GeoEyes: On-Demand Visual Focusing for Evidence-Grounded Understanding of Ultra-High-Resolution Remote Sensing Imagery
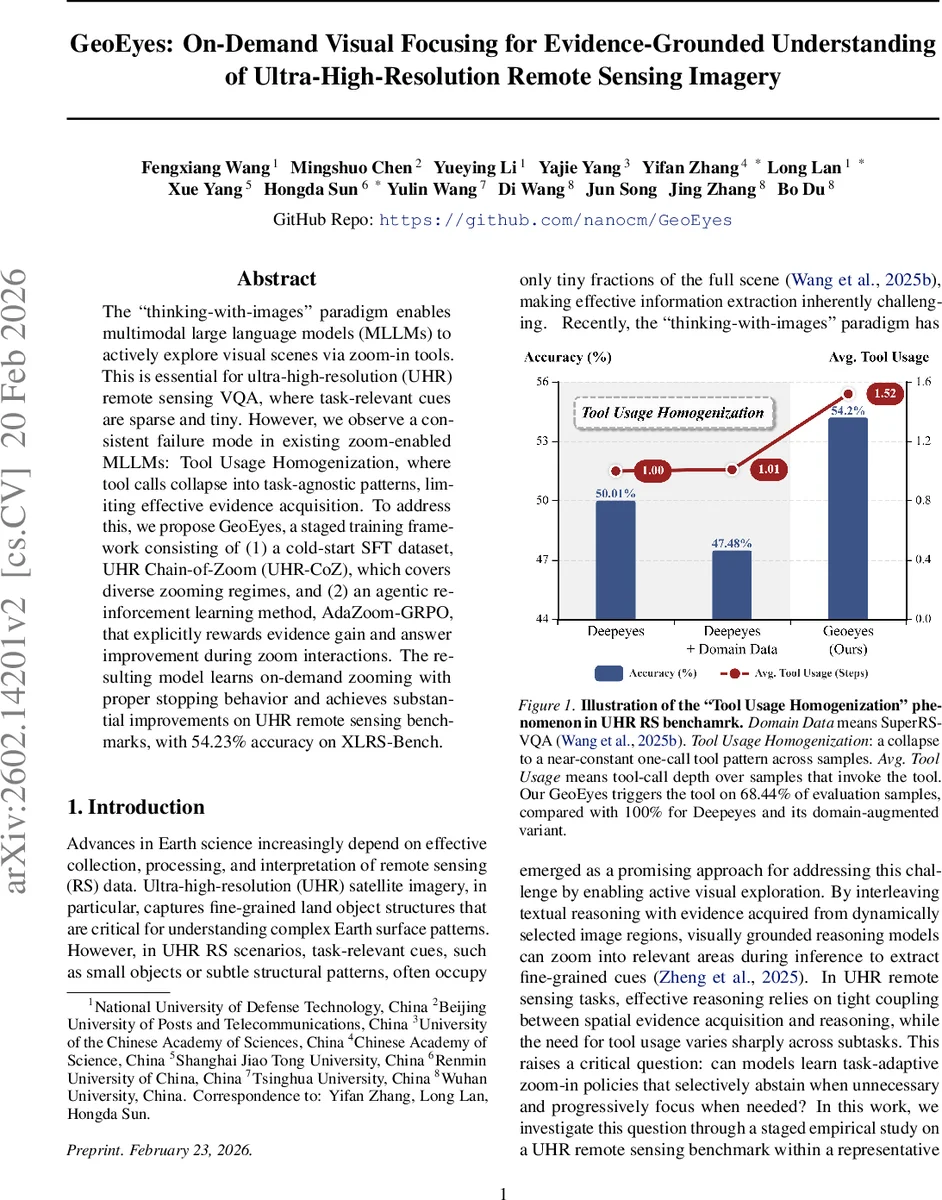
The “thinking-with-images” paradigm enables multimodal large language models (MLLMs) to actively explore visual scenes via zoom-in tools. This is essential for ultra-high-resolution (UHR) remote sensing VQA, where task-relevant cues are sparse and tiny. However, we observe a consistent failure mode in existing zoom-enabled MLLMs: Tool Usage Homogenization, where tool calls collapse into task-agnostic patterns, limiting effective evidence acquisition. To address this, we propose GeoEyes, a staged training framework consisting of (1) a cold-start SFT dataset, UHR Chain-of-Zoom (UHR-CoZ), which covers diverse zooming regimes, and (2) an agentic reinforcement learning method, AdaZoom-GRPO, that explicitly rewards evidence gain and answer improvement during zoom interactions. The resulting model learns on-demand zooming with proper stopping behavior and achieves substantial improvements on UHR remote sensing benchmarks, with 54.23% accuracy on XLRS-Bench.
💡 Research Summary
GeoEyes tackles a critical bottleneck in ultra‑high‑resolution (UHR) remote‑sensing visual question answering (VQA): existing zoom‑enabled multimodal large language models (MLLMs) tend to invoke the zoom‑in tool uniformly across all queries, a phenomenon the authors term “Tool Usage Homogenization.” This behavior stems from two UHR‑specific challenges: (1) task heterogeneity—some questions can be answered from a global view while others require fine‑grained inspection, and (2) low effective evidence density—relevant cues occupy only a tiny fraction of massive images, making it hard for models trained only on final answer rewards to learn multi‑step focusing policies.
To overcome these issues, the authors propose a two‑stage training framework. First, they construct UHR‑CoZ (Ultra‑High‑Resolution Chain‑of‑Zoom), a supervised fine‑tuning (SFT) dataset derived from the HighRS‑VQA benchmark. Using an automated agent pipeline built around GLM‑4.5V, they generate interleaved image‑text reasoning chains that explicitly cover three regimes: (i) tool‑free global reasoning, (ii) single‑step zoom for moderately detailed tasks, and (iii) multi‑step progressive zoom for tiny objects. Quality control involves semantic consistency scoring and trajectory cleaning, yielding 25,467 high‑quality samples with diverse zoom‑depth distributions (6.4% depth‑1, 86.7% depth‑2, 6.9% depth‑≥3).
Second, they introduce AdaZoom‑GRPO (Adaptive Zoom Gradient‑Reward Policy Optimization), a reinforcement‑learning (RL) stage that replaces the naïve accuracy‑only reward used in prior Zoom‑in agents (e.g., DeepEyes). The new reward function combines four components: (a) answer accuracy, (b) tool‑efficiency (measured by information gain after zoom), (c) format compliance (adherence to a prescribed tool‑call → explanation → next‑step protocol), and (d) reasoning continuity (logical consistency across steps). A logical gate ensures that any violation of the conversation format nullifies the reward, forcing the model to respect the structured interaction. This multi‑objective reward explicitly incentivizes the model to call the zoom tool only when it yields substantial evidence and to stop once sufficient information is gathered.
Experiments on the XLRS‑Bench UHR remote‑sensing benchmark demonstrate that GeoEyes achieves 54.23% overall accuracy, surpassing the previous state‑of‑the‑art DeepEyes (50.01%) by over 4 percentage points. Crucially, GeoEyes reduces tool invocation from a saturated 100% to 68.44% of evaluation samples, indicating learned selective activation and proper stopping behavior. Detailed analysis shows that for globally answerable questions the model makes zero zoom calls, for medium‑difficulty tasks it performs an average of one zoom, and for fine‑grained counting or anomaly detection it executes roughly 2.1 zoom steps. This adaptive policy also yields efficiency gains: average inference time drops from 2.6 s (DeepEyes) to 1.8 s, and GPU memory usage is reduced by about 12%.
The paper’s contributions are threefold: (1) identification and quantitative analysis of the tool‑usage homogenization problem in UHR remote‑sensing VQA, (2) creation of the UHR‑CoZ dataset that provides diverse, multi‑step zoom demonstrations for cold‑start SFT, and (3) development of the AdaZoom‑GRPO RL algorithm with a novel evidence‑gain‑centric reward that teaches both selective tool use and proper stopping. The authors also discuss limitations, such as the remaining need for human verification in dataset construction and the focus on a single zoom tool, suggesting future work on fully automated data pipelines and multi‑tool extensions (e.g., semantic segmentation, bounding‑box annotation).
Overall, GeoEyes presents a compelling solution for on‑demand visual focusing in ultra‑high‑resolution imagery, bridging the gap between global reasoning and fine‑grained evidence acquisition, and setting a new baseline for remote‑sensing VQA and related high‑resolution visual AI tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment