Arcee Trinity Large Technical Report
We present the technical report for Arcee Trinity Large, a sparse Mixture-of-Experts model with 400B total parameters and 13B activated per token. Additionally, we report on Trinity Nano and Trinity Mini, with Trinity Nano having 6B total parameters with 1B activated per token, Trinity Mini having 26B total parameters with 3B activated per token. The models’ modern architecture includes interleaved local and global attention, gated attention, depth-scaled sandwich norm, and sigmoid routing for Mixture-of-Experts. For Trinity Large, we also introduce a new MoE load balancing strategy titled Soft-clamped Momentum Expert Bias Updates (SMEBU). We train the models using the Muon optimizer. All three models completed training with zero loss spikes. Trinity Nano and Trinity Mini were pre-trained on 10 trillion tokens, and Trinity Large was pre-trained on 17 trillion tokens. The model checkpoints are available at https://huggingface.co/arcee-ai.
💡 Research Summary
The paper presents a comprehensive technical report on the Arcee Trinity family of open‑weight language models, focusing on three variants: Trinity Large (400 B total parameters, 13 B activated per token), Trinity Mini (26 B total, 3 B active), and Trinity Nano (6 B total, 1 B active). All models are decoder‑only transformers that employ a highly sparse Mixture‑of‑Experts (MoE) architecture. The authors detail every component of the design, from tokenization to training recipes, and introduce two novel contributions: the Soft‑clamped Momentum Expert Bias Updates (SMEBU) load‑balancing scheme for MoE routing, and the use of the Muon optimizer for large‑batch training.
Tokenizer
A custom 200 k BPE vocabulary is trained on ~48 GB of data (≈10 B tokens). The tokenizer incorporates a multi‑stage pipeline: (1) digit isolation with place‑aligned three‑digit chunking, improving arithmetic reasoning; (2) script‑aware isolation for CJK, Thai, Lao, Khmer, Myanmar, and Korean Hangul/Jamo; (3) standard word and punctuation splitting; (4) a byte‑level fallback. Comparative tables show the tokenizer achieves the best bytes‑per‑token compression among non‑SuperBPE tokenizers for English and French, and competitive results for CJK languages. The authors also experimented with SuperBPE, which reduced token count but did not translate into downstream performance gains at their scale.
Attention Architecture
The attention stack combines several recent advances: grouped‑query attention (GQA) to reduce KV‑cache size, QK‑normalization (RMSNorm applied to queries and keys) for training stability, gated attention (sigmoid gating of attention outputs) to curb activation spikes, and a 3:1 pattern of local to global layers. Local layers use sliding‑window attention with rotary positional embeddings (RoPE); global layers omit positional embeddings (NoPE). This arrangement follows Yang et al. (2025) and is claimed to provide strong long‑context performance while keeping compute and memory costs low. The authors report that the gated attention and local/global pattern helped recover performance when training at longer sequence lengths and enabled length extrapolation for Trinity Large.
Mixture‑of‑Experts (MoE) Design
MoE layers follow the DeepSeekMoE design, using fine‑grained routed experts plus an always‑active shared expert. SwiGLU is the activation function. Routing is performed with normalized sigmoid scores rather than softmax, and the top‑K experts are selected using the sum of routing scores and a per‑expert bias. The bias is updated separately from the model weights. For the smaller models (Nano and Mini) the authors employ the auxiliary‑loss‑free load‑balancing method introduced by Wang et al. (2024), which simply recenters the bias after each step.
SMEBU – New Load‑Balancing Scheme
For Trinity Large the authors replace the sign‑based bias update with a magnitude‑aware, tanh‑clamped update (SMEBU). The per‑expert load violation is normalized, passed through a tanh with a scale factor κ, then multiplied by a learning rate λ. A momentum buffer (β) smooths updates over time, and the updates are centered to keep the overall bias sum zero. The authors argue that the sign‑based method can cause oscillations because each step changes the bias by a fixed magnitude, whereas SMEBU provides smoother, scale‑independent corrections, reducing router instability observed in early large‑scale runs.
Optimizer and Training Regime
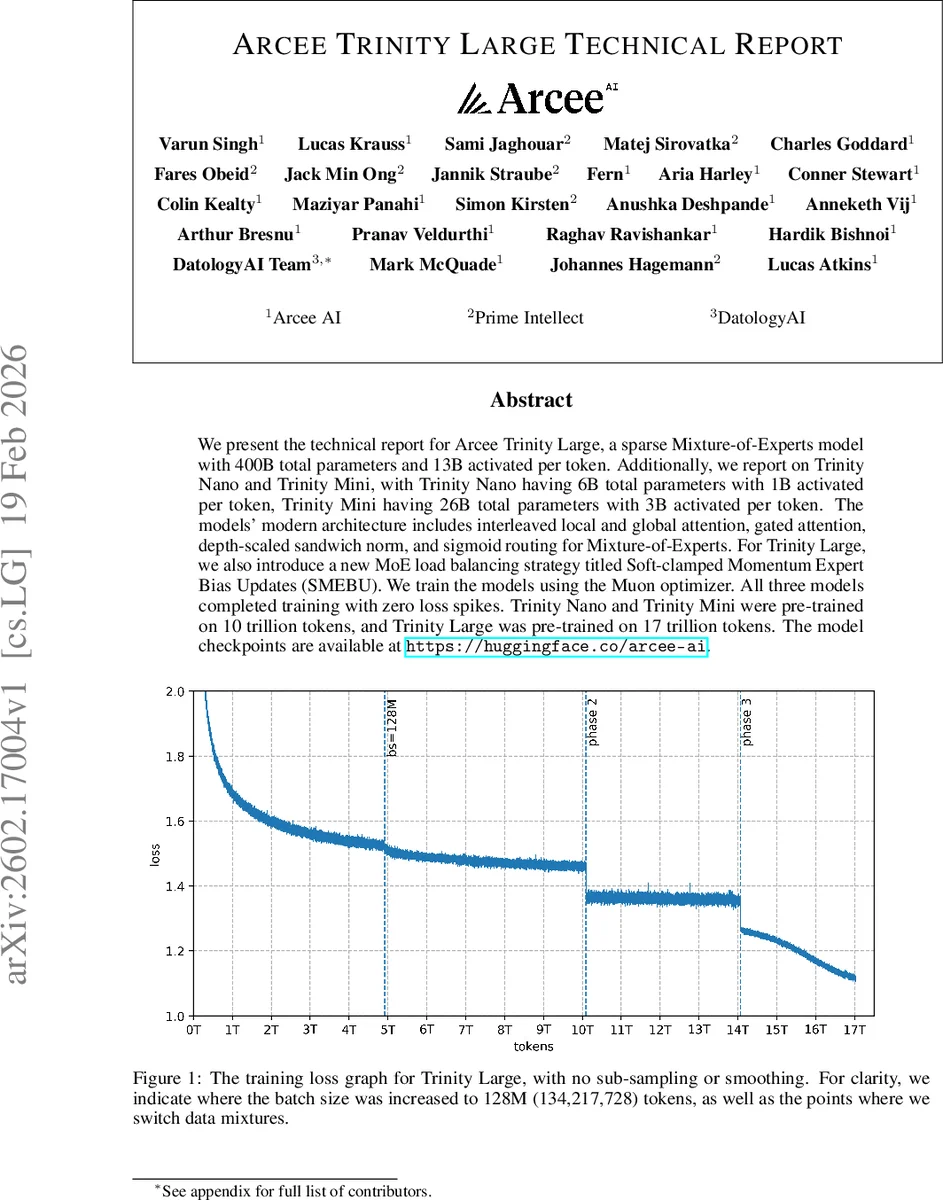
Training uses the Muon optimizer (Jordan et al., 2024), which purportedly allows a larger critical batch size and higher sample efficiency than AdamW. The authors trained Trinity Large on 17 trillion tokens, increasing batch size to 128 M tokens (≈134 M) at certain points, and report zero loss spikes throughout training. Trinity Nano and Mini were each trained on 10 trillion tokens. The training loss curve (Figure 1) shows a smooth decline without any sub‑sampling or smoothing.
Data
The pre‑training corpus mixes curated web‑scale data with synthetic data (code, instruction‑following, reasoning traces). The tokenizer was initially trained on a subset (≈10 B tokens) that under‑represents non‑English languages; the authors note that a full‑corpus tokenizer would likely close the remaining CJK compression gap.
Evaluation
While the paper mentions “Base” and “Preview” checkpoints and claims competitive results across standard benchmarks, detailed numbers are omitted from the excerpt. The authors emphasize that the architecture choices (local/global attention, gated attention, SMEBU) enable efficient inference at long context lengths and improve training stability.
Contributions and Limitations
Key contributions are: (1) a unified architecture combining sparse MoE, interleaved local/global attention, and gated attention; (2) the SMEBU load‑balancing algorithm that stabilizes expert routing in very large MoE models; (3) the use of the Muon optimizer to train at unprecedented batch sizes without loss spikes; (4) a carefully engineered tokenizer with place‑aligned digit handling and extensive script coverage. Limitations include incomplete CJK coverage in the tokenizer, lack of published benchmark numbers, and insufficient analysis of SMEBU hyper‑parameter scaling across model sizes.
Overall Assessment
Arcee Trinity represents a significant engineering effort to bring sparse MoE models to production‑grade scale while maintaining training stability and inference efficiency. The combination of novel routing stabilization (SMEBU), efficient attention patterns, and a high‑throughput optimizer makes the work a valuable reference for organizations building large language models that must operate under strict compute budgets and long‑context requirements. Open‑weight release on Hugging Face further enhances its impact, enabling the community to reproduce and extend the presented techniques.
Comments & Academic Discussion
Loading comments...
Leave a Comment