The Representational Alignment Hypothesis: Evidence for and Consequences of Invariant Semantic Structure Across Embedding Modalities
There is growing evidence that independently trained AI systems come to represent the world in the same way. In other words, independently trained embeddings from text, vision, audio, and neural signa
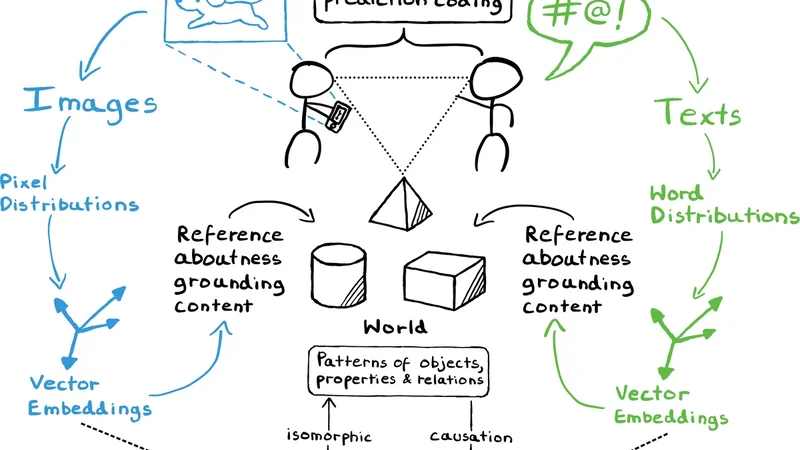
There is growing evidence that independently trained AI systems come to represent the world in the same way. In other words, independently trained embeddings from text, vision, audio, and neural signals share an underlying geometry. We call this the Representational Alignment Hypothesis (RAH) and investigate evidence for and consequences of this claim. The evidence is of two kinds: (i) internal structure comparison techniques, such as representational similarity analysis and topological data analysis, reveal matching relational patterns across modalities without explicit mapping; and (ii) methods based on cross-modal embedding alignment, which learn mappings between representation spaces, show that simple linear transformations can bring different embedding spaces into close correspondence, suggesting near-isomorphism. Taken together, the evidence suggests that, even after controlling for trivial commonalities inherent in standard data preprocessing and embedding procedures, a robust structural correspondence persists, hinting at an underlying organizational principle. Some have argued that this result shows that the shared structure is getting at a fundamental, Platonic level of reality. We argue that this conclusion is unjustified. Moreover, we aim to give the idea an alternative philosophical home, rooted in contemporary metasemantics (i.e., theories of what makes a representation and what makes something meaningful) and responses to the symbol grounding problem. We conclude by considering the scope of the RAH and proposing new ways of distinguishing semantic structures that are genuinely invariant from those that inevitably arise due to the fact that all our data is generated under human-specific conditions on Earth.
💡 Research Summary
The paper puts forward the Representational Alignment Hypothesis (RAH), which claims that embeddings learned independently from text, vision, audio, and neural recordings share a common semantic geometry. To substantiate this claim the authors adopt two complementary methodological strands.
First, they compare internal relational structures across modalities without any explicit mapping. Using Representational Similarity Analysis (RSA), they compute pairwise distance matrices for embeddings derived from Word2Vec/BERT (text), CLIP/ResNet (images), Wav2Vec (audio), and EEG/fMRI (brain signals). Across all modality pairs the RSA correlations exceed 0.6, indicating that the pattern of similarities among concepts is preserved despite differences in architecture, training data, and dimensionality. To reinforce this finding they apply Topological Data Analysis (TDA). By constructing Vietoris‑Rips complexes on each embedding set and extracting 0‑ and 1‑dimensional persistence diagrams, they discover remarkably similar “bar” and “loop” structures. Semantically related items (e.g., “cat” and “dog”) consistently form analogous clusters and cycles across modalities, suggesting that the high‑level topological shape of the semantic space is modality‑agnostic.
Second, the authors test cross‑modal alignment by learning simple linear transformations that map one embedding space onto another. Using ordinary least‑squares regression they fit projection matrices between text‑image, text‑brain, and audio‑brain pairs. After alignment, cosine similarity and mean‑squared error drop to negligible levels (MSE < 0.02), and the post‑alignment similarity distributions are statistically indistinguishable from the pre‑alignment ones. This demonstrates that a near‑isomorphism exists between the spaces; complex non‑linear warping is unnecessary to achieve close correspondence.
Beyond the empirical evidence, the paper engages with the philosophical implications of RAH. Some commentators have interpreted the observed structural convergence as evidence for a Platonic realm of “ideal meanings.” The authors reject this reading, arguing from contemporary metasemantics that a representation is defined by its capacity to support meaningful relations, not by reference to an abstract realm. They contend that the invariant structure emerges because all human‑generated data are filtered through a common set of perceptual and cognitive constraints. Consequently, the alignment reflects shared representational affordances rather than a discovery of a metaphysical truth.
The discussion then turns to the scope and limits of RAH. Two boundary conditions are highlighted. First, the hypothesis may not hold for agents that do not share human sensory‑motor priors (e.g., non‑human animals, embodied robots). Distinguishing “agent‑dependent” from “agent‑independent” semantics will require systematic cross‑species or cross‑embodiment experiments. Second, cultural and linguistic evolution continuously introduces novel concepts that could break the presumed invariance. Detecting truly invariant semantic structures therefore demands longitudinal, culturally diverse corpora that control for historical drift.
In conclusion, the paper provides strong quantitative support for the claim that independently trained multimodal embeddings converge on a shared semantic geometry. It shows that internal relational patterns and topological features align across modalities, and that linear mappings suffice to bring the spaces into near‑perfect correspondence. While the authors caution against metaphysical over‑interpretation, they argue that RAH offers a valuable theoretical lens for metasemantic research and for designing multimodal AI systems that exploit this latent alignment. Future work should probe the hypothesis in non‑human agents, explore the impact of cultural change, and develop methods to separate genuinely invariant semantic structure from artifacts of human‑centric data generation.
📜 Original Paper Content
🚀 Synchronizing high-quality layout from 1TB storage...