Persona2Web: Benchmarking Personalized Web Agents for Contextual Reasoning with User History
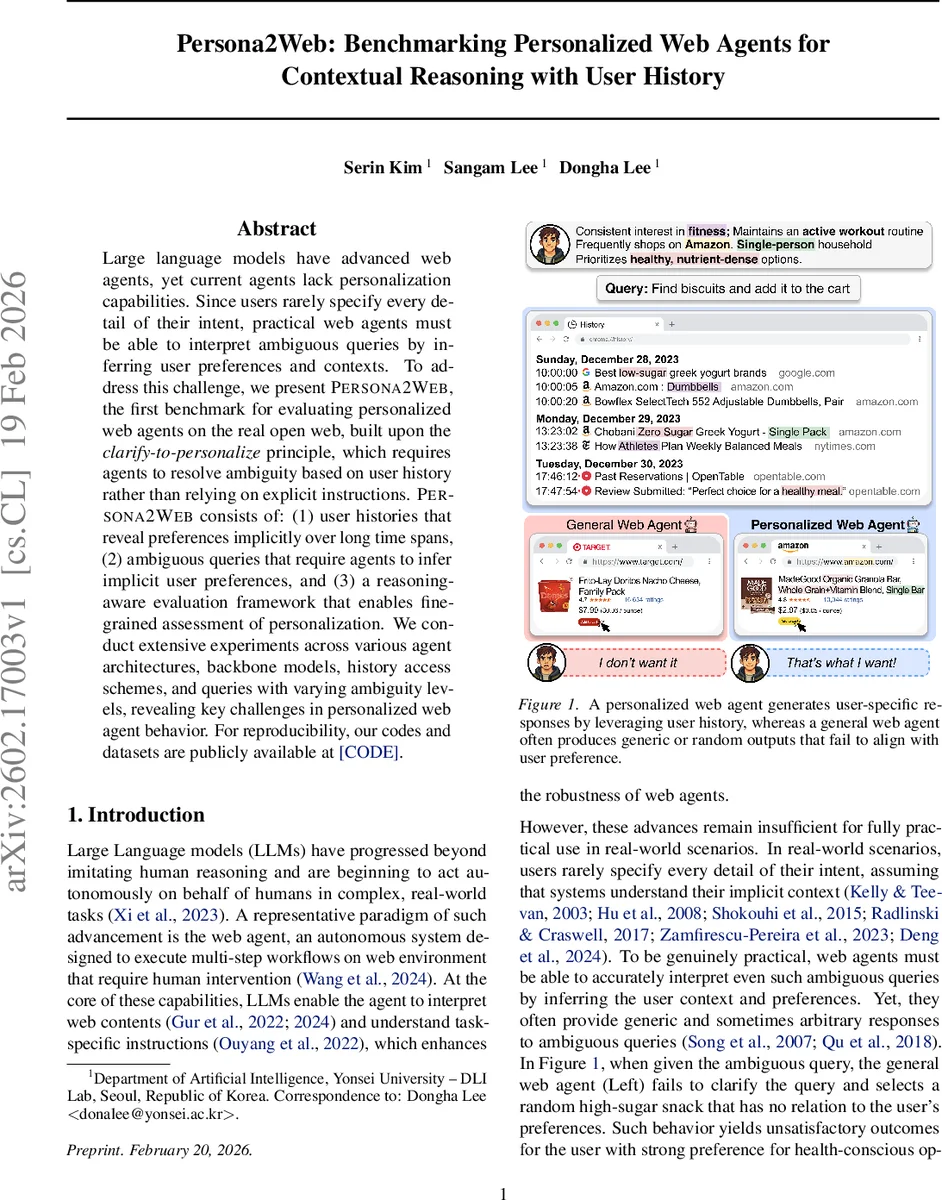
Large language models have advanced web agents, yet current agents lack personalization capabilities. Since users rarely specify every detail of their intent, practical web agents must be able to interpret ambiguous queries by inferring user preferences and contexts. To address this challenge, we present Persona2Web, the first benchmark for evaluating personalized web agents on the real open web, built upon the clarify-to-personalize principle, which requires agents to resolve ambiguity based on user history rather than relying on explicit instructions. Persona2Web consists of: (1) user histories that reveal preferences implicitly over long time spans, (2) ambiguous queries that require agents to infer implicit user preferences, and (3) a reasoning-aware evaluation framework that enables fine-grained assessment of personalization. We conduct extensive experiments across various agent architectures, backbone models, history access schemes, and queries with varying ambiguity levels, revealing key challenges in personalized web agent behavior. For reproducibility, our codes and datasets are publicly available at https://anonymous.4open.science/r/Persona2Web-73E8.
💡 Research Summary
Persona2Web introduces the first benchmark specifically designed to evaluate personalized web agents operating on the real open web. The authors argue that existing web‑agent benchmarks focus on fully specified instructions and static or simulated environments, thereby ignoring the ambiguous, context‑rich queries that real users typically pose. To fill this gap, they propose the “clarify‑to‑personalize” principle: agents must resolve missing information in a query by consulting a user’s long‑term browsing history rather than relying on explicit cues.
The benchmark consists of three core components. First, realistic user histories are generated for 50 synthetic users. Each history contains demographic attributes (age, gender, location) and domain‑specific preferences across 21 common web domains (e.g., e‑commerce, health, travel). Preferences are not listed outright; instead, a large language model (GPT‑4o) selects relevant domains, provides rationales, and then creates detailed preference attributes. These preferences are embedded into a year‑long sequence of high‑frequency (daily shopping, commuting) and low‑frequency (travel, medical check‑ups) events. Each event is broken down into a series of actions (search, visit, purchase, booking, review) with timestamps, object details, and website identifiers. About 10 % of the records are deliberately corrupted to mimic real‑world noise.
Second, ambiguous query sets are constructed for each user. Every query set contains three levels of ambiguity: Level 0 (fully explicit website and preference), Level 1 (preference explicit, website masked), and Level 2 (both website and preference masked). Level 2 is the target test case where the agent must infer the appropriate website and the user‑specific attribute solely from the history.
Third, a reasoning‑aware evaluation framework is introduced. It measures (a) Personalization Score (split into P_web for website selection and P_pref for preference alignment), (b) Intent Satisfaction (task correctness irrespective of personalization), and (c) Success Rate (both personalization and intent satisfied). Each metric uses a discrete rubric (0, 5, 10 points) and requires the agent to output a full reasoning trace. An LLM judge (GPT‑5‑mini) consumes the trace and the rubric to assign scores automatically. Personalization scores are further divided into retrieval accuracy (did the agent fetch the correct historical records?) and utilization accuracy (did it correctly apply the retrieved information?).
The authors evaluate two state‑of‑the‑art web‑agent architectures—AgentOccam and Browser‑Use 2—each powered by GPT‑4o as the underlying language model. Experiments vary the history access scheme (full vs. partial) and query ambiguity level. Key findings include: (1) without any history, agents achieve 0 % success on ambiguous queries, confirming that personal context is essential; (2) even with full history, the best success rate on Level 2 queries is only 13 %, indicating that current models struggle to extract and leverage implicit preferences; (3) personalization and navigation errors are often orthogonal—some agents navigate correctly but fail to personalize, while others personalize well but stumble on navigation due to dynamic web content or mis‑execution; (4) the reasoning‑aware metrics expose these failure modes, which would be hidden by a simple task‑completion score.
The paper concludes that merely providing user history is insufficient; effective personalization requires dedicated memory‑augmentation, indexing, and prompting strategies that can summarize long‑term, dispersed behavior. Moreover, evaluation must separate personalization reasoning from navigation execution, as the two contribute differently to user satisfaction. Future work is suggested in three directions: (i) integrating external knowledge bases or structured memory modules to improve long‑term preference retrieval; (ii) designing better prompts or retrieval‑augmented generation pipelines that can distill salient preferences from noisy histories; (iii) extending the benchmark to multilingual, multi‑cultural user profiles and to more dynamic web scenarios where real‑time feedback and error recovery are essential.
Overall, Persona2Web offers a comprehensive, open‑web benchmark that pushes the field beyond generic web automation toward truly personalized, context‑aware agents capable of handling the ambiguity inherent in everyday user queries.
Comments & Academic Discussion
Loading comments...
Leave a Comment