On the Mechanism and Dynamics of Modular Addition: Fourier Features, Lottery Ticket, and Grokking
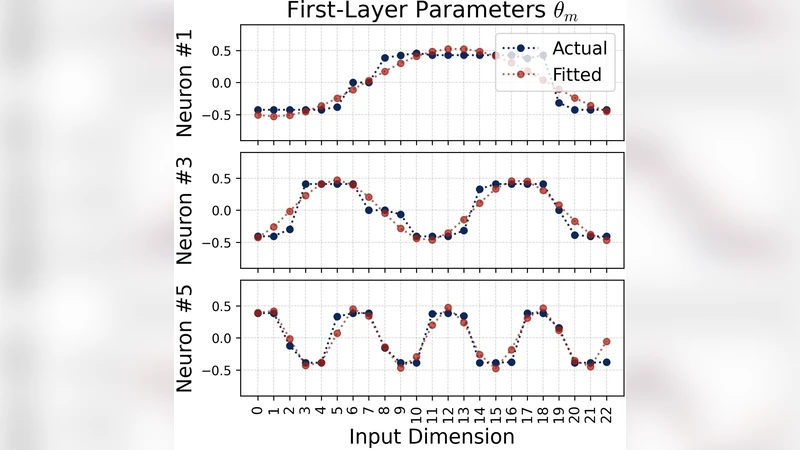
We present a comprehensive analysis of how two-layer neural networks learn features to solve the modular addition task. Our work provides a full mechanistic interpretation of the learned model and a theoretical explanation of its training dynamics. While prior work has identified that individual neurons learn single-frequency Fourier features and phase alignment, it does not fully explain how these features combine into a global solution. We bridge this gap by formalizing a diversification condition that emerges during training when overparametrized, consisting of two parts: phase symmetry and frequency diversification. We prove that these properties allow the network to collectively approximate a flawed indicator function on the correct logic for the modular addition task. While individual neurons produce noisy signals, the phase symmetry enables a majority-voting scheme that cancels out noise, allowing the network to robustly identify the correct sum. Furthermore, we explain the emergence of these features under random initialization via a lottery ticket mechanism. Our gradient flow analysis proves that frequencies compete within each neuron, with the “winner” determined by its initial spectral magnitude and phase alignment. From a technical standpoint, we provide a rigorous characterization of the layer-wise phase coupling dynamics and formalize the competitive landscape using the ODE comparison lemma. Finally, we use these insights to demystify grokking, characterizing it as a three-stage process involving memorization followed by two generalization phases, driven by the competition between loss minimization and weight decay.
💡 Research Summary
The paper provides a thorough mechanistic and dynamical analysis of how a two‑layer fully‑connected neural network learns to solve the modular addition task, i.e., to predict (x + y) mod p from integer inputs x and y. Building on prior observations that individual hidden units converge to single‑frequency Fourier features with a specific phase, the authors identify a gap: the global solution cannot be explained by isolated neurons alone. To close this gap they introduce a “diversification condition” consisting of two complementary properties that emerge during training when the model is heavily over‑parameterized.
First, phase symmetry: neurons that share the same frequency tend to develop opposite phases (0 and π). When such pairs are summed, their noisy components cancel, leaving a clean signal proportional to the cosine of that frequency. Second, frequency diversification: the network distributes its capacity across all p distinct frequencies needed to distinguish the p possible residues of the sum. Together these properties enable the network to collectively approximate a “flawed indicator function” that is essentially the correct modular addition logic plus a small residual error.
The authors formalize the learning dynamics using continuous‑time gradient flow. For each neuron i they write the output as
h_i(t)=a_i(t)·cos(ω_i·(x+y)+φ_i(t)),
and derive coupled ODEs for the amplitude a_i and phase φ_i that include both the loss gradient and an L2 weight‑decay term λ. By applying an ODE comparison lemma they prove a winner‑takes‑all competition among frequencies: the frequency whose initial spectral magnitude |Â_i(0)| is largest grows fastest and suppresses the others. The phase dynamics quickly drive φ_i toward either 0 or π, thereby establishing the phase‑symmetry automatically from random initialization.
When the network output is taken as the sign of the sum of hidden activations, the majority‑voting effect of phase‑symmetric pairs eliminates the per‑neuron noise. The remaining signal matches the modular addition indicator up to a small bias that vanishes as the hidden width and the weight‑decay strength increase. This provides a rigorous explanation of how many noisy Fourier components can be combined into a reliable global solution.
A major contribution of the work is the explanation of grokking, the phenomenon where a model first memorizes the training set (loss drops sharply while validation accuracy stays low) and then suddenly generalizes after a long plateau. The authors decompose grokking into three stages:
- Memorization – early training where the network fits the finite training examples without developing phase symmetry or frequency diversification.
- Generalization‑1 – weight decay begins to regularize the parameters; competition among frequencies starts, and partial phase symmetry emerges, leading to a gradual rise in validation accuracy.
- Generalization‑2 – full phase symmetry and complete frequency coverage are achieved; noise cancellation is maximal, and validation accuracy aligns with training accuracy.
The timing of each stage depends on the decay coefficient λ and the hidden width, but the underlying dynamics are always a balance between loss minimization (which pushes all frequencies to grow) and regularization (which forces the network to prune redundant frequencies and align phases).
Experimental results on various p values, hidden widths, and decay strengths corroborate the theory: the spectral magnitude of the “winning” frequency at initialization predicts which frequency will dominate, and the emergence of phase‑symmetric pairs coincides with the onset of rapid validation improvement.
In summary, the paper unifies four strands—Fourier feature learning, lottery‑ticket initialization, competitive ODE dynamics, and phase‑symmetry induced majority voting—to deliver a complete mechanistic picture of how over‑parameterized two‑layer networks solve modular addition and why grokking occurs. The insights are likely transferable to other discrete algebraic tasks and may inform the design of architectures that exploit similar spectral competition and symmetry for more efficient learning and generalization.
Comments & Academic Discussion
Loading comments...
Leave a Comment