Multiple Index Merge for Approximate Nearest Neighbor Search
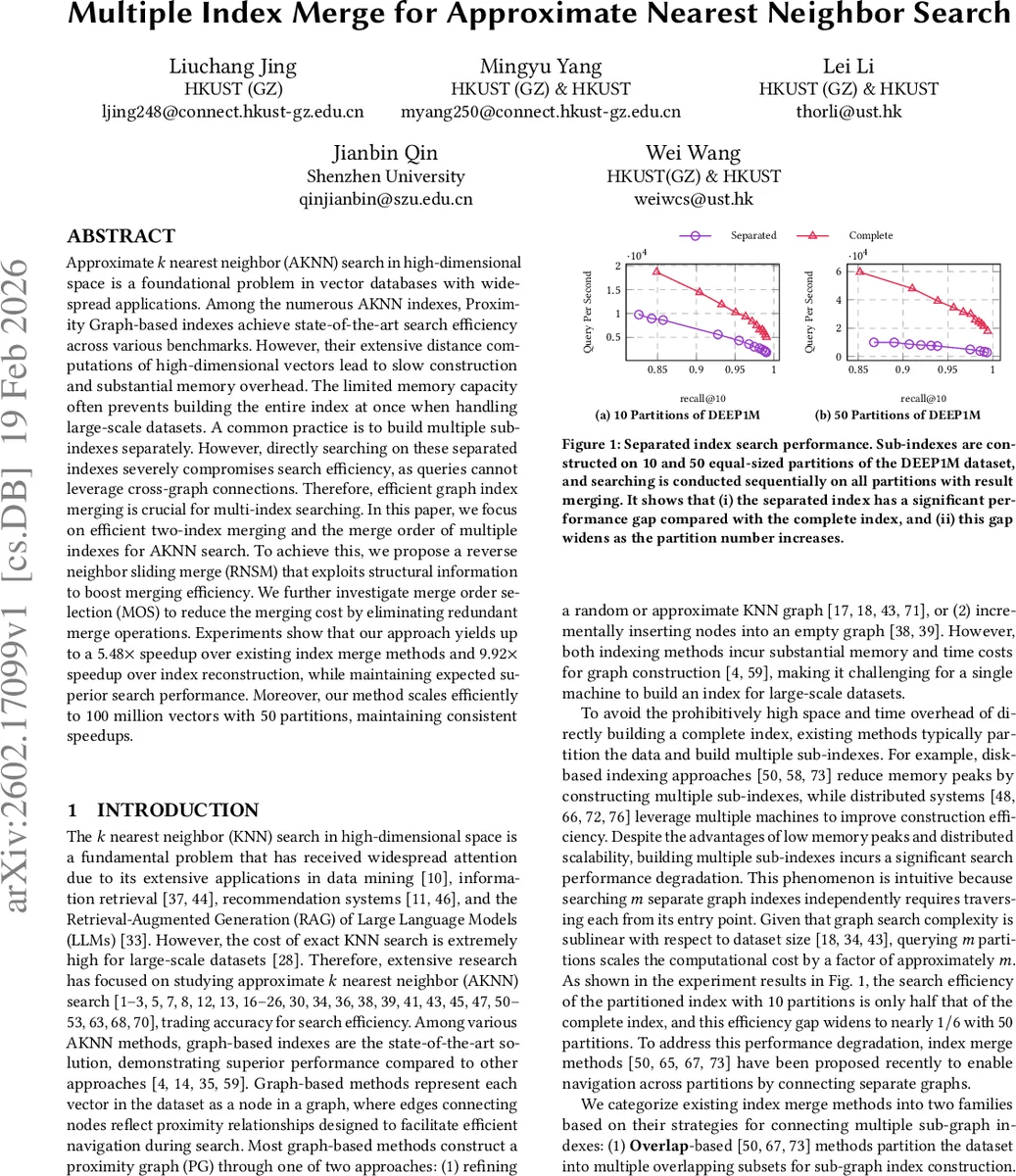
Approximate $k$ nearest neighbor (AKNN) search in high-dimensional space is a foundational problem in vector databases with widespread applications. Among the numerous AKNN indexes, Proximity Graph-based indexes achieve state-of-the-art search efficiency across various benchmarks. However, their extensive distance computations of high-dimensional vectors lead to slow construction and substantial memory overhead. The limited memory capacity often prevents building the entire index at once when handling large-scale datasets. A common practice is to build multiple sub-indexes separately. However, directly searching on these separated indexes severely compromises search efficiency, as queries cannot leverage cross-graph connections. Therefore, efficient graph index merging is crucial for multi-index searching. In this paper, we focus on efficient two-index merging and the merge order of multiple indexes for AKNN search. To achieve this, we propose a reverse neighbor sliding merge (RNSM) that exploits structural information to boost merging efficiency. We further investigate merge order selection (MOS) to reduce the merging cost by eliminating redundant merge operations. Experiments show that our approach yields up to a 5.48$\times$ speedup over existing index merge methods and 9.92$\times$ speedup over index reconstruction, while maintaining expected superior search performance. Moreover, our method scales efficiently to 100 million vectors with 50 partitions, maintaining consistent speedups.
💡 Research Summary
Approximate k‑nearest neighbor (AKNN) search in high‑dimensional spaces underpins many modern vector‑database applications, yet building a single proximity‑graph (PG) index for massive datasets is often infeasible due to prohibitive memory and construction time. A common workaround is to partition the data and construct multiple sub‑indexes independently, but naïvely searching each sub‑graph independently yields severe performance loss because queries cannot traverse cross‑partition edges. Existing merging techniques fall into two families: overlap‑based methods that duplicate data across partitions, and search‑based methods that treat every node of a source index as a query against a target index. Both approaches either waste memory or incur O(m²) search cost when merging m partitions, and they do not directly accelerate the merging process itself.
This paper addresses the two‑index merging problem and the ordering of multiple merges by introducing two novel components: Reverse Neighbor Sliding Merge (RNSM) and Merge Order Selection (MOS).
Reverse Neighbor Sliding Merge (RNSM)
RNSM reframes merging as a search‑optimization problem that exploits reverse‑nearest‑neighbor (RNN) relationships. First, it expands each node’s neighborhood to discover approximate RNNs, which serve as candidate pivots. A greedy pivot‑selection step then picks a small, representative set of pivots based on coverage and centrality. For each pivot, RNSM performs a “local sliding” operation: the search results obtained for the pivot are reused as starting points for its immediate neighbors, thereby avoiding redundant searches. Because each pivot’s sliding window is independent, the algorithm scales naturally to multi‑core or distributed environments. The three‑stage pipeline—neighbor expansion, pivot selection, sliding merge—dramatically reduces the number of distance computations required for merging while preserving the structural richness of the original graphs.
Merge Order Selection (MOS)
When more than two partitions exist, naïve pairwise merging repeats many operations and can degrade the topology of the final graph. MOS formulates the ordering problem as a graph‑optimization task with two simultaneous objectives: (1) minimize the total merge cost by constructing a sparse “merge‑order graph” that eliminates unnecessary pairwise merges, and (2) control the diameter of the eventual unified graph to keep search paths short. For randomly distributed partitions, MOS builds a weighted graph where edge weights reflect cross‑partition neighbor density and then extracts a minimum‑spanning‑forest to guide merges. For clustered partitions, MOS adopts a hierarchical strategy: first merge within clusters, then merge across clusters, thereby preserving locality and reducing long‑range edge creation. Both strategies produce a merge schedule that cuts redundant work and often improves final recall.
Experimental Evaluation
The authors integrate RNSM and MOS into several state‑of‑the‑art PG indexes—HNSW, NSG, SSG, and τ‑MNG—and evaluate on public benchmarks (DEEP1M, SIFT1M, GIST1M) as well as a synthetic 100‑million‑vector dataset split into 50 partitions. Baselines include the naïve search‑based merge, full reconstruction from scratch, and a SimJoin‑inspired variant. Results show:
- Speedup: up to 5.48× faster than the best existing merge method and up to 9.92× faster than full reconstruction.
- Recall: ≥ 0.99 at Recall@10, essentially matching a monolithic index built on the whole dataset.
- Scalability: with 50 partitions and 100 M vectors, RNSM+MOS still delivers > 2× speedup while keeping memory usage 30‑40 % lower than overlap‑based approaches.
- Generality: the technique works across all tested graph families, confirming its broad applicability.
Conclusions and Future Work
By turning the costly neighbor‑candidate generation phase into a reusable, pivot‑driven sliding process and by intelligently ordering merges to avoid redundancy, the paper delivers a practical solution for large‑scale AKNN indexing under memory constraints. The approach enables systems such as disk‑based vector stores or LSM‑tree‑style segment compaction to maintain high query throughput without repeatedly rebuilding entire graphs. Future directions include extending RNSM to dynamic insert/delete workloads, minimizing network traffic in distributed settings, and adapting the method to non‑Euclidean metrics or learned similarity functions.
Comments & Academic Discussion
Loading comments...
Leave a Comment