BPP: Long-Context Robot Imitation Learning by Focusing on Key History Frames
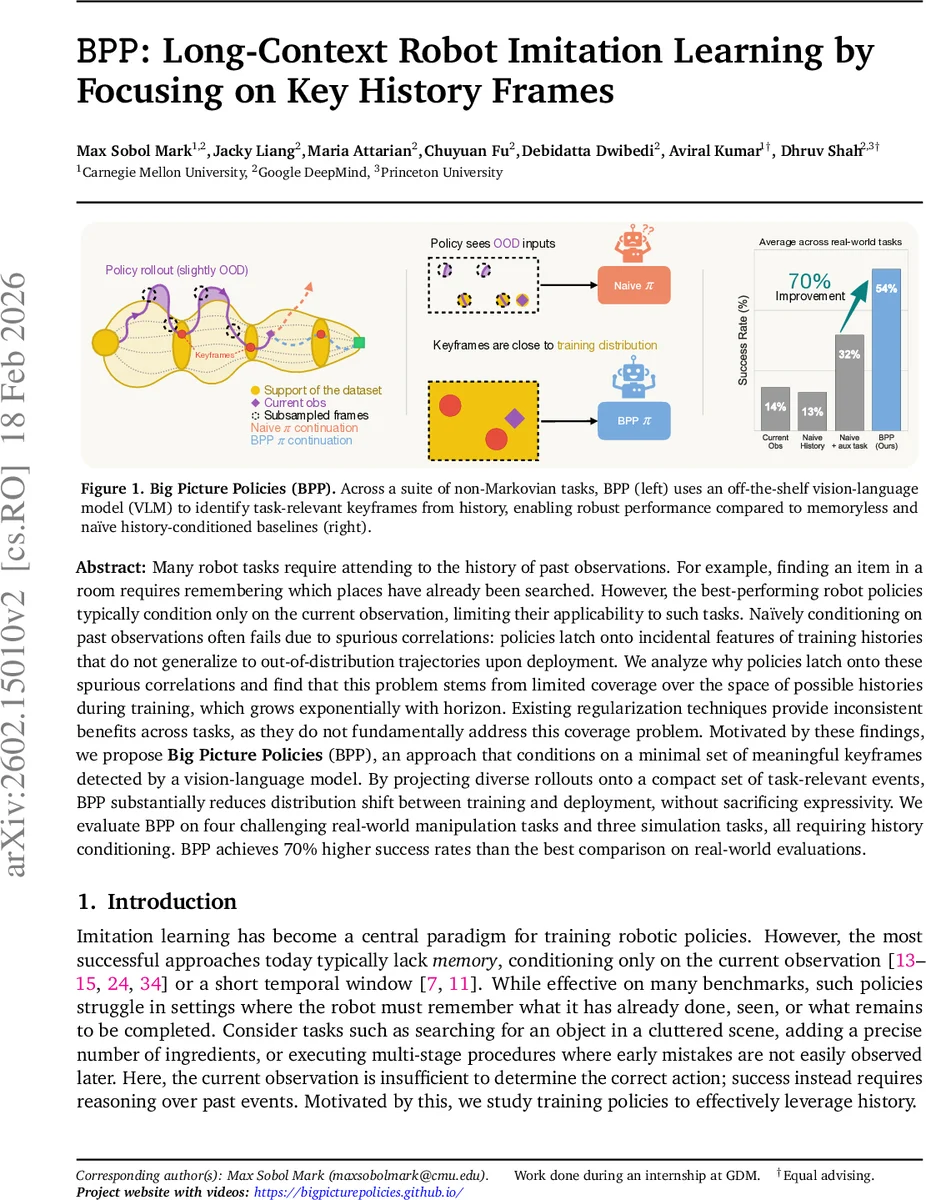
Many robot tasks require attending to the history of past observations. For example, finding an item in a room requires remembering which places have already been searched. However, the best-performing robot policies typically condition only on the current observation, limiting their applicability to such tasks. Naively conditioning on past observations often fails due to spurious correlations: policies latch onto incidental features of training histories that do not generalize to out-of-distribution trajectories upon deployment. We analyze why policies latch onto these spurious correlations and find that this problem stems from limited coverage over the space of possible histories during training, which grows exponentially with horizon. Existing regularization techniques provide inconsistent benefits across tasks, as they do not fundamentally address this coverage problem. Motivated by these findings, we propose Big Picture Policies (BPP), an approach that conditions on a minimal set of meaningful keyframes detected by a vision-language model. By projecting diverse rollouts onto a compact set of task-relevant events, BPP substantially reduces distribution shift between training and deployment, without sacrificing expressivity. We evaluate BPP on four challenging real-world manipulation tasks and three simulation tasks, all requiring history conditioning. BPP achieves 70% higher success rates than the best comparison on real-world evaluations. Videos are available at https://bigpicturepolicies.github.io/
💡 Research Summary
The paper tackles a fundamental limitation of current robot imitation learning: most high‑performing policies condition only on the current observation, which makes them unsuitable for tasks that require remembering past events (e.g., searching a room, multi‑step cooking, or assembling a complex structure). Naïvely feeding the entire observation history into a policy often leads to catastrophic failure because the policy latches onto spurious correlations that exist only in the training demonstrations. The authors identify the root cause as a coverage problem – the space of possible histories grows exponentially with horizon, and human‑collected expert demonstrations can only cover a tiny fraction of this space. Consequently, policies learn to exploit incidental patterns in the training histories that do not generalize when the rollout distribution shifts.
Existing remedies such as regularization, auxiliary losses, or architectural constraints only provide inconsistent gains because they do not address the underlying lack of coverage. To solve this, the authors propose Big Picture Policies (BPP), a method that replaces the raw history with a compact set of keyframes—semantically meaningful moments that are truly relevant for the task (e.g., “object grasped”, “sub‑goal completed”, “failure detected”). BPP leverages an off‑the‑shelf vision‑language model (VLM) to automatically select these keyframes via simple question‑answering: the VLM is asked whether a particular event has occurred, and frames with high confidence are kept. By projecting long, diverse trajectories onto a small set of informative frames, BPP dramatically reduces the effective size of the input distribution while preserving all information needed for accurate action prediction.
The method is integrated into a standard imitation‑learning pipeline: the policy receives the current observation together with the extracted keyframes and predicts actions using action‑chunking (predicting temporally extended action segments). Experiments span four real‑world bimanual manipulation tasks (mug replacement, marshmallow alignment, drawer search, stacking puzzle) and three simulated tasks (ingredient insertion, fixed‑password entry, variable‑password entry). All tasks are deliberately non‑Markovian, requiring memory to succeed. BPP outperforms strong baselines—including memory‑less policies, naïve history‑conditioned policies, and prior regularization‑based approaches—by up to 70 % higher success rates on real‑world tasks. Moreover, BPP reduces training time and memory consumption because the keyframe representation is far smaller than the full history.
Additional analyses reveal two important factors. First, action chunking (predicting longer action segments) mitigates spurious correlations by forcing the network to learn features that are robust to distribution shift; shorter chunks lead to larger performance gaps between expert and rollout data. Second, training a single, jointly‑optimized visual encoder across all timesteps (instead of freezing a short‑history encoder) further improves history conditioning. Nonetheless, even with long chunks, a performance gap remains relative to an oracle that has privileged state information, confirming that coverage remains a core challenge.
The paper also discusses limitations: the keyframe selection relies on hand‑crafted VLM queries, which may need automation for more complex tasks; VLMs trained on internet data might misinterpret domain‑specific scenes, requiring domain adaptation; and very long‑horizon tasks could generate many keyframes, reducing compression benefits. Future work could explore learned query generation, fine‑tuning VLMs for robotics, and hierarchical keyframe selection.
In summary, BPP introduces a pragmatic and effective paradigm shift: rather than trying to memorize the entire past, robots should focus on the few pivotal moments that truly matter. By coupling vision‑language models with imitation learning, the approach achieves substantial gains in data efficiency, robustness to out‑of‑distribution rollouts, and real‑world performance, opening a promising path for long‑context robot learning.
Comments & Academic Discussion
Loading comments...
Leave a Comment