Closing the Distribution Gap in Adversarial Training for LLMs
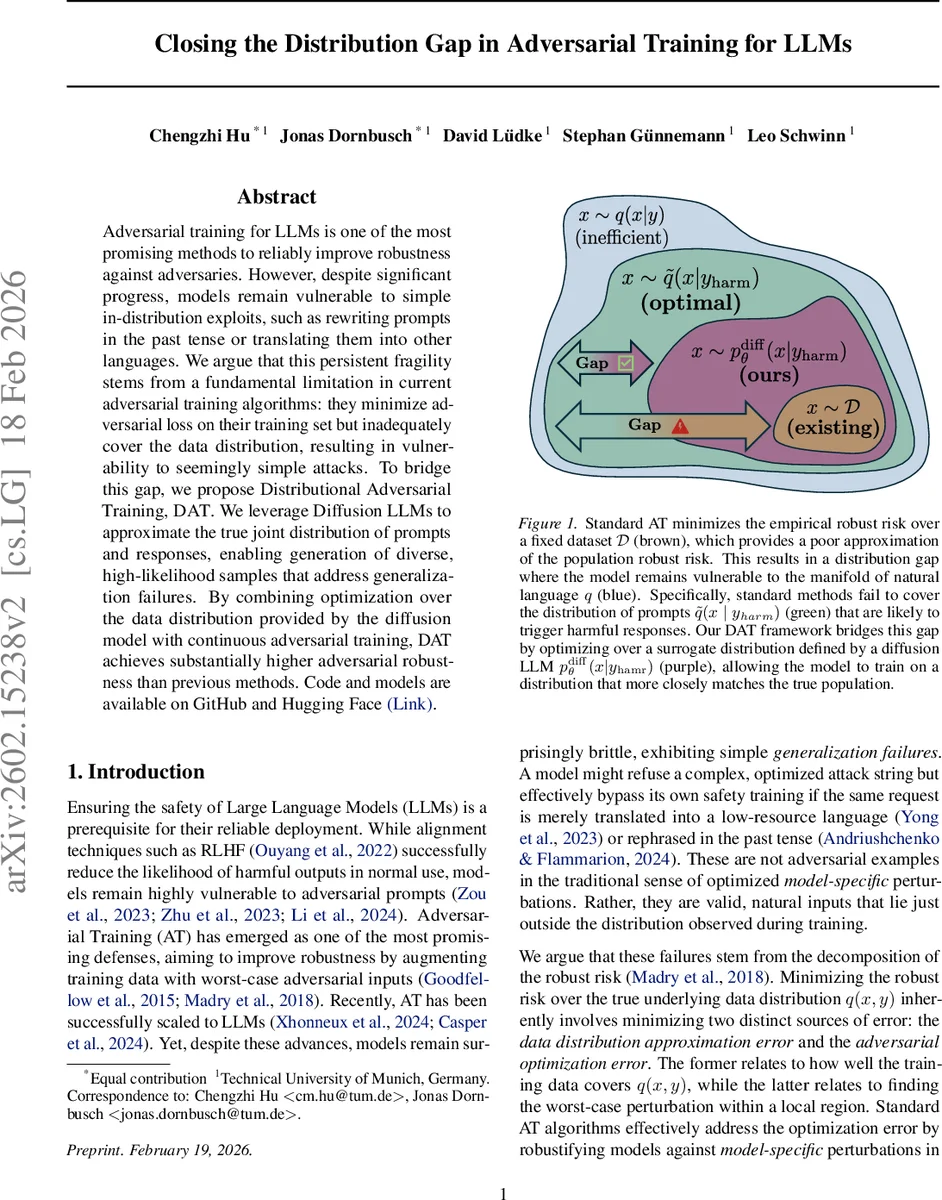
Adversarial training for LLMs is one of the most promising methods to reliably improve robustness against adversaries. However, despite significant progress, models remain vulnerable to simple in-distribution exploits, such as rewriting prompts in the past tense or translating them into other languages. We argue that this persistent fragility stems from a fundamental limitation in current adversarial training algorithms: they minimize adversarial loss on their training set but inadequately cover the data distribution, resulting in vulnerability to seemingly simple attacks. To bridge this gap, we propose Distributional Adversarial Training, DAT. We leverage Diffusion LLMs to approximate the true joint distribution of prompts and responses, enabling generation of diverse, high-likelihood samples that address generalization failures. By combining optimization over the data distribution provided by the diffusion model with continuous adversarial training, DAT achieves substantially higher adversarial robustness than previous methods.
💡 Research Summary
The paper identifies a fundamental shortcoming of current adversarial training (AT) for large language models (LLMs): it minimizes robust loss on a fixed training set but fails to approximate the true data distribution, leaving models vulnerable to simple in‑distribution manipulations such as tense changes or translations. The authors formalize this as a “distribution gap” between empirical robust risk and population robust risk, distinguishing data‑specific vulnerabilities (high‑probability prompts that naturally trigger harmful outputs) from model‑specific attacks (low‑probability, model‑tailored perturbations).
To close the gap, they propose Distributional Adversarial Training (DAT). DAT leverages diffusion‑based LLMs, which model the joint distribution of prompts and responses, enabling conditional sampling of diverse prompts x given a harmful response y (p_diffθ(x|y)). This yields data‑specific adversarial examples that are both high‑likelihood under the true distribution and highly transferable across models. The sampled prompts are then subjected to continuous adversarial training (CAT), where small continuous perturbations δ are applied to token embeddings to maximize a loss that encourages the model to refuse the harmful response. The outer optimization minimizes this worst‑case loss while a KL‑regularization term (λ_KL·L_KL) keeps the model close to its pre‑training state, preserving general performance.
The authors provide a theoretical guarantee: under a bounded loss and a total‑variation fidelity assumption between the diffusion surrogate and the true conditional distribution, the surrogate risk R_diff deviates from the true population risk R_pop by at most 2Mε. Thus improving the diffusion model directly tightens the risk approximation.
Empirically, DAT is evaluated on Llama‑3‑8B and Qwen‑2.5‑14B. Compared to standard AT and static‑dataset defenses, DAT dramatically reduces success rates of jailbreak attacks, translation attacks, and past‑tense reformulations. Diffusion‑generated prompts exhibit lower intra‑method cosine similarity (0.178) than GCG or BoN, confirming greater diversity. Transferability tests across five target models show that diffusion‑based inpainting attacks achieve higher attack success rates than model‑specific optimizations, demonstrating that DAT captures genuine data‑specific weaknesses. Importantly, performance on standard benchmarks (e.g., MMLU, TruthfulQA) remains largely unchanged, indicating that robustness gains do not come at the cost of overall capability.
In summary, the work introduces a novel training paradigm that jointly addresses data‑distribution approximation and adversarial optimization errors, offering a principled and effective solution to the distribution gap that has limited prior AT methods for LLM safety.
Comments & Academic Discussion
Loading comments...
Leave a Comment