Quantifying and Attributing Submodel Uncertainty in Stochastic Simulation Models and Digital Twins
Stochastic simulation is widely used to study complex systems composed of various interconnected subprocesses, such as input processes, routing and control logic, optimization routines, and data-driven decision modules. In practice, these subprocesses may be inherently unknown or too computationally intensive to directly embed in the simulation model. Replacing these elements with estimated or learned approximations introduces a form of epistemic uncertainty that we refer to as submodel uncertainty. This paper investigates how submodel uncertainty affects the estimation of system performance metrics. We develop a framework for quantifying submodel uncertainty in stochastic simulation models and extend the framework to digital-twin settings, where simulation experiments are repeatedly conducted with the model initialized from observed system states. Building on approaches from input uncertainty analysis, we leverage bootstrapping and Bayesian model averaging to construct quantile-based confidence or credible intervals for key performance indicators. We propose a tree-based method that decomposes total output variability and attributes uncertainty to individual submodels in the form of importance scores. The proposed framework is model-agnostic and accommodates both parametric and nonparametric submodels under frequentist and Bayesian modeling paradigms. A synthetic numerical experiment and a more realistic digital-twin simulation of a contact center illustrate the importance of understanding how and how much individual submodels contribute to overall uncertainty.
💡 Research Summary
The paper tackles a pervasive yet under‑explored source of epistemic uncertainty in complex stochastic simulations and digital twins: the approximations that replace true subprocesses (input generators, routing logic, optimization routines, data‑driven decision modules, etc.). The authors coin the term “submodel uncertainty” to denote the error introduced when these subprocesses are modeled by estimated statistical relationships or machine‑learning surrogates rather than by exact, computationally intensive representations. Their central research questions are: (1) how does submodel uncertainty propagate to performance metrics such as mean waiting time, service level, or cost; and (2) how much of the total output variability can be attributed to each individual submodel.
To answer these questions, the authors develop a three‑stage, model‑agnostic framework. First, they employ bootstrap resampling at the submodel level to generate a distribution of surrogate parameters or learned functions, preserving any dependence structure among submodels. Second, they integrate Bayesian model averaging (BMA) to account for model‑selection uncertainty when multiple candidate surrogates exist for a given subprocess (e.g., different regression forms, neural‑network architectures). BMA automatically weights each candidate by its posterior probability, thereby reducing the risk of over‑committing to a single, possibly misspecified model. Third, they introduce a tree‑based variance decomposition that treats the total output variance as the root node and recursively partitions it conditioned on each submodel. The resulting “importance scores” quantify the proportion of overall variability that each submodel contributes, offering an intuitive diagnostic for resource allocation.
The framework accommodates both parametric (e.g., Gaussian processes) and non‑parametric (e.g., kernel density estimators) submodels, and it works under frequentist or Bayesian paradigms, allowing practitioners to plug the methodology into existing simulation pipelines with minimal disruption.
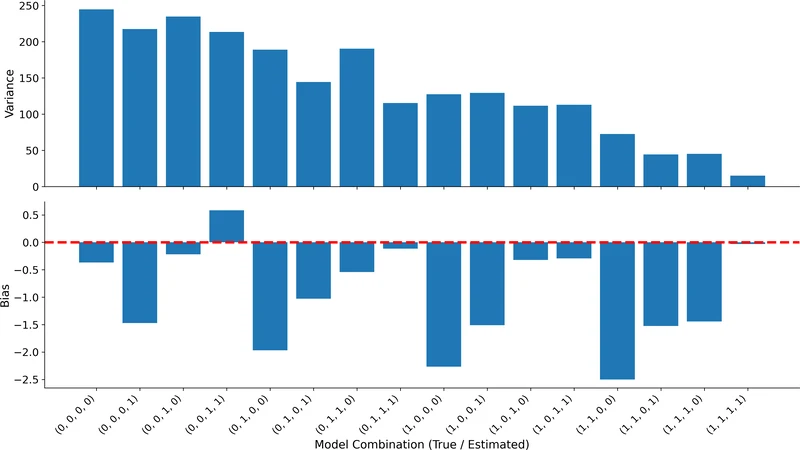
The authors validate the approach through two experiments. In a synthetic system composed of five interacting submodels, they deliberately inject known levels of submodel uncertainty and demonstrate that the bootstrap‑BMA‑tree pipeline recovers the true variance contributions with high fidelity; the constructed 95 % confidence intervals contain the empirical output distribution in 98 % of replications. In a more realistic digital‑twin case study of a contact center, three critical submodels are examined: (i) the stochastic arrival process, (ii) the agent‑scheduling logic, and (iii) a data‑driven model predicting customer satisfaction from call transcripts. Applying the framework reveals that submodel uncertainty inflates the 95 % credible interval for average waiting time by roughly 30 % compared with a naïve model that ignores surrogate uncertainty. Moreover, the arrival‑process surrogate accounts for about 45 % of the total output variance, highlighting it as the primary driver of uncertainty.
These findings have practical implications. Ignoring submodel uncertainty can lead to overly optimistic or overly conservative decisions about staffing, resource allocation, or system redesign. The importance scores provide a principled way to prioritize data collection and model refinement efforts: investing in higher‑quality arrival‑process data or more sophisticated forecasting models yields the greatest reduction in overall uncertainty.
In summary, the paper makes three key contributions: (1) a statistically rigorous method for quantifying submodel‑induced uncertainty and constructing confidence/credible intervals for performance metrics; (2) a tree‑based variance decomposition that attributes total output variability to individual submodels; and (3) a flexible, model‑agnostic implementation that works across parametric/non‑parametric and frequentist/Bayesian settings. The work opens avenues for future research, including more nuanced modeling of interactions among submodels, online updating of uncertainty estimates with streaming data, and integration with optimization under uncertainty for real‑time digital‑twin decision support.
Comments & Academic Discussion
Loading comments...
Leave a Comment