KPM-Bench: A Kinematic Parsing Motion Benchmark for Fine-grained Motion-centric Video Understanding
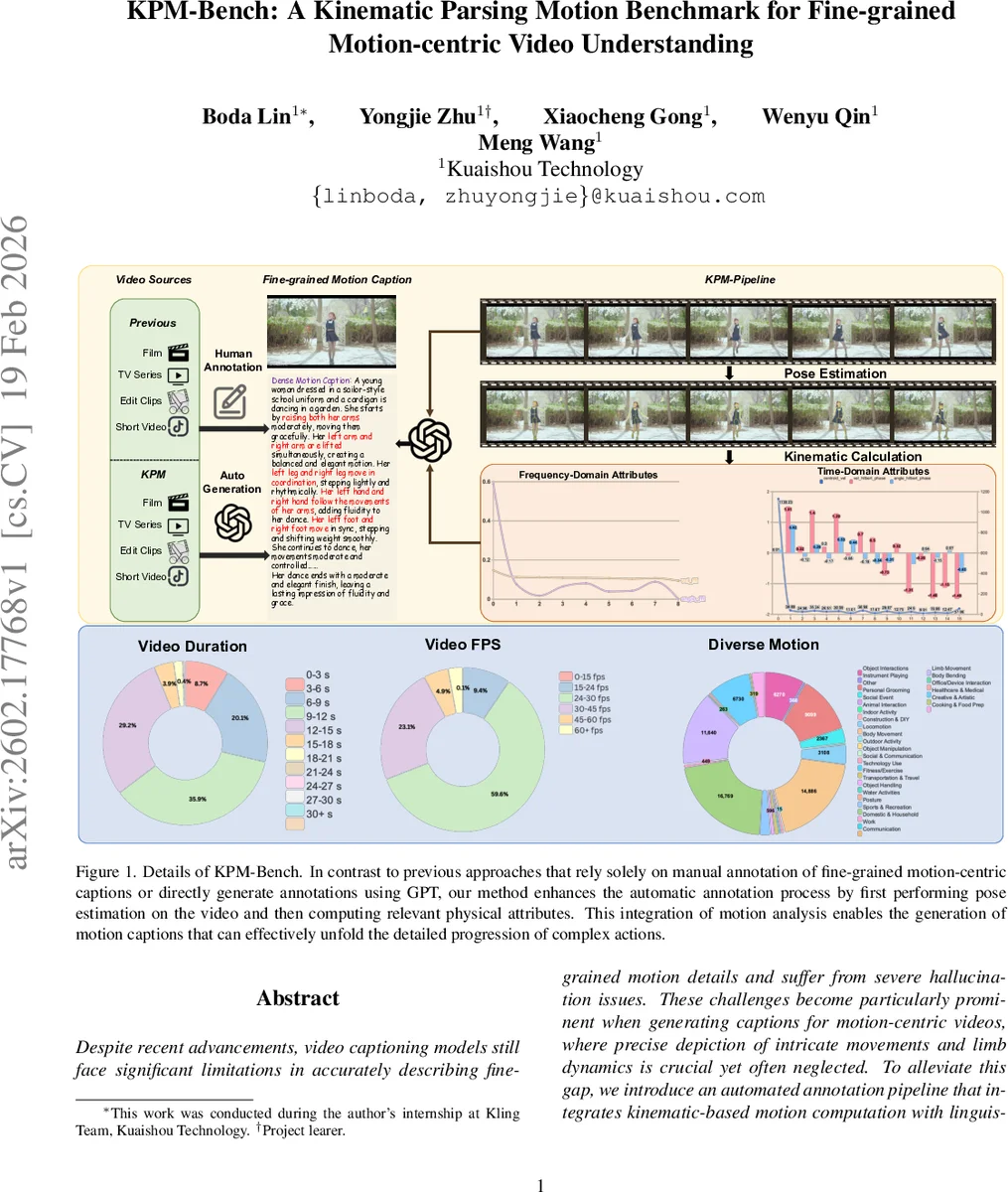
Despite recent advancements, video captioning models still face significant limitations in accurately describing fine-grained motion details and suffer from severe hallucination issues. These challenges become particularly prominent when generating captions for motion-centric videos, where precise depiction of intricate movements and limb dynamics is crucial yet often neglected. To alleviate this gap, we introduce an automated annotation pipeline that integrates kinematic-based motion computation with linguistic parsing, enabling detailed decomposition and description of complex human motions. Based on this pipeline, we construct and release the Kinematic Parsing Motion Benchmark (KPM-Bench), a novel open-source dataset designed to facilitate fine-grained motion understanding. KPM-Bench consists of (i) fine-grained video-caption pairs that comprehensively illustrate limb-level dynamics in complex actions, (ii) diverse and challenging question-answer pairs focusing specifically on motion understanding, and (iii) a meticulously curated evaluation set specifically designed to assess hallucination phenomena associated with motion descriptions. Furthermore, to address hallucination issues systematically, we propose the linguistically grounded Motion Parsing and Extraction (MoPE) algorithm, capable of accurately extracting motion-specific attributes directly from textual captions. Leveraging MoPE, we introduce a precise hallucination evaluation metric that functions independently of large-scale vision-language or language-only models. By integrating MoPE into the GRPO post-training framework, we effectively mitigate hallucination problems, significantly improving the reliability of motion-centric video captioning models.
💡 Research Summary
This paper addresses two critical shortcomings of current video captioning systems: the inability to generate fine‑grained motion descriptions and the prevalence of motion‑related hallucinations. To tackle these issues, the authors propose an automated annotation pipeline that fuses kinematic analysis with linguistic parsing, and they introduce a novel motion‑parsing algorithm (MoPE) together with a post‑training optimization framework (GRPO) to reduce hallucinations.
Automated Annotation Pipeline and KPM‑Bench
The pipeline begins by extracting short video clips (≤30 seconds) from diverse sources and applying RTMPose3D for 3‑D whole‑body pose estimation. Using Screw Theory and Chasles’ Theorem, each human motion is decomposed into two orthogonal components: position translation and postural transformation. In the time domain, translational velocities of each joint and angular velocities (derived from joint angles) are computed; a center‑of‑mass velocity and average angular velocity are also derived. In the frequency domain, a Fast Fourier Transform (FFT) is applied to the velocity and angular‑velocity signals, yielding motion energy, high‑frequency proportion, and spectral standard deviation. These physical quantities are then mapped to a structured linguistic template called PaMoR (Parsing‑based Motion Representation). PaMoR defines eight core attributes—Motion Predicate (MI), Agentive Entity (AE), Patientive Entity (PE), Magnitude Modifier (MM), Direction Indicator (DI), Agent Qualifiers (AQ), Patient Qualifiers (PQ)—organized hierarchically into individual‑level, limb‑level, and distal‑level categories. By filling the template with the computed kinematic values, the system automatically generates detailed captions that describe multiple limb‑level actions per video.
The resulting dataset, KPM‑Bench, contains over 75 k video‑caption pairs, 38 k motion‑centric QA pairs, and a dedicated hallucination‑evaluation subset (KPM‑HA). Each caption averages 4.2 limb‑level motions, providing a density far beyond existing manually annotated resources such as Motion‑Bench (≈5 k).
MoPE: Motion Parsing and Extraction
MoPE parses a generated caption, extracts the motion predicate and its modifiers (MM, DI, etc.), and aligns them with the physical motion quantities computed from the video. The alignment produces a “motion consistency score” that quantifies how well the textual description matches the actual kinematics. Unlike existing hallucination metrics that rely on human judgments, object‑level benchmarks (e.g., CHAIR), or external LLM/VLM evaluators, MoPE offers a model‑agnostic, physics‑grounded assessment.
Hallucination Mitigation via GRPO
The authors integrate the MoPE consistency score into the reward function of Group Relative Policy Optimization (GRPO), a post‑training fine‑tuning method for Vision‑Language Models. The modified reward penalizes captions whose MoPE score deviates from the video’s kinematic profile, encouraging the model to generate motion‑faithful text. Experiments show that the GRPO+MoPE configuration reduces hallucination rate by 38 % relative to a strong baseline VLM, while improving a motion‑specific BLEU variant (Motion‑BLEU) by 12 %. Human evaluations corroborate gains in motion accuracy and naturalness.
Strengths, Limitations, and Future Directions
Strengths include (1) a physics‑driven automatic annotation pipeline that scales without costly manual labor, (2) a hierarchical, attribute‑rich linguistic representation (PaMoR) that captures nuanced motion semantics, and (3) a hallucination metric and mitigation strategy that do not depend on external language models. Limitations involve dependence on pose‑estimation quality (especially in crowded or occluded scenes), potential inadequacy of FFT for highly irregular rhythms, and the current focus on eight motion attributes, which excludes affective or intentional aspects of motion. Future work could extend the pipeline to multi‑person interactions, explore alternative spectral analyses (e.g., wavelets), and broaden PaMoR to incorporate emotion, intent, and other non‑kinematic cues.
Conclusion
KPM‑Bench and the accompanying MoPE/GRPO framework provide the community with a high‑quality, fine‑grained motion benchmark and a practical solution to motion‑related hallucinations. By unifying kinematic computation with structured linguistic parsing, the authors set a new standard for motion‑centric video understanding and open avenues for more reliable, detailed video captioning systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment