Batch Prompting Suppresses Overthinking Reasoning Under Constraint: How Batch Prompting Suppresses Overthinking in Reasoning Models
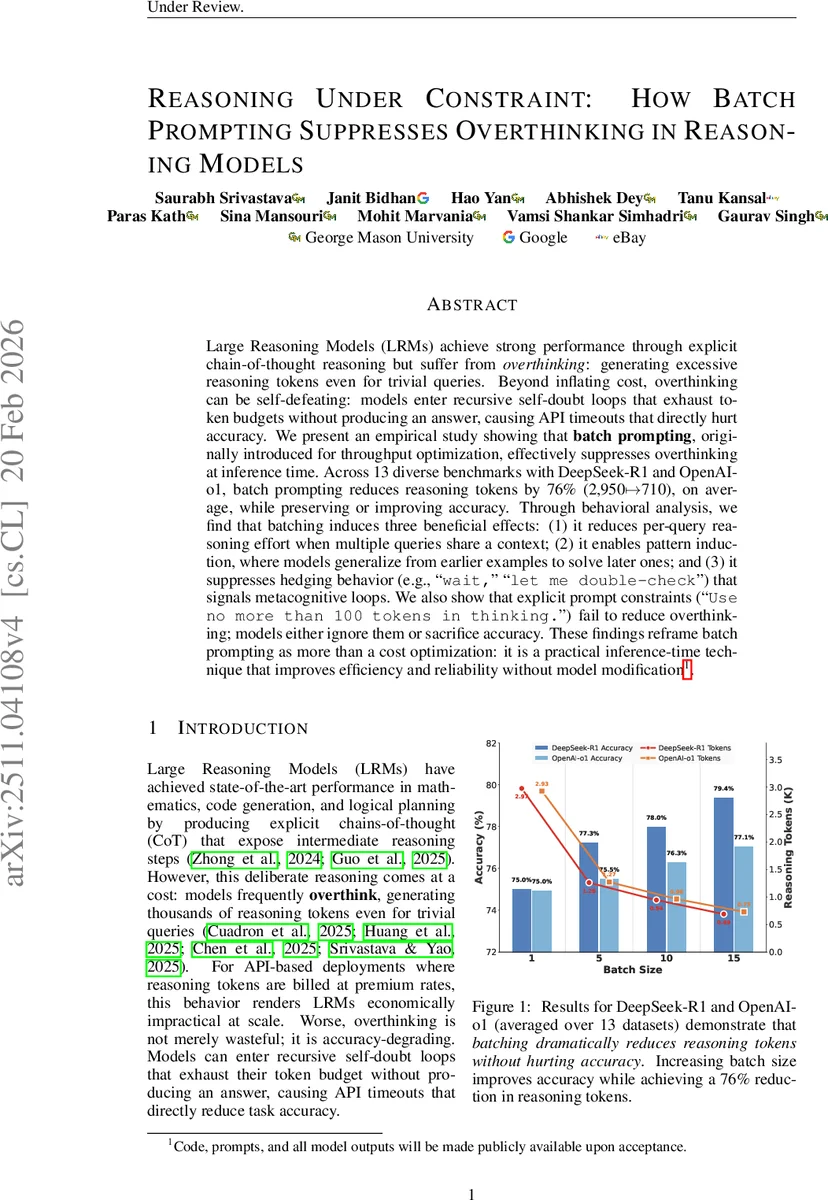
Large Reasoning Models (LRMs) achieve strong performance through explicit chain-of-thought reasoning but suffer from \textit{overthinking}: generating excessive reasoning tokens even for trivial queries. {Beyond inflating cost, overthinking can be self-defeating: models enter recursive self-doubt loops that exhaust token budgets without producing an answer, causing API timeouts that directly hurt accuracy.} We present an empirical study showing that \textbf{batch prompting}, originally introduced for throughput optimization, effectively suppresses overthinking at inference time. Across 13 diverse benchmarks with DeepSeek-R1 and OpenAI-o1, batch prompting {reduces reasoning tokens by 76% (2{,}950$\mapsto$710), on average, while preserving or improving accuracy}. Through behavioral analysis, we find that batching induces three beneficial effects: (1) it reduces per-query reasoning effort when multiple queries share a context; (2) it enables pattern induction, where models generalize from earlier examples to solve later ones; and (3) it suppresses hedging behavior (e.g., \texttt{wait,}'' \texttt{let me double-check}’’) that signals metacognitive loops. We also show that explicit prompt constraints (``\texttt{Use no more than 100 tokens in thinking.}’’) fail to reduce overthinking; models either ignore them or sacrifice accuracy. These findings reframe batch prompting as more than a cost optimization: it is a practical inference-time technique that improves efficiency and reliability without model modification.
💡 Research Summary
Large Reasoning Models (LRMs) such as DeepSeek‑R1 and OpenAI‑o1 have achieved state‑of‑the‑art performance on tasks that require multi‑step reasoning by explicitly generating chain‑of‑thought (CoT) traces. However, a growing body of work has identified a systematic inefficiency: even on trivial inputs, these models often produce excessively long reasoning sequences, a phenomenon termed “overthinking.” Overthinking inflates token costs and, more critically, can cause the model to enter recursive self‑doubt loops that exhaust the allocated token budget, leading to API timeouts and a direct drop in task accuracy. Prior mitigation strategies rely on internal model access—early‑stopping training, activation steering, or reinforcement‑learning fine‑tuning—making them unsuitable for closed‑weight APIs.
This paper investigates whether a purely inference‑time technique, batch prompting, can curb overthinking without any model modification. Batch prompting groups multiple queries into a single prompt, originally introduced to amortize prompt overhead and improve throughput. The authors hypothesize that the shared context creates an implicit regularizer that forces the model to allocate fewer reasoning tokens per query, analogous to human behavior under multitasking pressure.
Experimental Setup
- Models: DeepSeek‑R1 (deepseek‑reasoner) and OpenAI‑o1 (o1‑2024‑12‑17).
- Benchmarks: 13 diverse datasets covering arithmetic (GSM8K, Math500, Game‑of‑24), factual and epistemic QA (GPQA, SciTab, Epistemic, StrategyQA), structured extraction (Event Extraction, Object Count, Last Letter Concatenation), and challenging scientific tasks (IIT‑JEE, BBEH).
- Samples: 100 examples per dataset, following standard LLM evaluation practice.
- Batch Sizes: 1 (single‑query baseline), 5, 10, and 15.
- Metrics: Exact‑match or task‑specific accuracy, model‑reported reasoning token count (T_r), and output token count (T_o).
Key Findings
- Token Reduction: Increasing batch size from 1 to 15 cuts average reasoning tokens from 2,950 to 710—a 76 % reduction—while the fixed prompt overhead is amortized across queries.
- Accuracy Preservation or Improvement: Across both models, accuracy is either maintained or modestly improved (up to +3 % points) as batch size grows. The most pronounced gains appear on harder arithmetic and scientific QA tasks.
- Hedging Suppression: Phrases indicating metacognitive hesitation (“wait, let me double‑check”) drop from 21 occurrences in the single‑query setting to just 1 in the batch‑15 setting, suggesting that batch prompting curtails self‑doubt loops that often lead to timeouts.
- Explicit Token Constraints Fail: Adding a direct instruction such as “Use no more than 100 tokens in thinking.” does not reliably limit reasoning length; models either ignore the instruction or sacrifice accuracy dramatically.
Behavioral Analysis and Hypotheses
The authors propose three non‑exclusive mechanisms explaining why batching reduces overthinking:
- Shared‑Context Pressure: When multiple queries share a single context window, the model faces an implicit budget constraint, prompting it to generate shorter reasoning per query.
- Sequential Anchoring: The model processes batched queries sequentially; a concise style adopted for early queries biases later responses toward brevity.
- Implicit Difficulty Calibration: The presence of several queries signals that exhaustive reasoning is unnecessary for any single item, leading the model to allocate more tokens to genuinely difficult queries while compressing easy ones. Empirical data show adaptive token allocation—harder items still receive sufficient reasoning depth, preserving overall performance.
Comparative Evaluation
The study contrasts batch prompting with prior internal‑modification approaches, highlighting that batch prompting works out‑of‑the‑box with closed‑API models. Moreover, the technique simultaneously addresses cost, reliability, and accuracy, making it a practical solution for production deployments where token pricing and latency are critical concerns.
Limitations and Future Work
- All batches were constructed from semantically homogeneous queries; the effect of heterogeneous batches on overthinking remains unexplored.
- The optimal trade‑off between batch size, latency, and token limits warrants systematic investigation.
- Integrating batch prompting into real‑time serving pipelines and studying its interaction with request‑level QoS constraints is an open engineering challenge.
Conclusion
Batch prompting, originally a throughput‑optimization trick, emerges as a powerful inference‑time regularizer that suppresses overthinking in large reasoning models. By reducing reasoning token consumption by roughly four‑fold while maintaining or even boosting accuracy, it offers an immediate, model‑agnostic remedy for the cost and reliability issues that plague current LRM deployments. The findings encourage practitioners to adopt batch prompting as a default inference strategy, especially when working with closed‑weight APIs where internal model adjustments are infeasible.
Comments & Academic Discussion
Loading comments...
Leave a Comment