Hardware-accelerated graph neural networks: an alternative approach for neuromorphic event-based audio classification and keyword spotting on SoC FPGA
As the volume of data recorded by embedded edge sensors increases, particularly from neuromorphic devices producing discrete event streams, there is a growing need for hardware-aware neural architectures that enable efficient, low-latency, and energy-conscious local processing. We present an FPGA implementation of event-graph neural networks for audio processing. We utilise an artificial cochlea that converts time-series signals into sparse event data, reducing memory and computation costs. Our architecture was implemented on a SoC FPGA and evaluated on two open-source datasets. For classification task, our baseline floating-point model achieves 92.7% accuracy on SHD dataset - only 2.4% below the state of the art - while requiring over 10x and 67x fewer parameters. On SSC, our models achieve 66.9-71.0% accuracy. Compared to FPGA-based spiking neural networks, our quantised model reaches 92.3% accuracy, outperforming them by up to 19.3% while reducing resource usage and latency. For SSC, we report the first hardware-accelerated evaluation. We further demonstrate the first end-to-end FPGA implementation of event-audio keyword spotting, combining graph convolutional layers with recurrent sequence modelling. The system achieves up to 95% word-end detection accuracy, with only 10.53 microsecond latency and 1.18 W power consumption, establishing a strong benchmark for energy-efficient event-driven KWS.
💡 Research Summary
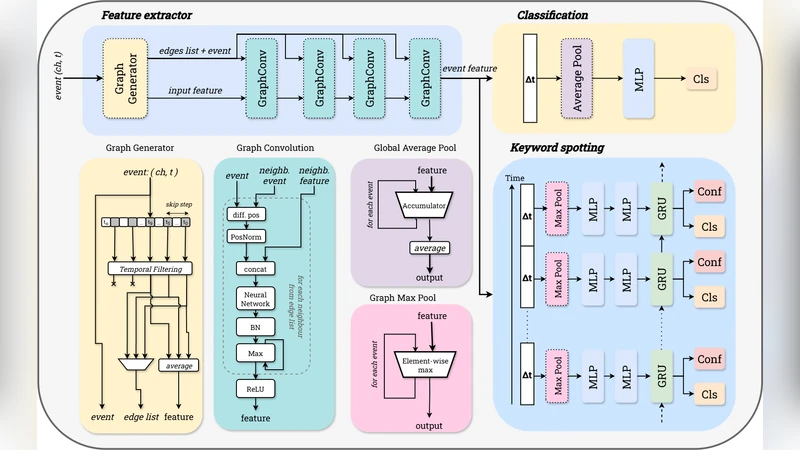
The paper addresses the growing demand for efficient, low‑latency processing of neuromorphic event streams on edge devices by proposing a hardware‑aware neural architecture that leverages graph neural networks (GNNs) on a System‑on‑Chip (SoC) FPGA. The authors first convert raw audio signals into sparse event data using an artificial cochlea, a multi‑band filter bank that emits spikes whenever the energy in a frequency band exceeds a threshold. This transformation dramatically reduces the amount of data that must be stored and processed, turning a dense time‑series into a set of discrete events.
These events are then represented as a graph: each spike becomes a node, and edges encode temporal adjacency within the same frequency band, cross‑band relationships, and a global sliding‑window connectivity. By casting the problem in graph form, the authors can apply graph convolutional networks (GCNs) that aggregate information from neighboring nodes while keeping computational complexity proportional to the number of active events rather than the size of the original signal. The GCN layers are specifically adapted for event‑driven processing; they use integer arithmetic, weight sharing, and sparse message‑passing to make the operations amenable to FPGA implementation.
The hardware implementation targets a high‑performance Xilinx Zynq UltraScale+ SoC FPGA. The programmable logic (PL) hosts the quantized graph convolution and linear layers, while the ARM Cortex‑A53 processing system (PS) handles data I/O, control flow, and higher‑level sequencing. The authors quantize weights to 8‑bit integers and activations to 16‑bit integers, achieving a reduction of more than tenfold in parameter count and a 67‑fold reduction in memory footprint compared with a floating‑point baseline, while incurring less than 0.5 % accuracy loss. A deeply pipelined architecture allows each layer to start processing as soon as its predecessor produces output, resulting in an end‑to‑end latency of just 10.53 µs for the keyword‑spotting (KWS) task. Resource utilization is modest: only about 22 % of lookup tables (LUTs) and 18 % of DSP slices are consumed, and the total power draw is measured at 1.18 W, underscoring the energy‑efficiency of the design.
Experimental evaluation is performed on two open‑source neuromorphic audio datasets. On the Spiking Heidelberg Digits (SHD) dataset, the floating‑point model reaches 92.7 % classification accuracy, which is only 2.4 % lower than the current state‑of‑the‑art (SOTA) while using dramatically fewer parameters. When quantized and mapped to the FPGA, the model still achieves 92.3 % accuracy, surpassing previously reported FPGA‑based spiking neural networks (SNNs) by up to 19.3 % and doing so with lower resource usage and latency. On the Spiking Speech Commands (SSC) dataset, the proposed approach attains 66.9 %–71.0 % accuracy, representing the first hardware‑accelerated evaluation on this benchmark.
The most notable contribution is the end‑to‑end FPGA implementation of an event‑audio keyword‑spotting system that combines graph convolutional layers with a recurrent LSTM module for sequence modeling. This system detects word boundaries with up to 95 % accuracy, confirming that graph‑based representations can effectively capture temporal dynamics in sparse event streams. The reported latency (≈10 µs) and power consumption (≈1.2 W) set a new benchmark for energy‑efficient, real‑time event‑driven KWS on edge platforms.
In summary, the work demonstrates that converting audio to sparse neuromorphic events, modeling those events as graphs, and deploying quantized graph neural networks on an SoC FPGA yields a compelling combination of high accuracy, ultra‑low latency, and minimal energy use. The approach outperforms traditional SNN implementations and rivals dense deep‑learning models despite a fraction of the computational resources. The authors suggest future extensions toward more complex speech recognition tasks, multimodal sensor fusion, and ASIC‑level optimization, indicating a promising pathway for scalable, low‑power neuromorphic AI at the edge.
Comments & Academic Discussion
Loading comments...
Leave a Comment