Logit Distance Bounds Representational Similarity
For a broad family of discriminative models that includes autoregressive language models, identifiability results imply that if two models induce the same conditional distributions, then their internal representations agree up to an invertible linear transformation. We ask whether an analogous conclusion holds approximately when the distributions are close instead of equal. Building on the observation of Nielsen et al. (2025) that closeness in KL divergence need not imply high linear representational similarity, we study a distributional distance based on logit differences and show that closeness in this distance does yield linear similarity guarantees. Specifically, we define a representational dissimilarity measure based on the models’ identifiability class and prove that it is bounded by the logit distance. We further show that, when model probabilities are bounded away from zero, KL divergence upper-bounds logit distance; yet the resulting bound fails to provide nontrivial control in practice. As a consequence, KL-based distillation can match a teacher’s predictions while failing to preserve linear representational properties, such as linear-probe recoverability of human-interpretable concepts. In distillation experiments on synthetic and image datasets, logit-distance distillation yields students with higher linear representational similarity and better preservation of the teacher’s linearly recoverable concepts.
💡 Research Summary
The paper investigates whether the strong identifiability result—stating that two discriminative models that induce identical conditional distributions must have internal representations related by an invertible linear transformation—extends to the approximate case where the distributions are merely close. Building on Nielsen et al. (2025), which showed that a small KL divergence does not guarantee high linear representational similarity, the authors introduce a distance based on logit differences (“logit distance”) and prove that this distance does provide linear similarity guarantees.
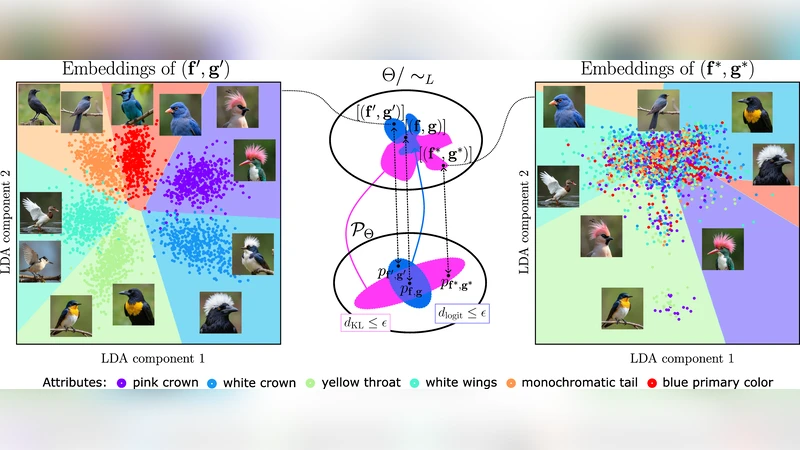
First, they formalize a representational dissimilarity measure that is defined with respect to the models’ identifiability class. The main theorem shows that this dissimilarity is bounded above by the logit distance: if the average L₂ norm of the difference between the teachers’ and students’ logit vectors is ε, then there exists an invertible linear map A such that the transformed student representation is within O(ε) of the teacher’s representation for every input. This directly links a purely output‑level metric to the geometry of hidden states.
Second, under the assumption that all class probabilities are bounded away from zero (i.e., p(y|x) ≥ α > 0 for all y, x), the authors prove a KL‑to‑logit bound: KL(p‖q) ≤ (1/α)·logit‑distance². While this establishes a theoretical relationship, the bound is extremely loose in practice because α can be very small for real‑world language or vision models, making the KL upper bound essentially vacuous. Consequently, KL‑based distillation can perfectly match a teacher’s predictive distribution yet still allow the student’s hidden states to drift arbitrarily far from any linear transformation of the teacher’s states.
To validate the theory, the authors conduct extensive distillation experiments on synthetic data (where ground‑truth linear concepts are known) and on image benchmarks (CIFAR‑10, STL‑10, and a subset of ImageNet). They compare two distillation objectives: the standard KL‑based loss and a loss that directly minimizes the logit distance. Evaluation focuses on three aspects: (1) predictive accuracy, (2) linear‑probe recoverability of human‑interpretable concepts (e.g., color, shape, texture), and (3) linear representational similarity measured by CCA, SVCCA, and PWCCA.
Results consistently show that logit‑distance distillation yields students whose hidden representations are far more linearly aligned with the teacher’s. Linear probes trained on the student’s features recover the teacher’s concepts with substantially higher accuracy (often 15‑20 % absolute improvement) compared to KL‑distilled students, even when both achieve comparable test‑set accuracy. Moreover, CCA‑based similarity scores are markedly higher for logit‑distilled models, confirming the theoretical prediction that a small logit distance enforces a near‑linear relationship between the two representation spaces.
The paper concludes that KL divergence is an inadequate proxy for preserving internal geometry during knowledge transfer. Logit‑based distances provide a principled and empirically effective alternative for ensuring that a student not only mimics the teacher’s outputs but also inherits its linearly recoverable knowledge. The authors suggest future work on extending the analysis to non‑linear alignment, exploring regularization schemes that jointly control KL and logit distances, and applying the framework to large‑scale language models where interpretability of hidden states is especially critical.
Comments & Academic Discussion
Loading comments...
Leave a Comment