When to Trust the Cheap Check: Weak and Strong Verification for Reasoning
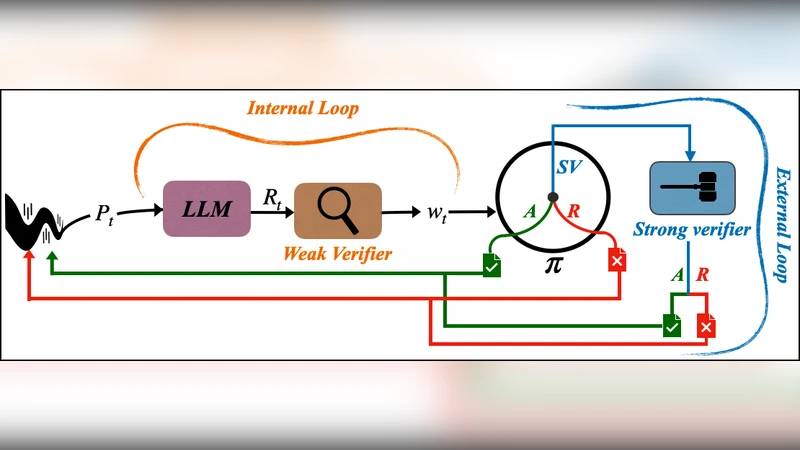
Reasoning with LLMs increasingly unfolds inside a broader verification loop. Internally, systems use cheap checks, such as self-consistency or proxy rewards, which we call weak verification. Externally, users inspect outputs and steer the model through feedback until results are trustworthy, which we call strong verification. These signals differ sharply in cost and reliability: strong verification can establish trust but is resource-intensive, while weak verification is fast and scalable but noisy and imperfect. We formalize this tension through weak–strong verification policies, which decide when to accept or reject based on weak verification and when to defer to strong verification. We introduce metrics capturing incorrect acceptance, incorrect rejection, and strong-verification frequency. Over population, we show that optimal policies admit a two-threshold structure and that calibration and sharpness govern the value of weak verifiers. Building on this, we develop an online algorithm that provably controls acceptance and rejection errors without assumptions on the query stream, the language model, or the weak verifier.
💡 Research Summary
The paper formalizes the verification loop that surrounds large‑language‑model (LLM) reasoning, distinguishing between inexpensive “weak verification” (e.g., self‑consistency, proxy rewards) and costly “strong verification” performed by users or external feedback. Weak verification is fast and scalable but noisy; strong verification is reliable but resource‑intensive. To manage the trade‑off, the authors introduce a policy that, given a weak‑verification score, decides to (1) accept the answer, (2) reject it, or (3) defer to strong verification. They define three performance metrics: incorrect acceptance (accepting a wrong answer based on weak verification), incorrect rejection (rejecting an answer that would be correct under strong verification), and the frequency of invoking strong verification.
Through population‑level analysis they prove that the optimal policy has a two‑threshold structure: a lower threshold τ_low below which the system always rejects, an upper threshold τ_high above which it always accepts, and a middle region where it calls for strong verification. The placement of these thresholds depends on the calibration (how well the weak score matches true correctness probability) and sharpness (the concentration of scores) of the weak verifier. Better calibrated and sharper weak verifiers push τ_low and τ_high apart, reducing the need for costly strong checks.
Crucially, the authors design an online algorithm that updates τ_low and τ_high on the fly, without any assumptions about the query stream, the underlying LLM, or the weak verifier. The algorithm receives user‑specified error budgets (α for false acceptance, β for false rejection) and guarantees that the empirical rates of both error types stay below these budgets while minimizing the strong‑verification frequency. This is achieved by tracking cumulative error statistics and adjusting thresholds adaptively.
Empirical simulations with several LLMs and weak verifiers (self‑consistency, label‑model scores, proxy rewards) demonstrate that the two‑threshold policy and the online algorithm dramatically cut the number of strong verifications compared with naïve baselines, while keeping both error rates within the prescribed limits. The experiments also show that improvements in weak‑verifier calibration directly translate into fewer strong‑verification calls.
In summary, the work provides a rigorous theoretical framework for balancing cost and reliability in LLM reasoning pipelines, identifies calibration and sharpness as key determinants of weak‑verifier value, and supplies a practical, assumption‑free online method for controlling verification errors. This enables system designers to explicitly trade off cheap, noisy checks against expensive, trustworthy ones, and opens avenues for future research on multi‑stage verification, personalized error tolerances, and learning‑based calibration of weak verifiers.
Comments & Academic Discussion
Loading comments...
Leave a Comment