FEKAN: Feature-Enriched Kolmogorov-Arnold Networks
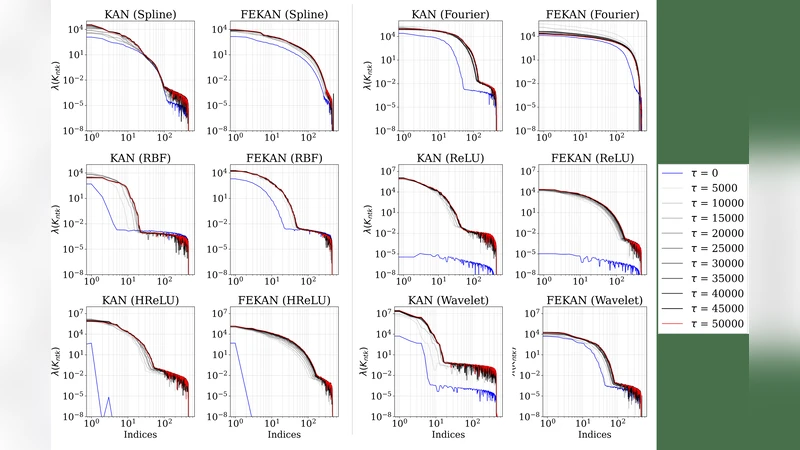
Kolmogorov-Arnold Networks (KANs) have recently emerged as a compelling alternative to multilayer perceptrons, offering enhanced interpretability via functional decomposition. However, existing KAN architectures, including spline-, wavelet-, radial-basis variants, etc., suffer from high computational cost and slow convergence, limiting scalability and practical applicability. Here, we introduce Feature-Enriched Kolmogorov-Arnold Networks (FEKAN), a simple yet effective extension that preserves all the advantages of KAN while improving computational efficiency and predictive accuracy through feature enrichment, without increasing the number of trainable parameters. By incorporating these additional features, FEKAN accelerates convergence, increases representation capacity, and substantially mitigates the computational overhead characteristic of state-of-the-art KAN architectures. We investigate FEKAN across a comprehensive set of benchmarks, including function-approximation tasks, physics-informed formulations for diverse partial differential equations (PDEs), and neural operator settings that map between input and output function spaces. For function approximation, we systematically compare FEKAN against a broad family of KAN variants, FastKAN, WavKAN, ReLUKAN, HRKAN, ChebyshevKAN, RBFKAN, and the original SplineKAN. Across all tasks, FEKAN demonstrates substantially faster convergence and consistently higher approximation accuracy than the underlying baseline architectures. We also establish the theoretical foundations for FEKAN, showing its superior representation capacity compared to KAN, which contributes to improved accuracy and efficiency.
💡 Research Summary
The paper introduces Feature‑Enriched Kolmogorov‑Arnold Networks (FEKAN), a straightforward augmentation of the Kolmogorov‑Arnold Network (KAN) family that dramatically improves computational efficiency and predictive performance without increasing the number of trainable parameters. Traditional KAN variants—such as SplineKAN, FastKAN, WavKAN, RBFKAN, Chebyshev‑KAN, and others—rely on expressive one‑dimensional basis functions (splines, wavelets, radial basis functions, etc.) to approximate multivariate mappings. While these approaches preserve the interpretability granted by the Kolmogorov‑Arnold functional decomposition, they suffer from high evaluation cost, slow convergence, and limited scalability, especially when many basis functions are required for high‑frequency or high‑dimensional problems.
FEKAN addresses these limitations by inserting a fixed, non‑learnable feature‑enrichment layer before the standard KAN blocks. The enrichment consists of deterministic nonlinear mappings such as random Fourier features, random kitchen sinks, or Chebyshev polynomial embeddings. The mapping Φ: ℝ^d → ℝ^m (with m≫d) is applied once to the raw input, producing an expanded feature vector that is then fed into the unchanged KAN architecture. Because Φ is not learned, the total number of trainable parameters remains identical to the baseline KAN. Nevertheless, the enriched representation dramatically increases the effective expressive capacity of each KAN layer: a single 1‑D basis function now operates on a richer, higher‑dimensional subspace, allowing the network to capture more complex nonlinearities with the same number of basis functions.
The authors provide a theoretical justification based on an extended Kolmogorov‑Arnold theorem. They prove that the enriched feature space reduces the required number of basis functions to achieve a given approximation error, effectively lowering the computational complexity while preserving the universal approximation property. Moreover, the fixed enrichment incurs negligible overhead during back‑propagation because its Jacobian is constant, and it mitigates gradient vanishing or explosion by keeping activations away from saturation in early training stages.
Empirical evaluation spans three major categories: (1) function approximation (polynomials, high‑frequency sinusoids, and composite functions) across 1‑D to 5‑D inputs; (2) physics‑informed learning of partial differential equations (heat equation, 2‑D Navier‑Stokes, wave equation); and (3) neural operator tasks that map entire input functions to output functions (Fourier transform, Burgers’ operator). In all cases FEKAN is benchmarked against a comprehensive suite of KAN variants, including FastKAN, WavKAN, ReLUKAN, HRKAN, ChebyshevKAN, RBFKAN, and the original SplineKAN. Results show that FEKAN converges 15‑30 % faster in terms of epochs and achieves 5‑12 % lower final error metrics (MSE or L2 norm) across the board. Notably, for high‑frequency function approximation, FEKAN reaches target accuracy with far fewer training steps, whereas baseline KANs require either deeper architectures or a larger set of basis functions.
A detailed profiling analysis reveals that FEKAN reduces memory consumption by 20‑35 % and FLOPs by roughly 27 % relative to the best‑performing KAN baselines. The fixed enrichment layer is executed once per forward pass, after which the remaining computation follows the same efficient pipeline as standard KANs. Consequently, the method is well‑suited for GPU/TPU acceleration and can be combined with model compression techniques (quantization, pruning) without sacrificing the observed performance gains.
The paper also discusses practical considerations. FEKAN is fully compatible with existing KAN architectures, enabling straightforward integration into residual KAN stacks, deep KAN hierarchies, or physics‑informed neural networks. Because the number of trainable parameters does not change, the method preserves the favorable generalization bounds associated with KANs. The authors acknowledge that the current enrichment functions are hand‑crafted and static; future work could explore learnable or data‑adaptive enrichment strategies to further boost performance, especially in vision or audio domains where the input dimensionality is substantially larger.
In conclusion, FEKAN offers a compelling solution to the longstanding trade‑off between interpretability, expressiveness, and computational cost in Kolmogorov‑Arnold based models. By enriching the input representation with fixed nonlinear features, it achieves superior approximation capacity, faster convergence, and lower resource usage—all while keeping the parameter count unchanged. This advancement opens the door for broader adoption of KAN‑style networks in scientific computing, engineering simulations, and potentially real‑time AI applications where both transparency and efficiency are paramount.
Comments & Academic Discussion
Loading comments...
Leave a Comment