genriesz: A Python Package for Automatic Debiased Machine Learning with Generalized Riesz Regression
Efficient estimation of causal and structural parameters can be automated using the Riesz representation theorem and debiased machine learning (DML). We present genriesz, an open-source Python package that implements automatic DML and generalized Rie…
Authors: Masahiro Kato
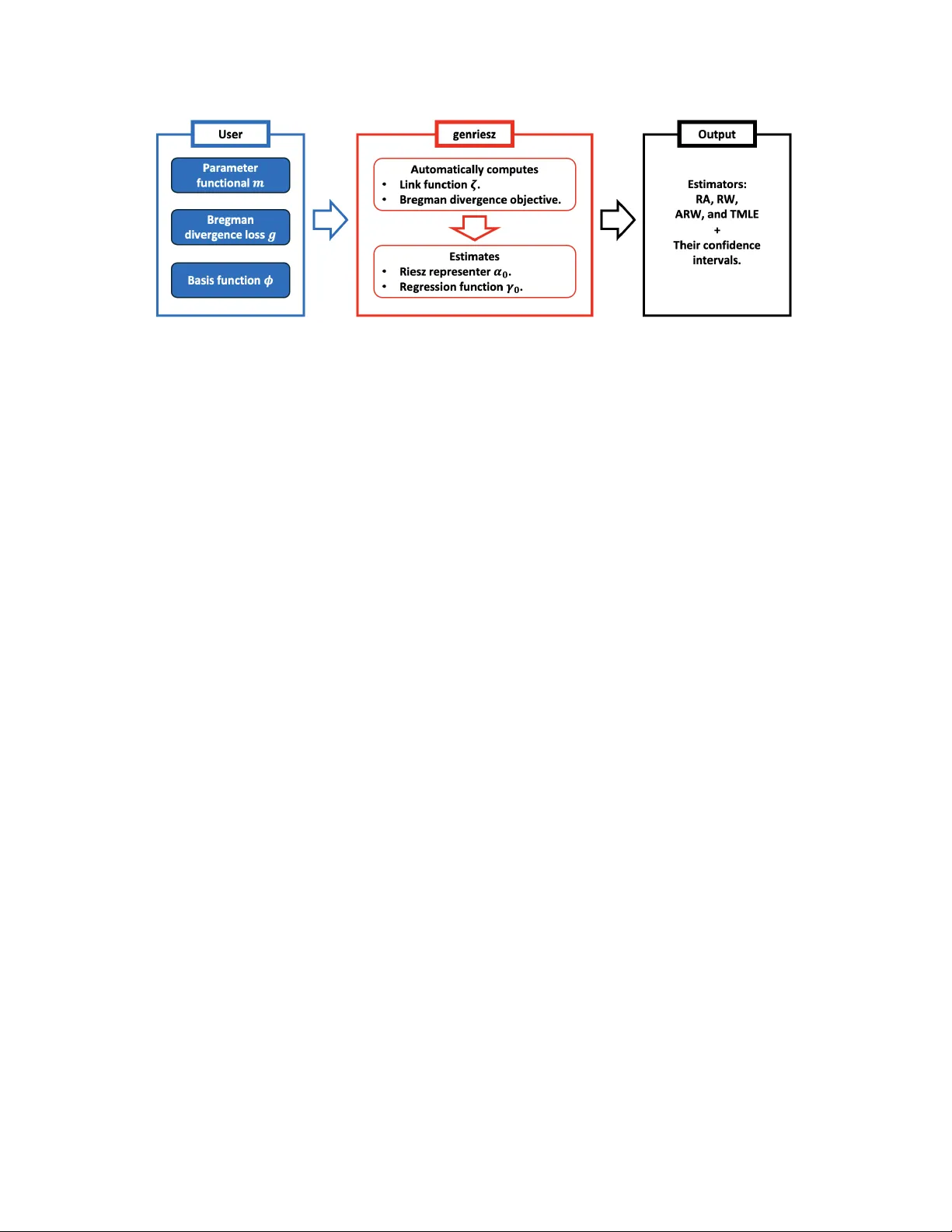
genriesz : A Python P ac k age for Automatic Debiased Mac hine Learning with Generalized Riesz Regression Masahiro Kato ∗ Data Analytics Departmen t, Mizuho-DL Financial T ec hnology , Co., Ltd. F ebruary 20, 2026 Abstract Efficien t estimation of causal and structural parameters can b e automated using the Riesz represen tation theorem and debiased machine learning (DML). W e present genriesz , an op en-source Python pack age that implemen ts automatic DML and gen- er alize d R iesz r e gr ession , a unified framework for estimating Riesz representers b y minimizing empirical Bregman div ergences. This framework includes co v ariate balanc- ing, nearest-neigh b or matching, calibrated estimation, and density ratio estimation as sp ecial cases. A k ey design principle of the pack age is automatic r e gr essor b alanc- ing (ARB): given a Bregman generator g and a representer mo del class, genriesz automatically constructs a compatible link function so that the generalized Riesz re- gression estimator satisfies balancing (momen t-matching) optimalit y conditions in a user-c hosen basis. The pac k age pro vides a mo dular interface for specifying (i) the target linear functional via a blac k-b o x ev aluation oracle, (ii) the represen ter mo del via basis functions (polynomial, RKHS appro ximations, random forest leaf enco dings, neural em b eddings, and a nearest-neigh b or catchmen t basis), and (iii) the Bregman generator, with optional user-supplied deriv ativ es. It returns regression adjustment (RA), Riesz w eighting (R W), augmen ted Riesz w eighting (AR W), and TMLE-style estimators with cross-fitting, confidence interv als, and p -v alues. W e highlight represen tative w orkflows for estimation problems such as the a verage treatmen t effect (A TE), A TE on treated (A TT), and av erage marginal effect estimation. The Python pack age is a v ailable at https://github.com/MasaKat0/genriesz and on PyPI. 1 In tro duction Man y targets in causal inference and econometrics can b e expressed as linear functionals of an unkno wn regression function. Prominent examples include the a v erage treatmen t effect (A TE), the av erage treatment effect on the treated (A TT), and a verage marginal effects (AME). ∗ Email: mkato-csecon@g.ecc.u-tokyo.ac.jp 1 Automatic debiased machine learning (ADML) pro vides general tools for v alid inference on suc h targets ( Chernozh uko v et al. , 2022b ). The ADML w orkflow separates the problem in to t wo parts. First, one estimates n uisance comp onen ts, t ypically a regression function and a Riesz representer. Second, one plugs these estimates in to a Neyman orthogonal score and a verages the resulting score o v er the sample. A Donsk er condition or cross-fitting then yields v alid inference under w eak rate conditions ( Chernozh uko v et al. , 2018 ; Klaassen , 1987 ). V arious metho ds ha ve been prop osed for Riesz representer estimation, suc h as Riesz regres- sion ( Chernozh uko v et al. , 2021 ; Chen & Liao , 2015 ), co v ariate balancing ( Imai & Ratko vic , 2013 ), and density ratio estimation ( Sugiyama et al. , 2012 ). Kato ( 2026 , 2025a ) demonstrates a unifying p erspective, Riesz r epr esenter fitting under Br e gman diver genc es , which is also referred to as generalized Riesz regression, Bregman-Riesz regression, or generalized co v ariate balancing. Hereafter, w e refer to this metho d as generalized Riesz regression, a name that emphasizes the connection b etw een Riesz representer fitting and balancing w eigh ts through the c hoice of link function. In this framew ork, one can reco ver the v arious metho ds listed ab o v e by sp ecifying particular forms of the Bregman div ergence. Our genriesz pac k age implemen ts generalized Riesz regression for ADML. Users sp ecify the estimand through an ev aluation oracle and choose a Riesz representer mo del and a Bregman generator. The pac k age then constructs a generator-induced link function to deliv er automatic regressor balancing, estimates the representer b y con vex optimization with ℓ p regularization, and rep orts regression adjustmen t (RA), Riesz w eighting (R W), augmen ted Riesz w eighting (AR W), and targeted maxim um likelihoo d estimation (TMLE)-st yle estimates with confidence in terv als, optionally using cross-fitting ( Bang & Robins , 2005 ; v an der Laan , 2006 ). The flo wc hart of this automatic procedure is below, where each ob ject will b e defined in the subsequen t sections (Figure 1 ): (i) the user sp ecifies the parameter functional m ( W , γ 0 ) for the parameter of in terest θ 0 : = E [ m ( W , γ 0 )] , the Bregman generator g for Riesz represen ter estimation, and the basis functions ϕ ( X ). (ii) the pack age automatically computes the link function ζ X , ϕ ( X ) ⊤ β that yields regres- sor balancing, and estimates the Riesz representer α 0 and, when needed, the regression function γ 0 . (iii) the pac k age outputs RA, R W, AR W, and TMLE-style estimators with standard errors and confidence interv als. During this process, the user do es not need to specify the analytic form of the Riesz represen ter α 0 or the link function ζ . These are constructed from the chosen basis and generator. Relation to existing softw are. The genriesz pac k age complemen ts established DML libraries suc h as DoubleML ( Bac h et al. , 2022 ) and EconML ( Batto cchi et al. , 2019 ), as w ell as broader causal inference to olkits such as DoWh y ( Sharma & Kiciman , 2020 ) and CausalML ( Chen et al. , 2020 ). These libraries offer ric h sets of estimators for canonical causal models and heterogeneous treatmen t effects. In con trast, genriesz is estimand-and-b alancing-c entric : 2 Figure 1: Flow c hart of genriesz . the user provides the functional m , the represen ter mo del, and the specific form of the Bregman div ergence, while the pac k age constructs generalized Riesz representers with a link function that yields balancing w eigh ts and returns the corresponding estimators. This fo cus also mak es explicit the connection betw een Riesz representer fitting and balancing weigh ts, including stable weigh ts ( Zubizarreta , 2015 ) and entrop y balancing ( Hainm ueller , 2012 ), as w ell as density ratio estimation metho ds av ailable in sp ecialized pac k ages suc h as densratio ( Makiy ama , 2019 ). 2 Key Ingredien ts of Generalized Riesz Regression Generalized Riesz regression connects Riesz represen ter estimation, co v ariate balancing, and debiased estimation through Bregman divergence minimization. This section summarizes the metho dological and theoretical foundations that underlie the soft w are design. F ull technical details, proofs, and extensions are provided in Kato ( 2026 ). 2.1 Linear F unctionals, Riesz Representers, and Orthogonal Scores Let W : = ( X , Y ) ∼ P , where X ∈ R d is a regressor and Y ∈ R is an outcome. Let γ 0 ( x ) : = E [ Y | X = x ]. W e consider targets of the form θ 0 : = E [ m ( W , γ 0 )] , (1) where m ( W , γ ) is linear in γ . In genriesz , users supply m as a callable that ev aluates γ at mo dified inputs, for example, b y switching a treatmen t comp onent. Under standard conditions, there exists a Riesz representer α 0 suc h that E [ m ( W , γ )] = E [ α 0 ( X ) γ ( X )] for all suitable γ . (2) The Riesz representer en ters the Neyman orthogonal score ψ ( W ; θ , γ , α ) : = m ( W , γ ) + α ( X ) ( Y − γ ( X )) − θ , (3) whic h plays a cen tral role in debiased estimation and v alid inference under weak conditions, with cross-fitting ( Chernozhuk ov et al. , 2018 ). 3 T able 1: Corresp ondence among Bregman div ergence losses, density ratio (DR) estimation metho ds, and Riesz represen ter (RR) estimation. RR estimation for A TE includes prop ensit y score estimation and cov ariate balancing weigh ts. In the table, C ∈ R denotes a constant that is determined b y the problem and the loss function. The pac k age also supports user-defined generators. g ( α ) DR estimation RR estimation ( α − C ) 2 LSIF SQ-Riesz regression ( Kanamori et al. , 2009 ) ( genriesz ) KuLSIF Riesz regression (RieszNet and F orestRiesz) ( Kanamori et al. , 2012 ) ( Chernozhuk ov et al. , 2021 , 2022a ) Hyv¨ arinen score matc hing RieszBo ost ( Hyv¨ arinen , 2005 ) ( Lee & Sc huler , 2025 ) KRRR ( Singh , 2024 ) Nearest neigh bor matching ( Lin et al. , 2023 ) Causal forest and generalized random forest ( W ager & Athey , 2018 ; Athey et al. , 2019 ) Dual solution with a linear link function Kernel mean matc hing Sieve Riesz representer ( Gretton et al. , 2009 ) ( Chen & Liao , 2015 ; Chen & Pouzo , 2015 ) Stable balancing w eights ( Zubizarreta , 2015 ; Bruns-Smith et al. , 2025 ) Approximate residual balancing ( Athey et al. , 2018 ) Cov ariate balancing by SVM ( T arr & Imai , 2025 ) Distributional balancing ( Santra et al. , 2026 ) ( | α | − C ) log ( | α | − C ) − | α | UKL div ergence minimization UKL-Riesz regression ( Nguyen et al. , 2010 ) ( genriesz ) T ailored loss minimization ( α = β = − 1) ( Zhao , 2019 ) Calibrated estimation ( T an , 2019 ) Dual solution with a logistic or log link function KLIEP Entrop y balancing weigh ts ( Sugiyama et al. , 2008 ) ( Hainmueller , 2012 ) ( | α | − C ) log ( | α | − C ) − ( | α | + C ) log ( | α | + C ) BKL div ergence minimization BKL-Riesz regression ( Qin , 1998 ) ( genriesz ) TRE MLE of the prop ensity score ( Rhodes et al. , 2020 ) (Standard approac h) T ailored loss minimization ( α = β = 0) ( Zhao , 2019 ) ( | α |− C ) 1+ ω − ( | α |− C ) ω − ( | α | − C ) BP div ergence minimization BP-Riesz regression for some ω ∈ (0 , ∞ ) ( Sugiyama et al. , 2011 ) ( genriesz ) C log (1 − α ) + C α (log ( α ) − log (1 − α )) PU learning PU-Riesz regression for α ∈ (0 , 1) ( du Plessis et al. , 2015 ) ( genriesz ) Nonnegative PU learning ( Kiryo et al. , 2017 ) General form ulation b y Bregman Density-ratio matching Generalized Riesz regression divergence minimization ( Sugiyama et al. , 2011 ) ( genriesz ) D3RE ( Kato & T eshima , 2021 ) 2.2 Bregman-Riesz Ob jectiv es Let g ( x, α ) b e con vex in the scalar α for eac h fixed x . The point wise Bregman div ergence is BD g ( α 0 ( x ) ∥ α ( x )) : = g ( x, α 0 ( x )) − g ( x, α ( x )) − ∂ α g ( x, α ( x )) ( α 0 ( x ) − α ( x )) . (4) 4 Generalized Riesz regression estimates α 0 b y minimizing an empirical Bregman-Riesz ob jectiv e of the form b L ( α ) : = 1 n n X i =1 − g ( X i , α ( X i )) + ∂ α g ( X i , α ( X i )) α ( X i ) − m ( W i , ∂ α g ( · , α ( · ))) + λ Ω ( α ) , (5) where Ω is a regularizer, for example an ℓ p p enalt y on a coefficient vector. Squared-loss gener- ators reco ver Riesz regression (primal, Chernozhuk o v et al. , 2021 ) and series Riesz representer (dual, Chen & Liao , 2015 ), while KL-t yp e generators reco ver tailored-loss, calibrated estima- tion form ulations (primal, Zhao , 2019 ; T an , 2019 ) and en tropy balancing (dual, Hainmueller , 2012 ). The pac k age pro vides built-in generators, squared distance (SQ), unnormalized KL (UKL) div ergence, binary KL (BKL) divergence, Basu’s p ow er (BP) div ergence, and PU families, and it also supp orts user-defined generators. Dual co ordinate and conjugate ob jective. A key iden tit y b ehind the implemen tation is the conjugacy relation g ∗ ( x, v ) : = sup α ∈A ( x ) { αv − g ( x, α ) } , α ∗ ( x, v ) : = arg max α ∈A ( x ) { αv − g ( x, α ) } , (6) where A ( x ) is the domain of α giv en x . F or differen tiable generators, α ∗ ( x, v ) = ( ∂ α g ) − 1 ( x, v ) . Using v ( x ) : = ∂ α g ( x, α ( x )) and g ∗ ( x, v ( x )) = α ( x ) v ( x ) − g ( x, α ( x )) , the ob jectiv e ( 5 ) is equiv alent, up to constan ts, to b L ∗ ( v ) : = 1 n n X i =1 g ∗ ( X i , v ( X i )) − m ( W i , v ) + λ Ω ∗ ( v ) . (7) This dual view is con venien t for optimization and for deriving the balancing optimalit y conditions. 2.3 Automatic Regressor Balancing via Generator-Induced Links T o fit α 0 in a mo del class, genriesz fo cuses on GLM-st yle parameterizations α β ( x ) = ζ − 1 ( x, f β ( x )) , f β ( x ) = ϕ ( x ) ⊤ β , (8) where ϕ is a user-c hosen basis and ζ is a link. A key choice is to set the link to the deriv ative of the generator, ζ ( x, α ) = ∂ α g ( x, α ) , ζ − 1 ( x, · ) = ( ∂ α g ( x, · )) − 1 , (9) so that the dual coordinate v ( x ) = ∂ α g ( x, α ( x )) is linear in β . This is the pac k age’s notion of ARB. In genriesz , the mo del is estimated b y solving a conv ex program in β : b β : = arg min β ∈ R p ( 1 n n X i =1 g ∗ ( X i , f β ( X i )) − m ( W i , f β ) + λ Ω ( β ) ) . (10) After estimating b β , the fitted Riesz representer is b α ( x ) = ζ − 1 x, f b β ( x ) . 5 Prop osition 2.1 (ARB implies balancing optimalit y conditions) . Consider the mo del ( 8 )–( 9 ). Fix q ∈ [1 , ∞ ] and set Ω( β ) = 1 q ∥ β ∥ q q . L et b β b e any empiric al minimizer of ( 10 ) and define b α ( x ) = α b β ( x ) . Under mild r e gularity c onditions, the KKT c onditions imply that ther e exist sc alars s 1 , . . . , s p such that 1 n n X i =1 b α ( X i ) ϕ j ( X i ) − m ( W i , ϕ j ) + λs j = 0 , s j ∈ ∂ 1 q | β j | q | β j = b β j , j = 1 , . . . , p. (11) Conse quently, the implie d b alancing c ondition takes the fol lowing explicit form: • If q = 1 , then | s j | ≤ 1 and henc e 1 n n X i =1 b α ( X i ) ϕ j ( X i ) − m ( W i , ϕ j ) ≤ λ, j = 1 , . . . , p. (12) • If q > 1 , then s j = sign b β j b β j q − 1 and henc e 1 n n X i =1 b α ( X i ) ϕ j ( X i ) − m ( W i , ϕ j ) = λ b β j q − 1 , j = 1 , . . . , p. (13) In p articular, when λ = 0 and the c onstr aints ar e fe asible, ( 11 ) yields exact sample b alancing. Prop osition 2.1 is a soft w are-relev ant consequence of the duality theory in Kato ( 2026 ). ARB ensures that the solv er automatically enforces the correct balancing equations for the user-sp ecified basis, ev en when the primal mo del ( 8 ) is nonlinear in β , for example under KL-t yp e links. Remark (Automatic link construction in genriesz ) . Users c an supply analytic derivatives ∂ α g and ( ∂ α g ) − 1 . If they do not, genriesz appr oximates ∂ α g by finite differ enc es and c omputes ( ∂ α g ) − 1 by r o ot finding. This al lows r apid pr ototyping of new Br e gman gener ators, at the c ost of additional numeric al c ar e, such as domain c onstr aints and br anch sele ction. Remark. ℓ 1 p enalty and sp arsity The ℓ 1 choic e is useful b e c ause ( 12 ) dir e ctly c ontr ols the maximum absolute moment imb alanc e by the single tuning p ar ameter λ . In genriesz , this r ole is primarily ab out fe asibility r elaxation and stability of r epr esenter fitting, r ather than r e c overing a sp arse c o efficient ve ctor. In p articular, using ℓ 1 her e should b e understo o d as imp osing an interpr etable slack on b alancing e quations, not as a sp arsity assumption on the true r epr esenter mo del. 2.4 Sp ecial Cases and Connections to Balancing W eigh ts The ARB construction ( 9 ) mak es explicit ho w generalized Riesz regression reco v ers classical balancing-w eight estimators as dual solutions. Intuitiv ely , the dual v ariable associated with the linear moment conditions corresp onds to p er-sample w eigh ts, and different generators g induce differen t weigh t regularizers. T able 1 summarizes common c hoices implemented in genriesz , see Kato ( 2026 ) for precise statements. 6 Domain constraints and branc h selection. Some generators require constrain ts suc h as | α | > C and α ∈ (0 , 1) . genriesz exp oses a branch fn in terface that selects a v alid branch, for example treated versus control, so that the fitted represen ter resp ects the generator domain b y construction. 2.5 Estimators: RA, R W, AR W, and TMLE Giv en nuisance estimates b γ and b α , optionally cross-fitted, genriesz outputs four plug-in estimators, regression adjustment (RA), Riesz w eighting (R W), augmented Riesz weigh ting (AR W), and targeted maxim um likelihoo d estimation (TMLE)-st yle estimators, defined as follo ws: b θ RA : = 1 n n X i =1 m ( W i , b γ ) , (14) b θ R W : = 1 n n X i =1 b α ( X i ) Y i , (15) b θ AR W : = 1 n n X i =1 b α ( X i ) ( Y i − b γ ( X i )) + m ( W i , b γ ) , (16) b θ TMLE : = 1 n n X i =1 m W i , b γ (1) , (17) In TMLE, b γ (1) is a one-dimensional fluctuation up date of b γ along the direction b α . W e consider t wo lik eliho o d choices, Gaussian and Bernoulli with a logit link, which lead to differen t up date maps for b γ (1) . See App endix B . Prop osition 2.2 (Asymptotic normalit y) . Supp ose b α and b γ ar e obtaine d by cr oss-fitting and satisfy me an-squar e-err or r ate c onditions such as ∥ b α − α 0 ∥ L 2 ( P ) ∥ b γ − γ 0 ∥ L 2 ( P ) = o p n − 1 / 2 along with mild moment c onditions. Then the AR W estimator in ( 17 ) is asymptotic al ly line ar with influenc e function ψ ( W ; θ 0 , γ 0 , α 0 ) in ( 3 ), so that √ n b θ AR W − θ 0 d − → N (0 , V [ ψ ( W ; θ 0 , γ 0 , α 0 )]) . A nalo gous statements hold for the TMLE-style estimator. Inference. F or eac h estimator, genriesz computes W ald-type standard errors from the empirical v ariance of the corresp onding estimated influence-function scores. Cross-fitting is recommended in high-capacity settings ( Chernozhuk o v et al. , 2018 ). 3 API Design and Soft w are Arc hitecture The design goal of genriesz is to separate statistic al intent , the functional m and the represen ter class, from numeric al implementation , basis matrices, generator deriv atives, solv ers, and cross-fitting. 7 3.1 Core Abstractions The main entry point is grr functional : from genriesz import grr_functional res = grr_functional( X=X, Y=Y, m=m, # Functional object basis=basis, # Feature map phi(x) generator=gen, # BregmanGenerator (or g=..., grad_g=..., inv_grad_g=..., grad2_g=...) cross_fit=True, folds=5, estimators=("ra","rw","arw","tmle"), ) print(res.summary_text()) The returned result ob ject stores p oin t estimates, standard errors, confidence in terv als, p -v alues, and optional out-of-fold nuisance predictions. Estimators, cross-fitting, and outcome mo dels. The estimators argumen t selects whic h plug-in estimators to report. The built-in names follo w the genriesz naming con v ention, "ra" for regression adjustment, "rw" for Riesz weigh ting, "arw" for augmen ted Riesz weigh ting, and "tmle" for the TMLE-st yle up date. Cross-fitting is enabled b y cross fit=True with folds con trolling the n um b er of folds. F or RA, AR W, and TMLE, the pac k age needs an outcome regression mo del b γ . Users can con trol its construction b y outcome models , for example, "shared" fits a linear mo del using the same basis and regularization in terface as the Riesz mo del, while "separate" fits the same outcome regression on a user-supplied outcome basis outcome basis . Setting outcome models="none" skips outcome mo deling, then only R W is av ailable. 3.2 Built-In F unctionals and W rapp ers F or common causal estimands with a binary treatment indicator D stored in a column of X , the pac k age provides conv enience wrappers that call grr functional with predefined m : • grr ate : A TE for X = [ D , Z ] with m ( W , γ ) = γ (1 , Z ) − γ (0 , Z ). • grr att : A TT for X = [ D , Z ] . One con v enient linear functional is m ( W , γ ) = D π 1 ( γ (1 , Z ) − γ (0 , Z )) with π 1 : = E [ D ] . In the wrapp er, π 1 is estimated b y b π 1 : = 1 n P n i =1 D i . • grr did : panel difference-in-difference (DID) implemen ted as A TT on ∆ Y : = Y 1 − Y 0 , where Y 0 and Y 1 are pre and p ost outcomes for the same units. • grr ame : AME via deriv atives, requiring a basis that implements ∂ ϕ ( x ) ∂ x k . These wrapp ers reduce b oilerplate for standard w orkflows while still exp osing basis and generator c hoices. 8 Algorithm 1 Simplified w orkflo w implemen ted b y grr functional Require: Data ( X i , Y i ) n i =1 , functional m , basis ϕ , generator g , folds K . 1: for k = 1 to K (if cross-fitting; else K = 1) do 2: Fit represen ter mo del b α ( − k ) on training fold via generalized Riesz regression. 3: Fit outcome mo del b γ ( − k ) on training fold if RA, AR W, or TMLE is requested. 4: Predict b α i and b γ i on held-out fold. 5: end for 6: Compute RA, R W, AR W, and TMLE estimators. 7: Compute standard errors and confidence in terv als from influence-function scores. 8: return Estimates and inference summary . 3.3 Basis F unctions and Extensibilit y The genriesz pac k age treats the represen ter mo del as linear in a user-sp ecified feature map ϕ ( x ). The core module includes polynomial features and treatment-in teraction features for A TE and A TT w orkflo ws, as well as RKHS-st yle appro ximations via random F ourier features and Nystr¨ om features. Tw o optional mo dules expand the basis library: (i) genriesz.sklearn basis pro vides a random forest leaf one-hot basis that turns a fitted ensem ble into a sparse feature map, and (ii) genriesz.torch basis wraps a PyT orch embedding net w ork as a frozen feature map. Finally , genriesz pro vides a kNN catchmen t basis KNNCatchmentBasis and matching utilities in genriesz.matching , whic h connect nearest-neigh b or matc hing to squared-loss Riesz regression ( Kato , 2025b ; Lin et al. , 2023 ). F eature maps. Keeping the solver linear in β in the dual co ordinate preserv es con v exity and the exact ARB optimality conditions in Prop osition 2.1 . This suggests a practical pattern for neural pip elines, learn an em b edding, freeze it, and then fit the representer in the induced feature space. 3.4 Optimization and Regularization The GLM solver supports ℓ p p enalties for an y p ≥ 1. P enalty in terface. F or the Riesz model, set riesz penalty="l2" for ridge, riesz penalty="l1" for lasso, and riesz penalty="lp" with riesz p norm=p for general p ≥ 1. A shorthand suc h as riesz penalty="l1.5" is also supported. When using the default linear outcome regression, the same interface is a v ailable via outcome penalty and outcome p norm . F or p ≥ 1, genriesz uses L-BF GS-B via SciPy , with a smo oth appro ximation of the ℓ 1 subgradien t when p = 1. The solv er exp oses iteration limits and tolerances, but defaults aim to w ork out-of-the-b o x for mo derate feature dimensions. 9 4 Assumptions on Input Data genriesz is designed around a simple data interface: X is a NumPy arra y of shap e ( n, d ) and Y is a vector of shap e ( n, ) . The meaning of columns of X is left to the user and to the functional ob ject. Binary treatmen t con v entions. F or wrapp ers for A TE, A TT, and DID estimation, the treatmen t indicator D is assumed to b e binary and stored at a known column index of X . The user can freely c ho ose the remaining co v ariates Z . P anel DID. F or grr did , the pac k age exp ects tw o outcome vectors Y0 and Y1 represen ting pre and p ost outcomes for the same units and computes ∆ Y : = Y 1 − Y 0 in ternally . Sampling and inference. The default inference uses an i.i.d. appro ximation and W ald- t yp e confidence in terv als. As with standard DML softw are, clustered or dep endent data require user-supplied adaptations, for example cluster-robust v ariance estimators, whic h are not y et part of the core release. 5 Examples and Repro ducibilit y The repository includes runnable scripts and Jupyter noteb o oks illustrating the workflo ws b elo w. 5.1 A TE with P olynomial F eatures and UKL Generator Let X = [ D , Z ] and choose a polynomial basis with treatmen t in teractions: from genriesz import ( grr_ate, PolynomialBasis, TreatmentInteractionBasis, UKLGenerator ) psi = PolynomialBasis(degree=2, include_bias=True) phi = TreatmentInteractionBasis(base_basis=psi) gen = UKLGenerator(C=1.0, branch_fn=lambda x: int(x[0] == 1.0)).as_generator() res = grr_ate( X=X, Y=Y, basis=phi, generator=gen, cross_fit=True, folds=5, estimators=("ra","rw","arw","tmle"), riesz_penalty="l2", riesz_lam=1e-3, ) print(res.summary_text()) 10 5.2 A TT and P anel DID A TT and panel DID are a v ailable via wrapper functions: from genriesz import ( grr_att, grr_did, PolynomialBasis, TreatmentInteractionBasis, SquaredGenerator ) psi = PolynomialBasis(degree=2, include_bias=True) phi = TreatmentInteractionBasis(base_basis=psi) gen = SquaredGenerator().as_generator() res_att = grr_att( X=X, Y=Y, basis=phi, generator=gen, cross_fit=True, folds=5, estimators=("arw","tmle"), ) res_did = grr_did( X=X, Y0=Y0, Y1=Y1, basis=phi, generator=gen, cross_fit=True, folds=5, estimators=("arw","tmle"), ) 5.3 Av erage Marginal Effects Av erage marginal effects can b e computed when the chosen basis implements deriv ativ es: from genriesz import grr_ame, PolynomialBasis, SquaredGenerator phi = PolynomialBasis(degree=2, include_bias=True) res_ame = grr_ame( X=X, Y=Y, coordinate=2, basis=phi, generator=SquaredGenerator().as_generator(), cross_fit=True, folds=5, estimators=("ra","rw","arw","tmle"), ) 11 5.4 Nearest-Neigh b or Matc hing Nearest-neigh b or matc hing w eights can b e computed using the built-in matc hing Riesz metho d: from genriesz import grr_ate, PolynomialBasis # A basis is required by the API. When outcome_models="none", it is not used. basis = PolynomialBasis(degree=1, include_bias=True) res_match = grr_ate( X=X, Y=Y, basis=basis, riesz_method="nn_matching", M=1, cross_fit=False, outcome_models="none", estimators=("rw",), ) 6 Pro ject Dev elopmen t and Dep endencies Av ailabilit y and installation. The pac k age is a v ailable on PyPI and can b e installed b y pip install genriesz . The pack age is also a v ailable on GitHub https://github.com/ MasaKat0/genriesz . Optional extras enable scikit-learn-based and PyT orc h-based bases. The documentation is hosted at https://genriesz.readthedocs.io . Dep endencies. The core pac k age dep ends only on NumPy and SciPy ( Harris et al. , 2020 ; Virtanen et al. , 2020 ). Optional extras provide scikit-learn-based tree feature maps and PyT orch-based neural feature maps ( P edregosa et al. , 2011 ; Buitinck et al. , 2013 ; Paszk e et al. , 2019 ). Qualit y control. The pro ject includes unit tests, t yp e hin ts, and contin uous in tegration to catc h regressions. The soft ware is released under the GNU General Public License v3.0 (GPL-3.0). 7 Comparison to Related Soft w are Debiased ML and causal ML libraries. DoubleML ( Bac h et al. , 2022 , 2024 ) and EconML ( Batto cc hi et al. , 2019 ) provide pro duction-quality implemen tations of canonical DML estimators, with a fo cus on treatmen t effect estimation and, in EconML , heterogeneous effects. DoWhy ( Sharma & Kiciman , 2020 ) pro vides an end-to-end causal inference in terface cen tered on causal graphs. CausalML ( Chen et al. , 2020 ) offers a broad suite of uplift mo deling and heterogeneous effect estimators. 12 genriesz is complemen tary . It targets low-dimensional linear functionals with v alid inference via orthogonalization and emphasizes representer estimation and balancing. This estimand-cen tric API makes it conv enient to prototype new targets b y defining only the oracle m , while keeping the represen ter fitting problem explicit. Balancing-w eight and densit y ratio to olkits. Several to olkits implement sp ecific balancing-w eight estimators, such as en tropy balancing or stable weigh ts, for A TE-lik e problems. Density ratio estimation pack ages such as densratio ( Makiy ama , 2019 ) implement metho ds suc h as uLSIF, RuLSIF, and KLIEP . genriesz connects these approac hes to Riesz represen ter estimation and DML-st yle inference through a single in terface. 8 Conclusion The genriesz pac k age provides an estimand-and-balancing-cen tric implementation of ADML via generalized Riesz regression under Bregman div ergences. By unifying Riesz representer fitting, automatic regressor balancing, and debiased estimation behind mo dular abstractions, the pac k age aims to mak e ADML practical for a wide range of causal and structural parameter estimation problems. References Susan A they , Guido W. Im b ens, and Stefan W ager. Approximate residual balancing: debiased inference of av erage treatmen t effects in high dimensions. Journal of the R oyal Statistic al So ciety. Series B (Statistic al Metho dolo gy) , 80(4):597–623, 2018. 4 Susan A they , Julie Tibshirani, and Stefan W ager. Generalized random forests. The Annals of Statistics , 47(2):1148 – 1178, 2019. 4 Philipp Bach, Victor Chernozh uk ov, Malte S. Kurz, and Martin Spindler. Doubleml - an ob ject-oriented implementation of double machine learning in python. Journal of Machine L e arning R ese ar ch , 23(53):1–6, 2022. 2 , 12 Philipp Bach, Malte S. Kurz, Victor Chernozhuk o v, Martin Spindler, and Sven Klaassen. Doubleml: An ob ject-oriented implemen tation of double mac hine learning in r. Journal of Statistic al Softwar e , 108(3):1–56, 2024. 12 Heejung Bang and James M. Robins. Doubly robust estimation in missing data and causal inference models. Biometrics , 61(4):962–973, 2005. 2 Keith Battocchi, Eleanor Dillon, Maggie Hei, Greg Lewis, Paul Ok a, Miruna Oprescu, and V asilis Syrgk anis. EconML: A Python pac k age for ML-based heterogeneous treatmen t effects estimation. https://github.com/py- why/EconML , 2019. 2 , 12 Da vid Bruns-Smith, Oliver Duk es, Avi F eller, and Elizab eth L Ogburn. Augmen ted balancing w eights as linear regression. Journal of the R oyal Statistic al So ciety Series B: Statistic al Metho dolo gy , 04 2025. 4 13 Lars Buitinc k, Gilles Louppe, Mathieu Blondel, F abian P edregosa, Andreas Mueller, Olivier Grisel, Vlad Niculae, Peter Prettenhofer, Alexandre Gramfort, Jaques Grobler, Rob ert La yton, Jake V anderPlas, Arnaud Joly , Brian Holt, and Ga ¨ el V aro quaux. API design for mac hine learning softw are: exp eriences from the scikit-learn pro ject. In ECML PKDD Workshop: L anguages for Data Mining and Machine L e arning , 2013. 12 Huigang Chen, T otte Harinen, Jeong-Y o on Lee, Mike Y ung, and Zhenyu Zhao. CausalML: Python pac k age for causal mac hine learning, 2020. 2 , 12 Xiaohong Chen and Zhipeng Liao. Siev e semiparametric t wo-step gmm under weak dep endence. Journal of Ec onometrics , 189(1):163–186, 2015. 2 , 4 , 5 Xiaohong Chen and Demian Pouzo. Siev e w ald and qlr inferences on semi/nonparametric conditional momen t mo dels. Ec onometric a , 83(3):1013–1079, 2015. 4 Victor Chernozh uk ov, Denis Chetverik o v, Mert Demirer, Esther Duflo, Christian Hansen, Whitney New ey , and James Robins. Double/debiased machine learning for treatmen t and structural parameters. The Ec onometrics Journal , 2018. 2 , 3 , 7 Victor Chernozh uk o v, Whitney K. Newey , Victor Quin tas-Martinez, and V asilis Syrgk anis. Automatic debiased machine learning via riesz regression, 2021. arXiv:2104.14737. 2 , 4 , 5 Victor Chernozh uk o v, Whitney New ey , V ´ ıctor M Quintas-Mart ´ ınez, and V asilis Syrgk anis. RieszNet and ForestRiesz: Automatic debiased machine learning with neural nets and random forests. In International Confer enc e on Machine L e arning (ICML) , 2022a. 4 Victor Chernozh uk o v, Whitney K. Newey , and Rah ul Singh. Automatic debiased machine learning of causal and structural effects. Ec onometric a , 90(3):967–1027, 2022b. 2 Marthin us Christoffel du Plessis, Gang. Niu, and Masashi Sugiy ama. Con vex form ulation for learning from p ositive and unlab eled data. In International Confer enc e on Machine L e arning (ICML) , 2015. 4 A. Gretton, A. J. Smola, J. Huang, Marcel Schmittfull, K. M. Borgw ardt, and B. Sc h¨ olkopf. Co v ariate shift b y kernel mean matc hing. Dataset Shift in Machine L e arning, 131-160 (2009) , 01 2009. 4 Jens Hainm ueller. En tropy balancing for causal effects: A m ultiv ariate rew eighting metho d to produce balanced samples in observ ational studies. Politic al A nalysis , 20(1):25–46, 2012. 3 , 4 , 5 Charles R. Harris, K. Jarro d Millman, St´ efan J. v an der W alt, Ralf Gommers, P auli Virtanen, Da vid Cournap eau, Eric Wieser, Julian T aylor, Sebastian Berg, Nathaniel J. Smith, Rob ert Kern, Matti Picus, Stephan Ho yer, Marten H. v an Kerkwijk, Matthew Brett, Allan Haldane, Jaime F ern´ andez del R ´ ıo, Mark Wieb e, P earu Peterson, Pierre G´ erard-Marchan t, Kevin Sheppard, T yler Reddy , W arren W eck esser, Hameer Abbasi, Christoph Gohlke, and T ra vis E. Oliphan t. Arra y programming with n ump y . Natur e , 585(7825):357–362, 2020. 12 14 Aap o Hyv¨ arinen. Estimation of non-normalized statistical mo dels b y score matching. Journal of Machine L e arning R ese ar ch , 6(24):695–709, 2005. 4 Kosuk e Imai and Marc Ratk o vic. Cov ariate balancing prop ensit y score. Journal of the R oyal Statistic al So ciety Series B: Statistic al Metho dolo gy , 76(1):243–263, 07 2013. ISSN 1369-7412. 2 T ak afumi Kanamori, Shohei Hido, and Masashi Sugiy ama. A least-squares approach to direct imp ortance estimation. Journal of Machine L e arning R ese ar ch , 10(Jul.):1391–1445, 2009. 4 T ak afumi Kanamori, T aiji Suzuki, and Masashi Sugiy ama. Statistical analysis of kernel-based least-squares densit y-ratio estimation. Mach. L e arn. , 86(3):335–367, Marc h 2012. ISSN 0885-6125. 4 Masahiro Kato. Direct bias-correction term estimation for prop ensit y scores and av erage treatmen t effect estimation, 2025a. arXiv: 2509.22122. 2 Masahiro Kato. Nearest neigh b or matching as least squares densit y ratio estimation and riesz regression, 2025b. arXiv: 2510.24433. 9 Masahiro Kato. A unified framew ork for debiased mac hine learning: Riesz represen ter fitting under bregman divergence, 2026. arXiv: 2601.07752. 2 , 3 , 6 Masahiro Kato and T akeshi T eshima. Non-negative bregman divergence minimization for deep direct densit y ratio estimation. In International Confer enc e on Machine L e arning (ICML) , 2021. 4 Ryuic hi Kiryo, Gang Niu, Marthinus Christoffel du Plessis, and Masashi Sugiyama. Positiv e- unlab eled learning with non-negativ e risk estimator. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , 2017. 4 Chris A. J. Klaassen. Consisten t estimation of the influence function of locally asymptotically linear estimators. Annals of Statistics , 15, 1987. 2 Kaitlyn J. Lee and Alejandro Sch uler. Rieszb o ost: Gradien t b o osting for riesz regression, 2025. arXiv: 2501.04871. 4 Zhexiao Lin, Peng Ding, and F ang Han. Estimation based on nearest neigh b or matc hing: from densit y ratio to a v erage treatment effect. Ec onometric a , 91(6):2187–2217, 2023. 4 , 9 Ko ji Makiyama. densratio: Densit y ratio estimation. https://CRAN.R- project.org/ package=densratio , 2019. R pac k age v ersion 0.2.1. 3 , 13 XuanLong Nguy en, Martin W ainwrigh t, and Michael Jordan. Estimating div ergence func- tionals and the likelihoo d ratio b y con vex risk minimization. IEEE , 2010. 4 Adam P aszke, Sam Gross, F rancisco Massa, Adam Lerer, James Bradbury , Gregory Chanan, T revor Killeen, Zeming Lin, Natalia Gimelshein, Luca An tiga, Alban Desmaison, Andreas K¨ opf, Edw ard Y ang, Zac h DeVito, Martin Raison, Alykhan T ejani, Sasank Chilamkurth y , 15 Benoit Steiner, Lu F ang, Junjie Bai, and Soumith Chin tala. Pytorc h: an imp erativ e st yle, high-p erformance deep learning library . In International Confer enc e on Neur al Information Pr o c essing Systems (NeurIPS) , 2019. 12 F. P edregosa, G. V aro quaux, A. Gramfort, V. Mic hel, B. Thirion, O. Grisel, M. Blon- del, P . Prettenhofer, R. W eiss, V. Dub ourg, J. V anderplas, A. P assos, D. Cournap eau, M. Brucher, M. Perrot, and E. Duchesna y . Scikit-learn: Mac hine learning in Python. Journal of Machine L e arning R ese ar ch , 12:2825–2830, 2011. 12 Jing Qin. Inferences for case-con trol and semiparametric t wo-sample density ratio mo dels. Biometrika , 85(3):619–630, 1998. 4 B. Rhodes, K. Xu, and M.U. Gutmann. T elescoping densit y-ratio estimation. In NeurIPS , 2020. 4 Diptanil San tra, Guanh ua Chen, and Chan Park. Distributional balancing for causal inference: A unified framework via characteristic function distance, 2026. arXiv: 2601.15449. 4 Amit Sharma and Emre Kiciman. Dowh y: An end-to-end library for causal inference, 2020. 2 , 12 Rah ul Singh. Kernel ridge riesz represen ters: Generalization, mis-sp ecification, and the coun terfactual effective dimension, 2024. arXiv: 2102.11076. 4 Masashi Sugiy ama, T aiji Suzuki, Shinic hi Nak a jima, Hisashi Kashima, P aul von B ¨ unau, and Motoaki Ka w anab e. Direct imp ortance estimation for cov ariate shift adaptation. A nnals of the Institute of Statistic al Mathematics , 60(4):699–746, 2008. 4 Masashi Sugiyama, T aiji Suzuki, and T ak afumi Kanamori. Density ratio matching under the bregman divergence: A unified framework of densit y ratio estimation. A nnals of the Institute of Statistic al Mathematics , 64, 10 2011. 4 Masashi Sugiy ama, T aiji Suzuki, and T ak afumi Kanamori. Density R atio Estimation in Machine L e arning . Cam bridge Univ ersity Press, 2012. 2 Zhiqiang T an. Regularized calibrated estimation of prop ensit y scores with model missp ecifi- cation and high-dimensional data. Biometrika , 107(1):137–158, 2019. 4 , 5 Alexander T arr and Kosuk e Imai. Estimating av erage treatmen t effects with supp ort v ector mac hines. Statistics in Me dicine , 44(5), 2025. 4 v an der Laan. T argeted maximum likelihoo d learning, 2006. U.C. Berkeley Division of Biostatistics W orking P ap er Series. W orking Paper 213. https://biostats.bepress. com/ucbbiostat/paper213/ . 2 P auli Virtanen, Ralf Gommers, T ravis E. Oliphant, Matt Haberland, Tyler Reddy , Da vid Cournap eau, Evgeni Burovski, P earu Peterson, W arren W eck esser, Jonathan Brigh t, St ´ efan J. v an der W alt, Matthew Brett, Joshua Wilson, K. Jarrod Millman, Nikola y Ma yoro v, Andrew R. J. Nelson, Eric Jones, Rob ert Kern, Eric Larson, C J Carey , ˙ Ilhan 16 P olat, Y u F eng, Eric W. Mo ore, Jak e V anderPlas, Denis Laxalde, Josef Perktold, Rob ert Cimrman, Ian Henriksen, E. A. Quin tero, Charles R. Harris, Anne M. Arc hibald, Antˆ onio H. Rib eiro, F abian P edregosa, Paul v an Mulbregt, and SciPy 1.0 Con tributors. SciPy 1.0: F undamen tal Algorithms for Scientific Computing in Python. Natur e Metho ds , 17:261–272, 2020. 12 Stefan W ager and Susan Athey . Estimation and inference of heterogeneous treatmen t effects using random forests. Journal of the Americ an Statistic al Asso ciation , 113(523):1228–1242, 2018. 4 Qingyuan Zhao. Cov ariate balancing propensity score b y tailored loss functions. The Annals of Statistics , 47(2):965 – 993, 2019. 4 , 5 Jos ´ e R. Zubizarreta. Stable w eigh ts that balance co v ariates for estimation with incomplete outcome data. Journal of the A meric an Statistic al Asso ciation , 110(511):910–922, 2015. 3 , 4 17 , A Built-in Bregman generators This appendix lists the built-in Bregman generators and their induced links. Squared distance generator. SquaredGenerator uses g ( α ) = ( α − C ) 2 . The link is ζ ( x, α ) = ∂ α g ( α ) = 2 ( α − C ). Unnormalized KL divergence generator. UKLGenerator uses, for | α | > C , g ( α ) = ( | α | − C ) log ( | α | − C ) − | α | . The link is ζ ( x, α ) = sign ( α ) log ( | α | − C ). Binary KL divergence generator. BKLGenerator uses, for | α | > C , g ( α ) = ( | α | − C ) log ( | α | − C ) − ( | α | + C ) log ( | α | + C ) . The corresponding link is ζ ( x, α ) = sign ( α ) log ( | α | − C ) − log ( | α | + C ) . Basu’s p ow er divergence generator. BPGenerator uses, for some ω > 0 and | α | > C , g ( α ) = ( | α | − C ) 1+ ω − ( | α | − C ) ω − ( | α | − C ) . The link is ζ ( x, α ) = sign ( α ) 1+ ω ω (( | α | − C ) ω − 1). PU learning loss generator. PUGenerator uses, for | α | ∈ (0 , 1), g ( α ) = C | α | log ( | α | ) + (1 − | α | ) log (1 − | α | ) . The link is ζ ( x, α ) = sign ( α ) C log ( | α | ) − log (1 − | α | ) . B Lik eliho o ds in TMLE Gaussian lik eliho o d. When Y is con tin uous, we use the additiv e fluctuation b γ (1) ( x ) : = b γ ( x ) + b ϵ b α ( x ) , b ϵ : = 1 n P n i =1 b α ( X i ) ( Y i − b γ ( X i )) 1 n P n i =1 b α ( X i ) 2 . (18) Since the functional γ 7→ m ( W, γ ) is linear, ( 17 ) can be written as b θ TMLE = b θ RA + b ϵ 1 n n X i =1 m ( W i , b α ) . (19) 18 Bernoulli lik eliho o d. When Y ∈ { 0 , 1 } , w e use a logistic fluctuation that updates b γ on the logit scale. Define Λ( t ) : = 1 / (1 + exp ( − t )) and logit ( p ) : = log p 1 − p . W e set b γ (1) ( x ) : = Λ (logit ( b γ ( x )) + b ϵ b α ( x )) , (20) where b ϵ is defined as a solution to the one-dimensional score equation 1 n n X i =1 b α ( X i ) Y i − b γ (1) ( X i ) = 0 . (21) The TMLE-st yle estimator is then computed by plugging b γ (1) in to ( 17 ). In con trast to the Gaussian case, the represen tation ( 19 ) do es not generally hold b ecause the map ϵ 7→ b γ (1) is nonlinear under the logit fluctuation. 19
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment