Surrogate-Based Prevalence Measurement for Large-Scale A/B Testing
Online media platforms often need to measure how frequently users are exposed to specific content attributes in order to evaluate trade-offs in A/B experiments. A direct approach is to sample content, label it using a high-quality rubric (e.g., an expert-reviewed LLM prompt), and estimate impression-weighted prevalence. However, repeatedly running such labeling for every experiment arm and segment is too costly and slow to serve as a default measurement at scale. We present a scalable \emph{surrogate-based prevalence measurement} framework that decouples expensive labeling from per-experiment evaluation. The framework calibrates a surrogate signal to reference labels offline and then uses only impression logs to estimate prevalence for arbitrary experiment arms and segments. We instantiate this framework using \emph{score bucketing} as the surrogate: we discretize a model score into buckets, estimate bucket-level prevalences from an offline labeled sample, and combine these calibrated bucket level prevalences with the bucket distribution of impressions in each arm to obtain fast, log-based estimates. Across multiple large-scale A/B tests, we validate that the surrogate estimates closely match the reference estimates for both arm-level prevalence and treatment–control deltas. This enables scalable, low-latency prevalence measurement in experimentation without requiring per-experiment labeling jobs.
💡 Research Summary
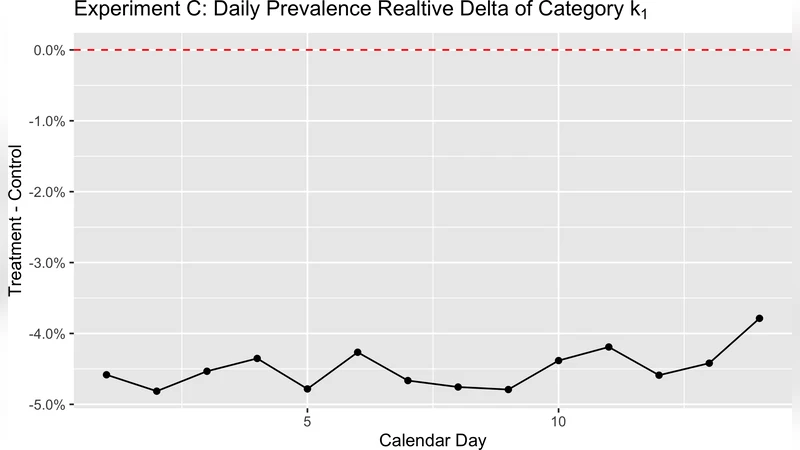
Online media platforms constantly run A/B experiments to evaluate new features, algorithmic changes, or policy updates. A critical metric in many of these experiments is the prevalence of a particular content attribute—such as toxicity, clickbait, or ad exposure—weighted by impressions. The most straightforward way to obtain this metric is to draw a random sample of content, apply a high‑quality labeling process (e.g., expert review or a carefully crafted LLM prompt), and compute an impression‑weighted prevalence estimate. However, repeating this costly labeling step for every experiment arm, segment, and rollout is infeasible at the scale of billions of impressions and hundreds of concurrent experiments.
The paper introduces a surrogate‑based prevalence measurement framework that separates the expensive labeling phase from per‑experiment evaluation. The core idea is to use a predictive model’s continuous score as a surrogate signal for the attribute of interest, calibrate this signal offline using a modest labeled sample, and then rely solely on impression logs to estimate prevalence for any future experiment.
Offline calibration
- A pre‑trained model produces a real‑valued score for each impression (e.g., the probability that the content is toxic).
- The score range is discretized into a set of buckets (e.g., 0‑0.1, 0.1‑0.2, …, 0.9‑1.0).
- From a labeled sample, the true positive rate (the “reference prevalence”) is computed for each bucket. This yields a calibrated bucket prevalence that corrects for any systematic bias in the raw model scores.
Because this step uses only a single labeled dataset, the labeling cost is incurred once, regardless of how many experiments follow.
Online estimation
During an experiment, the system already logs the model score for every impression. For each arm and segment, the distribution of impressions across the predefined buckets is calculated (the impression share per bucket). The prevalence for that arm is then estimated by a weighted sum:
\
Comments & Academic Discussion
Loading comments...
Leave a Comment