Multi-Modal Multi-Agent Reinforcement Learning for Radiology Report Generation: Radiologist-Like Workflow with Clinically Verifiable Rewards
We propose MARL-Rad, a novel multi-modal multi-agent reinforcement learning framework for radiology report generation that coordinates region-specific agents and a global integrating agent, optimized via clinically verifiable rewards. Unlike prior si…
Authors: Kaito Baba, Satoshi Kodera
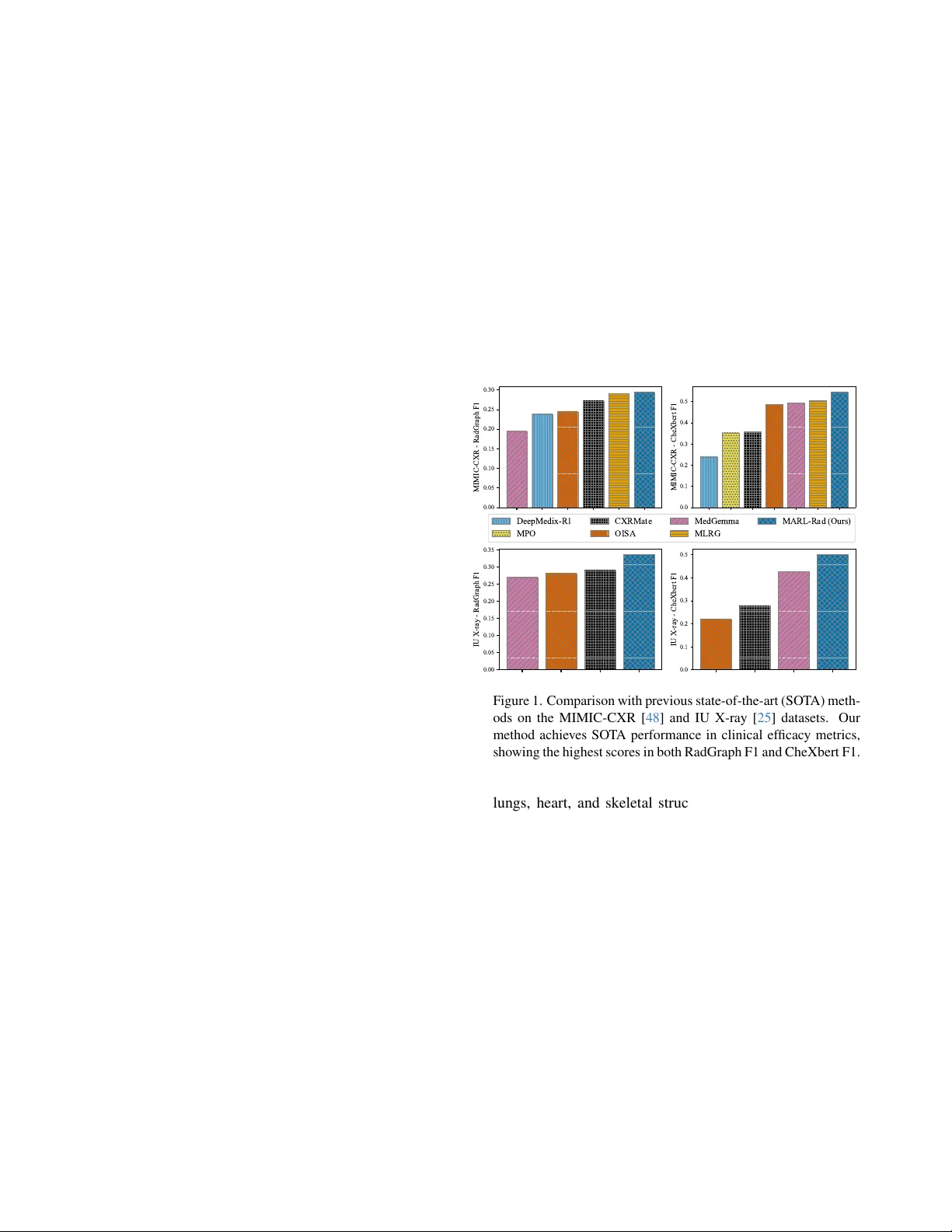
Multi-Modal Multi-Agent Reinf or cement Learning f or Radiology Report Generation: Radiologist-Like W orkflow with Clinically V erifiable Rewards Kaito Baba, Satoshi K odera Department of Cardiov ascular Medicine The Uni versity of T okyo Hospital, T okyo, Japan baba-kaito662@g.ecc.u-tokyo.ac.jp Abstract W e pr opose MARL-Rad, a no vel multi-modal multi-agent r einfor cement learning frame work for radiology r eport gen- eration that coor dinates r e gion-specific a gents and a global inte grating agent, optimized via clinically verifiable r e- war ds. Unlike prior single-model reinfor cement learning or post-hoc a gentization of independently trained models, our method jointly trains multiple agents and optimizes the entir e agent system thr ough r einfor cement learning. Exper- iments on the MIMIC-CXR and IU X-ray datasets show that MARL-Rad consistently impr oves clinically efficacy (CE) metrics such as RadGraph, CheXbert, and GREEN scores, achie ving state-of-the-art CE performance. Further analy- ses confirm that MARL-Rad enhances laterality consistency and pr oduces more accur ate, detail-informed r eports. 1. Introduction Recent adv ances in large language models (LLMs) have demonstrated remarkable reasoning and generation capa- bilities across a wide range of domains, including dialogue systems, mathematical reasoning, code synthesis, scientific discov ery , and medical diagnosis [ 23 , 31 , 88 , 127 ]. A ma- jor factor behind these adv ances is Reinforcement Learning with V erifiable Rew ards (RL VR), which strengthens mod- els through outcome-based feedback grounded in objec- tiv ely verifiable performance metrics [ 96 , 99 , 135 , 144 ]. At the same time, agentic systems ha ve emerged as a promis- ing paradigm for effecti vely leveraging LLMs to approach complex real-world tasks, by decomposing them into man- ageable subtasks and coordinating multiple agents tow ard a shared goal [ 5 , 33 , 37 , 44 , 52 , 57 , 59 , 94 , 123 , 142 ]. Medicine is one of the most important application domains of LLMs and large vision–language models (L VLMs). Among v arious medical modalities, chest X- ray (CXR) is one of the most widely used diagnostic tools in clinical practice, allo wing physicians to examine the 0.00 0.05 0.10 0.15 0.20 0.25 0.30 MIMIC-CXR - RadGraph F1 0.0 0.1 0.2 0.3 0.4 0.5 MIMIC-CXR - CheXbert F1 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 IU X-ray - RadGraph F1 0.0 0.1 0.2 0.3 0.4 0.5 IU X-ray - CheXbert F1 DeepMedix-R1 MPO CXRMate OISA MedGemma MLRG MARL-Rad (Ours) Figure 1. Comparison with previous state-of-the-art (SO T A) meth- ods on the MIMIC-CXR [ 48 ] and IU X-ray [ 25 ] datasets. Our method achieves SO T A performance in clinical efficac y metrics, showing the highest scores in both RadGraph F1 and CheXbert F1. lungs, heart, and skeletal structures to identify conditions such as pneumonia, pneumothorax, pleural effusion, and cardiomegaly [ 2 , 11 , 12 , 82 ]. Radiologists carefully in- spect CXR images and manually compose detailed diag- nostic reports based on their interpretations. Ho wev er , this reporting process is time-consuming and labor-intensi ve. As the demand for diagnostic imaging continues to in- crease, the burden of manual report writing can lead to de- lays in diagnosis and potential degradation in report qual- ity [ 10 , 21 , 26 , 98 ]. T o help mitigate these challenges and alleviate the reporting burden, automated radiology report generation (RRG) using LLMs has attracted gro wing atten- tion as a promising approach [ 1 , 4 , 22 , 24 , 24 , 55 , 62 , 72 , 92 , 106 , 116 , 119 , 125 , 126 , 145 ], with recent studies fur- ther e xploring reinforcement learning [ 18 , 66 ] and agentic system [ 28 , 50 , 79 , 131 , 139 ] design to enhance clinical ac- curacy and reasoning fle xibility . 1 Despite these recent developments, most reinforcement learning approaches to date remain limited to optimizing a single, monolithic model, e ven in recent works on agentic reinforcement learning with tool use or planning capabil- ities [ 14 , 27 , 29 , 60 , 81 , 95 , 102 , 104 , 137 ]. Also, exist- ing agentic systems are typically training-free, merely com- bining pretrained models through prompting without end- to-end optimization [ 44 , 52 , 59 , 94 , 142 ]. While some recent studies have explored off-polic y post-training from agent trajectories [ 83 ] or on-polic y reinforcement learning to a single central agent [ 63 ], on-polic y optimization of the entire agentic system within real-world workflows re- mains lar gely unexplored. In particular , such workflo w- aligned multi-agent reinforcement learning (MARL) has been scarcely e xplored in multi-modal or medical do- mains [ 61 , 85 , 115 , 130 ]. W ithout such workflo w-aligned multi-agent reinforcement learning, e xisting agentic sys- tems are inherently suboptimal, as individual agents are not jointly trained to collaborate in a manner consistent with real-world workflo ws of applied tasks. T o address this limitation and adv ance radiology report generation through more effecti ve agentic RL, we propose a nov el multi-modal multi-agent reinforcement learning framew ork for radiology report generation ( MARL-Rad ). MARL-Rad consists of region-specific agents responsible for localized observations and a global integrating agent that synthesizes their outputs. Our framew ork jointly trains these agents in an on-polic y manner based on clinically ver - ifiable rew ards, optimizing the entire agentic system within a realistic workflo w . This workflow mirrors the real practice of radiologists, who meticulously examine each anatomi- cal region before composing the comprehensive diagnos- tic report. Experiments on the MIMIC-CXR and IU X- ray datasets demonstrate that MARL-Rad consistently im- prov es clinical efficacy metrics such as RadGraph F1 [ 43 ], CheXbert F1 [ 103 ], and GREEN scores [ 89 ], achie ving state-of-the-art performance. Moreover , deeper analyses show that MARL-Rad improv es laterality consistenc y and produces more detailed and clinically accurate descriptions. Our key contrib utions are summarized as follows: • End-to-end optimization of collaborative agents : Un- like prior training-free approaches or single-agent RL methods, MARL-Rad performs on-policy optimization of the entire agentic system within a workflo w that mirrors the real practice of radiologists. • State-of-the-art performance on clinical efficacy (CE) metrics : Experiments on the MIMIC-CXR and IU X- ray datasets demonstrate that MARL-Rad achiev es state- of-the-art performance on various CE metrics, including RadGraph F1, CheXbert F1, and GREEN scores. • Enhanced laterality consistency and accurate, detail- informed reports : MARL-Rad improv es laterality con- sistency and generates more detailed and clinically accu- rate reports compared to single-agent RL baselines. 2. Related work 2.1. Reinf orcement lear ning for LLMs Reinforcement Learning with V erifiable Rewards (RL VR) has recently emerged as an alternati ve to traditional Rein- forcement Learning from Human Feedback (RLHF), pro- viding objectiv e, outcome-based feedback through deter- ministic verification functions rather than human prefer- ence models. By rewarding correctness or rule-based va- lidity , RL VR has impro ved reasoning capabilities in struc- tured domains, such as mathematics and code genera- tion [ 77 , 78 , 99 , 105 , 122 , 135 , 144 ]. More recently , agentic reinforcement learning has g ained attention, where models interact with external tools such as Python inter- preters or web search engines to improv e factual accu- racy [ 14 , 27 , 29 , 60 , 81 , 95 , 102 , 104 , 137 ]. Ho wever , most of these methods still focus on training a single, monolithic model, rather than jointly optimizing multiple agents. Con- sequently , genuine cooperative optimization among agents in real-world workflo ws remains largely unexplored. 2.2. Agentic systems with LLMs Agentic systems lev erage LLMs to perform goal-oriented reasoning, planning, and collaboration through structured interactions among multiple agents. Recent frameworks such as AutoGen [ 123 ], MetaGPT [ 33 ], CAMEL [ 57 ], hav e shown that pretrained LLMs can engage in cooper- ativ e behaviors via carefully designed prompts and work- flows [ 5 , 37 , 44 , 52 , 59 , 64 , 94 , 142 ]. Howe ver , most of these systems are training-free, relying on pre-trained mod- els without end-to-end optimization, resulting in suboptimal coordination and limited adaptability when applied to com- plex, real-world w orkflows. Recent works have started to explore reinforcement learning within agentic systems. For example, MAL T [ 83 ] performs post-training using trajectories collected from agent executions, but its optimization remains off-polic y and detached from real-world workflo w interactions. MA- PoRL [ 91 ] applies multi-agent reinforcement learning to improv e collaboration among language models, yet the op- timization of realistic, role-structured workflo ws in applied domains remains lar gely unexplored. T o address this gap, AgentFlow [ 63 ] introduces on-policy reinforcement learn- ing within an actual multi-agent workflow , but the optimiza- tion is limited to a single key planner agent rather than the entire agentic system. 2.3. LLMs f or radiology report generation (RRG) Early RRG systems mostly followed encoder –decoder paradigms with T ransformers, such as R2Gen [ 15 ], which established strong baselines on the MIMIC-CXR [ 48 ] and 2 IU X-ray [ 25 ] datasets. Recent LLM-centric approaches align a medical visual encoder with a frozen or fine-tuned LLM to produce more fluent, clinically grounded reports, such as R2GenGPT [ 118 ], XrayGPT [ 110 ], MAIRA-1 [ 42 ], MAIRA-2 [ 7 ], and CheXagent [ 17 ], along with other ap- proaches [ 1 , 3 , 8 , 20 , 24 , 26 , 30 , 32 , 34 – 36 , 38 – 40 , 45 , 46 , 49 , 51 , 55 , 56 , 72 , 74 , 75 , 80 , 84 , 86 , 92 , 93 , 106 , 111 , 114 , 119 – 121 , 124 – 126 , 128 , 129 , 132 , 133 , 136 , 138 , 140 , 141 , 145 , 146 ]. 2.4. Reinf orcement lear ning for RRG Recent studies hav e incorporated reinforcement learning to enhance clinical accuracy in RRG. LM-RRG [ 145 ] in- tegrates clinical-quality RL by directly optimizing Rad- CliQ [ 134 ] as a reward signal. BoxMed-RL [ 47 ] cou- ples chain-of-thought supervision with spatially verifi- able RL that ties textual findings to bounding-box evi- dence. DeepMedix-R1 [ 66 ] employs a three-stage pipeline: instruction-fine-tuning, synthetic reasoning sample expo- sure, and online reinforcement learning. OraPO [ 18 ] pro- poses an oracle-educated group relativ e policy optimiza- tion (GRPO) for radiology report generation that lecerages fact-le vel re ward (FactScore). Med-R1 [ 54 ] applies GRPO- based reinforcement learning to medical VLMs across eight imaging modalities and five VQA task types. Howe ver , these RL approaches primarily focus on optimizing a single model rather than optimizing entire multi-agent systems. 2.5. Agentic systems f or RRG Multi-agent frame works are beginning to appear in RRG, where they align with clinical reasoning stages or combine multi-agent retriev al-augmented generation (RA G). RadA- gents [ 139 ] proposes a radiologist-like, multi-agent work- flow for chest X-ray interpretation. CXRAgent [ 79 ] intro- duces a director-orchestrated, multi-stage agent for chest X-ray interpretation that validates tool outputs with an evidence-dri ven v alidator and coordinates diagnostic plan- ning and team-based reasoning. Y i et al. [ 131 ] decomposes CXR reporting into retrie val, draft, refinement, vision, and synthesis agents aligned with stepwise clinical reasoning. Elboardy et al. [ 28 ] proposes a model-agnostic, ten-agent framew ork that unifies radiology report generation and ev al- uation, coordinated by an orchestrator and including an LLM-as-a-judge. Howe ver , these agentic RRG systems are mostly training-free, relying on pretrained models without end-to-end optimization of entire systems. 3. Method 3.1. Preliminaries In this section, we introduce the notations necessary for this paper , and as background, briefly describe Group Sequence Policy Optimization (GSPO) [ 144 ], which is a sequence- lev el variant of GRPO [ 99 ] that improv ed performance. Let D denote the data distribution ov er query–answer pairs ( q , a ) . Like GRPO, GSPO samples a group of G re- sponses ( { x i } G i =1 ∼ π θ old ( · | q )) for each query q , where π θ old denotes the policy used to generate outputs before up- dating the current policy . Each sampled response x i is then ev aluated by a verifiable reward r ( x i , a ) , and group-relati ve advantage is computed as follo ws: ˆ A i : = r ( x i , a ) − mean( { r ( x i , a ) } G i =1 ) std( { r ( x i , a ) } G i =1 ) . (1) GSPO then performs policy optimization by maximizing the following objecti ve: J GSPO ( θ ) : = E ( q ,a ) ∼D , { x i } G i =1 ∼ π θ old ( ·| q ) " 1 G G X i =1 min s i ( θ ) ˆ A i , clip( s i ( θ ) , 1 − ε, 1 + ε ) ˆ A i # , (2) where s i ( θ ) : = π θ ( x i | q ) π θ old ( x i | q ) 1 / | x i | = Q | x i | t =1 π θ ( x i,t | q , x i,
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment