References Improve LLM Alignment in Non-Verifiable Domains
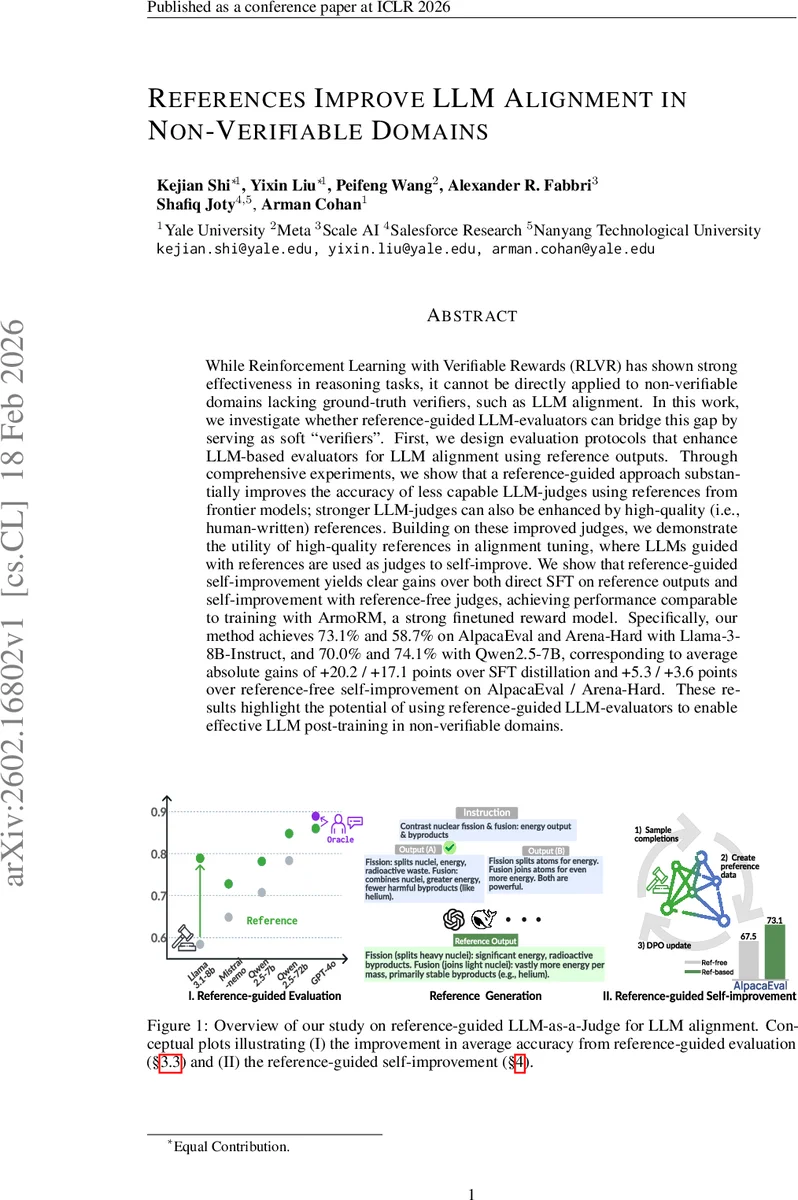
While Reinforcement Learning with Verifiable Rewards (RLVR) has shown strong effectiveness in reasoning tasks, it cannot be directly applied to non-verifiable domains lacking ground-truth verifiers, such as LLM alignment. In this work, we investigate whether reference-guided LLM-evaluators can bridge this gap by serving as soft “verifiers”. First, we design evaluation protocols that enhance LLM-based evaluators for LLM alignment using reference outputs. Through comprehensive experiments, we show that a reference-guided approach substantially improves the accuracy of less capable LLM-judges using references from frontier models; stronger LLM-judges can also be enhanced by high-quality (i.e., human-written) references. Building on these improved judges, we demonstrate the utility of high-quality references in alignment tuning, where LLMs guided with references are used as judges to self-improve. We show that reference-guided self-improvement yields clear gains over both direct SFT on reference outputs and self-improvement with reference-free judges, achieving performance comparable to training with ArmoRM, a strong finetuned reward model. Specifically, our method achieves 73.1% and 58.7% on AlpacaEval and Arena-Hard with Llama-3-8B-Instruct, and 70.0% and 74.1% with Qwen2.5-7B, corresponding to average absolute gains of +20.2 / +17.1 points over SFT distillation and +5.3 / +3.6 points over reference-free self-improvement on AlpacaEval / Arena-Hard. These results highlight the potential of using reference-guided LLM-evaluators to enable effective LLM post-training in non-verifiable domains.
💡 Research Summary
This paper investigates whether reference‑guided large language model (LLM) evaluators can serve as soft verifiers for alignment tasks that lack ground‑truth reward functions, a setting the authors refer to as “non‑verifiable domains.” The core idea is to augment LLM‑as‑a‑Judge systems with explicit prompting strategies that make systematic use of reference outputs, thereby turning references into a form of supervisory signal akin to the verifiable rewards used in RL‑VR for reasoning tasks.
Two prompting methods are introduced. RefEval presents a reference answer and explicitly instructs the judge to compare candidate outputs against the reference in terms of factual correctness, instruction adherence, brevity, and overall quality. RefMatch goes further by asking the judge to act primarily as a semantic‑and‑stylistic matcher, focusing on similarity to the reference. Both methods differ from prior work that merely concatenates a reference; they provide detailed guidance on how the reference should be leveraged during evaluation.
The authors first evaluate the impact of these prompts on the accuracy of 11 diverse LLM judges (ranging from small open‑source models to frontier systems) across five human‑annotated alignment benchmarks (including AlpacaEval and Arena‑Hard). When references are generated by a stronger model (GPT‑4o), the average pairwise accuracy improves by 6.8 percentage points over a strong reference‑free baseline. Human‑written high‑quality references further boost the performance of the strongest judges, confirming that reference quality matters throughout the spectrum of model capabilities.
Having established more reliable judges, the paper proceeds to a self‑improvement pipeline for alignment tuning. The pipeline consists of two stages: (1) Supervised Fine‑Tuning (SFT) on the reference outputs (distillation), and (2) Direct Preference Optimization (DPO) where the same LLM acts as a judge, now guided by the reference‑enhanced prompts, to provide preference signals for further training. Importantly, no external human feedback or separate reward model is required after the initial reference generation.
Experiments with Llama‑3‑8B‑Instruct and Qwen2.5‑7B demonstrate that this two‑stage approach outperforms both (a) direct SFT on references alone and (b) reference‑free self‑improvement. On AlpacaEval, Llama‑3 reaches 73.1 %, and on the harder Arena‑Hard benchmark it scores 58.7 %; Qwen2.5‑7B attains 70.0 % and 74.1 %, respectively. These numbers correspond to absolute gains of +20.2 / +17.1 pp over the SFT baseline and +5.3 / +3.6 pp over reference‑free DPO. Moreover, the reference‑guided DPO performance is comparable to training with ArmoRM‑Llama3‑8B, a strong finetuned reward model, despite not having trained any separate reward model.
The contributions can be summarized as follows:
- Methodological – Introduction of explicit reference‑guided prompting (RefEval, RefMatch) that reliably improves LLM‑judge accuracy across a wide range of models and datasets.
- Empirical – Demonstration that enhanced judges enable effective self‑improvement via DPO, achieving state‑of‑the‑art alignment scores without additional human or AI feedback.
- Conceptual – Proposal of a new paradigm, termed RL from Reference‑Guided Rewards (RLRR), which extends the benefits of verifiable‑reward RL to domains where rule‑based verification is infeasible.
The paper also discusses limitations. The approach hinges on the availability of high‑quality references; generating such references at scale may still require expensive frontier models or human effort. The current experiments use a single reference per instruction; future work could explore multi‑reference ensembles, dynamic reference generation, or integration with other RL algorithms beyond DPO.
Overall, the study provides compelling evidence that reference‑guided LLM evaluators can act as effective soft verifiers, enabling robust alignment tuning in non‑verifiable settings and opening a promising research direction for scalable, automated LLM self‑improvement.
Comments & Academic Discussion
Loading comments...
Leave a Comment