025), who use Gaussian pro- cess regression with linear cov ariate ef fects, by using Bayesian Additiv e Re gression T rees (B AR T) as our machine learning method (Chipman et al., 2010). This allows for non-linear cov ariate ef- fects and f ast computation for lar ge spatial datasets. T o allo w for fidelity to complex spatial trends, we include a spatial embedding layer similar to Chen et al. (2024), who add a spatial embed- ding to a neural network regression. Furthermore, we in vestigate the consequences of allocating the policy to regions (i.e., polygons) rather than individual locations. In a simulation study , we compare our spatiotemporal DSR approach to DID, demonstrating increased precision and unbi- asedness in accounting for outcomes of policy interventions. W e conduct causal inference on the concessions/deforestation relationship, and we conclude with a discussion of future problems and innov ations in the field of spatial statistics. 2 Cambodian def orestation background and data Southeast Asian countries like Cambodia have experienced an expansion of rubber farming since the year 2000, coinciding with a rise in prices of the v aluable agricultural commodity . The Cam- bodian government encouraged the development of large plantations during this rubber boom through granting lar ge land concessions to pri v ate b usinesses, man y of which replaced natural forests (Hurni and Fox, 2018). Nev ertheless, deforestation may also occur due to the prev alence of illegal logging in Cambodia and the challenges of enforcing forest protection legislation. For example, in 1997, the illegal logging harv est w as o ver ten times the size of the legal logging output (BRA CK, 2003). This leav es open the question of whether land concessions increase deforestation or merely shift it from illegal loggers to legal companies. Additionally , different crop types may 4 inform amounts of deforestation that are present. For example, rubber plantations often require clear-cutting nativ e forests before planting, whereas timber production frequently reduces defor- estation by managing and selectively cutting the existing forest. Other crops grown in Cambodia include black pepper , cashe ws, and sugar , which can affect rates of deforestation and the regions in which it occurs (Hurni and Fox, 2018; Um, 2014). A number of priv ate companies hav e emerged to implement and account for these REDD+ projects, b ut recent analyses suggest that the majority hav e dubious ef fectiv eness (Guizar-Couti ˜ no et al., 2022; W est et al., 2023). Dif ferent strate gies exist to combat the loss of biodiv ersity and ecosystem destruction resulting from deforestation in Cambodia. Protected areas (P As) maintain biodiv ersity by sealing off an area from human intervention. Black and Anthony (2022) present a study measuring the effecti veness of P As in preventing deforestation in Cambodia. They use nearest-neighbor propensity scores for their P A assessment. Eight cov ariates are used to compare treated and untreated samples of data. Black and Anthony (2022) find that Cambodia’ s P As had a significant, negati ve association with deforestation in all studied time periods. Forested land in P As can be up to 12 . 5% less likely to face deforestation than matched unprotected forests, though this ef fect may decrease ov er time due to increased land concession pressure for agricultural demands. Another method for deforesta- tion reductions is the de velopment of Reduce Emissions from Deforestation and forest Degrada- tion (REDD+) projects. Pauly et al. (2022) study the deforestation differences between REDD+ projects and nearby P As and find that REDD+ projects were 158% more effecti ve at prev enting forest loss than nearby P As. 2.1 Study Area W e defined a common 1 km grid cov ering Cambodia (476 x 580; Figure 1) and took grid squares as study units. Only grid squares within the Cambodian boundary and having more than 5% for- est cover and less than 5% urban cover in the year 2000 were retained for analysis (n=145,832). Existing datasets of deforestation, concession/protected status, and cov ariates (e.g., elev ation, pop- ulation, etc.) were resampled to the common 1 km grid, with an aggregation method appropriate to their use case (details below). Except where noted, data were obtained in their nativ e spatial 5 Figure 1: Defor estation and concessions : Deforestation by pixel in the pre-intervention (left) and post-intervention (right) period. Purple represents little deforestation, while brighter greens sho w significant deforestation. A yellow result represents 100 percent deforestation in the raster . A concessions graph is in the center , where yellow indicates the conceded land. resolution from Google Earth Engine (Gorelick et al., 2017) with GD AL (Contrib utors, 2020) sub- sequently used for resampling. 2.2 Def orestation, Concession and Ancillary Data Deforestation data were obtained from the Global Forest Change product (GFC; Hansen et al., 2013), which pro vides the year of deforestation at 30 m resolution o ver the entire globe for the pe- riod 2000-2024. Annual deforestation area totals were created by aggre gating the 30 m deforested pixels to the 1 km grid, in each year, via summation. W e also used the GFC’ s forest cov erage in 2000 data to establish a baseline of forest cov er in each study unit. The Cambodian League for the Promotion and Defense of Human Rights (LICADHO, 2024) provided the boundaries of forest concessions as well as their type and year of establishment among other (unused) characteristics. Protected area boundaries and types were sourced from the W orld Database of Protected Areas (UNEP-WCMC and IUCN, 2025). These vector datasets were first rasterized to a 100 m grid using a majority rule for protected/concessed status (binary), year of protected area/concession establishment, and the concession crop type. These datasets were then resampled to the 1 km study grid by av eraging the binary protected/concessed status creating a measure of the fraction of the 1 km grid cell that is protected/concessed. The years of establishment and crop type grids were aggregated to the 1 km study grid using the majority rule. The pre-intervention outcome variable for pixel i , Y 0 , is the total forest loss for a pixel during the 4 years prior to, but not including, the concession year . W e only assign values of Y 0 to rasters 6 with a concession date between 2005 and 2024. Likewise, the post-intervention outcome, Y 1 , is the total forest loss spanning the concession year and the three follo wing years. This v ariable only applies to concessions occurring between 2001 and 2020. Restricted ranges for Y 0 and Y 1 result from having av ailable deforestation data only during the years 2001–2023. Figure 1 shows a map of Cambodia with Y 0 (left) and Y 1 (right). The pre-treatment mean across pixels for with and without treatment are 0.037 and 0.024, respecti vely . The corresponding post-treatment means are 0.162 and 0.029. Therefore, a naiv e difference in dif ferences is (0.162 - 0.029) - (0.037 - 0.024) = 0.12, i.e., a 12 % deforestation of the pixel due to concessions. The prev alance of deforestation is often dependent on the en vironmental and human context of a particular place. An area that is far from significant population density , with difficult rugged terrain, and/or with challenging weather conditions may be under less deforestation pressure com- pared to more easily accessed areas. W e summarized this en vironmental context by creating popu- lation, ele vation, and climate summaries for each study unit. Population density was obtained from W orldPop and summed within the 1 km study units (W orldPop Research Programme, 2015). The Copernicus global 30 m DEM (Copernicus DEM, 2019) was used to compute the average elev a- tion within each study unit. ERA5-Land monthly data (Copernicus Climate Change Service, 2025) were used to compute the av erage monthly precipitation and air temperature within each study unit. Additionally , the Copernicus Global Land Cov er Layers (CGLS-LC100; European Union’ s Coper- nicus Land Monitoring Service, 2025) were used to sum the areas of urban and water within each grid square. 3 Double machine learning f or spatial differ ence-in-differences Let Y it be the observation at location s i for i ∈ { 1 , ..., n } at time t ∈ { 0 , 1 } (as described in Section 2, some observations are missing), and X it = (1 , X it 1 , ..., X itp ) be an associated vector of observed cov ariates (e.g., temperature, precipitation). It is assumed that an intervention is applied to a subset of the locations between the two observation times, with D i = 1 if site i was gi ven the intervention and D i = 0 otherwise. DML (Chernozhukov et al., 2018) is a two-stage estimator that first remov es trends in the outcome ( Y it ) and treatment ( D i ) variables that can be explained 7 by the co variates ( X it ) and then regresses the residual outcome onto the residual treatment to estimate the casual effect. In this section, we extend the spatial DML of Wiecha et al. (2025) to the spatiotemporal DID setting. The procedure is summarized in Algorithm 1. Algorithm 1: Spatiotemporal Double Machine Learning Data: Outcomes Y 0 and Y 1 , treatment D, spatial location s , cov ariate matrix X, with or without W endland Basis Expansion Result: γ estimate 1. First-stage regressions with cross-fitting Split the locations into K folds f or k = 1 , ..., K do Create training indices for K − 1 folds Create testing index for k th fold Fit Y 0 and Y 1 separately using bart from dbarts (Dorie, 2025) Predict ˆ Y 0 and ˆ Y 1 for the k th fold Fit D using pbart from BART (Chipman et al., 2010). Predict ˆ D for the k th fold end 2. Second-stage regression Compute the residuals R Y i 0 = Y i 0 − ˆ Y i 0 , R Y i 1 = Y i 1 − ˆ Y i 1 , and R D i 1 = D i − ˆ D i Use the residuals to estimate γ in second-stage regression R Y it = β + δ t + αR D i + ¯ α ¯ R D i + γ tR D i + ¯ γ t ¯ R D i + ε it 3.1 Stage 1: Spatial regr essions The first stage builds spatial regression models for the outcome and treatment v ariables. The outcome model for time t ∈ { 0 , 1 } is Y it = f t ( X it , s i ) + ϵ it (1) where f t is an unkno wn mean function, ϵ it indep ∼ Normal (0 , σ 2 t ) is error and the regressions are fit separately for each time point. The binary treatment variable is modeled as the spatial logistic regression model with pre-treatment co variates X i 0 , logit { Prob ( D i = 1) } = g ( X i 0 , s i ) . (2) 8 for unkno wn function g . The functions f 0 , f 1 and g can be estimated with an y machine learning method, including Gaussian process re gression, i.e. Kriging, or neural networks. In this paper , we use Bayesian Adapti ve Regression T rees (B AR T ; Chipman et al. (2010)) to provide arbitrarily flexible models for the unkno wn regression functions that can be fit with large datasets with continuous ( Y it ) and binary ( D i ) outcomes, as well as random effects (see Section 3.3). B AR T builds a model of data by dev eloping a set of binary decision trees based on its input variables. This machine learning method uses the end points of these trees to de velop a posterior distrib ution that models the data. Including the coordinates s i as features in the B AR T regression can capture complex spatial trends. Howe ver , for large and di verse regions such as Cambodia, this may require a lar ge number of deep trees. T o facilitate spatial modeling, we follow Chen et al. (2024) and use an embedding layer to supplement the coordinates with a spatial basis expansion. Follo wing Chen et al. (2024), we use define a rectangular grid of knots location u 1 , ..., u L cov ering the spatial domain of interest and use W endland basis functions (Nychka et al., 2015) Z il = (1 − d il ) 6 (36 d 2 il + 18 d il + 3) / 3 if d il ≤ 1 0 if d il > 1 (3) for d il = || s i − u l || /ϕ and bandwidth parameter ϕ set to 2.5 times the grid spacing. The basis functions Z i = ( Z i 1 , ..., Z iL ) T are then used as inputs to BAR T . That is, we fit the model with means f t ( X it , s i , Z i ) and g ( X i 0 , s i , Z i ) . If the functions f t and g are smooth in space, the first-stage regression can be fit to the entire training data (W iecha et al., 2025). Otherwise, cross-fitting is a way to ensure the first-stage re- gressions do not overfit and obscure the intervention effect. In cross-fitting, the n locations are randomly partitioned into K folds, and the predictions b Y i 0 , b Y i 1 and b D i are made from a model trained on the data from the K − 1 folds that e xclude site i . In the analyses belo w we take K = 10 and allocate sites (the same allocation for all three re gressions) into folds using a complete random sample. 9 3.2 Stage 2: Final estimate and standard error Denoting the cross-fitting residuals as R Y i 0 = Y i 0 − b Y i 0 , R Y i 1 = Y i 1 − b Y i 1 and R D i = D i − b D i , the second-stage regression is R Y it = β + δ t + αR D i + ¯ α ¯ R D i + γ tR D i + ¯ γ t ¯ R D i + ε it , (4) where ¯ R D i is the local mean of R D i ov er the neighboring pix els. In (4), the cov ariates X i are remov ed because their ef fects ha ve been remov ed in the first stage. The treatment effect of interest, γ , is obtained by least squares regression. Letting R be the vector length 2 n composed of the R Y it , Z be the corresponding 2 n × 6 design matrix and θ = ( β , δ, α , ¯ α, γ , ¯ γ ) T be the unkno wn coef ficients, the estimator is ˆ θ = ( Z T Z ) Z T R . As in Chernozhukov et al. (2018) and W iecha et al. (2025), the standard error is computed using the robust method of MacKinnon and White (1985), Cov ( ˆ θ ) = ( Z T Z ) − 1 Z T DZ ( Z T Z ) − 1 where D is the diagonal matrix with elements ( R Y it − ˆ β − ˆ δ t − ˆ αR D i − ˆ ¯ α ¯ R D i − ˆ γ tR D i − ˆ ¯ γ t ¯ R D i ) 2 . This is computed in the lm robust function in R with the “HC0” standard error option (Blair et al., 2025). A heuristic mathematical argument that this two-stage algorithm can remove spatially- smooth missing confounder variables is gi ven in Appendix A. Code to implement the method is av ailable at https://github.com/ddeprof/Spatiotemporal_DML . 3.3 Extension to clustered treatments In concessions within Cambodia, the government grants contiguous polygons to pri vate entities. Hence, treatments can be said to be “clustered” into discrete groups. W e can group treated pixels into polygons where they undergo the same treatment status as a unit. W e can model each polygon as a block with random effects (RE) on the outcome variable Y . This reflects the reality that each 10 piece of land may ha ve different qualities and circumstances that af fect the deforestation outcome. For example, some companies may eagerly deforest all land, clear -cutting the entire concession with great precision, while others may hav e incentives to preserv e some or all of the forested land on their ne w property . This modeling of clustered treatments is further explored in a detailed simulation study (see Section 4) to test the ef ficacy of ST -DML methodology on more realistic data scenarios. 4 Simulation study W e conduct two simulation studies to e valuate the performance of the proposed DML methods. In Section 4.1, treatment is assigned at the pixel lev el. T o mimic the Cambodia data, in Section 4.2 treatment is assigned to blocks of pixels. In both cases, we generate data on an m × m grid of spatial locations spanning [0 , 1] 2 . The data-generating model includes fiv e spatial co variates. For cov ariate j , ( X 1 j , ..., X nj ) is generated as a Gaussian process with mean zero, v ariance one, and Mat ´ ern correlation with range ρ and smoothness ν using the package spectralGP (Paciorek, 2007). The cov ariates are independent o ver j ∈ { 1 , ..., 5 } and shared by the treatment and outcome models. In the analysis of the simulated data, it is assumed that the first p = 3 cov ariates are observed and included in analysis as X i = (1 , X i 1 , ..., X ip ) , but the remaining cov ariates are not observed. Since these missing cov ariates are associated with both the treatment and response, this omission induces spatial confounding. 4.1 Simulation design with pixel-level treatment allocation Gi ven the cov ariates X i , logit { Prob ( D i = 1) } = h 1 ( X i ) and Y it = h 2 ( t, X i , D i ) + ε it for t ∈ { 0 , 1 } , with ε it iid ∼ Normal (0 , σ 2 ) . The regression functions are taken to be (McCulloch and Sparapani, 2025) h 1 ( X i ) = sin( π X i 1 X i 2 ) + 20( X i 3 − 0 . 5) 2 + 10 X i 4 + 5 X i 5 (5) h 2 ( t, X i , D i ) = X i 1 + tX i 1 + 3 X i 4 + 5 tX i 5 + γ tD i . (6) 11 The interaction between cov ariates and time in (6) breaks the parallel trends assumption required for competing methods OLS and DID. The true treatment effect is set to γ = 3 . The other param- eters are set to ρ = 0 . 3 , σ 2 = 1 and m = 32 so n = m 2 = 1024 . A complete random sample of 20% of the Y it are taken to be missing. W e vary ν ∈ { 1 , 2 , 5 } to explore ho w changes in the smoothness af fect the efficac y of our ST -DML method. W e simulate 120 datasets for each ν . For each dataset, we fit six versions of the ST -DML method. W e vary the feature sets in the first-stage BAR T regressions: X i only (“X”), X i and s i (“XS”), and X i , s i and Z i with L = 100 basis functions (“XSZ”). Each method is fit with and without crossfitting. For B AR T on outcome Y 0 and Y 1 , we use the def ault settings in the bart function from the dbarts package (Dorie, 2025); for B AR T on the treatment D , we use the default settings in the pbart function from the BART package (Chipman et al., 2010). W e compare ST -DML with the spatiotemporal dif ference-in- dif ferences (ST -DID) method proposed by Delgado and Florax (2015). They include the mean of the treatment at neighboring locations as a local confounder adjustment. Let N i be the collection of m i sites deemed as neighbors of site i , and ¯ D i = P j ∈N i D j /m i be the proportion of the neighbors gi ven the intervention. This local treatment adjustment is added as Y it = X it β + δ t + αD i + ¯ α ¯ D i + γ tD i + ¯ γ t ¯ D i + ε it . (7) W e also compare this with an unadjusted ordinary least squares (OLS) fit that sets ¯ α = ¯ γ = 0 . For both methods, the interaction ef fect γ is causal ef fect of interest, estimated using least squares. Methods are compared with bias, mean squared error (MSE), av erage confidence interval length and cov erage of 95% confidence intervals for the treatment ef fect, γ . 4.2 Simulation design with clustered treatment allocation In our motiv ating application, treatment is allocated to spatially continuous blocks. In this simu- lation, we test whether our pixel-le vel spatial model can accommodate this block treatment allo- cation. W e partition the n pixels into G = 64 blocks, each a 4 × 4 rectangle. Let g i ∈ { 1 , ..., G } be the block that contains pix el i . Treatment is allocated at the block le vel using the block av erage 12 of the cov ariates. F or j ∈ { 1 , ..., p } and g ∈ { 1 , ..., G } , let ¯ X g j be the mean of X ij in block g and ¯ X g = (1 , ¯ X g 1 , ..., ¯ X g p ) . Then the treatment in block g is generated as logit { Prob ( ¯ D g = 1) } = h 1 ( ¯ X g ) and individual pixels are assigned the block treatment, D i = ¯ D g i . The observations are then generated as Y it = α g i + h 2 ( t, X i , D i ) + ε it (8) where α g iid ∼ Normal (0 , τ 2 ) , ε it iid ∼ Normal (0 , σ 2 ) , and τ 2 = σ 2 = 0 . 25 , where functions h 1 and h 2 are in (5) and (6). There are no missing observ ations and we simulate 120 datasets. W e test six versions of the ST -DML approach. All methods include X i , s i and L = 100 W endland basis functions Z i as features in B AR T . W e consider three methods of crossfitting: no crossfitting and crossfitting “by pixel” and “by block. ” In crossfitting by pixel, we allocate pixels to the K = 10 folds, as in the simulation described on data without clustered treatment, but for crossfitting by block we randomly assign the G blocks to the K folds and allocate pixels according to their block’ s assignment. In the second stage for block crossfitting, we modify equation (4) to be R Y it = β + δ t + α R D i + γ tR D i + ε it . W e perform all 3 crossfitting methods using B AR T with and without random effects in the first stage. In crossfitting, we integrate random effects by block as Y it = α g i t + f t ( X it , s i ) + ϵ it with α g t indep ∼ Normal (0 , τ 2 t ) separately for t ∈ { 0 , 1 } and logit { Prob ( ¯ D g = 1) } = g ( ¯ X g ) . This random-effect model is fit using the function rbart vi in the package dbarts for BAR T on the outcome v ariable (Dorie, 2025), whereas the treatment v ariable’ s fit continues using pbart from the BART package. 4.3 Results The results of the pix el-lev el simulation with ν = 2 are giv en in T able 1; see Appendix B for the results with the other smoothness parameters. For all three smoothness le vels, competing methods OLS and DID suffer from large bias and MSE and low cov erage. The ST -DML methods that use spatial information in B AR T are more efficient than non-spatial methods, with ST -DML with cross-fitting and W endland basis expansion in the first stage performing best of all compared methods. W ith the exception of the methods that exclude spatial information, the bias and MSE are both lower for the ST -DML methods with crossfitting compared to their corresponding methods 13 without crossfitting. From these simulations, we conclude that using B AR T with the W endland basis e xpansion and crossfitting pro vides our strongest estimation for treatment ef fect γ . Although this is true across all smoothness v alues, our suggested ST -DML method grows more accurate as smoothness increases (see Appendix). T able 1: Comparison of ordinary least squares (OLS), difference-in-dif ferences (DID) and spa- tiotemporal double ML (DML) for pixel-le vel tr eatment allocation and smoothness ν = 2 . DML methods vary by excluding spatial information (X), using spatial coordinates (XS) and spa- tial basis functions (XSZ) in B AR T fits and performing DML with and without cross-fitting (CF). Methods for estimating the treatment effect are compared using bias, mean squared error (MSE), confidence interv al (CI) length and coverage of 95% interv als. Method Bias MSE CI length Coverage OLS 0 . 821 1 . 191 1 . 578 0 . 433 DID 0 . 535 0 . 536 1 . 839 0 . 825 DML - X - no CF 0 . 485 0 . 457 1 . 687 0 . 800 DML - X - CF 0 . 643 0 . 633 1 . 771 0 . 733 DML - XS - no CF − 0 . 614 0 . 445 0 . 724 0 . 133 DML - XS - CF 0 . 223 0 . 123 1 . 070 0 . 883 DML - XSZ - no CF − 0 . 763 0 . 624 0 . 583 0 . 017 DML - XSZ - CF 0 . 083 0 . 044 0 . 853 0 . 933 W e proceed to the simulation with block treatment allocation as described in Section 4.2. T a- ble 2 and Figure 3 (see Appendix A.1) compare ST -DML methods with OLS and DID. ST -DML performs more accurately with crossfitting but without random ef fects integrated in B AR T . Cross- fitting by block yields the lo west bias, b ut co verage and MSE are better when crossfitting by pix el. These two methods outperform competing methods OLS and DID, as well as other ST -DML meth- ods that do not have crossfitting or that utilize random block ef fects directly . From these compar- isons, we conclude that DML with W endland basis expansion and crossfitting by pixel, without random ef fects, is the strongest methodology for data with clustered treatment allocation. 5 A pplication to Cambodian def orestation T o analyze the Cambodian deforestation data, follo wing the results in Section 4, we use ST -DML with crossfitting by pixel and without random effects. W e first analyze the relativ e v ariable im- 14 T able 2: Comparison of ordinary least squares (OLS), difference-in-dif ferences (DID) and spa- tiotemporal double ML (DML) for block-level treatment allocation . DML methods are fit with and without block random effects (RE) in the first stage and with no cross-fitting and cross-fitting by pixel and block. Methods for estimating the treatment effect are compared using bias, mean squared error (MSE), credible interv al (CI) length and coverage of 95% interv als. Method Bias MSE CI length Cov erage OLS 0.664 1.686 1.614 0.525 DID – 0.384 0.881 4.558 0.983 DML - no RE - no CF – 0.844 0.824 1.330 0.267 DML - no RE - pixel CF – 0.197 0.112 1.413 0.983 DML - no RE - block CF 0.132 0.352 0.923 0.583 DML - RE - no CF 1.133 1.585 0.981 0.133 DML - RE - pixel CF 1.148 1.978 2.849 0.650 DML - RE - block CF 0.486 1.396 1.803 0.583 portance of different confounders that affect treatment and outcome in the first-stage B AR T fits. The statistic varcount from the dbarts package measures v ariable importance during our B AR T fitting in the first stage of ST -DML ( L = 100) and is recorded in T able 3. W e average the varcount statistic across all K folds. Forest cover is one of the most important confounding v ariables affecting both treatment and outcome. This is reasonable because there should not be large amounts of deforestation where there are fe w trees. Like wise, barren lands are often less desirable for farming and logging than fertile, forested ones – leading to less concessions asso- ciated with lands of less forest cover . Climate v ariables precipitation and temperature also prov e important, likely because they affect the gro wth of different crops. On the other hand, population, urbanization, and water v ariables are less important in our stage-one modeling. The y ha ve less impact on deforestation and concessions. T able 3: V ariable Importance for the B AR T fits using L = 100 spatial basis functions V ariable F orest Cover Ele vation Population Pr ecip T emp Urban W ater Y 0 66.5 18.4 6.0 15.7 13.8 7.0 3.9 Y 1 60.7 17.1 3.8 14.4 16.7 1.4 4.8 D 19.8 11.2 3.6 9.9 11.6 1.6 1.2 When we estimate the effect of land concessions on deforestation, we witness a positiv e treat- 15 ment effect (i.e., concessions slightly increase deforestation) for all methodologies (T able 4). Ho w- e ver , compared to OLS and DID, we hav e a much smaller treatment ef fect from the ST -DML method that more effecti vely removes spatial confounders. W e compare the estimated treatment ef fect as we vary the number of knot points in the W endland basis expansion ( L ) for ST -DML ’ s stage one BAR T input. Figure 2 demonstrates that including the spatial basis functions reduces the treatment ef fect, but the results are not sensiti ve to the number of basis functions. Accord- ing to our full model in volving crossfitting and W endland dimension expansion with L = 100 , a raster conceded in Cambodia experiences about 1.8 % of extra deforestation on av erage than one not conceded. This is a small number; potential reasons limiting its magnitude include rampant illegal deforestation on non-conceded lands or companies waiting long periods of time to begin deforestation. This demonstrates a small but statistically significant effect of land concessions on deforestation in Cambodia. T able 4: Ef fect estimates for the Cambodia data using ordinary least squares (OLS), spatiotem- poral Differences in Dif ferences (DID) and double machine learning without (DML - nonspatial) and with (DML - spatial) including spatial cov ariates ( s and L = 100 W endland basis functions) in B AR T fits. Method Estimate Standard Error CI Lower CI Upper OLS 2.63 0.34 1.97 3.29 DID 1.74 0.30 1.15 2.34 DML - nonspatial 1.87 0.31 1.27 2.48 DML - spatial 1.86 0.31 1.25 2.48 6 Discussion The proposed spatiotemporal double machine learning approach addresses missing confounders in ev aluating policy interventions with spatiotemporal observational data. W e propose a flexible model using Bayesian Additiv e Regression Trees (BAR T) with a spatial embedding layer to ac- count for missing spatial cov ariates present before and after treatment. A simulation study was conducted with two designs to ev aluate the performance of the DML methods. The first design is with treatment allocation at the pixel lev el and the second is with clustered treatment allocation. 16 Figure 2: Treatment ef fect estimation using varying lev els of spatial information, from no spatial information to L = 196 W endland basis functions. The points are estimates, and bars are 95 % confidence interv als. For both studies, when addressing unobserved spatial confounding, our ST -DML model outper- forms the leading approaches. Our application of ST -DML to ev aluate the policy impacts of land concession on deforestation in Cambodia finds that for when treatments are observed in Cambodia, the av erage amount of deforestation increases by 2 % . Limitations in this study design provide enticing areas for future research. For example, we assumed a homogeneous treatment effect, but the effect of land concessions may in fact exhibit dif ferences in various regions of Cambodia (i.e., crop type). W e could consider statistics like the conditional average treatment effect that provide insight on potential treatment heterogeneity . Similarly , our simulated model of treatment allocation (based on equally-sized, square blocks) does account for clustered treatments, but it fails to account for the di versity of sizes and shapes of land concessions. Our simulated treatment clusters were defined solely on basis of spatial proximity , while real land polygons may hav e other confounders in common that influence concession deci- sions. Future work can include treatment allocation models that more accurately capture real-world 17 concession processes. Finally , future w ork can incorporate further novel perspectiv es on our inputs of space and time. Currently , we account for time as a binary variable, where we consider “before” as the 4 years pre-treatment, and “after” as the concession year and the following 3 years. Howe ver , this fails to consider how some companies may take longer than 4 years to begin their processes of defor- estation (potentially contributing to our relati vely small 2 % treatment ef fect). This, along with the presence of rampant illegal deforestation on non-conceded lands, could explain ho w the treatment ef fect of 1 . 8% is relativ ely small in magnitude. Another potential step could be consideration of time in 3 or more dif ferent stages or as a continuous variable. Regarding space, we considered neighborhood effects during our analysis, but we did not account for larger -scale spillov er ef fects that still occur outside of adjacent squares. Incorporating this spillo ver could be an interesting next step in in vestigating this policy e valuation problem. Acknowledgements This work was supported by the National Science Foundation (DMS2349611) and National Insti- tutes of Health (1R01ES036270-01A1). Refer ences Abadie, A. (2005) Semiparametric dif ference-in-differences estimators. The Revie w of Economic Studies , 72 , 1–19. URL http://www.jstor.org/stable/3700681 . Bach, P ., Schacht, O., Chernozhukov , V ., Klaassen, S. and Spindler , M. (2024) Hyperparameter T uning for Causal Inference with Double Machine Learning: A Simulation Study. Pr oceedings of Machine Learning Researc h , 236 . URL h tt ps: // pro ce ed ing s. mlr .p re ss/ v2 36 /bach24a.html . Bardaka, E., Delgado, M. S. and Florax, R. J. (2019) A spatial multiple treatment/multiple out- come dif ference-in-differences model with an application to urban rail infrastructure and gentri- fication. T r ansportation Resear ch P art A: P olicy and Practice , 121 , 325–345. Bhuyan, P ., McCoy , E. J., Li, H. and Graham, D. J. (2021) Analysing the Causal Ef fect of London 18 Cycle Superhighways on T raffic Congestion. The Annals of Applied Statistics , 15 . URL https: //www.jstor.org/stable/27273919 . Black, B. and Anthony , B. P . (2022) Counterfactual assessment of protected area av oided deforesta- tion in Cambodia: Trends in effecti veness, spillov er effects and the influence of establishment date. Global Ecology and Conservation , 38 , e02228. Blair , G., Cooper , J., Coppock, A., Humphreys, M. and Sonnet, L. (2025) estimatr: F ast estimators for design-based infer ence . URL h t tp s: // CR AN .R- p ro je ct .o rg / pa ck ag e= es t im atr . R package v ersion 1.0.6. Bolin, D. and W allin, J. (2024) Spatial Confounding Under Infill Asymptotics. . BRA CK, D. (2003) Illegal logging and the illegal trade in forest and timber products. The Inter- national F or estry Revie w , 5 , 195–198. Butts, K. (2021) Dif ference-in-differences estimation with spatial spillovers. arXiv pr eprint arXiv:2105.03737 . Chen, W ., Li, Y ., Reich, B. J. and Sun, Y . (2024) Deepkriging: spatially dependent deep neural networks for spatial prediction. Statistica Sinica , 34 , 291–311. Chernozhuko v , V ., Chetveriko v , D., Demirer , M., Duflo, E., Hansen, C., Ne wey , W . and Robins, J. (2018) Double/debiased machine learning for treatment and structural parameters. Chipman, H. A., George, E. I. and McCullogh, R. E. (2010) B AR T : Bayesian Additi ve Regression T rees. The Annals of Applied Statistics . Contributors, G. (2020) Geospatial data abstraction softw are library . Copernicus Climate Change Service (2025) ERA5: Fifth generation of ECMWF atmospheric re- analyses of the global climate. URL h tt ps: // ww w.e cm wf. in t/ en/ fo re cas ts /d a t aset/ecmwf- reanalysis- v5 . A vailable at: ECMWF . Accessed on 3 Jun 2025. Copernicus DEM (2019) Global and European Digital Elev ation Model. European Space Agency (ESA) & European Union’ s Copernicus Programme. Programme of the European Union and European Space Agenc y (ESA). Modified Copernicus Sentinel data [2025] processed in Coper - nicus Bro wser. Delgado, M. S. and Florax, R. J. (2015) Difference-in-dif ferences techniques for spatial data: Local autocorrelation and spatial interaction. Economics Letters , 137 , 123–126. Dorie, V . (2025) dbarts: Discr ete Bayesian Additive Re gr ession T rees Sampler . URL h t t p s : //CRAN.R- project.org/package=dbarts . R package version 0.9-32. Dupont, E., Marques, I. and Kneib, T . (2024) Demystifying Spatial Confounding. arXiv:2309.16861 . 19 European Union’ s Copernicus Land Monitoring Service (2025) Global Dynamic Land Cover. URL h t t p s : // l a n d . c o p e r n i c u s . e u / e n / p r o d u c t s/ g l o b a l- d y n a m i c- l a n d- c o v e r ? t a b = o v e r v i e w . This publication has been prepared using European Union’ s Copernicus Land Monitoring Service information. Accessed 3 Jun 2025. Falasca, F ., Perezhogin, P . and Zanna, L. (2024) Data-driv en dimensionality reduction and causal inference for spatiotemporal climate fields. American Physical Society , 109 . Gorelick, N., Hancher , M., Dixon, M., Ilyushchenko, S., Thau, D. and Moore, R. (2017) Google Earth Engine: Planetary-scale geospatial analysis for e veryone. Remote Sensing of En vir onment , 202 , 18–27. Big Remotely Sensed Data: tools, applications and experiences. Guizar-Couti ˜ no, A., Jones, J. P ., Balmford, A., Carmenta, R. and Coomes, D. A. (2022) A global e valuation of the ef fectiv eness of voluntary REDD+ projects at reducing deforestation and degra- dation in the moist tropics. Conservation Biology , 36 , e13970. Hansen, M. C., Potapov , P . V ., Moore, R., Hancher, M., T urubanov a, S. A., T yukavina, A., Thau, D., Stehman, S. V ., Goetz, S. J., Lov eland, T . R., Kommareddy , A., Egorov , A., Chini, L., Justice, C. O. and T o wnshend, J. R. G. (2013) High-resolution global maps of 21st-century forest cover change. Science , 342 , 850–853. URL https ://www.sc ience.or g/doi/abs /10.112 6/science.1244693 . Hurni, K. and Fox, J. (2018) Rubber has replaced many of southeast asia’ s natural forests. T ech. r ep. , East-W est Center . URL http://www.jstor.org/stable/resrep24570 . K eller , J. P . and Szpiro, A. A. (2020) Selecting a Scale for Spatial Confounding Adjustment. J our- nal of the Royal Statistical Society: Series A (Statistics in Society) , 1121–1143. K ¨ uhne, F ., Schomaker , M., Stojko v , I., Jahn, B., Conrads-Frank, A., Siebert, S., Sroczynski, G., Puntscher , S., Schmid, D., Schnell-Inderst, P . and Siebert, U. (2022) Causal evidence in health decision making: methodological approaches of causal inference and health decision science. German medical science: GMS e-journal , 20 . Li, J., Xue, J., W ei, J., Ren, Z., Y u, Y ., An, H., Y ang, X. and Y ang, Y . (2023) Insighting Driv ers of Population Exposure to Ambient Ozone Concentrations across China Using a Spatiotemporal Causal Inference Method. Remote Sensing , 15 . LICADHO (2024) Cambodia’ s concessions. URL ht tps: //ww w.li cadh o- ca mbod ia.o r g/land_concessions/ . Accessed on 2 Jun 2025. MacKinnon, J. G. and White, H. (1985) Some heterosk edasticity-consistent cov ariance matrix estimators with improv ed finite sample properties. J ournal of econometrics , 29 , 305–325. McCulloch, R. and Sparapani, R. (2025) BART : implements Bayesian Additive Re gression T r ees into R . URL https://CRA N . R- project.org/package= p a ckage_name . R package version 1.0.0. 20 Nychka, D., Bandyopadh yay , S., Hammerling, D., Lindgren, F . and Sain, S. (2015) A multiresolu- tion Gaussian process model for the analysis of lar ge spatial datasets. Journal of Computational and Graphical Statistics , 24 , 579–599. Paciorek, C. J. (2007) Bayesian smoothing with Gaussian processes using Fourier basis functions in the spectralGP library . J ournal of Statistical Softwar e , 19 . Pauly , M., Crosse, W . and T osteson, J. (2022) High deforestation trajectories in Cambodia slo wly transformed through economic land concession restrictions and strategic ex ecution of REDD+ protected areas. Scientific r eports , 12 , 17102. Reich, B. J., Y ang, S., Guan, Y ., Giffin, A. B., Miller , M. J. and Rappold, A. (2021) A Revie w of Spatial Causal Inference Methods for En vironmental and Epidemiological Applications. Inter- national Statistical Revie w , 89 , 605–634. Rubin, D. B. (1974) Estimating Causal effects of treatments in randomized and nonrandomized studies. J ournal of Educational Psycholo gy , 66 , 688. Um, K. (2014) Cambodia in 2013: The winds of change. Southeast Asian Af fairs , 99–116. UNEP-WCMC and IUCN (2025) Protected Planet: The W orld Database on Protected Areas (WDP A). V andenbroucke, J. P ., Broadbent, A. and Pearce, N. (2016) Causality and causal inference in epi- demiology: the need for a pluralistic approach. International Journal of Epidemiology , 45 . URL https://doi.org/10.1093/ije/dyv341 . W est, T . A., W under , S., Sills, E. O., B ¨ orner , J., Rifai, S. W ., Neidermeier , A. N., Frey , G. P . and K ontoleon, A. (2023) Action needed to make carbon offsets from forest conservation work for climate change mitigation. Science , 381 , 873–877. W iecha, N., Hoppin, J. A. and Reich, B. J. (2025) T wo-stage spatial regression models for spatial confounding. Biometrics , 81 , ujaf093. W orldPop Research Programme (2015) Open Spatial Demographic Data and Research. W orldPop. URL https://www.worldpop.org/ . Accessed on 3 Jun 2025. 21 A ppendix A: Removal of spatial conf ounders Here we provide a heuristic justification that the proposed estimator can account for spatially- smooth unmeasured confounders. W e make the follo wing assumptions: (A1) The data-generating model is Y it = θ it + t γ D i + ϵ it . (A2) The spatial processes are decomposed as θ it = u it + e it , t ∈ { 0 , 1 } , D i = u i 2 + e i 2 where u are spatially smooth and e is spatially-independent local error . (A3) The first stage estimators can fit the spatially smooth components. Thus, ˆ Y it = u it + γ tu i 2 , t ∈ { 0 , 1 } , ˆ D i = u i 2 . (A4) The local errors satisfy E " n X i =1 e i 2 ( e i 1 + ϵ i 1 ) e 2 # = 0 . B AR T is fit in the first stage to obtain estimators ˆ Y i 0 , ˆ Y i 1 and ˆ D i . W ith the abov e assumptions, the residuals from the regression are R i 0 = Y i 0 − ˆ Y i 0 = [ u i 0 + e i 0 + ϵ i 0 ] − u i 0 = e i 0 + ϵ i 0 , R i 1 = Y i 1 − ˆ Y i 1 = [ u i 1 + e i 1 + γ ( u i 2 + e i 2 ) + ϵ i 1 ] − [ u i 1 + γ u i 2 ] = e i 1 + ϵ i 1 + γ e i 2 , R i 2 = D i − ˆ D i = [ u i 2 + e i 2 ] − u i 2 = e i 2 . 22 The ordinary least-squares estimator ˆ γ is ˆ γ = P n i =1 R i 1 R i 2 P n i =1 R 2 i 2 = P n i =1 [ e i 1 + ϵ i 1 + γ e i 2 ] e i 2 P n i =1 e 2 i 2 = γ + P n i =1 [ e i 1 + ϵ i 1 ] e i 2 P n i =1 e 2 i 2 . (9) For ˆ γ to be an unbiased estimator , 0 = E P n i =1 ( e i 1 + ϵ i 1 ) e i 2 P n i =1 e 2 i 2 = E E P n i =1 ( e i 1 + ϵ i 1 ) e i 2 P n i =1 e 2 i 2 e 2 = { e 12 , e 22 , . . . , e n 2 } = E E [ P n i =1 e i 2 ( e i 1 + ϵ i 1 ) | e 2 ] P n i =1 e 2 i 2 . The denominator P n i =1 e 2 i 2 > 0 and the numerator is zero by Assumption A4, so the bias is zero. Of course, this result hinges on Assumption A3 that spatial trends are e xactly remo ved by the first- stage regression, which is unrealistic, but the argument presented here builds the intuition for the two-stage estimator . A ppendix B: Additional simulation study r esults T ables 5 and 6 gi ve the results of the pixel-le vel treatment allocation simulation with smoothness parameters ν = 1 and ν = 5 , respectiv ely . The results of the block-lev el treatment assignment are visualized in Figure 3 23 T able 5: Comparison of ordinary least squares (OLS), difference-in-dif ferences (DID) and spa- tiotemporal double ML (DML) for pixel-le vel tr eatment allocation and smoothness ν = 1 . DML methods vary by excluding spatial information (X), using spatial coordinates (XS) and spa- tial basis functions (XSZ) in B AR T fits and performing DML with and without cross-fitting (CF). Methods for estimating the treatment effect are compared using bias, mean squared error (MSE), confidence interv al (CI) length and coverage of 95% interv als. Method Bias MSE CI length Coverage OLS 0 . 812 1 . 090 1 . 571 0 . 483 DID 0 . 570 0 . 541 1 . 826 0 . 775 DML no spatial no cross 0 . 562 0 . 522 1 . 739 0 . 775 DML no spatial with cross 0 . 695 0 . 700 1 . 812 0 . 700 DML with spatial no cross − 0 . 328 0 . 182 0 . 948 0 . 650 DML with spatial with cross 0 . 344 0 . 213 1 . 261 0 . 825 W endland without cross − 0 . 494 0 . 294 0 . 790 0 . 267 W endland with cross 0 . 187 0 . 091 1 . 055 0 . 917 T able 6: Comparison of ordinary least squares (OLS), difference-in-dif ferences (DID) and spa- tiotemporal double ML (DML) for pixel-le vel tr eatment allocation and smoothness ν = 5 . DML methods vary by excluding spatial information (X), using spatial coordinates (XS) and spa- tial basis functions (XSZ) in B AR T fits and performing DML with and without cross-fitting (CF). Methods for estimating the treatment effect are compared using bias, mean squared error (MSE), confidence interv al (CI) length and coverage of 95% interv als. . Method Bias MSE CI length Coverage OLS 0 . 835 1 . 308 1 . 573 0 . 475 DID 0 . 541 0 . 589 1 . 832 0 . 750 DML no spatial no cross 0 . 435 0 . 434 1 . 619 0 . 767 DML no spatial with cross 0 . 615 0 . 625 1 . 714 0 . 675 DML with spatial no cross − 0 . 834 0 . 744 0 . 565 0 . 033 DML with spatial with cross 0 . 140 0 . 081 0 . 900 0 . 892 W endland without cross − 0 . 934 0 . 908 0 . 472 0 . 000 W endland with cross 0 . 017 0 . 037 0 . 709 0 . 967 24 Figure 3: Simulation study comparing OLS, DID, three methods without random effects, and three methods with random ef fects. The true value of γ = 3 , and smoothness ν = 2 . 25
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment