LayerSync: Self-aligning Intermediate Layers
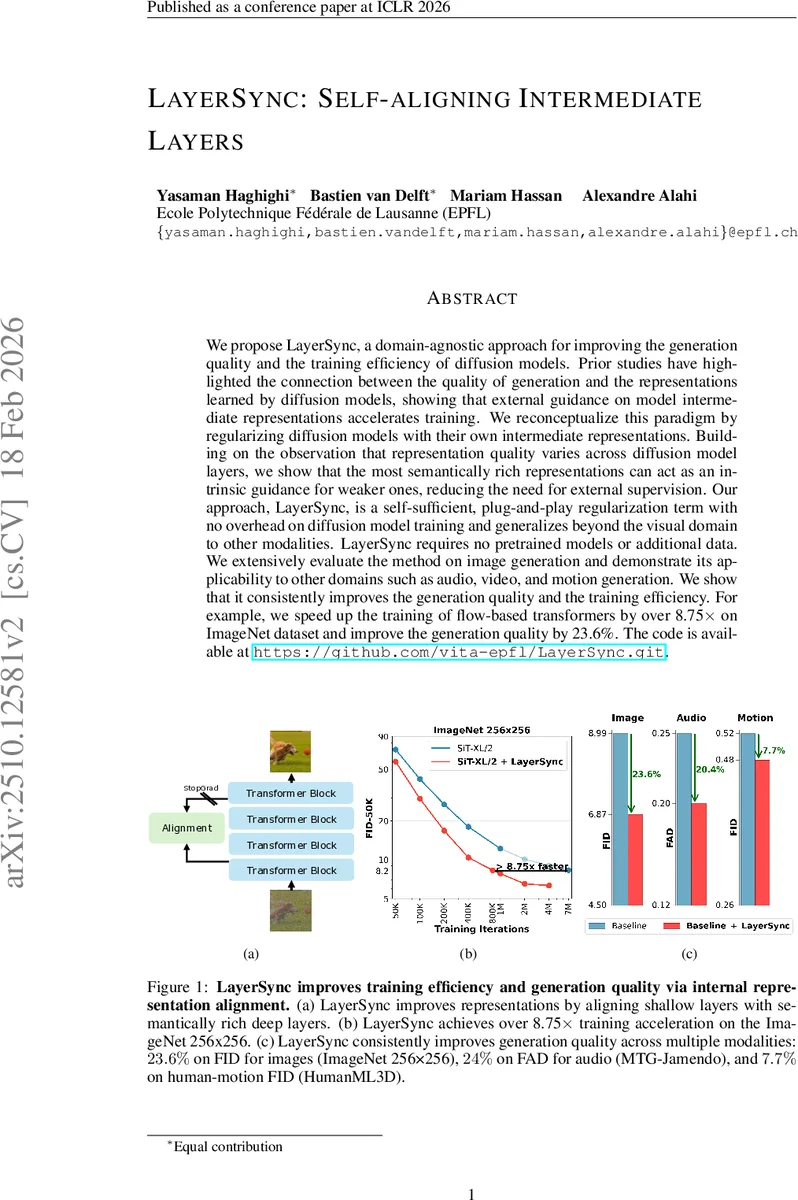
We propose LayerSync, a domain-agnostic approach for improving the generation quality and the training efficiency of diffusion models. Prior studies have highlighted the connection between the quality of generation and the representations learned by diffusion models, showing that external guidance on model intermediate representations accelerates training. We reconceptualize this paradigm by regularizing diffusion models with their own intermediate representations. Building on the observation that representation quality varies across diffusion model layers, we show that the most semantically rich representations can act as an intrinsic guidance for weaker ones, reducing the need for external supervision. Our approach, LayerSync, is a self-sufficient, plug-and-play regularizer term with no overhead on diffusion model training and generalizes beyond the visual domain to other modalities. LayerSync requires no pretrained models nor additional data. We extensively evaluate the method on image generation and demonstrate its applicability to other domains such as audio, video, and motion generation. We show that it consistently improves the generation quality and the training efficiency. For example, we speed up the training of flow-based transformer by over 8.75x on ImageNet dataset and improved the generation quality by 23.6%. The code is available at https://github.com/vita-epfl/LayerSync.
💡 Research Summary
LayerSync introduces a self‑contained regularization technique for diffusion models that leverages the model’s own intermediate representations as intrinsic guidance, eliminating the need for external pretrained networks. The authors observe that representation quality varies across layers: deeper layers tend to capture richer semantic information, while early layers are comparatively weaker. Building on this hierarchy, LayerSync aligns the feature vectors of a selected “weak” early layer k with those of a “strong” deeper layer k′ (k < k′) by maximizing cosine similarity while applying stop‑gradient to the deeper layer so it acts as a fixed teacher. The alignment loss L₍LayerSync₎(k,k′)=−E₍xₜ,t₎
Comments & Academic Discussion
Loading comments...
Leave a Comment