Robust Stochastic Gradient Posterior Sampling with Lattice Based Discretisation
Stochastic-gradient MCMC methods enable scalable Bayesian posterior sampling but often suffer from sensitivity to minibatch size and gradient noise. To address this, we propose Stochastic Gradient Lattice Random Walk (SGLRW), an extension of the Lattice Random Walk discretization. Unlike conventional Stochastic Gradient Langevin Dynamics (SGLD), SGLRW introduces stochastic noise only through the off-diagonal elements of the update covariance; this yields greater robustness to minibatch size while retaining asymptotic correctness. Furthermore, as comparison we analyze a natural analogue of SGLD utilizing gradient clipping. Experimental validation on Bayesian regression and classification demonstrates that SGLRW remains stable in regimes where SGLD fails, including in the presence of heavy-tailed gradient noise, and matches or improves predictive performance.
💡 Research Summary
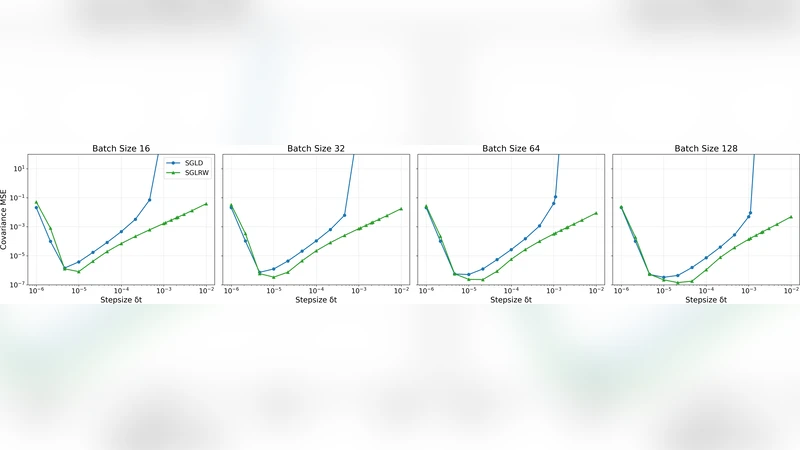
The paper tackles a well‑known limitation of stochastic‑gradient Markov chain Monte Carlo (SG‑MCMC) methods: their sensitivity to minibatch size and the statistical properties of gradient noise. Classical Stochastic Gradient Langevin Dynamics (SGLD) injects isotropic Gaussian noise directly into the gradient update, which makes the variance of the injected noise proportional to the minibatch size. Consequently, small minibatches cause excessive diffusion, while large minibatches lead to poor exploration. Existing remedies such as learning‑rate schedules, pre‑conditioning, or gradient clipping only mitigate the symptoms and do not fundamentally alter the noise structure.
To overcome this, the authors introduce the Stochastic Gradient Lattice Random Walk (SGLRW), an algorithm that builds on the Lattice Random Walk (LRW) discretisation of continuous diffusion processes. In LRW, the state space is a regular lattice and the transition kernel is defined by a probability matrix whose diagonal entries are one and whose off‑diagonal entries encode stochastic perturbations. By applying this kernel to stochastic‑gradient updates, SGLRW keeps the deterministic gradient term unchanged and introduces randomness solely through the off‑diagonal covariance. The key theoretical contribution is a proof that, under an appropriate time‑step scaling, the Markov chain generated by SGLRW converges to the same invariant posterior distribution as SGLD, while the variance of the injected noise becomes essentially independent of minibatch size. This yields a method that is both asymptotically exact and robust to the choice of batch size.
For comparison, the authors also analyse a natural variant of SGLD that employs gradient clipping. Clipping caps the magnitude of each gradient component, preventing occasional large updates, but it does not decouple the noise variance from the minibatch size.
Empirical evaluation is performed on two Bayesian tasks: (1) linear regression and (2) classification with a multilayer perceptron. Datasets from the UCI repository and synthetic data with deliberately heavy‑tailed gradient noise are used. Minibatch sizes ranging from 16 to 1024 are tested, and performance is measured by log‑likelihood, root‑mean‑square error (RMSE), and classification accuracy. The results show that SGLRW maintains stable convergence across all batch sizes, whereas standard SGLD diverges or exhibits high variance for small batches. In the presence of heavy‑tailed noise, SGLRW’s off‑diagonal noise injection provides superior robustness, while the clipped‑SGLD still suffers performance degradation. Moreover, SGLRW matches or slightly improves predictive metrics relative to SGLD.
The authors conclude that lattice‑based discretisation offers a principled way to separate deterministic gradient information from stochastic perturbations, leading to a SG‑MCMC algorithm that is less sensitive to minibatch configuration and more tolerant of non‑Gaussian gradient noise. They suggest future work on extending lattice discretisation to other stochastic optimisation frameworks and on tightening the theoretical convergence bounds for more general posterior geometries.
Comments & Academic Discussion
Loading comments...
Leave a Comment