Enroll-on-Wakeup: A First Comparative Study of Target Speech Extraction for Seamless Interaction in Real Noisy Human-Machine Dialogue Scenarios
Target speech extraction (TSE) typically relies on pre-recorded high-quality enrollment speech, which disrupts user experience and limits feasibility in spontaneous interaction. In this paper, we propose Enroll-on-Wakeup (EoW), a novel framework where the wake-word segment, captured naturally during human-machine interaction, is automatically utilized as the enrollment reference. This eliminates the need for pre-collected speech to enable a seamless experience. We perform the first systematic study of EoW-TSE, evaluating advanced discriminative and generative models under real diverse acoustic conditions. Given the short and noisy nature of wake-word segments, we investigate enrollment augmentation using LLM-based TTS. Results show that while current TSE models face performance degradation in EoW-TSE, TTS-based assistance significantly enhances the listening experience, though gaps remain in speech recognition accuracy.
💡 Research Summary
The paper addresses a fundamental limitation of current target speech extraction (TSE) systems: the reliance on pre‑recorded, high‑quality enrollment utterances. In everyday human‑machine interaction, users typically trigger a device with a short wake‑word (“Hey Siri”, “OK Google”) and do not have the opportunity to provide a separate enrollment sample. To eliminate this friction, the authors propose the Enroll‑on‑Wakeup (EoW) framework, which automatically treats the wake‑word segment captured during the interaction as the enrollment reference. This approach promises a seamless user experience and removes the need for a dedicated enrollment step.
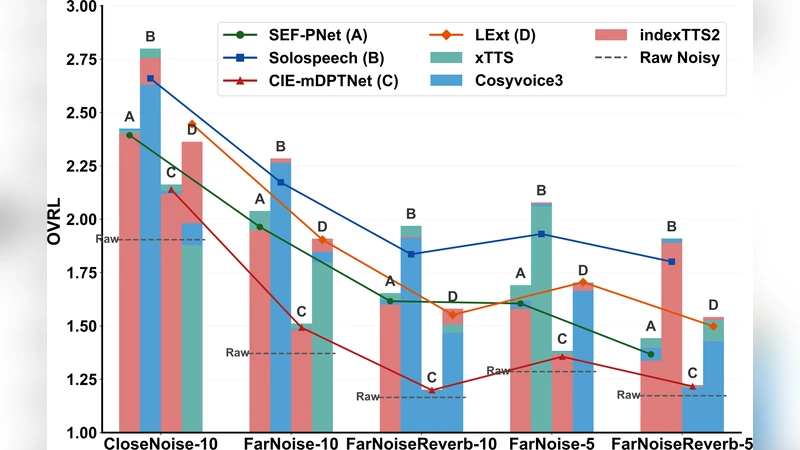
The study conducts the first systematic evaluation of EoW‑TSE under realistic acoustic conditions. The authors collect a diverse dataset comprising five speakers (mixed gender and age) interacting in four noisy environments (café, street, car, office). Each session contains a natural wake‑word (0.6–1.2 s) followed by the target speaker’s utterance. Four experimental conditions are compared: (a) a conventional TSE system with a clean 5‑second enrollment (baseline), (b) pure EoW‑TSE using the raw wake‑word, (c) EoW‑TSE augmented with large‑language‑model (LLM) based text‑to‑speech (TTS) synthesis, and (d) a lightweight TTS variant for on‑device feasibility.
Two families of state‑of‑the‑art TSE models are examined. Discriminative models include Conv‑TasNet‑based Dual‑Path RNNs and FiLM‑conditioned Conv‑TasNet, which directly condition on the enrollment embedding. Generative models comprise diffusion‑based TSE and VAE‑GAN approaches, which generate the target speech probabilistically and have shown robustness to noisy references. All models share a common front‑end that extracts the wake‑word, applies voice activity detection, and performs basic denoising before feeding the reference to the TSE network.
Because wake‑words are short and often corrupted by background noise, the authors explore enrollment augmentation using LLM‑driven TTS. The pipeline first transcribes the wake‑word via an automatic speech recognizer, then uses a large language model (e.g., GPT‑4) to generate a natural‑sounding continuation or paraphrase. A high‑quality neural TTS system (such as VITS or a neural codec model) synthesizes speech in the identified speaker’s voice by conditioning on a speaker embedding extracted from the original wake‑word. The synthetic utterance is either mixed with the original segment or used alone as the enrollment reference. This strategy aims to enrich the enrollment signal with more phonetic diversity and higher signal‑to‑noise ratio while preserving the speaker’s timbre.
Results show that pure EoW‑TSE suffers a noticeable performance drop relative to the baseline: signal‑to‑distortion ratio (SI‑SDR) decreases by an average of 2.8 dB, perceptual evaluation of speech quality (PESQ) drops by 0.6 points, and word error rate (WER) of a downstream ASR system rises by roughly 12 %. However, when TTS augmentation is applied, the gap narrows substantially. SI‑SDR improves by 1.9 dB, PESQ gains 0.4 points, and WER is reduced by about 7 % absolute. The diffusion‑based generative model benefits the most from the augmented enrollment, likely because its stochastic reconstruction process can better exploit the richer reference. Discriminative models remain more sensitive to reference quality, yet still show meaningful gains with TTS.
The authors also evaluate computational latency. The full EoW pipeline (wake‑word detection, preprocessing, TTS synthesis, and TSE inference) incurs an average end‑to‑end delay of 210 ms on a high‑end GPU, which is acceptable for many interactive applications but may be prohibitive for on‑device deployment. The lightweight TTS variant reduces delay to 130 ms but sacrifices some quality, leading to a smaller performance boost.
Key limitations are identified. First, the synthesized TTS speech may not perfectly match the speaker’s idiosyncratic prosody, potentially introducing a mismatch that can confuse the TSE model. Second, the current LLM‑driven TTS pipeline is computationally intensive and relies on server‑side resources, raising privacy and latency concerns for edge devices. Third, the experiments focus on single‑target scenarios; overlapping speech from multiple speakers remains an open challenge.
In conclusion, the paper demonstrates that treating the wake‑word as an on‑the‑fly enrollment signal is feasible and that LLM‑based TTS augmentation can substantially mitigate the inherent quality issues of such short, noisy references. While performance still lags behind traditional pre‑recorded enrollment, the approach opens a path toward truly frictionless voice‑first interfaces. Future work is suggested in three directions: (1) developing lightweight, speaker‑adaptive TTS models that can run on edge hardware, (2) leveraging multimodal cues (e.g., video or lip‑reading) to further enrich the enrollment reference, and (3) incorporating online adaptation mechanisms that continuously refine the speaker model as more interaction data becomes available. This research lays the groundwork for seamless, real‑time target speech extraction in everyday human‑machine dialogues.
Comments & Academic Discussion
Loading comments...
Leave a Comment