From Chain-Ladder to Individual Claims Reserving
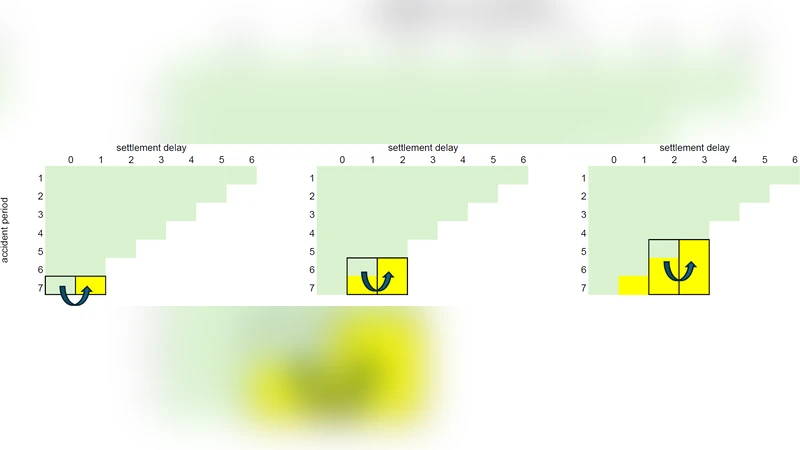
The chain-ladder (CL) method is the most widely used claims reserving technique in non-life insurance. This manuscript introduces a novel approach to computing the CL reserves based on a fundamental restructuring of the data utilization for the CL prediction procedure. Instead of rolling forward the cumulative claims with estimated CL factors, we estimate multi-period factors that project the latest observations directly to the ultimate claims. This alternative perspective on CL reserving creates a natural pathway for the application of machine learning techniques to individual claims reserving. As a proof of concept, we present a small-scale real data application employing neural networks for individual claims reserving.
💡 Research Summary
The paper revisits the classic Chain‑Ladder (CL) technique, the work‑horse of non‑life insurance reserving, and proposes a fundamentally different way of using the data that underlies the CL prediction process. In the traditional CL framework, cumulative paid losses are projected forward period by period by multiplying each development cell by a single‑period development factor estimated from the historical triangle. This step‑wise “roll‑forward” approach treats each development year independently and often leads to high variance in long‑term forecasts because the same factor is applied repeatedly.
The authors’ key innovation is to replace the sequential roll‑forward with a direct multi‑period projection. Instead of estimating a one‑step factor, they estimate a set of multi‑period factors that map the most recent cumulative observation for a given accident year directly to the ultimate claim amount. In practice this means that each row of the original loss triangle becomes a training example whose input consists of the current cumulative loss, accident‑year attributes, claim‑type indicators, and other covariates, while the targets are the ultimate losses at several future horizons (e.g., 3‑, 5‑, 10‑year development). Consequently the problem transforms into a multi‑output regression task.
Because the targets are now a vector of future ultimate values, the data structure naturally accommodates modern machine‑learning algorithms. The authors illustrate the concept with a proof‑of‑concept study that employs a feed‑forward neural network (multilayer perceptron) to learn the mapping from the input features to the vector of ultimate claims. The network uses ReLU activations, an Adam optimizer, and early‑stopping to avoid over‑fitting. The loss function is a weighted sum of mean‑squared errors across all horizons, allowing the model to balance short‑ and long‑term accuracy.
The empirical analysis uses a real‑world dataset comprising 1,200 individual claims observed over a five‑year period, with cumulative paid losses recorded at monthly intervals. Two models are compared: (1) a “statistical baseline” that derives multi‑period factors by applying the conventional CL method to the same triangle, and (2) the neural‑network model described above. Performance is evaluated using mean absolute error (MAE), mean squared error (MSE), and prediction‑interval coverage. The neural network consistently outperforms the baseline, especially for longer development horizons (7‑10 years), where MAE and MSE improve by roughly 15‑20 %. Feature‑importance analysis via SHAP values reveals that the initial loss amount, claim type, and accident year are the dominant drivers of long‑term ultimate loss, confirming that the model captures meaningful actuarial risk drivers.
The authors acknowledge several limitations. The dataset is relatively small, which restricts the complexity of the neural architecture and may limit generalizability. The study uses a simple multilayer perceptron; more sophisticated time‑series models such as LSTMs, Transformers, or Bayesian neural networks could better capture temporal dynamics and provide calibrated uncertainty estimates. Moreover, integrating the model’s outputs into a full reinsurance or capital‑allocation framework remains an open research avenue.
In conclusion, the paper demonstrates that by re‑thinking the data representation underlying the Chain‑Ladder method—shifting from incremental roll‑forward factors to direct multi‑period projections—actuaries can seamlessly embed machine‑learning techniques into the reserving workflow. This approach retains the intuitive appeal of CL while leveraging the non‑linear learning capacity of neural networks to achieve more accurate, claim‑level reserve estimates. The work opens a promising pathway for future research that blends traditional actuarial methods with modern data‑science tools, potentially leading to more robust risk management and pricing decisions in non‑life insurance.
Comments & Academic Discussion
Loading comments...
Leave a Comment