Sink-Aware Pruning for Diffusion Language Models
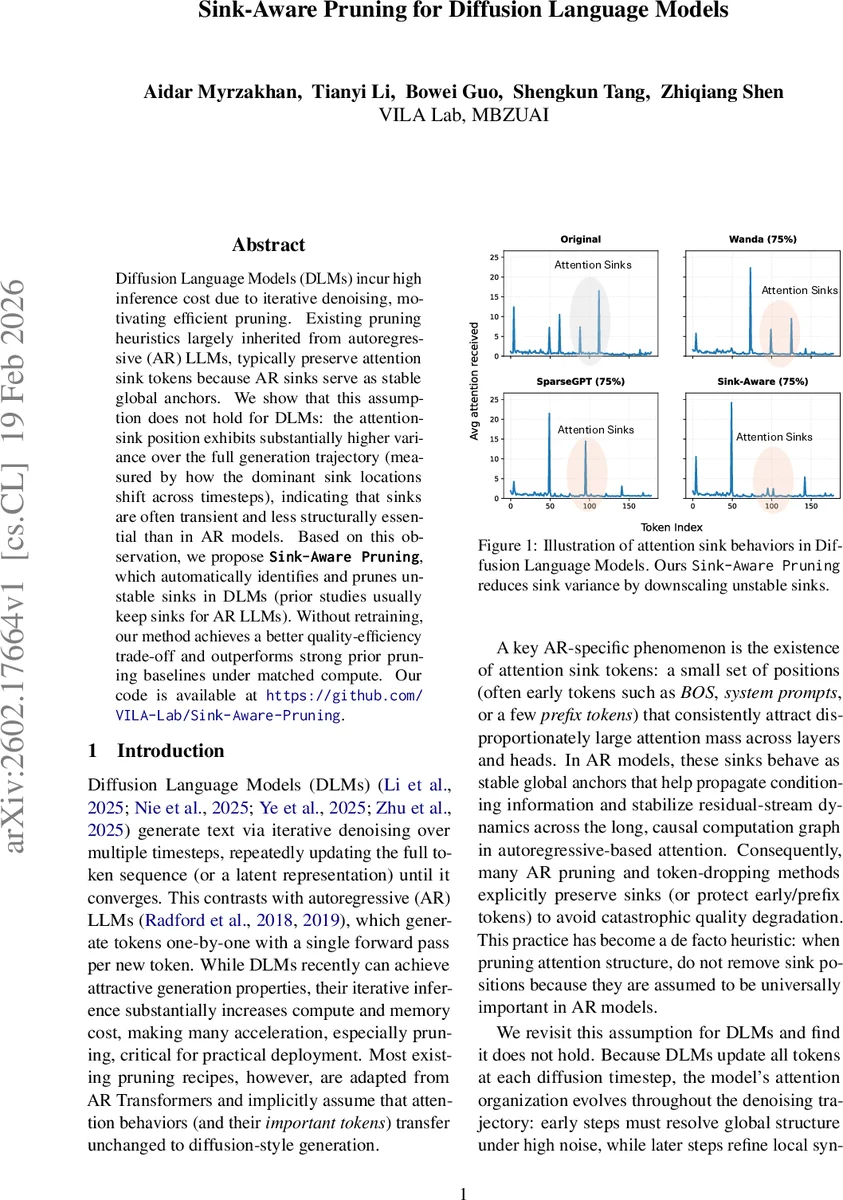
Diffusion Language Models (DLMs) incur high inference cost due to iterative denoising, motivating efficient pruning. Existing pruning heuristics largely inherited from autoregressive (AR) LLMs, typically preserve attention sink tokens because AR sinks serve as stable global anchors. We show that this assumption does not hold for DLMs: the attention-sink position exhibits substantially higher variance over the full generation trajectory (measured by how the dominant sink locations shift across timesteps), indicating that sinks are often transient and less structurally essential than in AR models. Based on this observation, we propose ${\bf \texttt{Sink-Aware Pruning}}$, which automatically identifies and prunes unstable sinks in DLMs (prior studies usually keep sinks for AR LLMs). Without retraining, our method achieves a better quality-efficiency trade-off and outperforms strong prior pruning baselines under matched compute. Our code is available at https://github.com/VILA-Lab/Sink-Aware-Pruning.
💡 Research Summary
Diffusion Language Models (DLMs) generate text by repeatedly denoising a noisy sequence, updating the entire token list at each diffusion timestep. While this non‑autoregressive paradigm enables parallel generation and strong generation quality, it also incurs a large inference cost because attention must be recomputed for the full sequence at every step. Existing pruning methods for large language models are largely borrowed from autoregressive (AR) transformers, where a well‑known phenomenon called “attention sinks” – a small set of early tokens (e.g., BOS, system prompts) that attract a disproportionate amount of attention across many layers and heads – is treated as a stable global anchor. Consequently, most AR‑centric pruning recipes explicitly preserve these sink positions to avoid catastrophic quality loss.
The authors of this paper argue that the “keep‑sinks” heuristic does not transfer to DLMs. They first quantify sink behavior by measuring, at each generation step t, the incoming attention mass mₜ(i)=∑ⱼAₜⱼ,i for every token i, where Aₜ is the attention matrix. Two variance statistics are introduced: (1) spatial variance σ²_spatial = Var_i( \bar{m}(i) ) where \bar{m}(i) is the average over all steps, capturing how unevenly attention is distributed overall; (2) temporal variance σ²_temporal = Var_t(cₜ), where cₜ is the attention‑weighted centroid of the current sink set Sₜ. Experiments on AR models (LLaMA‑3, Qwen2.5) show high spatial variance but near‑zero temporal variance – sinks are concentrated on a few early positions and remain fixed throughout generation. In contrast, DLMs (LLaDA, Dream) exhibit low spatial variance but temporal variance orders of magnitude larger, indicating that dominant sinks drift dramatically across diffusion steps. Early timesteps (high noise) focus attention on global structure, causing early tokens to become transient sinks; later timesteps shift attention toward local refinement, and new sink positions emerge.
Based on this observation, the paper proposes Sink‑Aware Pruning, a diffusion‑specific post‑training pruning strategy that automatically identifies and removes unstable sinks. The method proceeds as follows:
- Sink scoring – For each timestep, compute per‑token attention mass across all layers and heads, then derive a soft sink score φₜ(j) using a sigmoid of the deviation from the mean mass (controlled by a sensitivity ε).
- Temporal aggregation – Average φₜ(j) over a set of uniformly sampled timesteps to obtain a final sink score sⱼ for each token.
- Down‑weighting – Define a weight ωⱼ = 1 − sⱼ and multiply the original activation X by ω to produce a sink‑aware activation \tilde{X}.
- Integration with existing metrics – Feed \tilde{X} into established importance estimators such as Wanda (magnitude × input‑norm) or SparseGPT (second‑order reconstruction error). This yields sink‑aware importance scores for each weight.
- Pruning – Apply a standard magnitude‑based or reconstruction‑based mask using the updated scores, achieving the desired sparsity without any fine‑tuning.
The approach is lightweight: it only requires a calibration dataset to collect attention statistics and does not involve gradient computation or retraining. Empirically, the authors evaluate on two large DLMs (LLaDA‑8B and Dream‑7B) and compare against strong baselines (Wanda, SparseGPT) under matched compute budgets. At sparsity levels ranging from 70 % to 90 %, Sink‑Aware Pruning consistently yields lower perplexity and higher BLEU scores than the baselines, sometimes improving by 5–10 % relative. Importantly, when the same technique is applied to AR models, preserving sinks remains the optimal choice, confirming that the proposed method adapts to the generation paradigm rather than imposing a one‑size‑fits‑all rule.
The paper’s contributions are threefold:
- Introduction of quantitative sink‑variance metrics that reveal a fundamental difference between AR and diffusion generation dynamics.
- A novel pruning pipeline that leverages these metrics to down‑weight unstable sink positions, enabling more aggressive sparsification of DLMs without quality loss.
- Open‑source release of code and calibration pipelines, facilitating reproducibility and future extensions.
The authors discuss several avenues for future work, including combining sink‑aware pruning with quantization or knowledge distillation, dynamically adjusting diffusion schedules to reduce sink drift, and evaluating latency‑memory trade‑offs in real‑time applications such as chat assistants. Overall, the paper convincingly demonstrates that attention sinks are not universally “must‑keep” tokens; their importance is generation‑paradigm dependent, and exploiting this insight yields a principled and effective route to accelerate diffusion language models.
Comments & Academic Discussion
Loading comments...
Leave a Comment