Thinking by Subtraction: Confidence-Driven Contrastive Decoding for LLM Reasoning
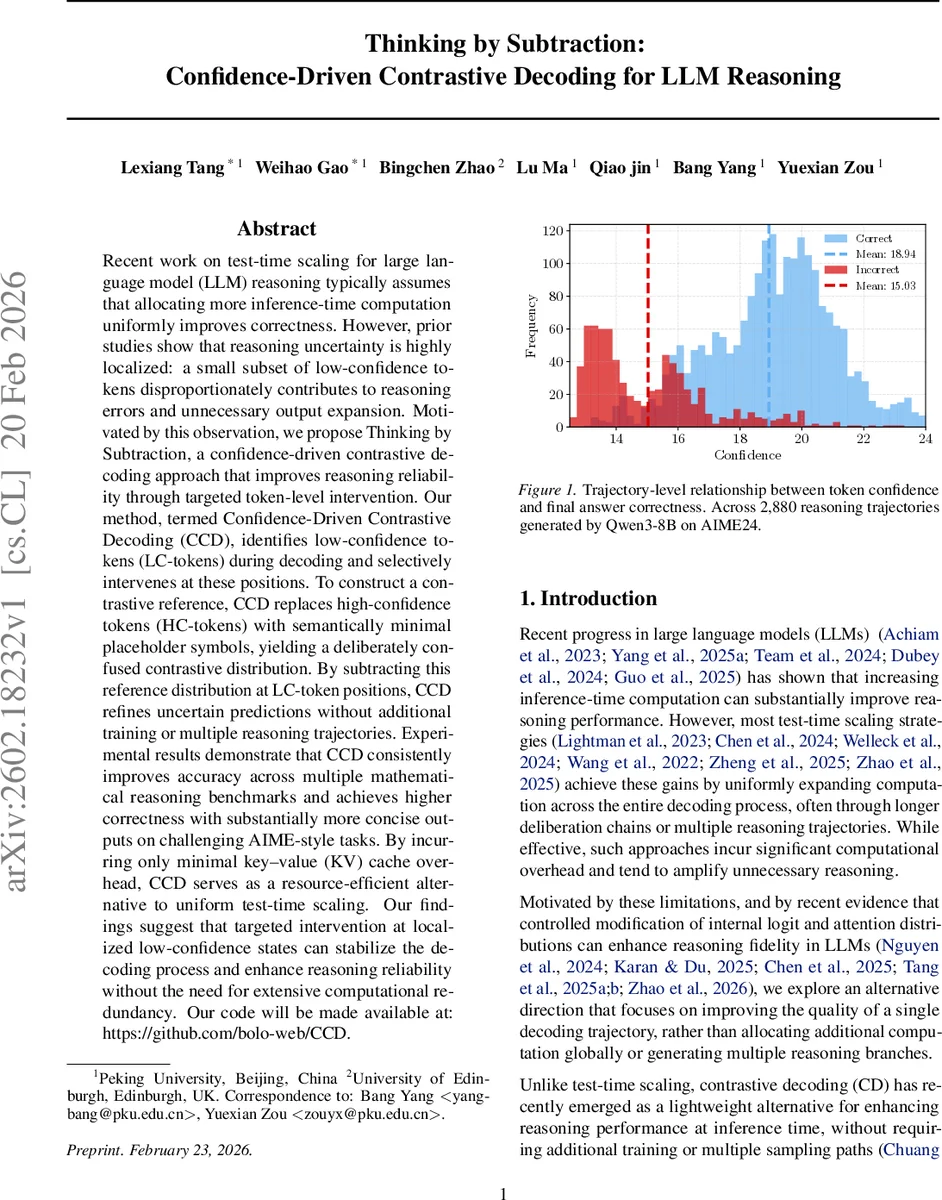
Recent work on test-time scaling for large language model (LLM) reasoning typically assumes that allocating more inference-time computation uniformly improves correctness. However, prior studies show that reasoning uncertainty is highly localized: a small subset of low-confidence tokens disproportionately contributes to reasoning errors and unnecessary output expansion. Motivated by this observation, we propose Thinking by Subtraction, a confidence-driven contrastive decoding approach that improves reasoning reliability through targeted token-level intervention. Our method, Confidence-Driven Contrastive Decoding, detects low-confidence tokens during decoding and intervenes selectively at these positions. It constructs a contrastive reference by replacing high-confidence tokens with minimal placeholders, and refines predictions by subtracting this reference distribution at low-confidence locations. Experiments show that CCD significantly improves accuracy across mathematical reasoning benchmarks while substantially reducing output length, with minimal KV-cache overhead. As a training-free method, CCD enhances reasoning reliability through targeted low-confidence intervention without computational redundancy. Our code will be made available at: https://github.com/bolo-web/CCD.
💡 Research Summary
The paper introduces Confidence‑Driven Contrastive Decoding (CCD), a test‑time, training‑free method that improves the reliability of large language model (LLM) reasoning by intervening only at low‑confidence decoding steps. The authors begin by observing that reasoning errors in LLMs are highly localized: a small subset of tokens generated with low predictive confidence disproportionately cause downstream mistakes and unnecessary output expansion. Rather than uniformly increasing inference‑time computation—as done in most test‑time scaling approaches—the authors propose to detect low‑confidence tokens (LC‑tokens) on the fly and apply a contrastive decoding correction exclusively at those positions.
Token‑level confidence is quantified as the negative average log‑probability of the top‑k candidates (Equation 1). A sliding window of recent confidences provides a local estimate of the confidence dynamics. Tokens whose confidence falls below a quantile threshold τ_cd (derived from the window) are marked as LC‑tokens; those above a higher quantile τ_rep are marked as high‑confidence (HC‑tokens).
When an LC‑token is encountered, CCD constructs a “contrastive context” by replacing all HC‑tokens in the recent history with a neutral placeholder token (e.g.,
Implementation-wise, CCD maintains two parallel key‑value (KV) caches: a standard main cache for ordinary autoregressive generation and a contrastive cache that stores the placeholder‑masked hidden states. The contrastive cache is updated only for HC‑tokens, so the extra memory footprint is a single additional KV cache of the same size as the original. No extra forward passes through the transformer are required; the only additional computation is the logit subtraction, making the overhead predictable and modest (approximately 1.1× the baseline KV‑cache cost).
The authors provide a theoretical justification: high‑confidence tokens receive large attention weights and act as semantic anchors, so masking them perturbs the hidden representation z_t substantially (first‑order Taylor expansion). This reduces the mutual information between context and next token, raising conditional entropy and flattening the contrastive distribution. Subtracting this flatter distribution from the confident main distribution increases the top‑logit margin at the LC‑token, thereby raising its confidence and stabilizing the reasoning trajectory.
Empirically, CCD is evaluated on four challenging mathematical reasoning benchmarks: AIME 2024, AIME 2025, BRUMO 2025, and HMMT 2025. The method is tested on a suite of open‑weight LLMs ranging from 4 B to 32 B parameters (Qwen3‑4B/8B/14B/32B) and a distilled 1.5 B model (DeepSeek‑R1‑Distill‑Qwen‑1.5B). Across all models and datasets, CCD consistently improves answer accuracy by 4–7 percentage points compared to standard greedy or beam decoding, while simultaneously reducing output length by 20–35 %. The gains are achieved without any fine‑tuning, additional supervision, or multiple reasoning trajectories.
In summary, CCD demonstrates that targeted, confidence‑aware contrastive decoding can substantially enhance LLM reasoning performance with minimal computational cost. By focusing resources on the few uncertain tokens rather than uniformly expanding computation, CCD offers a practical, model‑agnostic plug‑in for improving reliability in real‑world inference settings. The paper’s contributions include (1) the formulation of confidence‑driven token selection, (2) a lightweight contrastive decoding mechanism that leverages placeholder‑masked contexts, (3) a dual‑KV‑cache implementation with negligible overhead, and (4) extensive empirical validation showing both accuracy and efficiency improvements. This work opens a new direction for test‑time inference optimization that balances performance gains with resource constraints.
Comments & Academic Discussion
Loading comments...
Leave a Comment