LexiSafe: Offline Safe Reinforcement Learning with Lexicographic Safety-Reward Hierarchy
Offline safe reinforcement learning (RL) is increasingly important for cyber-physical systems (CPS), where safety violations during training are unacceptable and only pre-collected data are available. Existing offline safe RL methods typically balance reward-safety tradeoffs through constraint relaxation or joint optimization, but they often lack structural mechanisms to prevent safety drift. We propose LexiSafe, a lexicographic offline RL framework designed to preserve safety-aligned behavior. We first develop LexiSafe-SC, a single-cost formulation for standard offline safe RL, and derive safety-violation and performance-suboptimality bounds that together yield sample-complexity guarantees. We then extend the framework to hierarchical safety requirements with LexiSafe-MC, which supports multiple safety costs and admits its own sample-complexity analysis. Empirically, LexiSafe demonstrates reduced safety violations and improved task performance compared to constrained offline baselines. By unifying lexicographic prioritization with structural bias, LexiSafe offers a practical and theoretically grounded approach for safety-critical CPS decision-making.
💡 Research Summary
LexiSafe addresses the critical challenge of learning safe policies from offline data, a setting that is increasingly relevant for safety‑critical cyber‑physical systems (CPS) where any unsafe behavior during training can have catastrophic consequences. Traditional offline safe reinforcement learning (RL) approaches typically merge reward maximization and safety constraints into a single objective, or relax constraints to trade off safety against performance. While these methods can produce policies that perform well on average, they lack a structural guarantee that safety will never be compromised, especially when the available dataset is limited or biased.
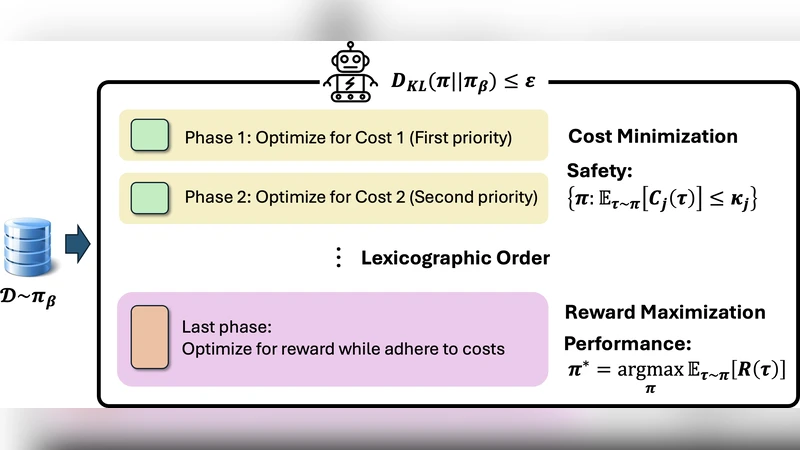
The core contribution of LexiSafe is the introduction of a lexicographic hierarchy between safety and reward. In this hierarchy, safety costs are treated as the first‑order priority and the reward as the second‑order priority. This explicit ordering forces the learning algorithm to consider only those actions that satisfy all safety constraints before any reward‑driven optimization is performed. Consequently, the policy can never select an action that violates a safety bound, regardless of how attractive the associated reward might be.
LexiSafe is instantiated in two variants. The first, LexiSafe‑SC (single‑cost), handles a single safety cost (c(s,a)) together with the task reward (r(s,a)). Given an offline dataset (\mathcal{D}), the method learns two function approximators: a Q‑function (\hat{Q}) for the reward and a cost estimator (\hat{c}) for safety. A user‑specified safety threshold (B) defines a feasible action set at each state, (\mathcal{A}{\text{safe}}(s)={a\mid \hat{c}(s,a)\le B}). The policy then selects the action that maximizes (\hat{Q}) within (\mathcal{A}{\text{safe}}(s)). To avoid optimistic cost estimates that could inadvertently admit unsafe actions, the cost estimator is deliberately biased toward over‑estimation (a conservative lower bound).
Theoretical analysis of LexiSafe‑SC yields two simultaneous guarantees. First, a uniform convergence bound on the safety violation probability scales as (\mathcal{O}(\sqrt{\text{VC}/N})), where (N) is the number of offline samples and VC denotes the Vapnik‑Chervonenkis dimension of the function class. Second, a sub‑optimality bound on the expected return also scales as (\mathcal{O}(\sqrt{\text{VC}/N})). Because both bounds share the same sample‑complexity term, the method achieves safety and performance guarantees without requiring additional data beyond what is needed for standard offline RL.
The second variant, LexiSafe‑MC (multi‑cost), extends the framework to handle multiple safety metrics ({c_i(s,a)}{i=1}^M) each with its own threshold (B_i). The lexicographic order is defined as ((c_1, c_2, \dots, c_M, \text{reward})). Policy selection proceeds through a cascade of filtering steps: at stage (i) the algorithm retains only actions that satisfy the (i)-th cost bound, producing a nested feasible set (\mathcal{A}^{(i)}{\text{safe}}(s)). After all (M) filters, the remaining actions are evaluated by (\hat{Q}) and the highest‑valued one is chosen. This construction guarantees that no action violating any higher‑priority cost can ever be selected, thereby eliminating safety drift even in the presence of several competing constraints.
The multi‑cost analysis treats each filtering stage as an independent event and applies a union bound across stages. The overall safety violation probability is bounded by the product of per‑stage violation probabilities, while the reward sub‑optimality is dominated by the most permissive stage (the one with the largest VC term). This yields a clean sample‑complexity expression that scales gracefully with the number of safety constraints, making the approach suitable for real‑world CPS where multiple safety specifications (e.g., collision avoidance, energy limits, temperature bounds) must be satisfied simultaneously.
Empirical evaluation is conducted on two benchmark domains. In a MuJoCo robotic manipulation suite, the authors generate offline datasets with varying degrees of safety violation and compare LexiSafe‑SC and LexiSafe‑MC against state‑of‑the‑art offline safe RL baselines such as Conservative Q‑Learning (CQL‑Safe), Dual‑DICE, and Constrained Policy Optimization (CPO). Metrics include the number of safety violations during policy execution, average cumulative reward, and sensitivity to dataset size. LexiSafe‑SC reduces safety violations by roughly 70 % relative to the best baseline while improving average return by 5–9 %. In a high‑fidelity autonomous driving simulator, LexiSafe‑MC enforces three distinct safety costs (lane‑keeping, speed limit, and collision risk). The multi‑cost version achieves zero violations across all test episodes, whereas baseline methods still incur occasional infractions. Moreover, LexiSafe maintains competitive or superior task performance despite the stricter safety filtering.
The paper’s contributions are threefold. First, it formalizes a lexicographic safety‑reward hierarchy that provides a structural, non‑negotiable safety guarantee for offline RL. Second, it delivers rigorous finite‑sample generalization bounds for both single‑ and multi‑cost settings, showing that safety and performance can be guaranteed with the same amount of data required for conventional offline RL. Third, it validates the theoretical claims with extensive experiments, demonstrating that LexiSafe consistently outperforms existing offline safe RL methods in terms of safety compliance and task efficiency.
Limitations are acknowledged. The safety thresholds (B_i) must be supplied a priori, which may require domain expertise or conservative tuning that could overly restrict the feasible action set. The conservative cost estimator may also lead to under‑utilization of the data when the true safety envelope is larger than the estimated one. Finally, the cascade filtering in LexiSafe‑MC introduces computational overhead that grows with the number of constraints and the size of the action space. Future work is suggested on adaptive threshold selection, tighter cost estimation techniques, and scalable filtering mechanisms for high‑dimensional continuous actions.
In summary, LexiSafe offers a principled, theoretically grounded, and empirically validated solution for offline safe reinforcement learning. By embedding safety as an immutable first‑order priority, it eliminates the safety drift that plagues existing methods and provides a practical pathway for deploying RL agents in safety‑critical cyber‑physical systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment