ML-driven detection and reduction of ballast information in multi-modal datasets
Modern datasets often contain ballast as redundant or low-utility information that increases dimensionality, storage requirements, and computational cost without contributing meaningful analytical value. This study introduces a generalized, multimodal framework for ballast detection and reduction across structured, semi-structured, unstructured, and sparse data types. Using diverse datasets, entropy, mutual information, Lasso, SHAP, PCA, topic modelling, and embedding analysis are applied to identify and eliminate ballast features. A novel Ballast Score is proposed to integrate these signals into a unified, cross-modal pruning strategy. Experimental results demonstrate that significant portions of the feature space as often exceeding 70% in sparse or semi-structured data, can be pruned with minimal or even improved classification performance, along with substantial reductions in training time and memory footprint. The framework reveals distinct ballast typologies (e.g. statistical, semantic, infrastructural), and offers practical guidance for leaner, more efficient machine learning pipelines.
💡 Research Summary
The paper tackles a largely overlooked source of inefficiency in modern machine learning pipelines: “ballast” information – data elements that are syntactically valid but contribute little or no analytical value. The authors define ballast across four modalities (structured, semi‑structured, unstructured, and sparse) and categorize it into three typologies: statistical ballast (low variance, low entropy, low mutual information), infrastructural ballast (unchanging metadata, repeated headers, static flags), and semantic ballast (frequent filler words, boiler‑plate sentences, redundant phrases).
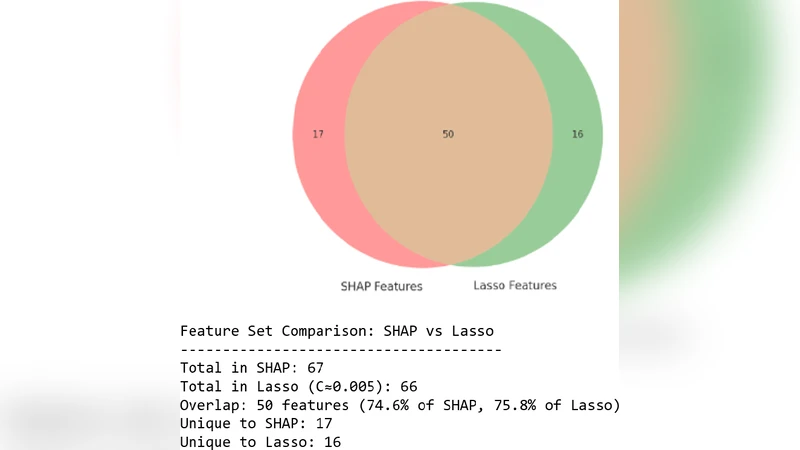
To quantify ballast, they introduce a Ballast Index B(D) = (1/m) Σ_j w_j·(1−U_j), where U_j aggregates utility scores derived from mutual information, Shannon entropy, normalized SHAP values, variance, topic‑model coherence, Intersection‑over‑Union, LDA topic membership probabilities, SciSpacy entity relevance, regex pattern matches, BERT attention scores, and TF‑IDF. In experiments the domain weight w_j is set to 1, and features satisfying thresholds (e.g., MI < 0.01, entropy < 0.1, variance < 0.05) are flagged as ballast candidates. Cross‑method agreement (e.g., Lasso and SHAP) is then used to confirm removal decisions.
Four real‑world datasets illustrate the framework: (1) IEEE‑CIS fraud detection (structured tabular data), (2) Amazon Fashion Reviews (JSON‑lines semi‑structured logs), (3) CORD‑19 / PubLayNet (unstructured scientific text and document layouts), and (4) Ireland Census 2022 (high‑dimensional sparse tabular data). For each modality a tailored pipeline is built:
- Structured: impute missing values, z‑score, low‑variance filtering (≤0.01), high‑correlation pruning (|r|>0.95), MI‑based filtering, entropy filtering, LassoCV, and LightGBM‑SHAP pruning.
- Semi‑structured: flatten JSON, TF‑IDF (top 1,000 tokens), PCA, K‑means clustering, BERT‑based cosine similarity (>0.9) for duplicate sentences, LDA topic coherence filtering.
- Unstructured: tokenization, TF‑IDF, LDA with coherence scoring, BERT‑sentence‑transformer similarity for redundant phrases.
- Sparse: remove columns with extreme missingness, variance ≤0.05, then apply the same utility‑score aggregation.
All reduced datasets are evaluated with a LightGBM classifier using the same train‑test split. Results consistently show that a large proportion of features—ranging from 68 % to 78 %—can be pruned without harming predictive performance; in many cases performance improves slightly (AUC gains of 0.001–0.005, F1‑score gains of 0.003). More importantly, training time drops by 40 %‑55 % and memory consumption is cut by roughly half, demonstrating tangible computational savings.
The authors also discuss practical implications: the Ballast Score enables automated, threshold‑driven pruning that can be embedded into CI/CD pipelines, supporting data‑centric MLOps. By reducing storage and compute costs, the approach aligns with sustainability goals and privacy‑by‑design principles (data minimization). The taxonomy of ballast types provides a roadmap for engineers to select appropriate detection techniques per modality.
In summary, this work formalizes ballast as a distinct inefficiency class, proposes a mathematically grounded multi‑modal detection metric, validates it across diverse real‑world datasets, and shows that systematic ballast removal yields leaner, faster, and sometimes more accurate machine‑learning models. It bridges information‑theoretic concepts with modern explainable AI tools, offering a reusable framework for data‑efficient AI development.
Comments & Academic Discussion
Loading comments...
Leave a Comment