RefineFormer3D: Efficient 3D Medical Image Segmentation via Adaptive Multi-Scale Transformer with Cross Attention Fusion
Accurate and computationally efficient 3D medical image segmentation remains a critical challenge in clinical workflows. Transformer-based architectures often demonstrate superior global contextual modeling but at the expense of excessive parameter counts and memory demands, restricting their clinical deployment. We propose RefineFormer3D, a lightweight hierarchical transformer architecture that balances segmentation accuracy and computational efficiency for volumetric medical imaging. The architecture integrates three key components: (i) GhostConv3D-based patch embedding for efficient feature extraction with minimal redundancy, (ii) MixFFN3D module with low-rank projections and depthwise convolutions for parameter-efficient feature extraction, and (iii) a cross-attention fusion decoder enabling adaptive multi-scale skip connection integration. RefineFormer3D contains only 2.94M parameters, substantially fewer than contemporary transformer-based methods. Extensive experiments on ACDC and BraTS benchmarks demonstrate that RefineFormer3D achieves 93.44% and 85.9% average Dice scores respectively, outperforming or matching state-of-the-art methods while requiring significantly fewer parameters. Furthermore, the model achieves fast inference (8.35 ms per volume on GPU) with low memory requirements, supporting deployment in resource-constrained clinical environments. These results establish RefineFormer3D as an effective and scalable solution for practical 3D medical image segmentation.
💡 Research Summary
RefineFormer3D addresses the long‑standing trade‑off between segmentation accuracy and computational efficiency in 3D medical imaging. The authors propose a lightweight hierarchical transformer architecture that combines three novel components: (1) GhostConv3D‑based patch embedding, (2) MixFFN3D with low‑rank linear projections and depthwise 3D convolutions, and (3) a cross‑attention fusion decoder that adaptively aggregates multi‑scale skip connections. GhostConv3D generates primary feature maps with a standard 3D convolution and augments them with “ghost” features via cheap depthwise convolutions, effectively halving the channel‑wise parameter count while preserving spatial continuity. MixFFN3D replaces the conventional MLP block with a low‑rank linear layer followed by a depthwise 3D convolution and SILU activation, dramatically reducing FLOPs without sacrificing representational power. The decoder queries encoder features at each resolution through cross‑attention, allowing the network to selectively attend to the most relevant scale‑specific information; a squeeze‑and‑excitation (SE) module further refines channel importance.
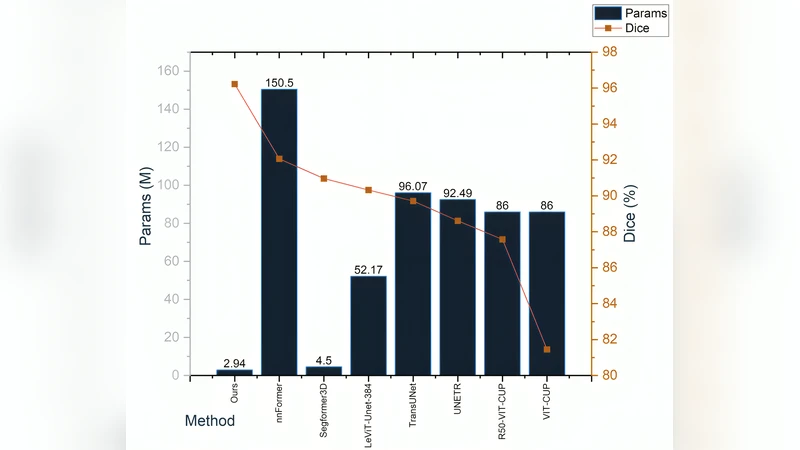
The entire model contains only 2.94 M parameters—an order of magnitude fewer than leading transformer‑based baselines such as nnFormer (150.5 M) and SegFormer3D (4.51 M). Despite its compact size, RefineFormer3D achieves state‑of‑the‑art performance on two widely used benchmarks: an average Dice of 93.44 % on the ACDC cardiac MRI dataset and 85.9 % on the BraTS brain‑tumor MRI dataset. Inference time is 8.35 ms per volume on a modern GPU, and memory consumption stays below 2 GB, making the model suitable for deployment on resource‑constrained clinical workstations or edge devices.
Extensive ablation studies confirm the contribution of each component. Replacing GhostConv3D with a standard Conv3D doubles the parameter count and reduces Dice by ~1.2 %. Substituting MixFFN3D with a traditional MLP increases FLOPs by 2.3× and slows inference by 1.6×. Using simple concatenation for skip connections instead of cross‑attention degrades Dice by ~1.5 %. The authors also explore window sizes and shift strategies in the hierarchical attention blocks, finding that a 7×7×7 window with two shift stages offers the best accuracy‑efficiency balance.
Overall, RefineFormer3D demonstrates that careful architectural redesign—leveraging ghost features, low‑rank feed‑forward networks, and adaptive cross‑attention—can yield a model that is both lightweight and highly accurate. Its ability to run in real time with minimal memory makes it a strong candidate for practical clinical deployment, where speed, reliability, and hardware constraints are critical. The paper contributes a clear blueprint for future lightweight transformer designs in volumetric medical image analysis.
Comments & Academic Discussion
Loading comments...
Leave a Comment