We study nonparametric maximum likelihood estimation of probability densities under a total variation (TV) type penalty, sectional variation norm (also named as Hardy-Krause variation). TV regularization has a long history in regression and density estimation, including results on $L^2$ and KL divergence convergence rates. Here, we revisit this task using the Highly Adaptive Lasso (HAL) framework. We formulate a HAL-based maximum likelihood estimator (HAL-MLE) using the log-spline link function from \citet{kooperberg1992logspline}, and show that in the univariate setting the bounded sectional variation norm assumption underlying HAL coincides with the classical bounded TV assumption. This equivalence directly connects HAL-MLE to existing TV-penalized approaches such as local adaptive splines \citep{mammen1997locally}. We establish three new theoretical results: (i) the univariate HAL-MLE is asymptotically linear, (ii) it admits pointwise asymptotic normality, and (iii) it achieves uniform convergence at rate $n^{-(k+1)/(2k+3)}$ up to logarithmic factors for the smoothness order $k \geq 1$. These results extend existing results from \citet{van2017uniform}, which previously guaranteed only uniform consistency without rates when $k=0$. We will include the uniform convergence for general dimension $d$ in the follow-up work of this paper. The intention of this paper is to provide a unified framework for the TV-penalized density estimation methods, and to connect the HAL-MLE to the existing TV-penalized methods in the univariate case, despite that the general HAL-MLE is defined for multivariate cases.
Deep Dive into HAL-MLE Log-Splines Density Estimation (Part I: Univariate).
We study nonparametric maximum likelihood estimation of probability densities under a total variation (TV) type penalty, sectional variation norm (also named as Hardy-Krause variation). TV regularization has a long history in regression and density estimation, including results on $L^2$ and KL divergence convergence rates. Here, we revisit this task using the Highly Adaptive Lasso (HAL) framework. We formulate a HAL-based maximum likelihood estimator (HAL-MLE) using the log-spline link function from \citet{kooperberg1992logspline}, and show that in the univariate setting the bounded sectional variation norm assumption underlying HAL coincides with the classical bounded TV assumption. This equivalence directly connects HAL-MLE to existing TV-penalized approaches such as local adaptive splines \citep{mammen1997locally}. We establish three new theoretical results: (i) the univariate HAL-MLE is asymptotically linear, (ii) it admits pointwise asymptotic normality, and (iii) it achieves unif
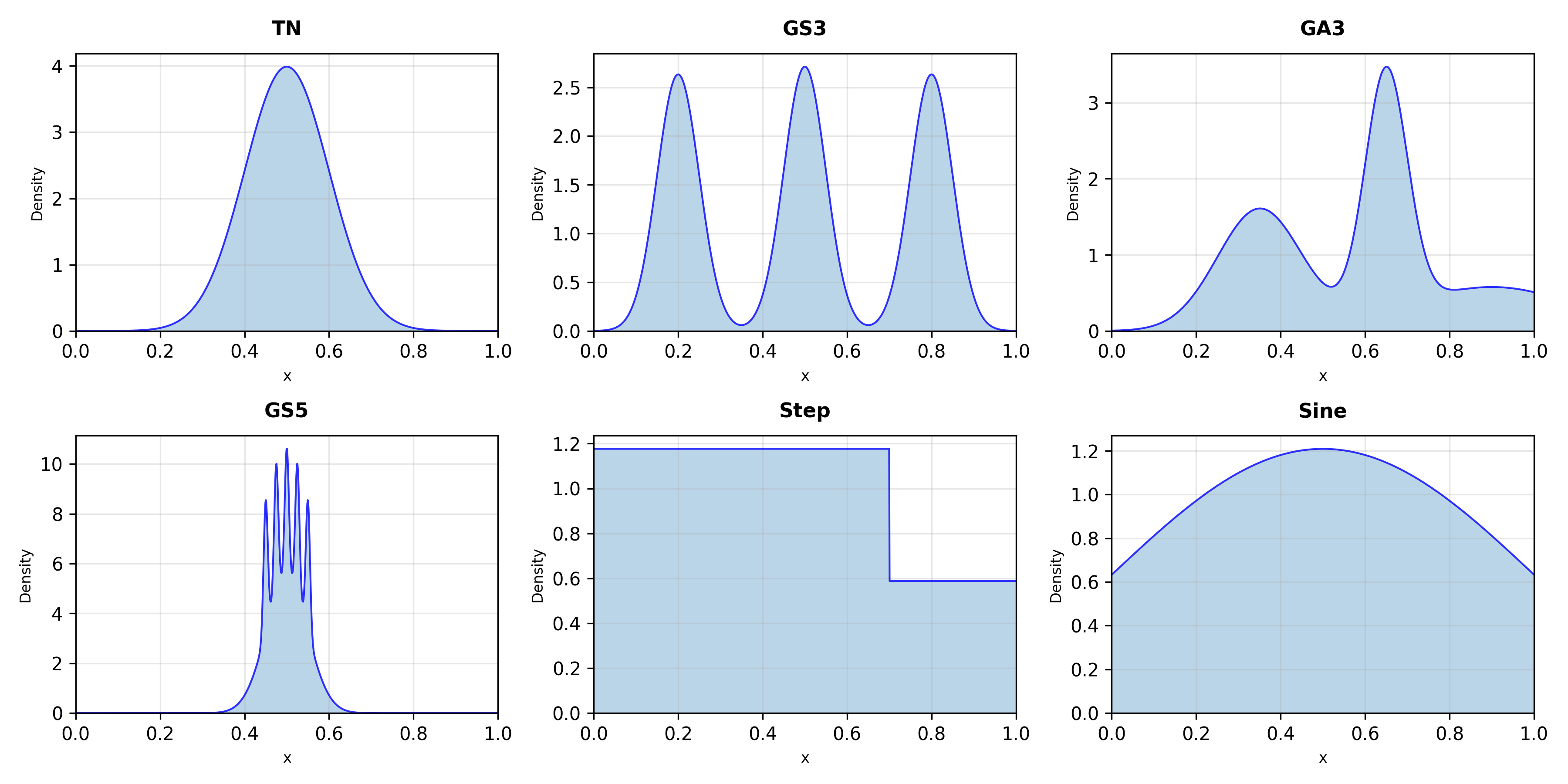
We consider nonparametric density estimation on a compact support. Given a random variable X ∼ P 0 , where P 0 is absolutely continuous, and i.i.d. samples x 1:n from P 0 , our goal is to estimate the true density function p 0 of the underlying distribution P 0 . This paper aims to provide a thorough theoretical analysis of univariate density estimation with a variational penalty and its application. The statistical model for P 0 will be nonparametric up till assuming that p 0 has support on a known interval [a, b] and is a cadlag function with a bounded variation norm, explained in detail below. Our framework is naturally extended to the multivariate case.
Nonparametric density estimation methods typically include kernel-based approaches, splines, and wavelet techniques. Kernel density estimation (KDE), despite its simplicity, suffers from several drawbacks: it poorly captures densities with rapidly varying regions and faces severe challenges due to the curse of dimensionality in the multivariate case.
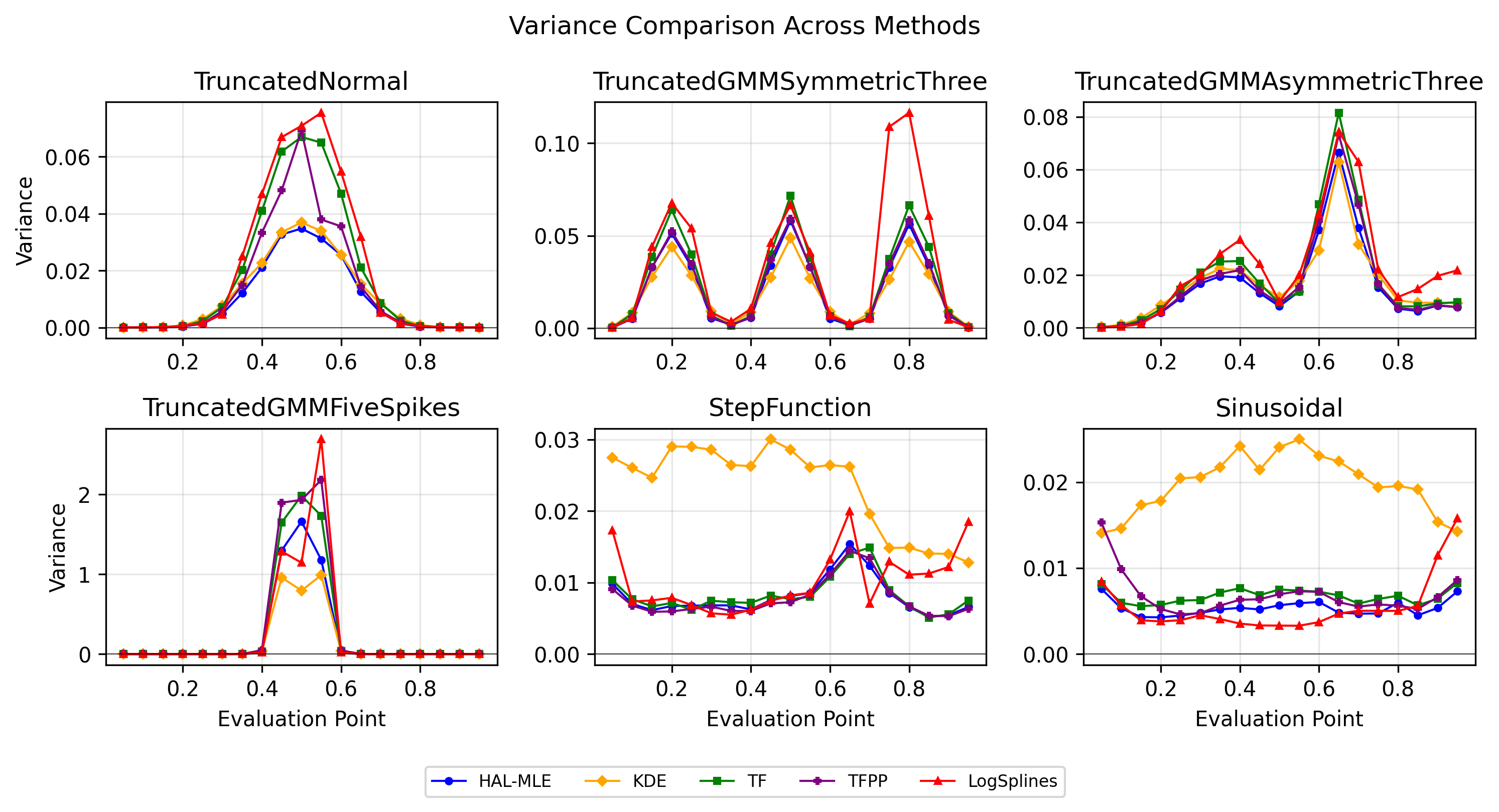
The first drawback of KDE arises from the fact that it is a linear smoother whose fitted values depend linearly on the observed responses. TV penalties have been introduced into spline regression to resolve the same problem with kernel regression, smoothing splines, etc. Mammen & Van De Geer (1997) developed local adaptive splines (LAS) demonstrating L 2 convergence, while Tibshirani (2014) formulated restricted LAS and trend filtering (TF) as general Lasso regressions. Later, the TV penalty was also introduced into the density estimation problem (Bak et al., 2021;Sadhanala et al., 2024). The TV-penalized logspline density estimation (PLSDE) proposed in Bak et al. (2021) is more relevant to our problem, and it intends to tackle the oscillation issue of logspines method (Kooperberg & Stone, 1991, 1992). Kooperberg & Stone (1992) employs an exponential link transformation ensuring positivity:
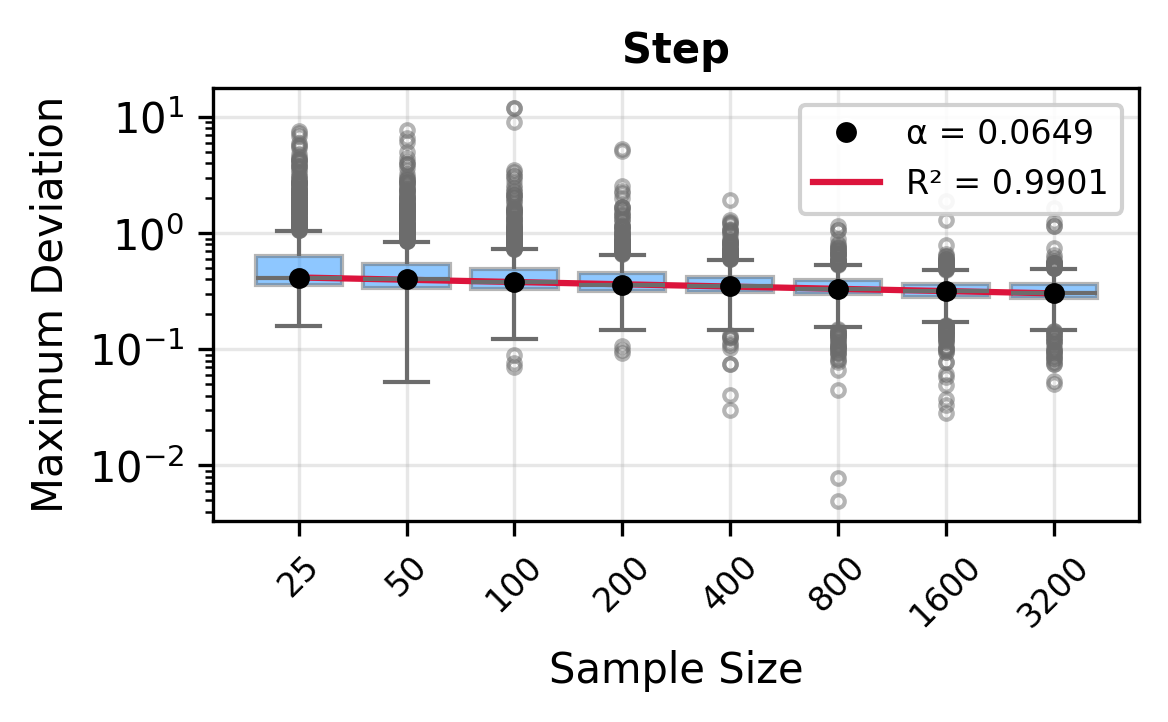
with splines f (x) = j β j ϕ j (x), typically cubic B-splines. Parameters are estimated via maximum likelihood, often guided by criteria such as AIC or BIC. A theoretical analysis of the logspline model is provided in Stone (1990). Bak et al. (2021) employed TV penalty and BIC criteria to provide univariate KL-divergence convergence analysis and its generalization to bivariate case. However, their method, Penalized Log-spline Density Estimation (PLSDE), encounters difficulties generalizing to multivariate settings without assuming higher-order continuity. This is a manifestation of the curse of dimensionality, and it falls into the same problem for the multivariate spline when the TV penalty is not introduced. Another problem is that PLSDE is limited to the uniform knots, which is not preferred in the multivariate case. An argument of the knot placement problem is provided in Section 2.
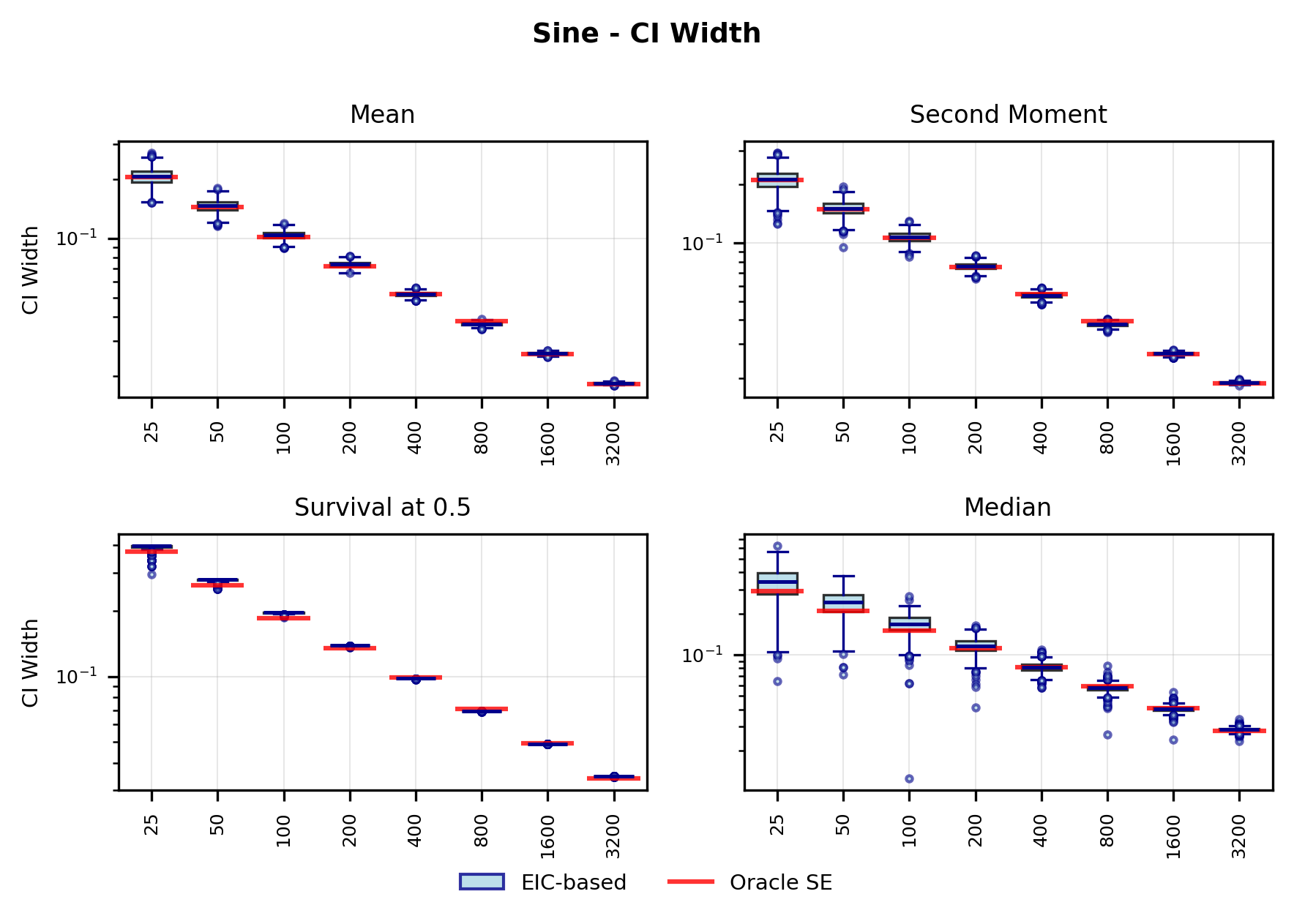
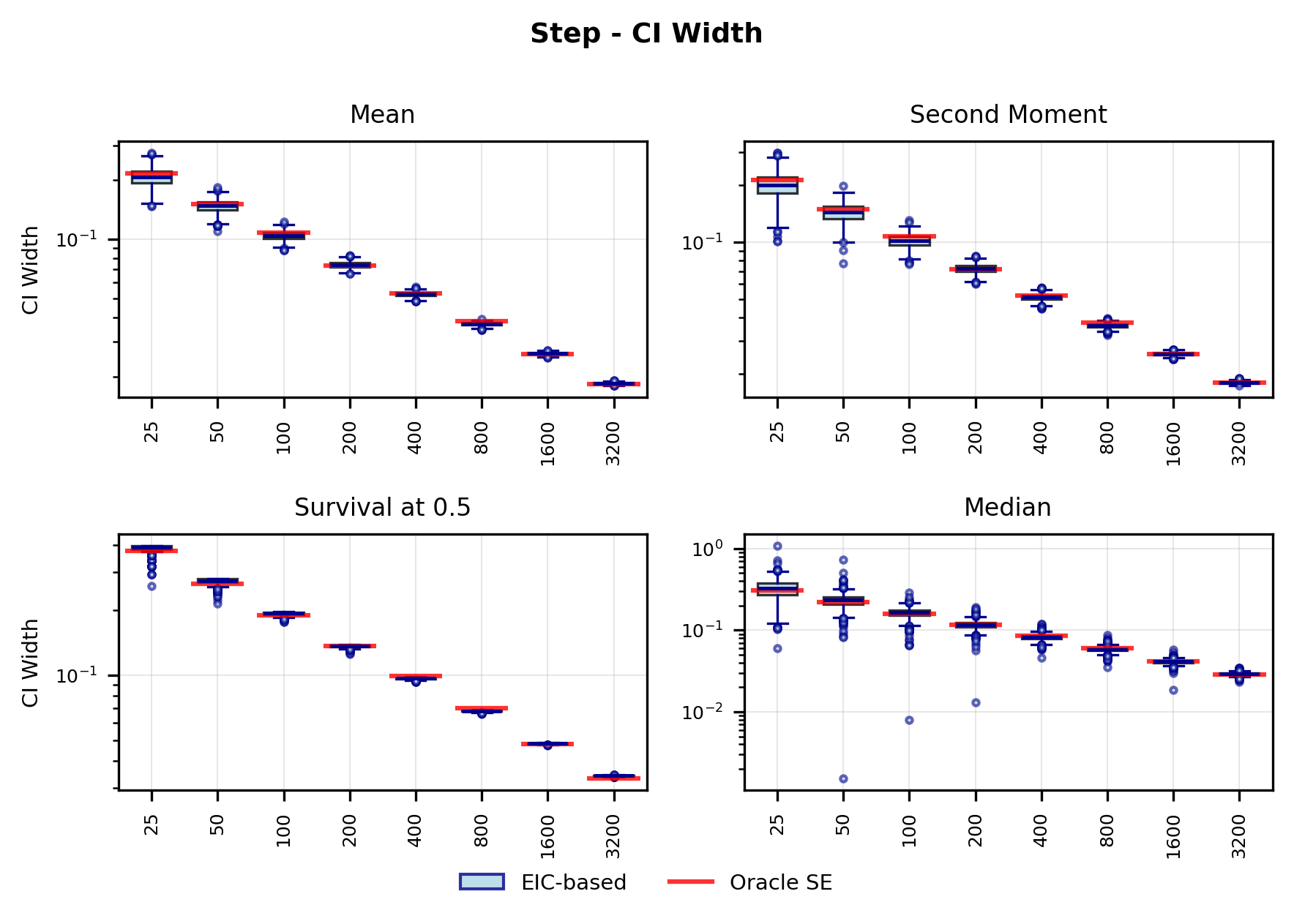
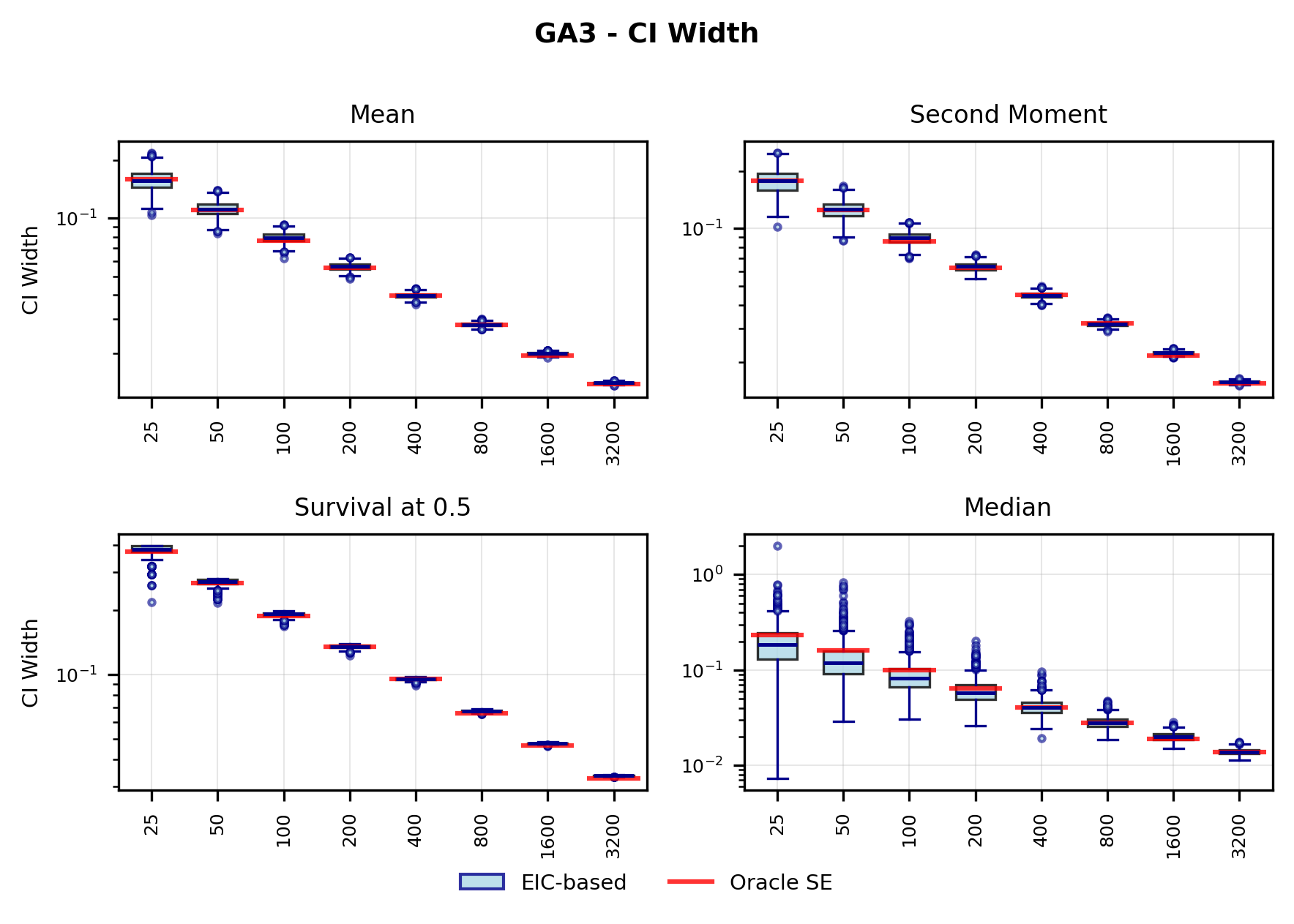
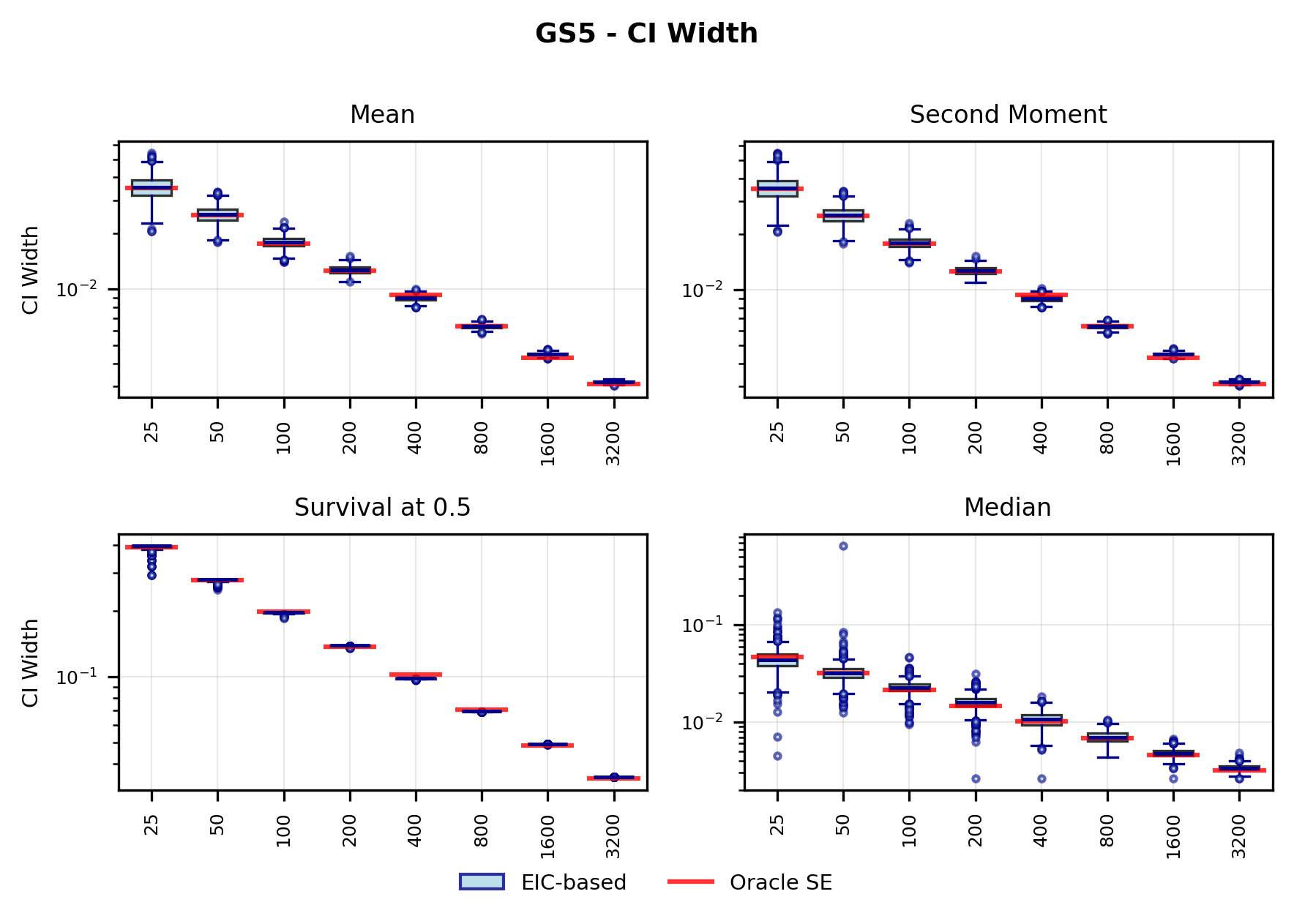
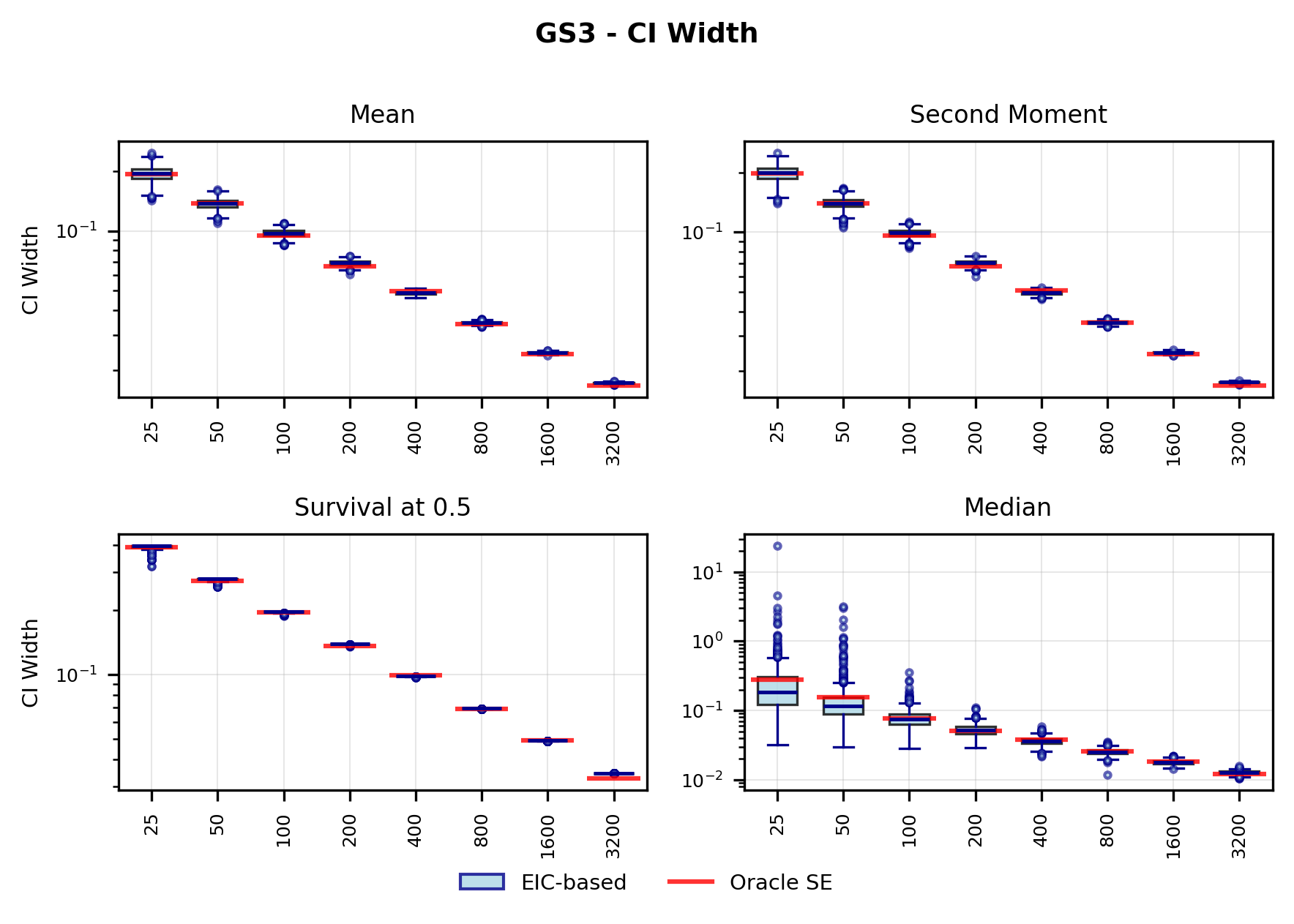
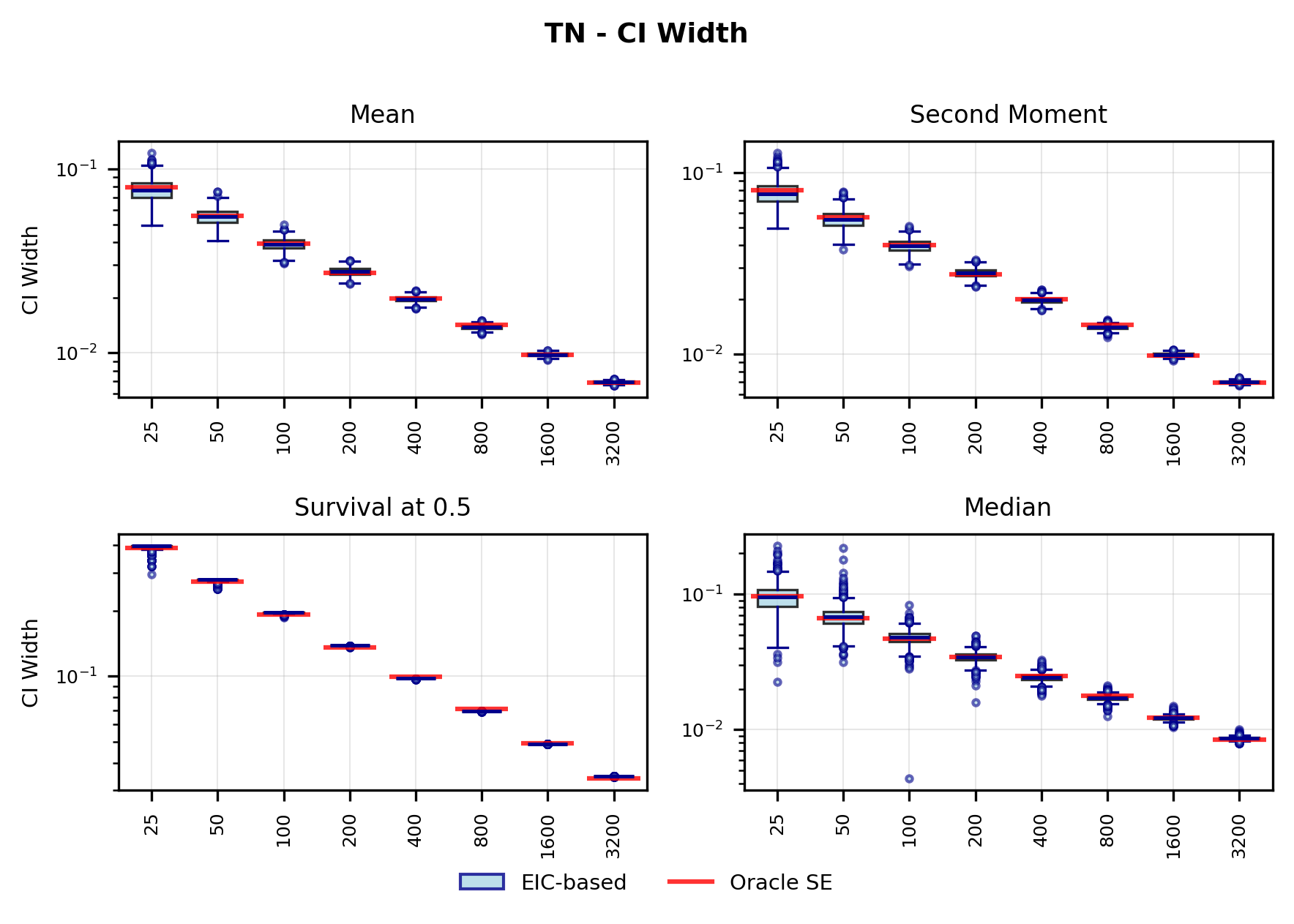
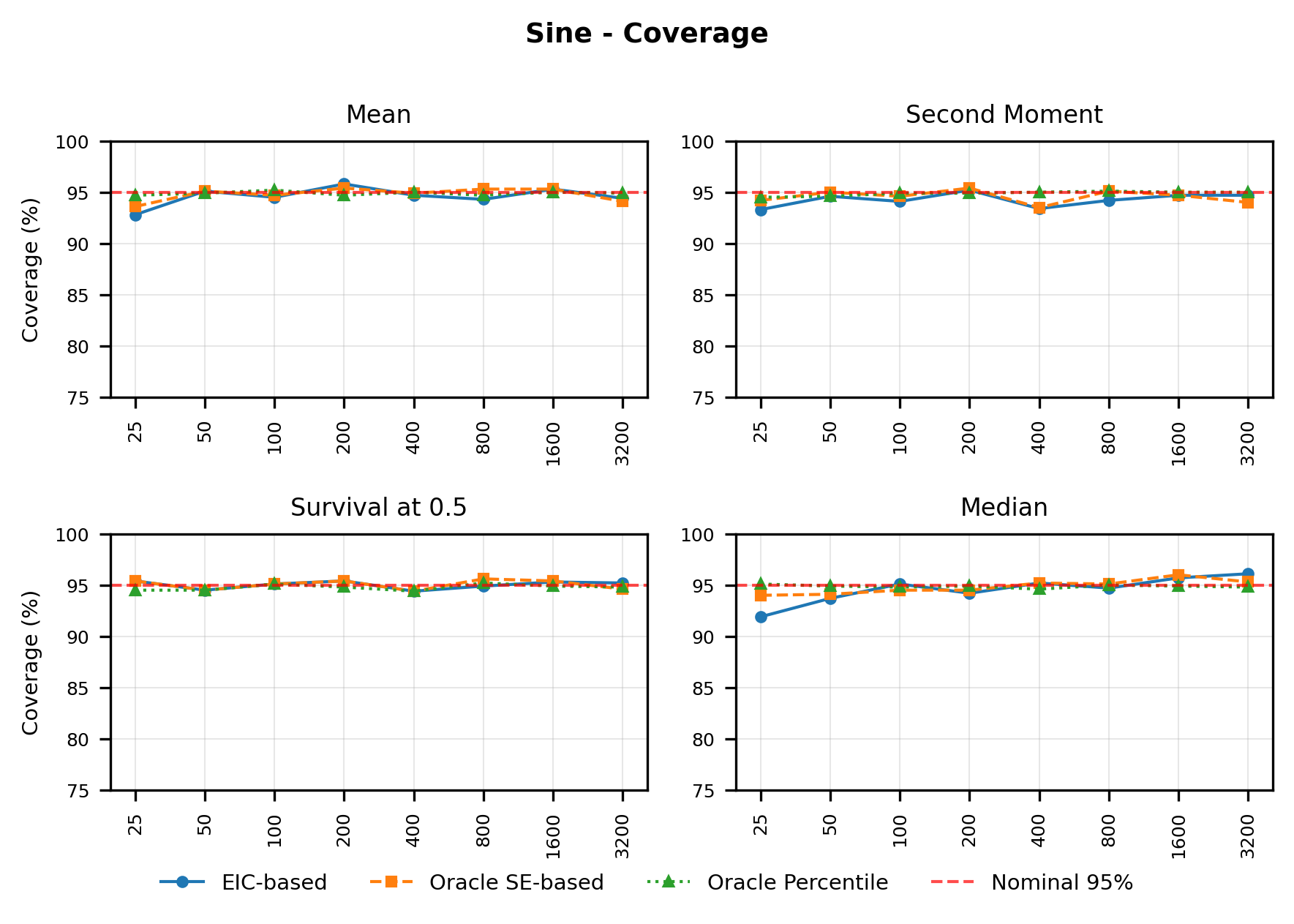
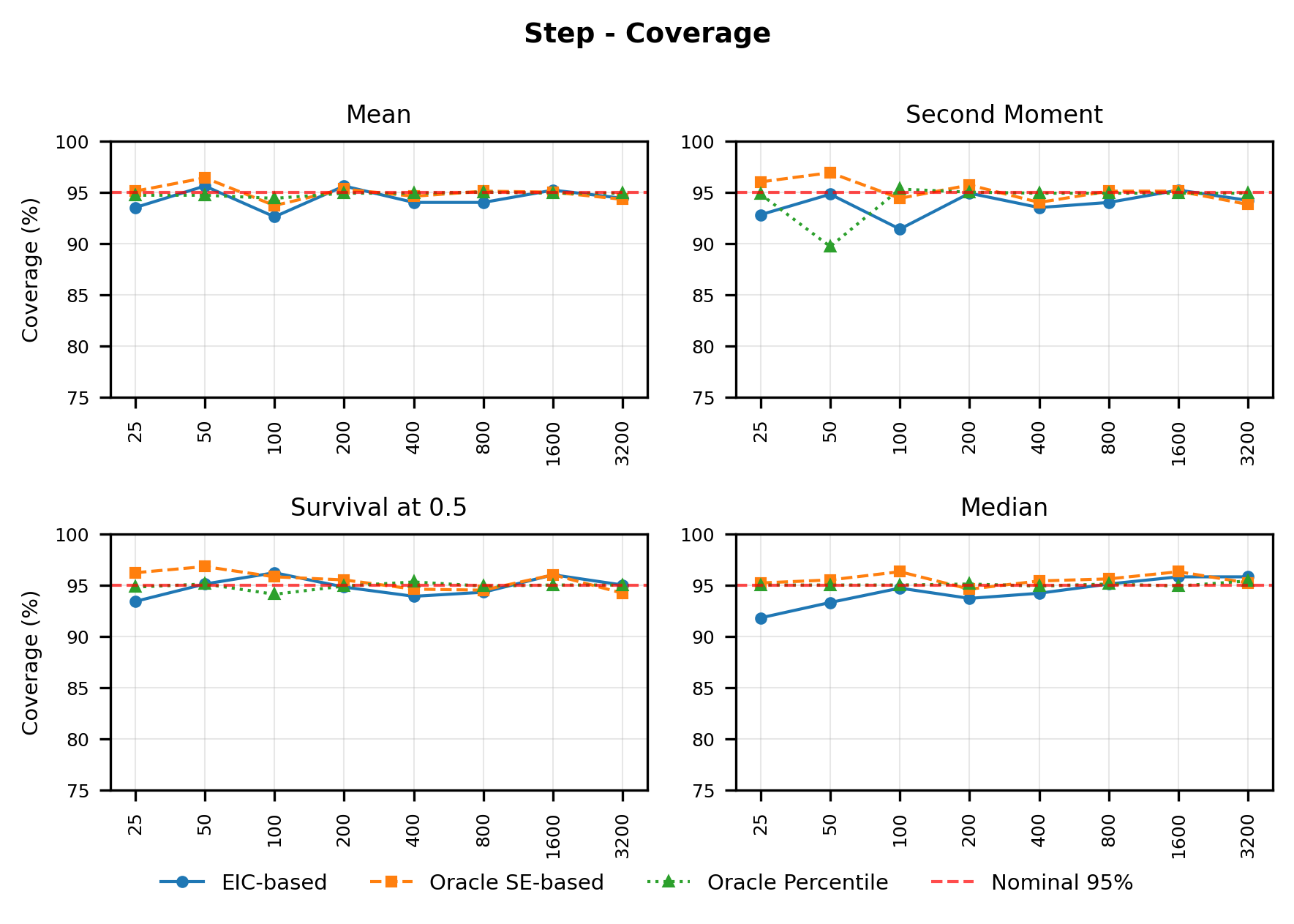
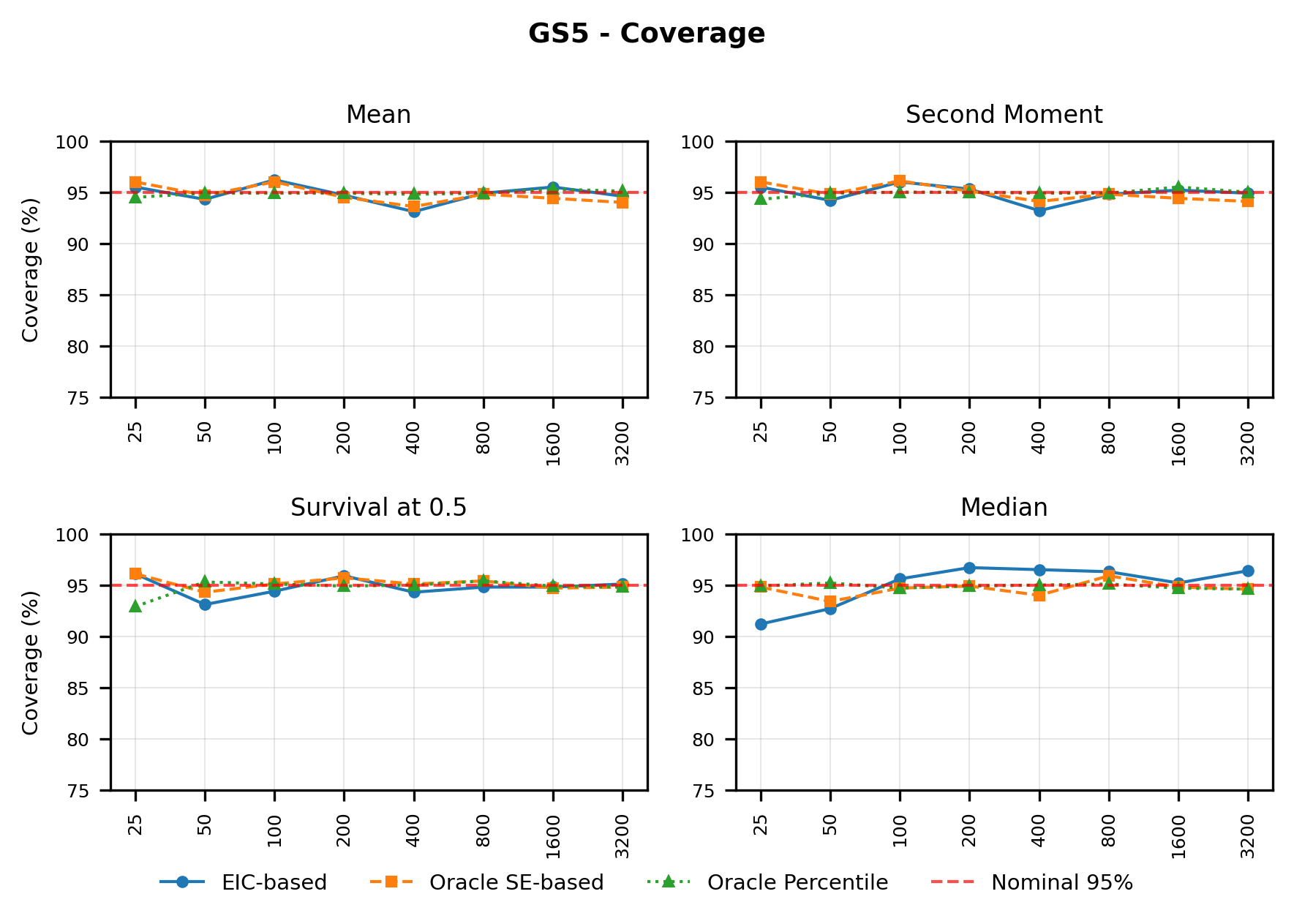
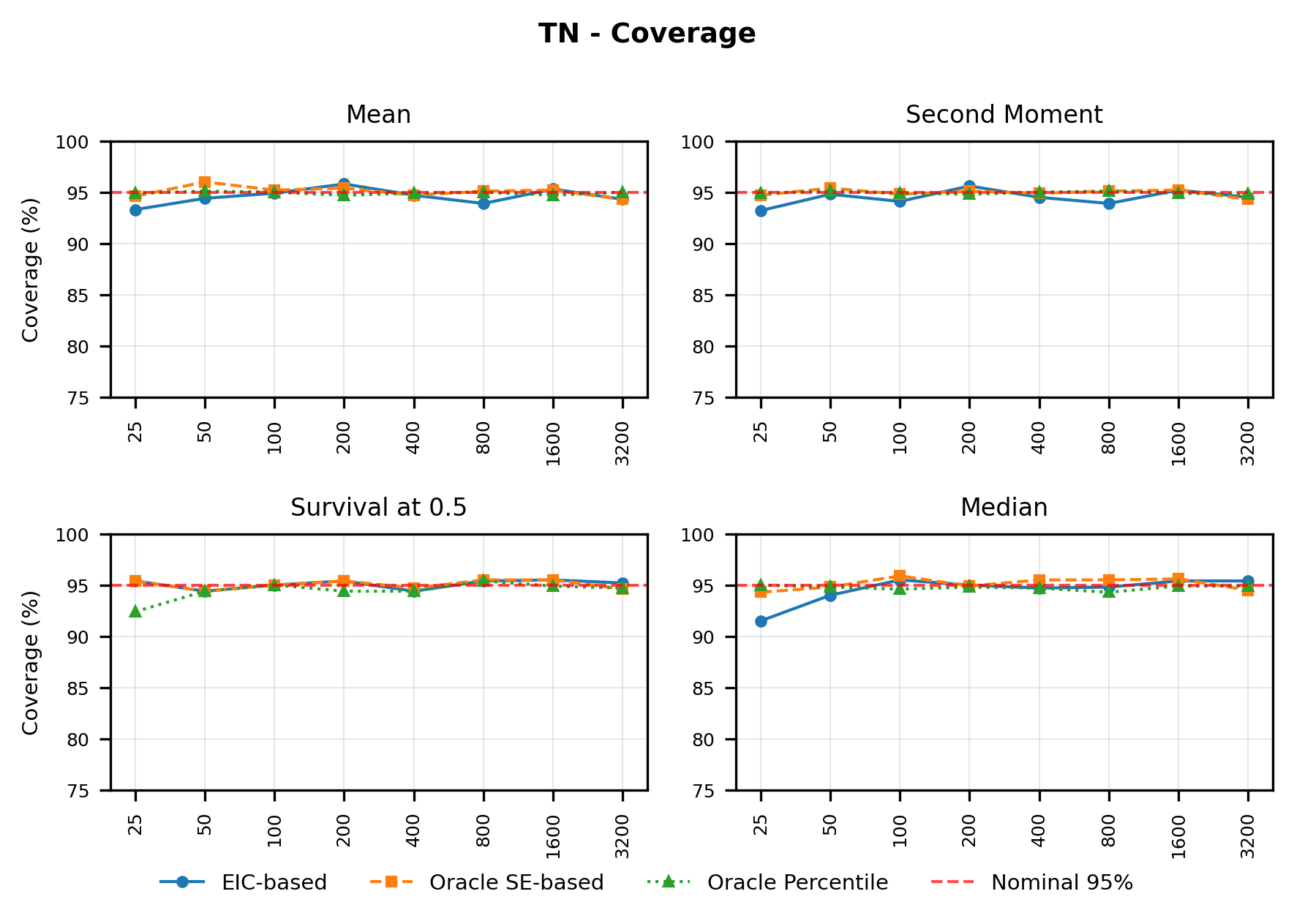
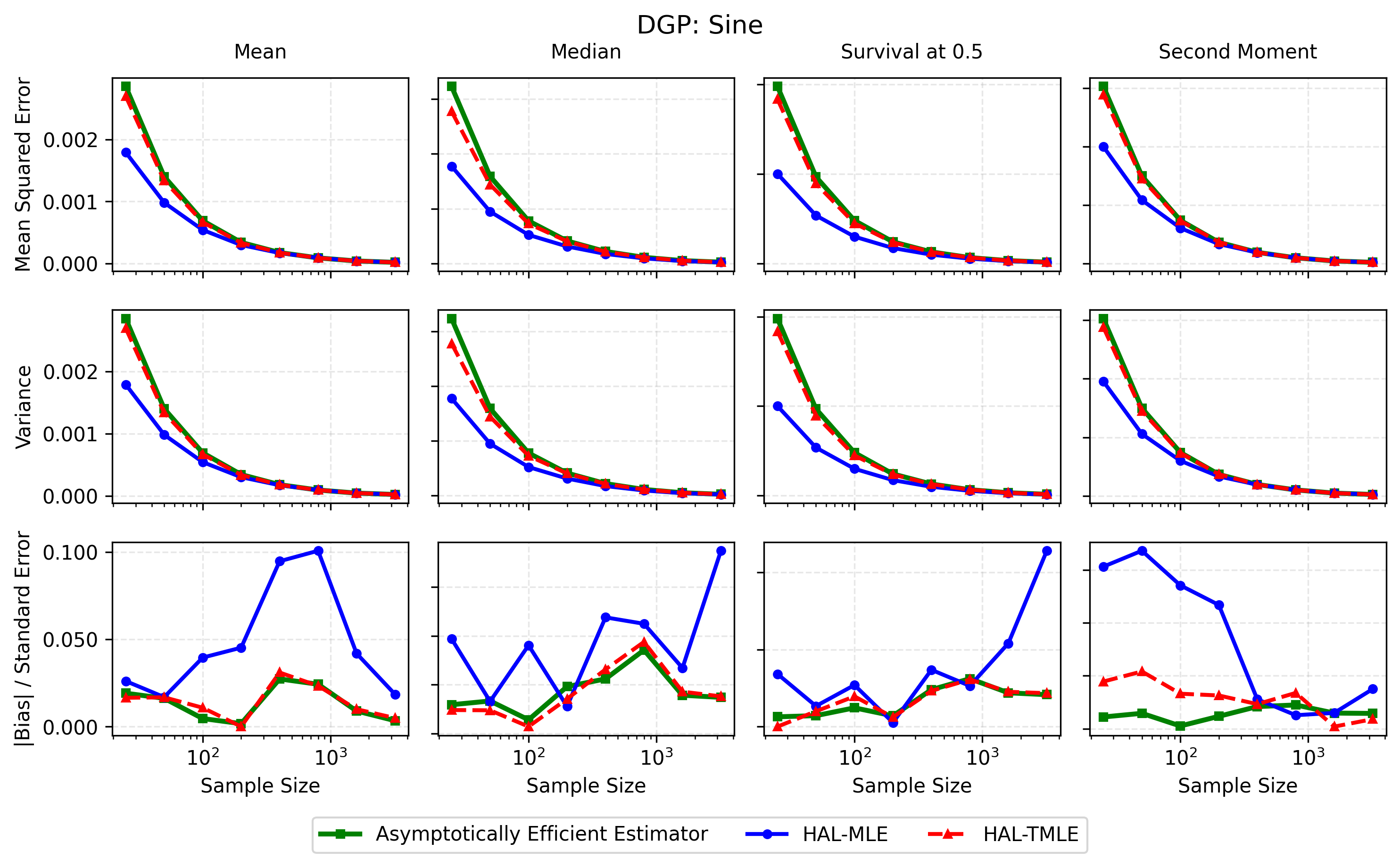
In contrast, the Highly Adaptive Lasso (HAL) proposed by van der Laan (2017) and practically introduced in Benkeser & Van Der Laan (2016) estimates multivariate càdlàg functions defined on [0, 1] d using a sectional variation norm, yielding uniform consistency and pointwise asymptotic normality without dimension-enforced smoothness assumptions. The density estimator based on HAL is referred to as HAL-MLE log-splines method. In this paper, we restrict our focus to univariate HAL-MLE in order to compare the performance with the classical log-spines methods and demonstrate theoretical connections to LAS and TF approaches, even though the HAL theory applies to the multivariate case. Other than density estimation, HAL-MLE also provide the asymptotic efficiency guarantee for general pathwise-differentiable statistical estimand, i.e. moments, survival probability, or percentiles, by a simple plug-in or a single-step TMLE procedure as developed in van der Laan (2017); van der Laan et al. (2023).
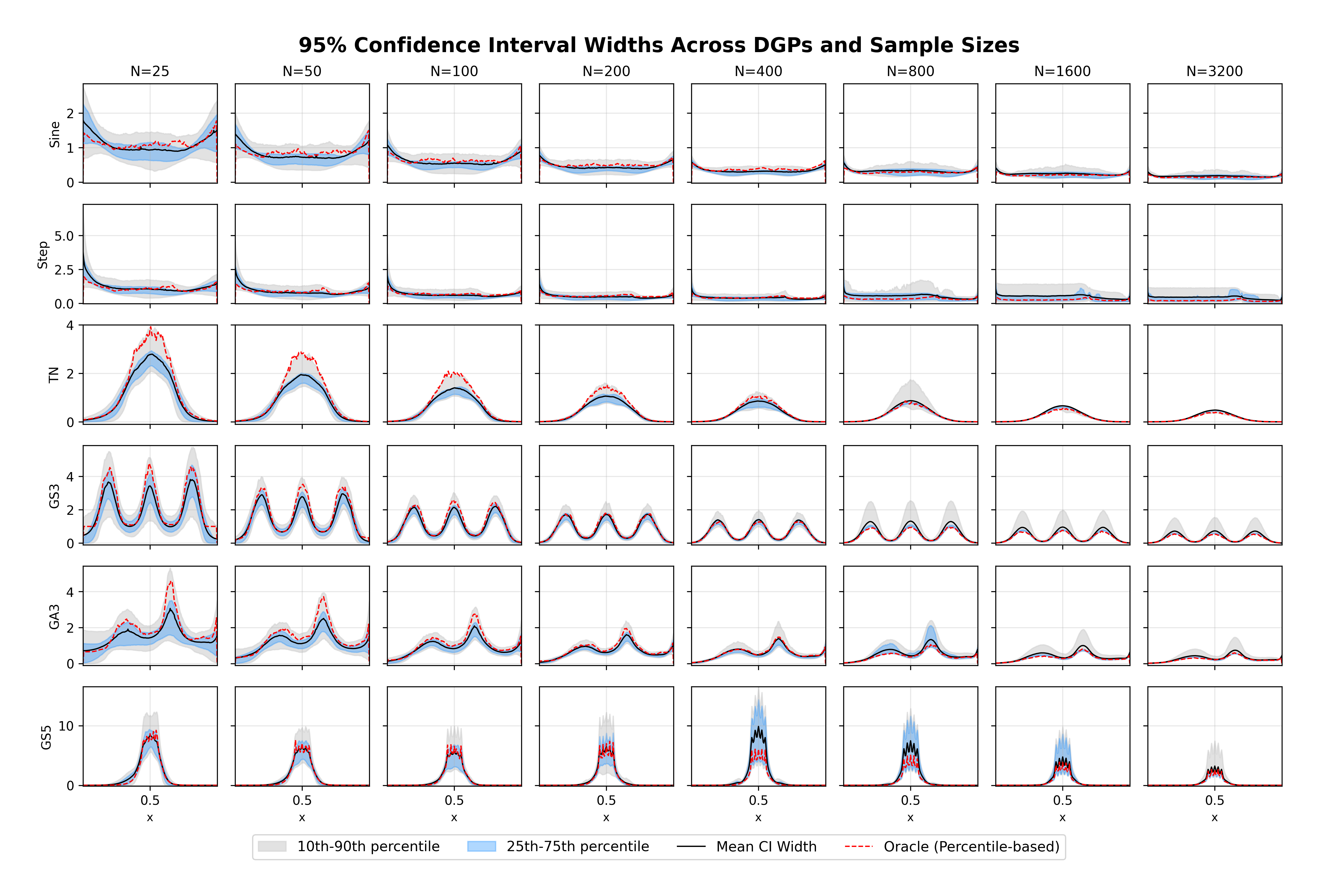
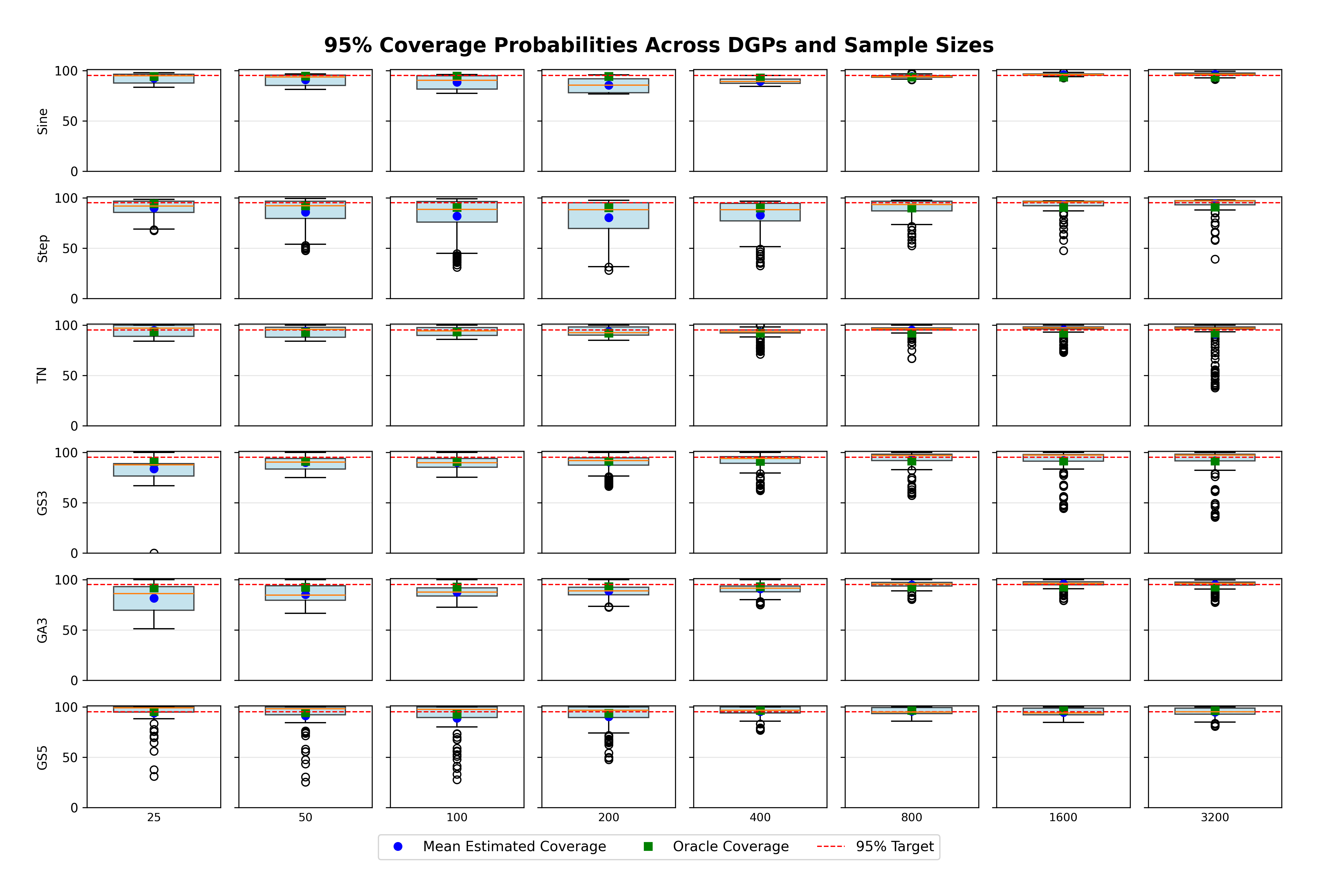
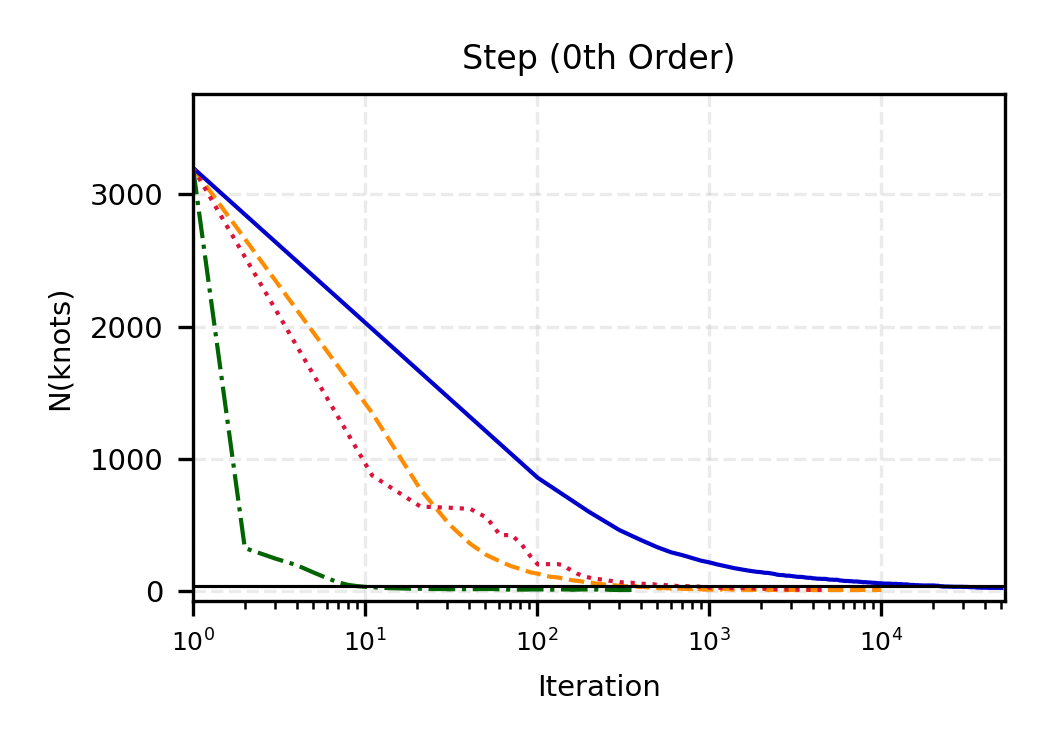
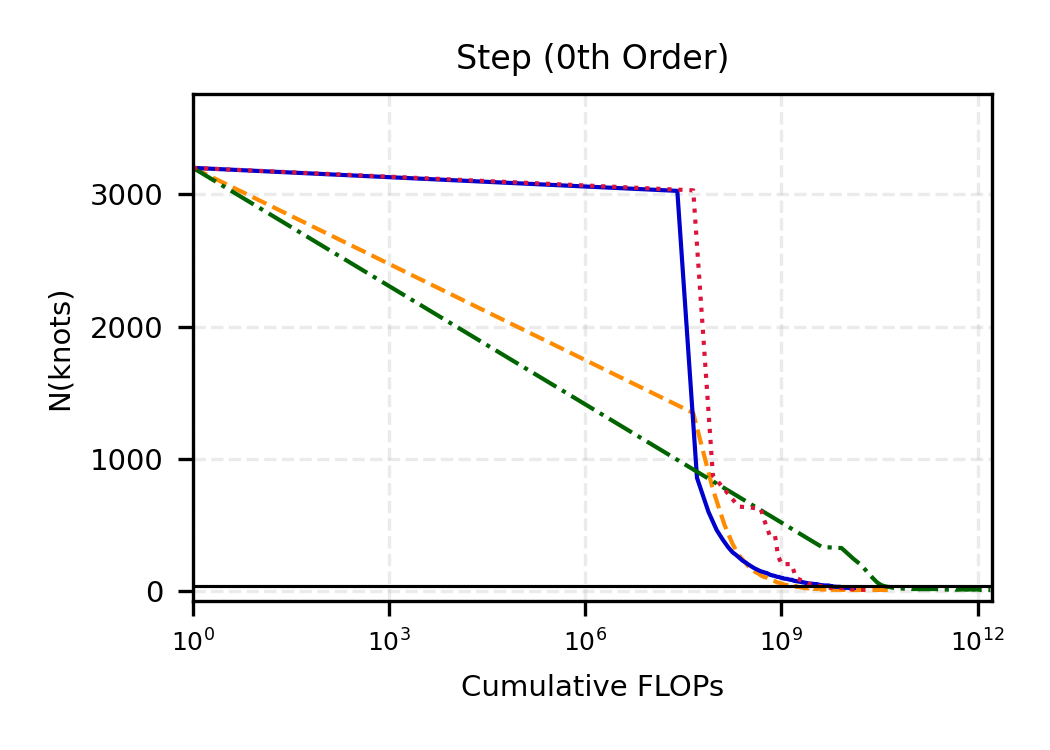
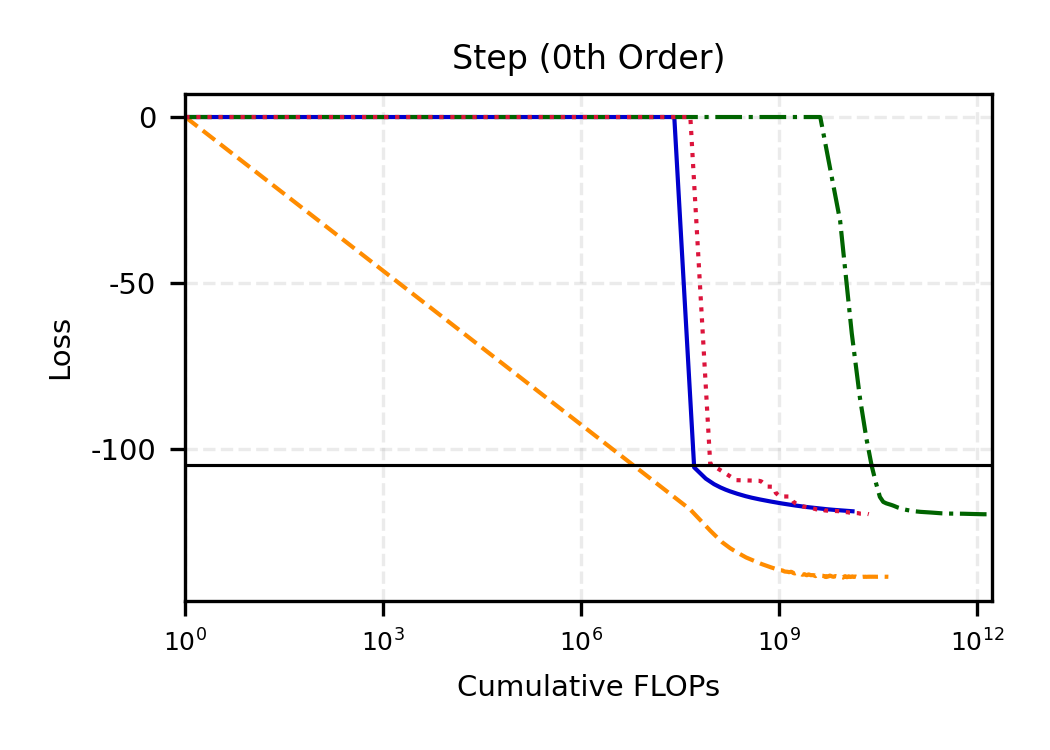
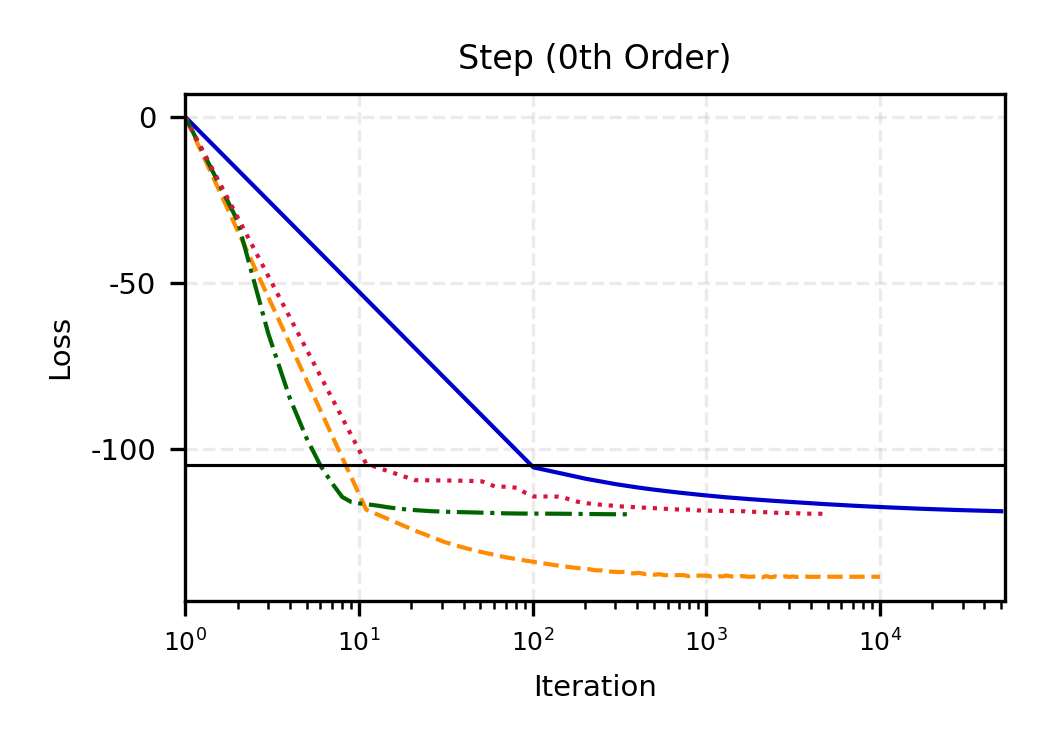
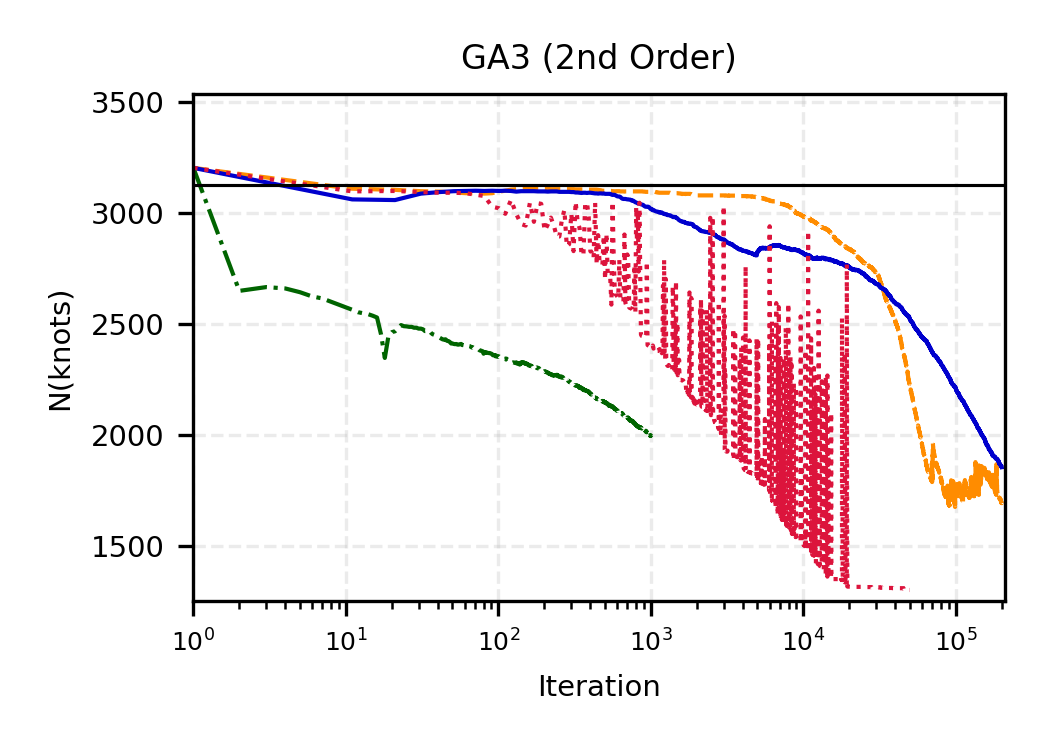
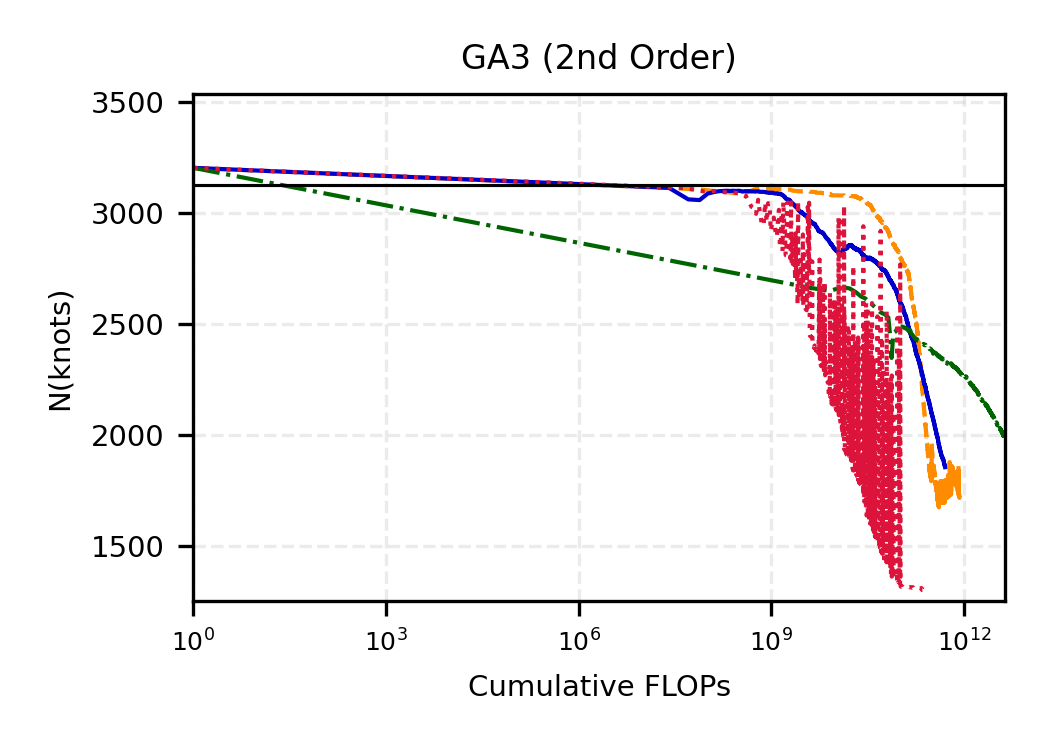
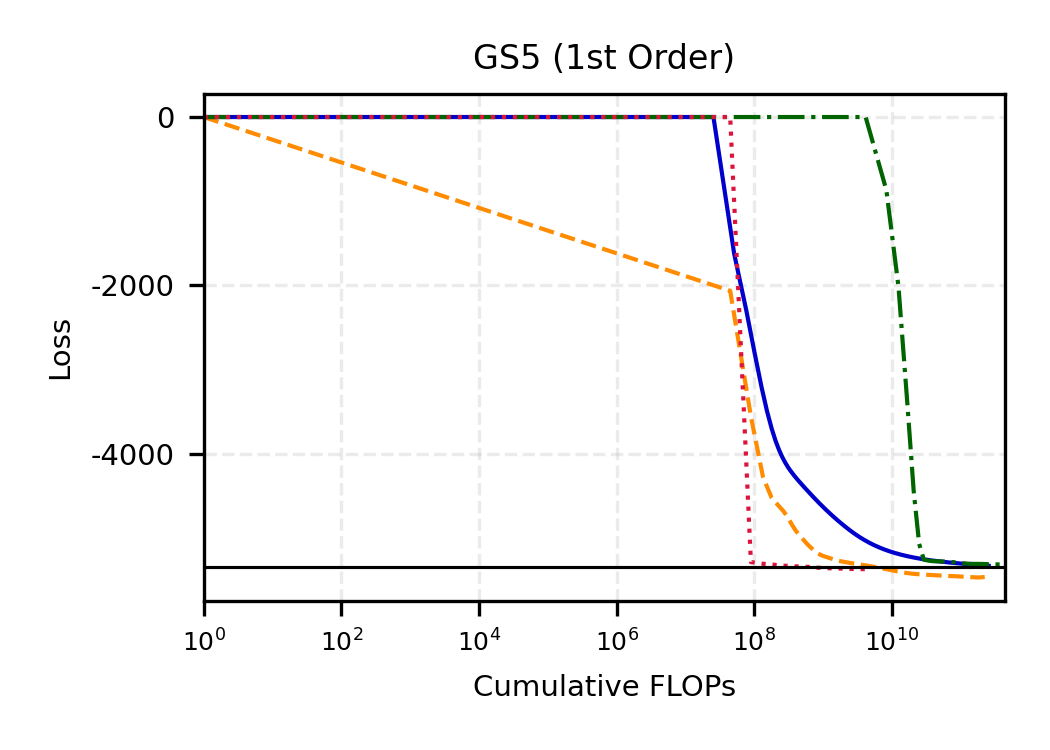
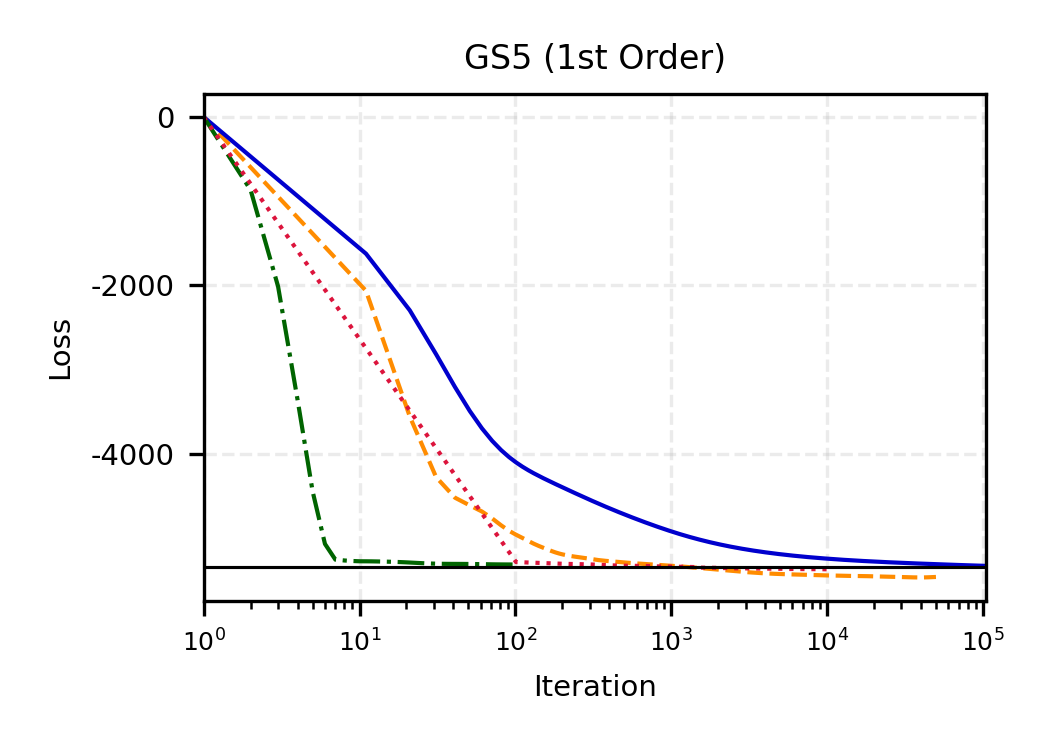
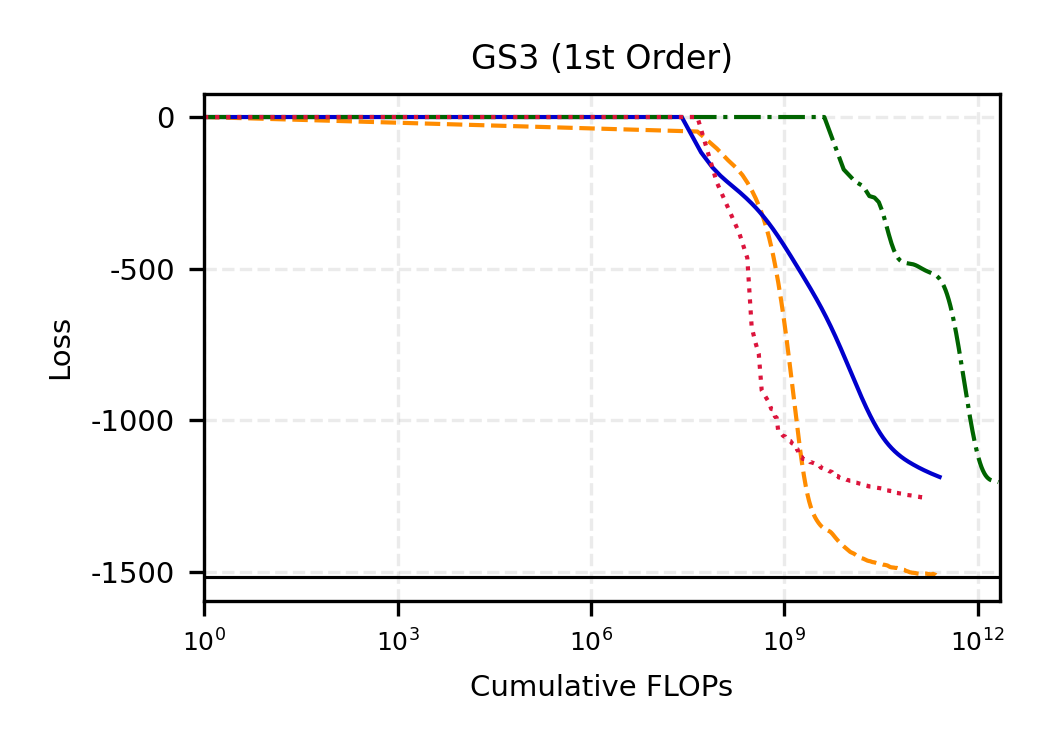
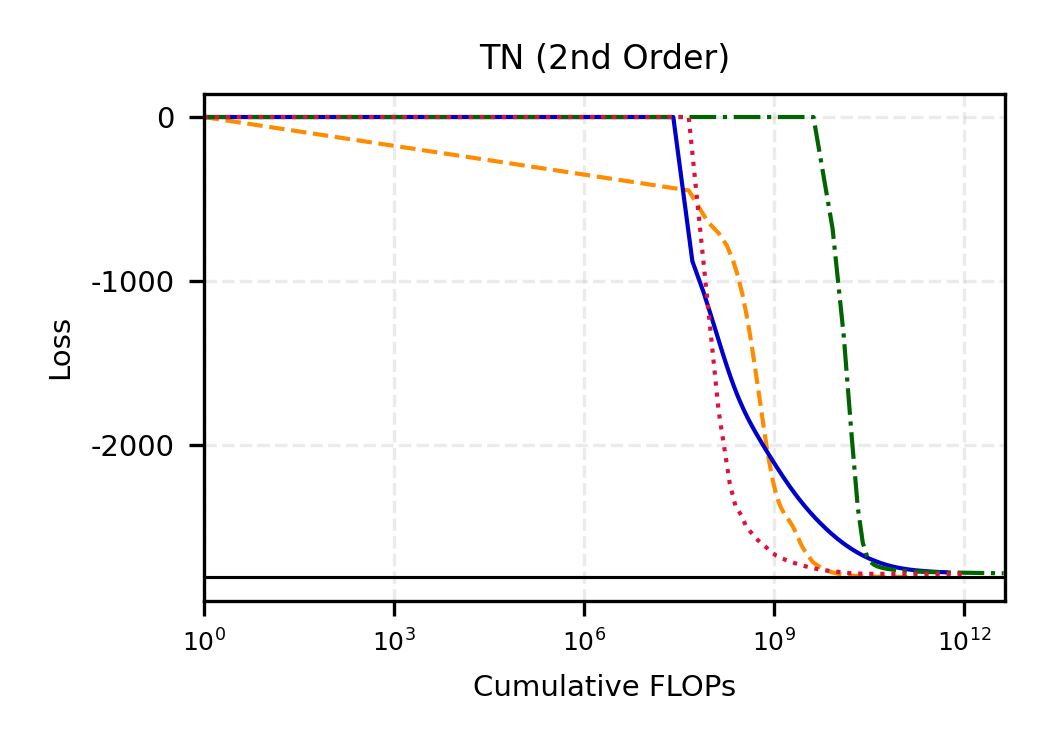
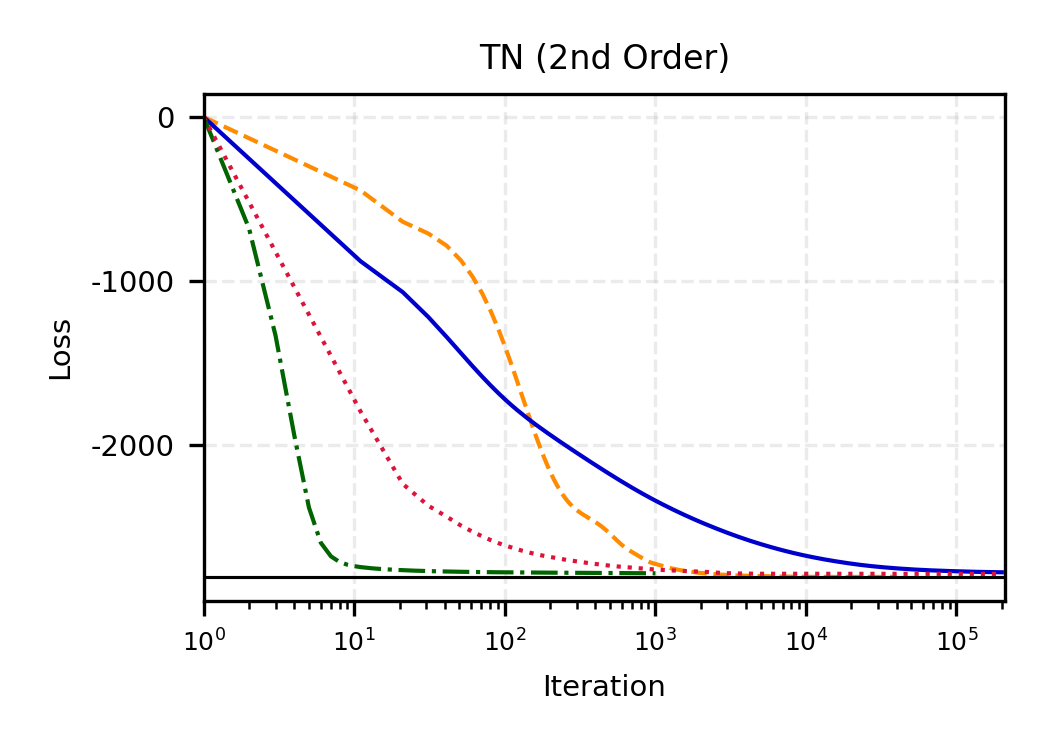
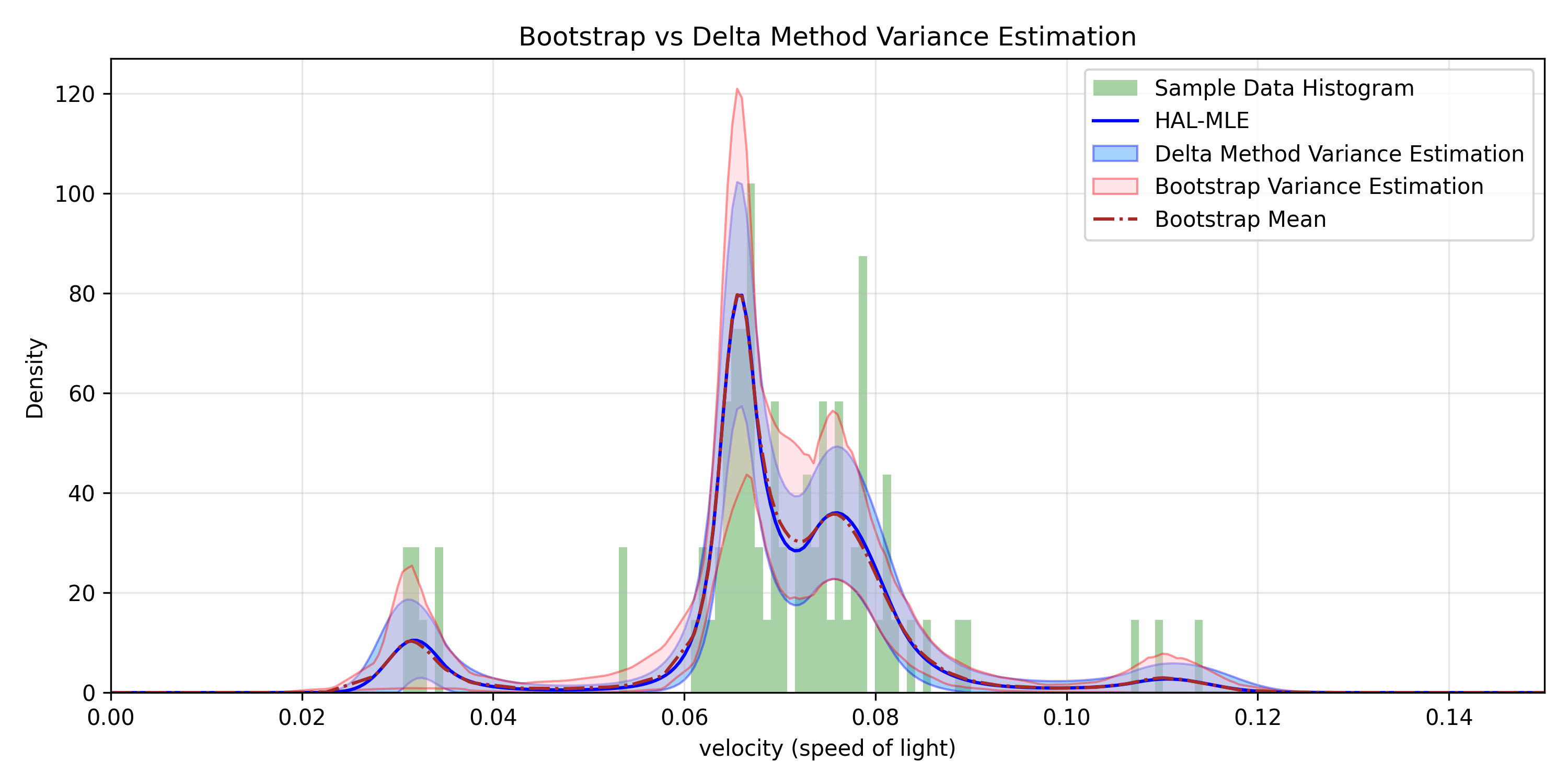
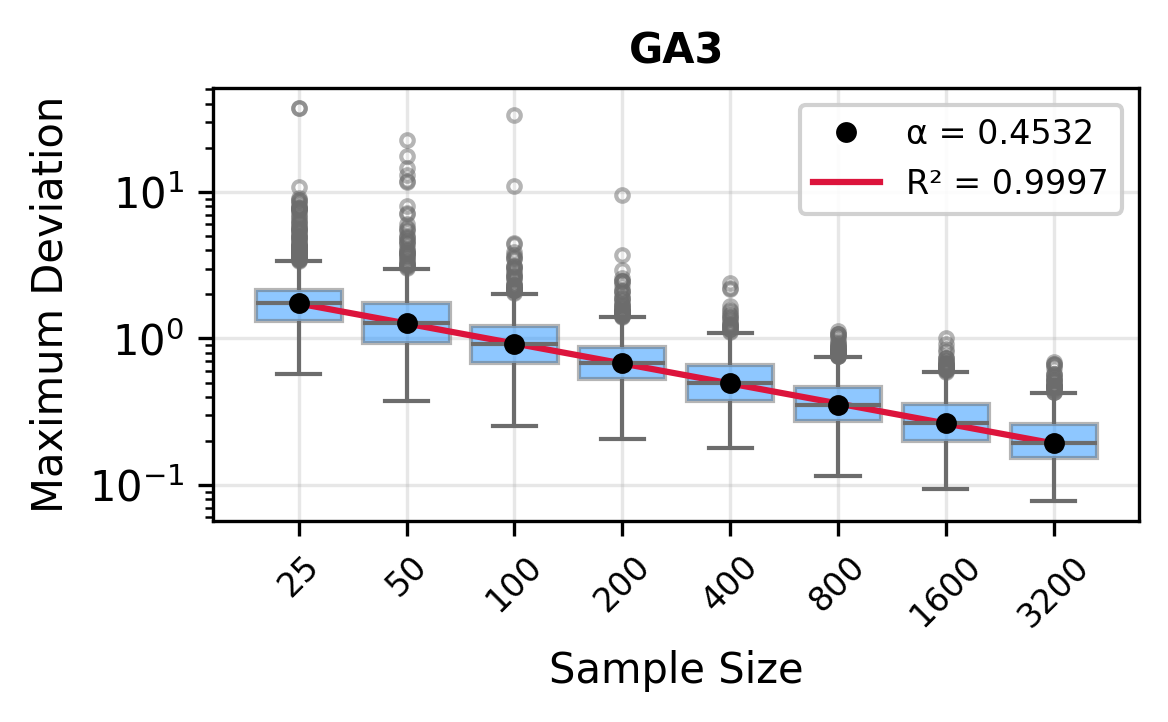
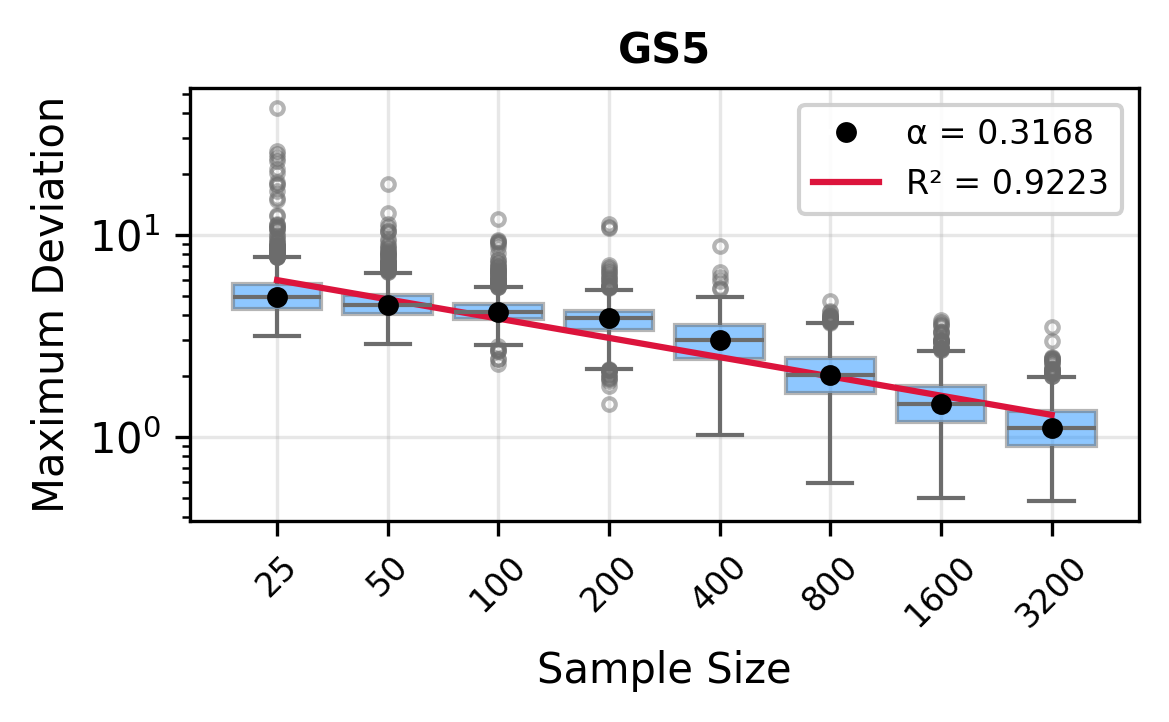
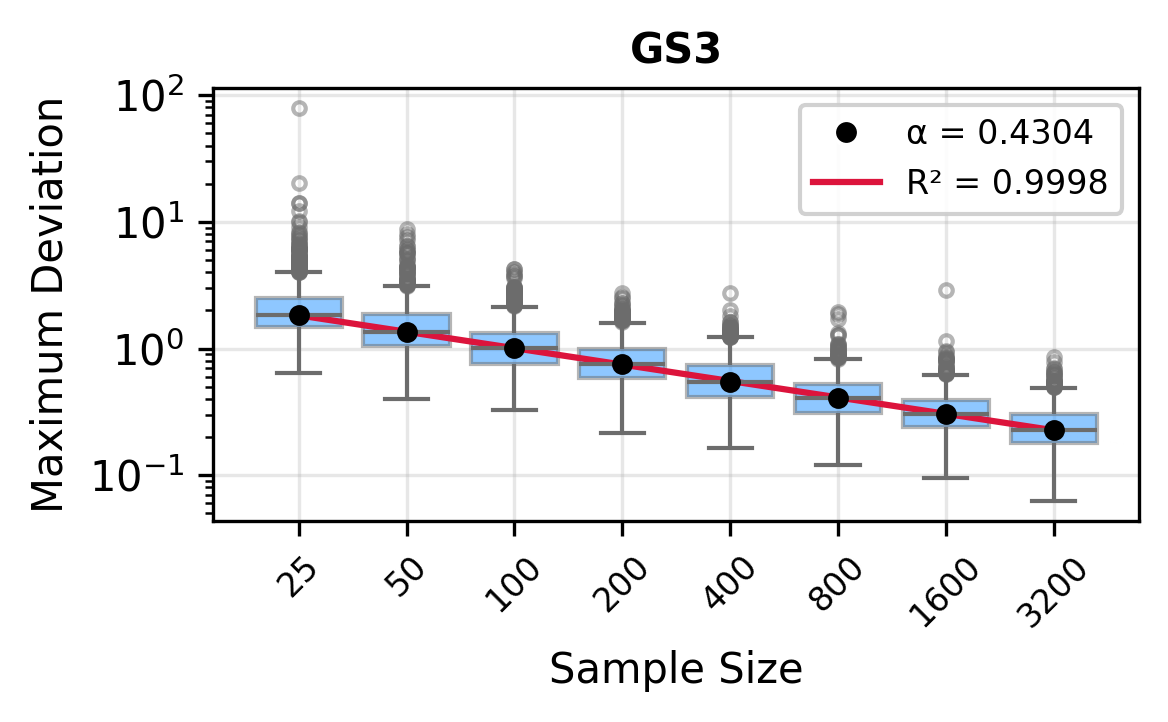
The remainder of this paper is organized as follows. Section 2 introduces the HAL assumption and establishes its connection to the classical bounded total variation (BTV) assumption underlying local adaptive splines. Section 3 presents the construction of HAL-MLE with the log-spline link function (Leonard, 1978;Silverman, 1982;Kooperberg & Stone, 1992;Rytgaard et al., 2023). Section 4 presents the theoretical results on its univariate L 2 convergence, asymptotic linearity, pointwise asymptotic normality, and uniform convergence. We also propose a variance estimator for the density based on the delta method. Section 5 considers the plug-in HAL-MLE and HAL-TMLE of pathwise differentiable statistical estimands, shown to achieve asymptotic efficiency with influence-curve-based variance estimation. Section 6 turns to computation, where we discuss the implementation of a series of optimization algorithms tailored for HAL-MLE. Section 7 reports simulation results, empirically verifying the theoretical guarantees mentioned in the previous sections, and comparing the finite sample performance of HAL-MLE with TF (applied to density estimation), log-splines, and
…(Full text truncated)…
This content is AI-processed based on ArXiv data.