Nonparametric Kernel Regression for Coordinated Energy Storage Peak Shaving with Stacked Services
Developing effective control strategies for behind-the-meter energy storage to coordinate peak shaving and stacked services is essential for reducing electricity costs and extending battery lifetime in commercial buildings. This work proposes an end-to-end, two-stage framework for coordinating peak shaving and energy arbitrage with a theoretical decomposition guarantee. In the first stage, a non-parametric kernel regression model constructs state-of-charge trajectory bounds from historical data that satisfy peak-shaving requirements. The second stage utilizes the remaining capacity for energy arbitrage via a transfer learning method. Case studies using New York City commercial building demand data show that our method achieves a 1.3 times improvement in performance over the state-of-the-art forecast-based method, achieving cost savings and effective peak management without relying on predictions.
💡 Research Summary
This paper addresses the challenge of simultaneously performing peak‑shaving and energy‑arbitrage with a behind‑the‑meter battery energy storage system (BESS) in a commercial building. Traditional approaches rely on demand and price forecasts and solve a large‑scale stochastic optimization over a monthly horizon, which is computationally intensive and vulnerable to forecast errors. The authors propose a novel two‑stage, data‑driven framework that eliminates the need for explicit forecasts while guaranteeing optimality under realistic cost hierarchies.
Problem formulation and theoretical decomposition
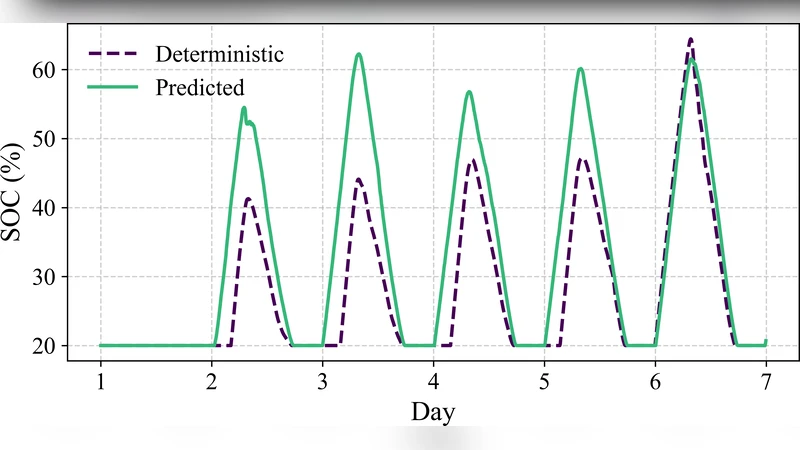
The original joint optimization minimizes total electricity cost, comprising a large peak‑demand charge (κ), real‑time energy price (λₜ), and battery degradation cost (c), subject to battery dynamics, power limits, and SoC bounds. Recognizing that κ is orders of magnitude larger than λₜ and c, the authors prove (via KKT analysis) that the problem can be equivalently decomposed into: (1) a peak‑shaving subproblem that minimizes κ·p plus a tiny tie‑breaking term δ∑eₜ₊₁, yielding the optimal peak level p* and a low‑SoC trajectory e*; (2) an arbitrage subproblem that maximizes revenue while respecting the constraints p ≤ p* and eₜ₊₁ ≥ e*ₜ₊₁. This decomposition reduces a long‑horizon stochastic problem to two deterministic, tractable stages.
Kernel regression for SoC reserve prediction
Stage 1 requires a forecast of the SoC reserve needed for peak shaving. Instead of a conventional time‑series predictor, the authors construct a non‑parametric kernel regression model using historical demand windows. For each historical window of length T, they solve the peak‑shaving subproblem offline to obtain the hindsight‑optimal SoC reserve e_hist and daily peak target p_hist. The input feature vector consists of the T most recent demand values plus daily‑cycle sine and cosine terms. At runtime, the current feature Xₜ is compared to all historical vectors; the K nearest neighbors (KNN) are identified via Euclidean distance, and a Gaussian kernel with bandwidth σ assigns weights wₜ,ₛ.
A confidence‑level parameter α∈(0,1) controls conservatism: the predicted SoC reserve ˆeαₜ₊₁ is the α‑quantile of the weighted SoC values from the KNN set. This “α‑confidence” mechanism allows operators to trade off risk of under‑reserving (higher arbitrage) against the risk of exceeding the peak limit (higher penalty). The peak‑shaving target p_predₜ₊₁ is simply the weighted average of the KNN peak values, with real‑time adaptation handled later in the controller.
Real‑time two‑stage controller
The controller runs every 5 minutes.
Stage 1 (Peak shaving) uses the current SoC eₜ, the predicted reserve ˆeαₜ₊₁, and the current peak target pₜ (updated as the maximum of previous pₜ₋₁ and p_predₜ₊₁). If the observed net demand Dₜ exceeds pₜ, the controller discharges just enough (subject to power limit P and SoC feasibility) to keep net demand ≤ pₜ; otherwise, if SoC is below the reserve and demand is below pₜ, it charges to replenish the reserve.
Stage 2 (Arbitrage) then allocates any remaining power and energy capacity to a non‑anticipatory arbitrage policy (cited from prior work). The algorithm respects the peak‑shaving bound p ≤ p* and the SoC lower bound eₜ₊₁ ≥ e*ₜ₊₁ derived from Stage 1.
Hyper‑parameter tuning
Three hyper‑parameters—look‑back window T, kernel bandwidth σ, and neighbor count K—are tuned automatically. The authors employ a tiered search: coarse‑to‑fine for T, logarithmic then linear refinement for σ, and broad‑to‑fine for K. The objective combines total cost savings (relative to a no‑storage baseline) and annual battery cycles (a proxy for degradation).
Case study and results
The framework is evaluated on a 35‑story, 800 kWh‑scale commercial building in New York City, using six years (2019‑2024) of 5‑minute demand data and NYISO real‑time prices. Peak demand charges follow Con‑Edison’s seasonal rates ($42.80/kW summer, $33.50/kW other months). The BESS has an energy‑to‑power ratio of 2.2 h, 90 % round‑trip efficiency, and SoC limits of 20 %–100 %.
Two benchmarks are considered: (i) a deterministic peak‑shaving‑only optimization limited to one cycle per day, and (ii) a state‑of‑the‑art forecast‑based controller using recursive XGBoost demand predictions. The proposed kernel‑regression‑driven method achieves a 30 % higher total cost reduction (≈ 1.3× improvement) and reduces annual battery cycles by roughly 20 % compared with the forecast‑based baseline. Importantly, the method meets the monthly peak‑demand target without any explicit demand forecast, while still capturing a substantial portion of arbitrage revenue.
Significance and future work
By removing reliance on explicit forecasts and exploiting a provably optimal decomposition, the approach offers a lightweight, scalable solution for real‑time BESS operation under monthly peak‑demand tariffs. The α‑confidence mechanism provides a simple yet powerful knob for operators to adjust risk tolerance. Limitations include the memory and computational cost of kernel regression for very large datasets and the sensitivity of α to operational preferences. Future research directions suggested include integrating richer contextual features (weather, occupancy), employing online learning or deep‑embedding techniques to improve scalability, and extending the framework to incorporate additional ancillary services such as frequency regulation or demand‑response events.
Comments & Academic Discussion
Loading comments...
Leave a Comment