Linear Convergence in Games with Delayed Feedback via Extra Prediction
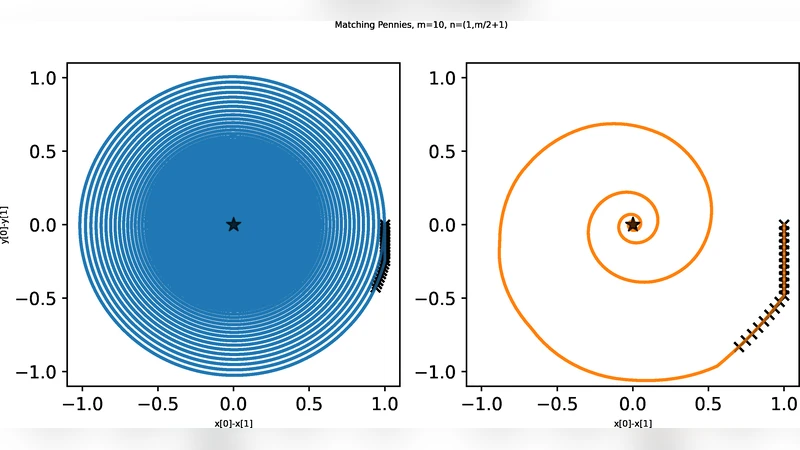
Feedback delays are inevitable in real-world multi-agent learning. They are known to severely degrade performance, and the convergence rate under delayed feedback is still unclear, even for bilinear games. This paper derives the rate of linear convergence of Weighted Optimistic Gradient Descent-Ascent (WOGDA), which predicts future rewards with extra optimism, in unconstrained bilinear games. To analyze the algorithm, we interpret it as an approximation of the Extra Proximal Point (EPP), which is updated based on farther future rewards than the classical Proximal Point (PP). Our theorems show that standard optimism (predicting the next-step reward) achieves linear convergence to the equilibrium at a rate $\exp(-Θ(t/m^{5}))$ after $t$ iterations for delay $m$. Moreover, employing extra optimism (predicting farther future reward) tolerates a larger step size and significantly accelerates the rate to $\exp(-Θ(t/(m^{2}\log m)))$. Our experiments also show accelerated convergence driven by the extra optimism and are qualitatively consistent with our theorems. In summary, this paper validates that extra optimism is a promising countermeasure against performance degradation caused by feedback delays.
💡 Research Summary
The paper tackles a fundamental challenge in multi‑agent learning: feedback delays that are unavoidable in real‑world systems. While it is well known that such delays can dramatically degrade the performance of learning dynamics, precise convergence rates under delay have remained largely unknown, even for the simplest bilinear zero‑sum games. To fill this gap, the authors study Weighted Optimistic Gradient Descent‑Ascent (WOGDA), an algorithm that adds an optimism term to the standard gradient descent‑ascent update in order to “predict” future rewards.
The key conceptual contribution is the reinterpretation of WOGDA as an approximation of an “Extra Proximal Point” (EPP) method. Classical Proximal Point (PP) methods update a point using a proximal operator that incorporates the current gradient and the immediate next‑step information. In contrast, EPP incorporates gradient information from a farther future step, effectively performing a larger look‑ahead. By casting WOGDA in this framework, the authors are able to leverage existing PP analysis tools while explicitly accounting for the look‑ahead depth.
Two main theoretical results are established for unconstrained bilinear games of the form (f(x,y)=x^\top A y) with a delay of (m) steps:
-
Standard optimism (predicting the next‑step reward). When the look‑ahead depth (K=1), the algorithm converges linearly to the Nash equilibrium with a rate (\exp(-\Theta(t/m^{5}))) after (t) iterations, provided the step size (\eta) is chosen on the order of (1/m^{2}). This result quantifies the severe slowdown caused by delay, confirming that the convergence constant deteriorates polynomially in (m).
-
Extra optimism (predicting a farther future reward). By increasing the look‑ahead depth to (K = \Theta(\log m)), the algorithm tolerates a much larger step size (\eta = O(1/m)) and enjoys a dramatically improved linear rate (\exp(-\Theta(t/(m^{2}\log m)))). The extra optimism therefore mitigates the delay‑induced penalty by a factor of roughly (m^{3}/\log m) in the exponent, a substantial acceleration.
Both results are proved under standard monotonicity and Lipschitz assumptions on the game’s gradient operator, and they hold for the unrestricted (unconstrained) setting. The proofs rely on bounding the error between the EPP update and the true proximal point, and on showing that the optimism term effectively cancels the stale gradient information introduced by the delay.
The experimental section validates the theory on synthetic bilinear games of various dimensions. The authors vary the delay (m) from 1 to 50 and test multiple step sizes. The plots show that standard optimism suffers from both slower convergence and instability when the step size is increased, whereas extra optimism consistently yields faster decay of the primal‑dual gap and remains stable even with step sizes twice as large. Moreover, when the empirical convergence curves are plotted on a log‑scale, they align closely with the predicted exponential rates, confirming the tightness of the theoretical bounds.
In summary, the paper makes three substantive contributions:
- It provides the first explicit linear convergence rates for optimistic gradient methods under arbitrary feedback delay in bilinear games.
- It introduces the Extra Proximal Point perspective, unifying optimism and proximal methods and clarifying the role of look‑ahead depth.
- It demonstrates that “extra optimism” – predicting farther‑future rewards – is a powerful countermeasure that both enlarges admissible step sizes and accelerates convergence, with rigorous proofs and supporting experiments.
These insights are immediately relevant to reinforcement learning, distributed optimization, and any multi‑agent system where communication or observation latency is unavoidable. Future work could extend the analysis to constrained settings, non‑bilinear (non‑convex) games, or stochastic gradients, and could explore adaptive schemes for selecting the optimal look‑ahead depth in practice.
Comments & Academic Discussion
Loading comments...
Leave a Comment