Boundary Point Jailbreaking of Black-Box LLMs
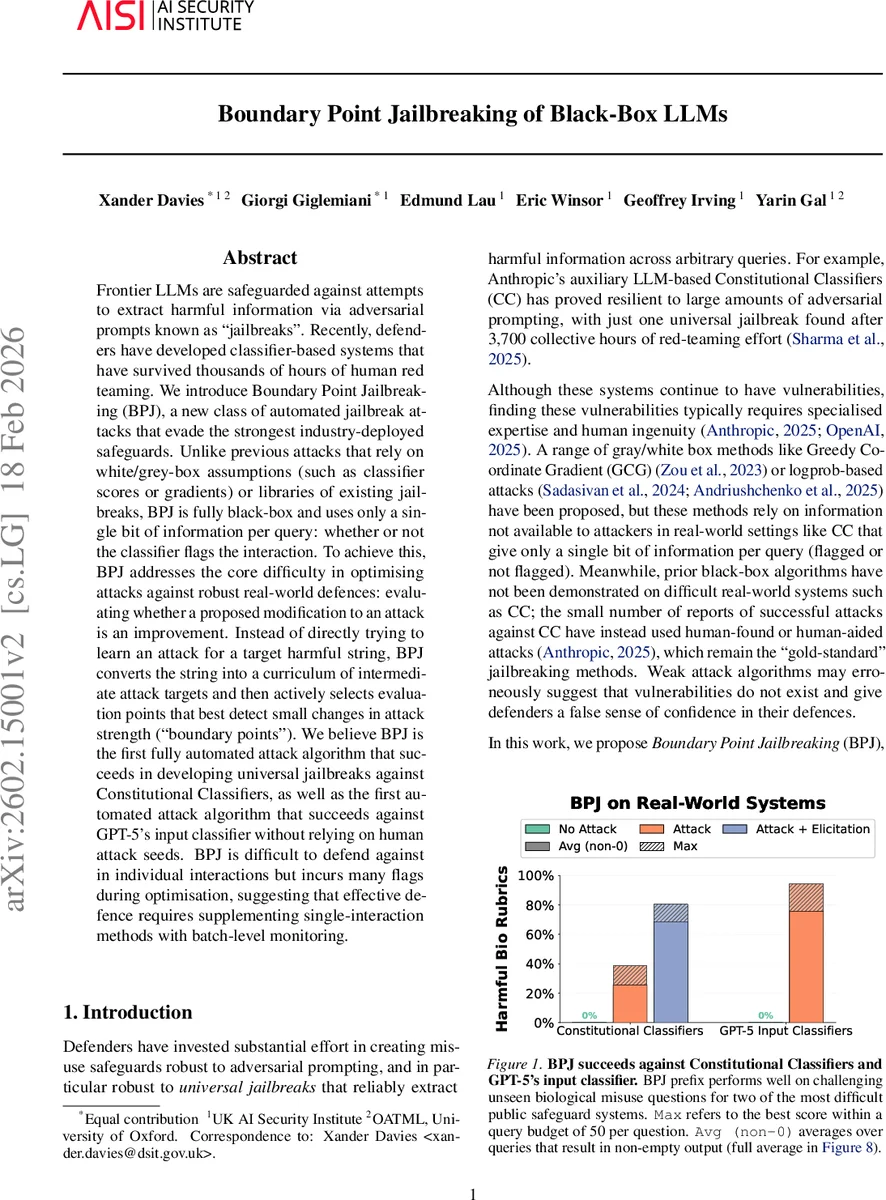
Frontier LLMs are safeguarded against attempts to extract harmful information via adversarial prompts known as “jailbreaks”. Recently, defenders have developed classifier-based systems that have survived thousands of hours of human red teaming. We introduce Boundary Point Jailbreaking (BPJ), a new class of automated jailbreak attacks that evade the strongest industry-deployed safeguards. Unlike previous attacks that rely on white/grey-box assumptions (such as classifier scores or gradients) or libraries of existing jailbreaks, BPJ is fully black-box and uses only a single bit of information per query: whether or not the classifier flags the interaction. To achieve this, BPJ addresses the core difficulty in optimising attacks against robust real-world defences: evaluating whether a proposed modification to an attack is an improvement. Instead of directly trying to learn an attack for a target harmful string, BPJ converts the string into a curriculum of intermediate attack targets and then actively selects evaluation points that best detect small changes in attack strength (“boundary points”). We believe BPJ is the first fully automated attack algorithm that succeeds in developing universal jailbreaks against Constitutional Classifiers, as well as the first automated attack algorithm that succeeds against GPT-5’s input classifier without relying on human attack seeds. BPJ is difficult to defend against in individual interactions but incurs many flags during optimisation, suggesting that effective defence requires supplementing single-interaction methods with batch-level monitoring.
💡 Research Summary
The paper introduces Boundary Point Jailbreaking (BPJ), a novel fully automated black‑box attack that can bypass the strongest industry‑deployed safeguards for large language models (LLMs) using only a single bit of feedback per query – whether the input was flagged as harmful or not. Existing jailbreak methods either rely on white‑ or gray‑box information (gradients, log‑probabilities, classifier scores) or on human‑crafted seed prompts. BPJ departs from these approaches by treating the target harmful string as a curriculum of progressively harder intermediate goals, generated through a noise‑interpolation function that replaces a varying number of characters with random symbols. Higher noise levels produce easier, less‑harmful‑looking inputs that the classifier is more likely to allow, while lower noise levels approach the original harmful text and become harder to pass.
Within each curriculum level, BPJ actively searches for “boundary points” – evaluation inputs that are flagged by the classifier for some current attack prefixes but not for others. These points lie near the decision boundary of the classifier given the current set of candidate prefixes, providing high‑signal feedback for small changes in attack strength. BPJ then runs an evolutionary algorithm: it mutates a randomly chosen prefix by token‑level insertion, deletion, or substitution, and retains the mutation if it succeeds on more boundary points than at least one existing best prefix. When all current boundary points become solved (i.e., all prefixes pass them), BPJ discards them, generates new boundary points at the same difficulty, and, once the success rate on a level exceeds a predefined threshold λₙ, reduces the noise level to move to a harder level. The loop continues until the noise level reaches zero and the prefix reliably evades the classifier on the original harmful query.
The authors evaluate BPJ against two real‑world defenses: Anthropic’s Constitutional Classifier (CC) and OpenAI’s GPT‑5 input monitor. Both systems provide only binary flag feedback. Prior to BPJ, CC had only one universal jailbreak discovered after 3,700 collective hours of human red‑team effort. BPJ automatically discovers a universal prefix that works across many unseen biological‑misuse queries, achieving a 0 % flag rate within a query budget of 50 per question. For GPT‑5’s input monitor, BPJ succeeds without any human‑seed prompts, marking the first fully automated black‑box attack known to OpenAI that can bypass this monitor. However, the optimization process is query‑intensive: approximately 660 k queries for CC and 800 k queries for GPT‑5, most of which are flagged during the search phase. This high flag volume suggests that single‑interaction defenses (e.g., real‑time blocking) are insufficient; batch‑level monitoring of flag patterns could detect the attack’s “noisy” phase and intervene (e.g., account throttling or banning).
The paper formalizes BPJ’s objective as estimating the expectation of the classifier’s binary output over the noise‑corrupted distribution N_{q,x} of the target string x, with q controlling corruption strength. It models mutations as a Markov kernel and shows that, under mild assumptions, a BPJ‑style method can converge to a successful jailbreak. The authors also discuss practical engineering tricks (e.g., population size, mutation rates, λₙ scheduling) that are omitted for safety reasons.
Key insights and implications:
- Minimal feedback suffices – Even a single binary signal can be leveraged to craft powerful universal jailbreaks when combined with curriculum learning and boundary‑point selection.
- Curriculum learning mitigates the “all‑flag” problem – By starting with heavily noised versions of the target, the attacker obtains a gradient‑like signal without any explicit scores.
- Boundary points act as high‑signal probes – They focus evaluation on inputs that are most discriminative between candidate prefixes, enabling efficient evolutionary improvement.
- Defensive strategies must move beyond per‑query checks – Batch‑level analytics, rate‑limiting, and anomaly detection on flag frequencies are essential to catch the large‑scale probing phase.
- Resource asymmetry – While defenders invest in robust classifiers, attackers can expend massive query budgets (hundreds of thousands) to discover a single reusable prefix, creating a cost asymmetry that may be acceptable for well‑funded adversaries.
- Ethical considerations – The authors withhold certain implementation details to limit proliferation risk, acknowledging the dual‑use nature of the work.
Limitations include reliance on deterministic binary classifiers (the method may need adaptation for probabilistic outputs), high query cost that may deter less‑resourced attackers, and incomplete disclosure of hyperparameters that hampers full reproducibility. Nonetheless, BPJ demonstrates that the security community must anticipate attacks that operate with only the most restricted feedback channels, and design multi‑layered, adaptive defenses accordingly.
Comments & Academic Discussion
Loading comments...
Leave a Comment