Sign Lock-In: Randomly Initialized Weight Signs Persist and Bottleneck Sub-Bit Model Compression
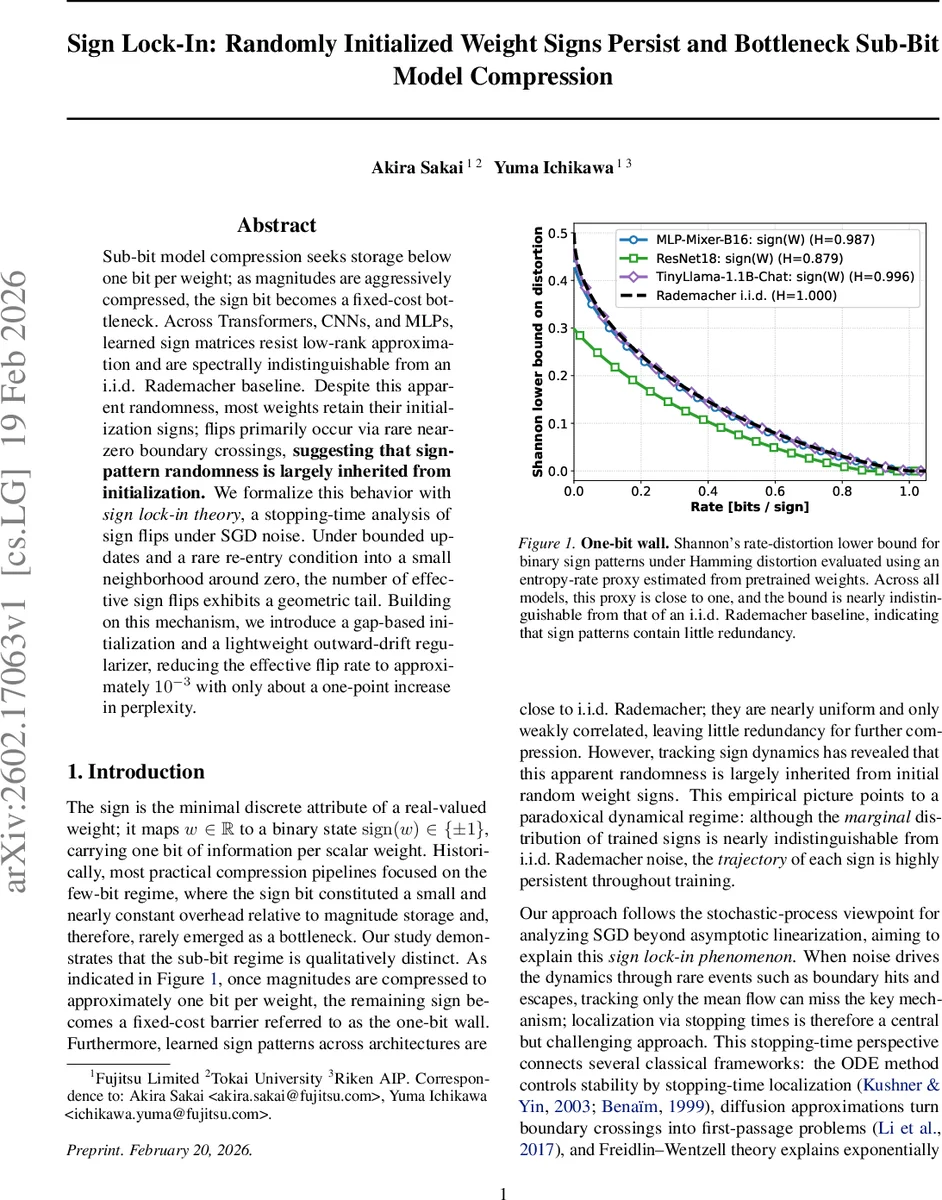
Sub-bit model compression seeks storage below one bit per weight; as magnitudes are aggressively compressed, the sign bit becomes a fixed-cost bottleneck. Across Transformers, CNNs, and MLPs, learned sign matrices resist low-rank approximation and are spectrally indistinguishable from an i.i.d. Rademacher baseline. Despite this apparent randomness, most weights retain their initialization signs; flips primarily occur via rare near-zero boundary crossings, suggesting that sign-pattern randomness is largely inherited from initialization. We formalize this behavior with sign lock-in theory, a stopping-time analysis of sign flips under SGD noise. Under bounded updates and a rare re-entry condition into a small neighborhood around zero, the number of effective sign flips exhibits a geometric tail. Building on this mechanism, we introduce a gap-based initialization and a lightweight outward-drift regularizer, reducing the effective flip rate to approximately $10^{-3}$ with only about a one-point increase in perplexity.
💡 Research Summary
The paper investigates a previously under‑explored regime of model compression where the average storage per parameter falls below one bit, termed the “sub‑bit” regime. In this setting, the sign of each weight becomes a fixed‑cost bottleneck because magnitudes can be aggressively quantized to less than one bit, but the binary sign must still be stored. The authors empirically demonstrate this “one‑bit wall” across three representative architectures—MLP‑Mixer‑B16, ResNet‑18, and TinyLlama‑1.1B‑Chat—by decomposing each weight matrix into a sign matrix S∈{±1} and a magnitude matrix A≥0.
First, they evaluate compressibility via low‑rank approximation error E_r(·). While A’s error drops quickly as the rank ratio q = r/d increases, S’s error decays very slowly, indicating that sign matrices resist low‑rank compression. Second, they assess randomness by comparing the singular‑value spectra of sub‑matrices of S with those of i.i.d. Rademacher matrices using a two‑sample Kolmogorov–Smirnov test. The KS distances are tiny, showing that trained sign patterns are spectrally indistinguishable from pure random noise.
Despite this apparent randomness, a dynamic analysis reveals that most signs remain identical to their random initial values throughout training. The authors define a flip ratio flip(t) that measures the proportion of weights whose sign differs from initialization at step t. Empirically, flip(t) rises only slightly during early training and stays well below 5 % even after full convergence. Flips occur almost exclusively when a weight’s magnitude wanders into a narrow neighborhood around zero, suggesting that sign changes are triggered by rare boundary crossings.
To formalize this observation, the paper introduces a minimal stochastic‑process model for a single scalar weight w_t. Two regions are defined: an outer region where |w| ≥ ρ (sign‑stable) and a boundary region where |w| ≤ ε (sign‑ambiguous). Stopping times σ_k (exits to the outer region) and τ_k (entries into the boundary) are constructed. Two key assumptions are made: (1) bounded updates (|w_{t+1}−w_t| ≤ Δ) preventing a single step from jumping across zero while staying in the outer region, and (2) a uniform re‑entry bound P
Comments & Academic Discussion
Loading comments...
Leave a Comment